我们已经告诉您有关
文本的有趣
统计信息, 对有关在文本分析中使用自动编码器的文章进行了
评论 ,并为我们提供了
可转让借用和
释义的全新
搜索算法,使我们感到惊讶。 我决定继续我们的公司传统,首先,以“ T”开头,其次,告诉:
- 如何在数亿篇文章中快速找到一段文本;
- 加载到Anti-Plagiarism系统后文档变成什么,下一步该怎么做;
- 如何形成几乎没有人看过但值得的报告;
- 如何索引不全部,但足够。

一切如何开始
2005年,莫斯科最大的一所大学的校长来到
Forecsys,来解决一个非常严重的问题-在教育机构中,学生通过了完全注销的文凭和学期论文。 我们挑选了数百本优秀学生的作品,并通过简单的查询在网络中进行搜索。 超过一半的
“优秀学生”被证明是骗子,他们从互联网上下载了文凭并仅替换了标题页。 一半以上的优秀学生,卡尔! 普通学生发生的事情很难想象。 搜索工作的最简单方法是查询包含带有“黑洞”的单词。 我们已经意识到灾难的严重性。 迫切需要解决一些问题。 到那时,外国英语大学已经在使用借用的搜索解决方案,但是由于某种原因,没有人检查过俄语。
那时,外国玩家不想让他们的解决方案适应俄语。 结果,在2005年3月17日,开始了第一个国内借贷搜索系统的开发。 “ Anti-抄袭”一词是在稍后产生的,antiplagiat.ru域于2005年4月28日注册。 我们计划在2005年9月1日之前发布该站点,但是,就像程序员经常遇到的那样,它没有时间。 我们公司的正式生日是antiplagiat.ru首次收到用户的日期,即9月4日。 您知道,对此我感到非常高兴,因为在公司生日那天的公司聚会上,每个人都可以冷静地庆祝,而不必担心孩子的上学日。
但是我有些分心。 在2005年,我们创建了一种搜索引擎,其中与Yandex和Google不同的是,查询不是两个或三个单词,而是一个包含多个句子的全文。 因此,如果您的文字包含1000个字符(大约半页),则可以合理使用“反抄袭”。
在服务开发期间,在php(Web部件)和Microsoft SQL Server(搜索引擎)上制作了原型。 立刻清楚的是,这不会生效,并且会慢慢处理几百万个文档。 因此,我不得不削减搜索引擎。 现在,系统是用C#和python编写的,使用PostgreSQL和MongoDB(事实上,还有很多,但是在下一篇文章中会介绍更多)。 搜索引擎仍由我们完全开发。 如果您想了解系统开发的历史,公司流程的变化以及Antiplagiarism在其生命中不同时期工作的硬件,以及现在正在工作,请在评论中写下。
提供公司名称的单词现在已成为家喻户晓的单词。 通常在搜索引擎中,人们会找到诸如“检查是否存在抄袭”,“增加反pla窃”之类的表述。 在俄罗斯和邻国与借阅搜索领域有某种联系的每个人都在尝试使用“反抄袭”一词在搜索结果中提出它。 人们经常被问到其他“反抄袭”。 因此,“反抄袭”是其中之一,它是我们公司的商标和名称。
在贷款搜索服务实施之初,我们决定将文本作为一个字符序列来使用。 从文本,含义的搜索,句子的分析等各种语义构造被立即拒绝了。 我们选择的解决方案具有两个巨大的优势-高搜索速度和相对较小的搜索索引量。
目前,我们的阵容中有三种产品。 它们在功能上有所区别,但基本上都包含借用搜索的相同原理。 在本文中,我将讨论传统的借阅搜索是如何工作的-该功能从一开始就已成为服务的基础,并且在概念上仍然没有改变。 正如您在图中看到的,借位搜索方案非常简单明了,就像画猫头鹰一样。 首先,我们从用户那里获取文档,然后从中提取文本。 然后,我们在本文中寻找借项,得到“修订”(我们称其为一个搜索模块的报告),最后,我们将修订收集到一个大报告中,并作为结果显示给用户。
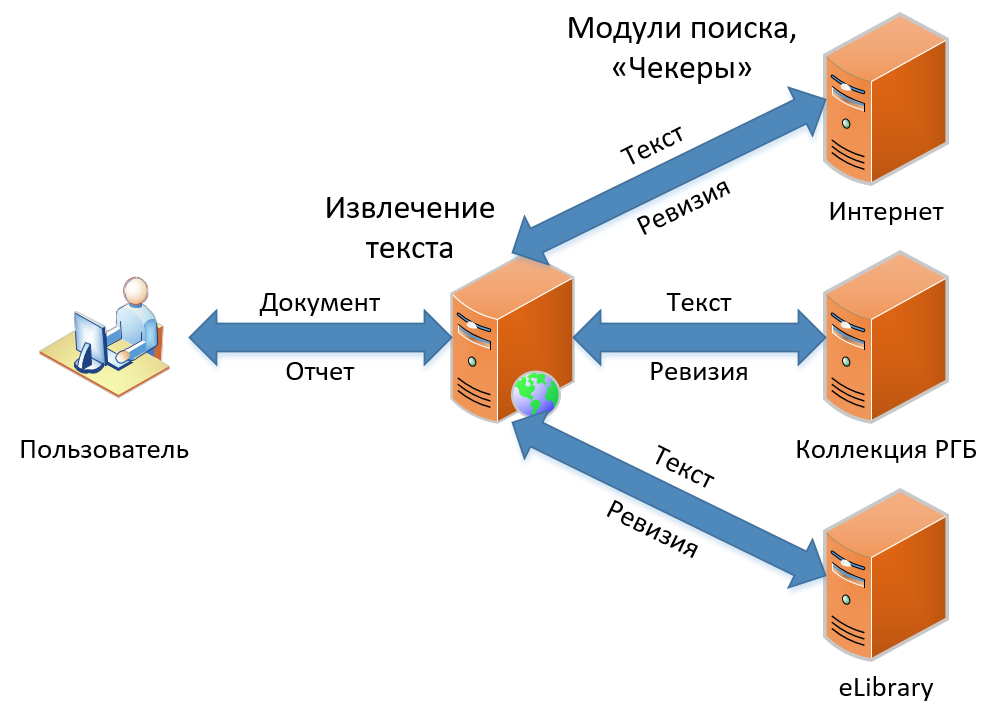
让我们详细了解所有这些情况。
文字提取
首先,“反抄袭”是仅搜索
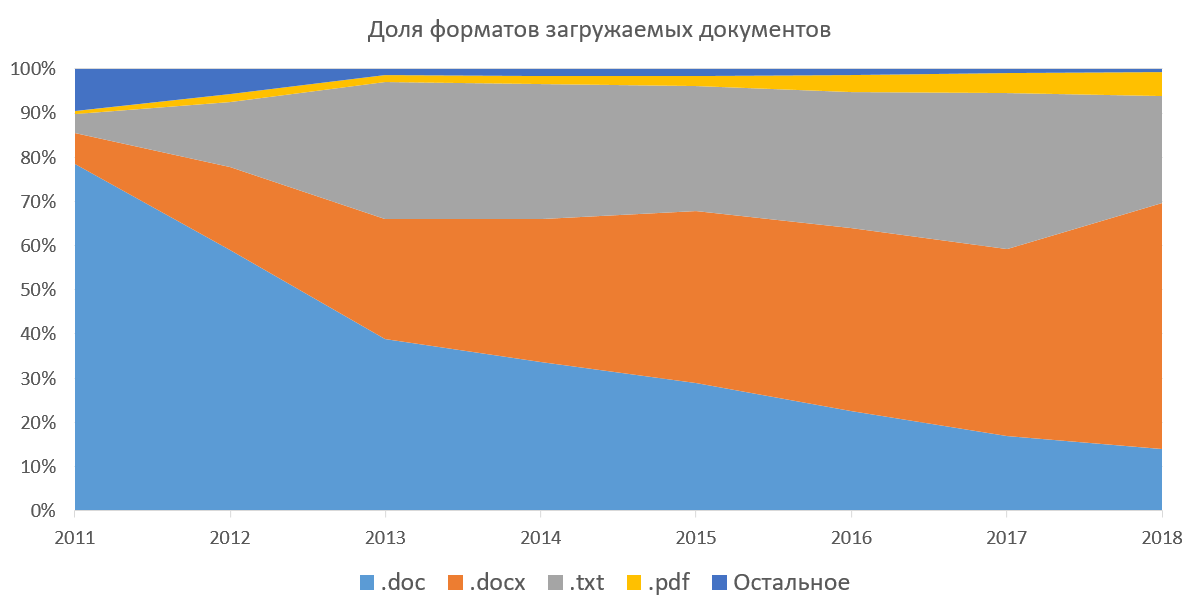
文本借用的服务,这意味着我们需要从所有文档中提取文本才能继续使用。 该系统支持以docx,doc,txt,pdf,rtf,odt,html,pptx和其他几种(从未使用过的)格式下载文档的功能。 您还可以将所有这些文档下载到归档文件中(7z,zip,rar)。 当我们无法通过Web界面一次上传多个文档时,此方法很受欢迎。 下图显示了可下载文档格式在我们系统的公司部分中的普及程度。 它显示了docx在过去几年中是如何被doc取代的,并且pdf的比例正在逐渐增加。 如果您不考虑txt(提取文本是微不足道的),那么对我们来说最有趣的是pdf。 国外pdf是事实上的标准,它发表文章,为学生做准备。 根据我们的统计,pdf在俄罗斯和独联体国家正逐渐流行。 我们自己正在向大众推广这种格式,建议下载其中的文档。
我们将私人客户的文档下载格式限制为pdf和txt,这就是为什么我们减少了资源消耗并降低了支持免费服务的成本。 毕竟,您需要检查文本,而不是测试系统? 那么上传什么格式有什么区别呢?
提取文本的下一个最简单的方法是docx,因为事实上,它是一个内部带有xml的zip归档文件,处理起来非常简单,并且可以在低级别上完成很多工作。
对我们来说最困难的是文档。 这种格式已经关闭很长时间了,现在有很多实现。 最后一个不支持.docx的Microsoft Word(尽管通过Microsoft Office兼容包)已于20年前发布,并已包含在Microsoft Office 97中。该格式使用OLE,后来又扩展为COM和ActiveX,所有内容均为二进制,有时不兼容版本之间。 总的来说,现代程序员的梦dream以求。 .doc格式逐渐退出现场很不错。 我认为现在是我们帮助他退休的时候了。 不久,我们将有目的地警告用户该格式已过时。
所以,回到报告。 我们得到了文件并开始提取文本。 该系统还与文本一起提取页面上单词的位置,以便将来有可能向我们的用户显示文档本身上借入报告的标记。 此外,在同一阶段,我们正在寻找反-窃的技术解决方法。
一旦出现了“反抄袭”,并显示出原创性的百分比,就有一些人希望以最小的努力通过一张借贷支票,以及提供这种金钱服务的人。 问题在于数值参数要求成为估计。 毕竟,它是如此简单-不用阅读而是使用系统作为工具来阅读作品,而不必阅读它,而是通过独创性的百分比来评估它! 正是这种不幸导致了诸如调整作品的方向(为了增加作品的原创性而改变文字)。 在
“关于在俄罗斯大学中检测借贷的实践”一文中,详细了解大学过程中的问题。
在国外搜索系统中,检测技术变通方法并加以解决的问题实际上是不值得的。 事实是,被发现的“假耳朵”将受到非常严厉的惩罚-开除,以及对科学声誉的不可磨灭的污点,与以后的职业不相容。 在我们的案例中,情况非常简单:“哦,这个系统搞砸了!”,“哦,不是我,而是我自己!” 该学生很可能被送去重做。 事实是,注销并不是可耻的事情。
但是又分心了。 提取文本的另一种方法是OCR。 我们在虚拟打印机上打印文档,然后识别它。 在文章
“为抗lag病服务中的图像识别”中了解有关此内容的更多信息。
现在,我们有一些有关提取文本的故事。 首先,我们使用IFilters提取文本。 它们很慢,仅在Windows下运行,并且不返回格式信息(不清楚白色文本在白色背景上的位置,因此您不能直接在用户文档中标记借用块)。 我们以为如果开始使用付费库就可以解决这些问题,但是在这里我们发现了局限性:仍然在Windows下,他们看不到公式,有时它们落在特别准备的文档上(不同的库在不同的库中!)。 下一个想法是对所有传入的文档进行OCR,但是这种方法非常耗资源(在一个核心上每分钟仅处理10页),并且在某些地方无法准确提取文本。
尽管有几次我们认为这是幸福,但我们没有找到灵丹妙药。 但是,在此生活了一点之后,他们意识到这又是一次体验。 文本提取在性能(您需要每分钟从数百个文档中提取文本),可靠性(您需要从所有内容中提取文本),功能(格式,变通办法,仅此而已)之间保持良好的平衡。 现在,以上所有内容以及我们需要做的更多工作。 我们正在不断尝试这一领域,并继续寻找幸福。
提取文本,找到回合并将其部分消除,我们出发寻找借贷!
借用搜索
搜索过程中实现的想法是由Ilya Segalovich和Yuri Zelenkov提出的(例如,您可以在文章:
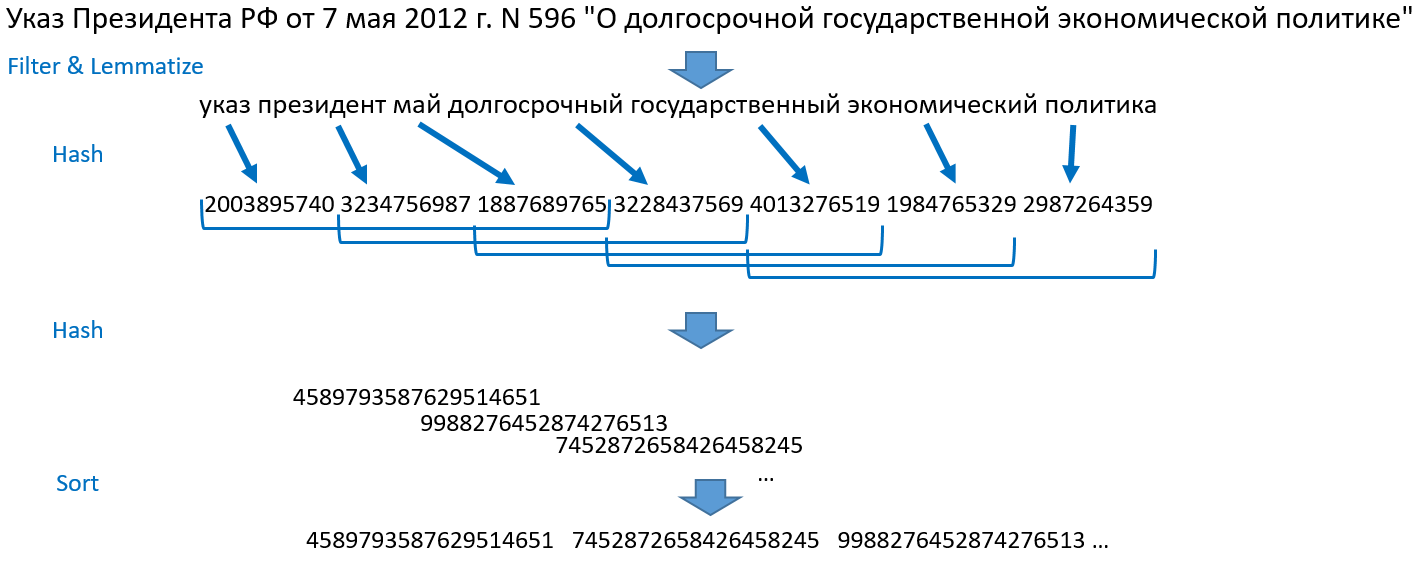
确定Web文档模糊重复项的方法的比较分析中阅读)。 我会告诉您它对我们的运作方式。 例如,以下句子:“ 2012年5月7日俄罗斯联邦总统令N 596”关于国家长期经济政策的“。
- 我们将句子分解为单词,我们抛出数字,标点符号和停用词。 对所有单词进行词法化处理(归纳为正常形式)。
- 我们通过哈希将单词变成整数,得到一个数字数组。
- 我们采用前三个哈希,然后是第二,第三,第四哈希,然后是第三,第四,第五哈希,依此类推直到哈希数组的末尾。 这是瓦片-平铺。 该方法之所以得名,是因为这种平铺的重叠集。 我们将每个图块合并为一个对象,然后再次哈希。
- 我们对结果数字进行排序,得到有序的整数数组。 这是搜索的基础。
现在,对于搜索,我们需要一个魔术函数,该函数根据这样的哈希列表将按匹配哈希数降序排序的文档转换为源文档。 此功能应该可以快速运行,因为 我们想搜索数十亿个文档。 为了快速找到这样的集合,我们需要一个反向索引,该索引通过哈希返回此哈希所在的文档列表。 我们已经实现了这样一个巨大的哈希表。 与我们的旧搜索兄弟不同,我们将此表存储在ssd上,而不是存储在内存中。 我们的表现还很差。 索引搜索只占整个文档处理周期的一小部分。 查看搜索的方式:
阶段1.索引搜索
对于请求文本的每个散列,我们获得了其中出现的源文档的标识符的列表。 接下来,我们根据请求文本中遇到的哈希数对源文档的标识符列表进行排序。 我们获得了有关借贷来源的候选文档的排名列表。
阶段2.审核的构建
对于一个大型的求职者文本请求,可能大约有一万个,将每个文档与请求中的文本进行比较仍然很多。 我们贪婪地,果断地行动。 我们采用第一个原始文档,将其与请求文本进行比较,并从所有其他候选项中排除那些在第一文档中已经存在的哈希。 我们从哈希值列表中删除哈希值为零的候选者,然后根据新的哈希值数对候选者进行重新排序。 我们从新列表中获取第一个文档,将其与源文本进行比较,删除散列,删除零个候选者,并对候选者进行重新排序。 我们执行10到20次,通常足以使列表用完,或者仅保留匹配多个哈希的文档。
使用单词哈希可以使我们更快地执行比较操作,节省内存,并且不存储源文档的文本,而是存储在索引过程中获得的数字转换(TextSpirit,我们亲切地称呼它们),从而侵犯了版权。 使用后缀树选择特定借用片段。
作为一个搜索模块检查的结果,我们得到了一个修订,其中包含源列表,它们的元数据和相对于请求文本的借用单位的坐标。
报告汇编
顺便说一句,如果10-15个模块之一未按时响应怎么办? 我们搜索RSL,电子图书馆和担保人的藏书。 这些搜索模块位于第三方组织的领土上,并且出于版权原因不能转移到我们的网站。 此处的故障点始终是通信渠道和不受我们控制的数据中心中的各种不可抗力。 一方面,可以在任何搜索模块中找到借用信息;另一方面,如果系统的某个组件不可用,则可以降低搜索质量,但可以提供大部分结果,同时警告用户某些搜索模块的结果尚未准备好。 您会采用哪种选择? 我们将适当地应用这两个选项。

最后,所有修订都已收到,我们开始组装报告。 它使用的方法类似于准备一个修订版。 似乎没有什么复杂的,但也有一些有趣的任务。 我们有两种类型的借款。 “引文”以绿色表示-“引文”模块中正确引用(根据GOST)的引号,“通用表达式”模块中“需要证明的内容”类型的表达式,来自Guarantor和Lexpro数据库的监管文件。 所有其他借款均标记为橙色。 除非进入整个橙色区域,否则绿色优先于橙色。
结果,该报告可以与桌上的纸上印刷的文本进行比较,在上面涂上多色条(借款和报价单),彼此之间相互重叠。 我们上面看到的是一份报告。 每个来源都有两个指标:
报告中的份额是从此来源考虑的借贷量与文档总数的比率。 如果在多个来源中找到相同的文本,则仅在其中一个中将其考虑在内。 当您更改报告的配置(启用或禁用源)时,源的此指示符可能会更改。 总的来说,它给出了借阅和引用的百分比(取决于来源的颜色)。
文本中所占的
份额 -从给定文本源中借用的数量与文档总数量的比率。 按来源归纳文本中的份额是没有意义的,很容易得出146%甚至更多。 报告更改时,此指示器不会更改。
当然,可以编辑报告。 这是一项特殊功能,供专家检查作品以禁止借用作者自己的作品(该片段可能不仅存在于作者自己的作品中,而且还存在于其他地方),并分开借用块,从借用引文。 编辑报告的结果是,专家获得了借贷的真实价值。 必须阅读任何验证工作。 通过查看文档的原始格式(在其中标记了借用框)并在阅读时立即编辑报告,可以方便地进行此操作。 不幸的是,这不是每个人的逻辑操作,许多人对创意的百分比感到满意,甚至没有看报告。
但是,让我们回过头去,找出由Anti-Plagiarism创建的Internet搜索模块的索引中包含哪些内容。
互联网索引
反-窃主要集中于学生作品,科学出版物,最终资格作品,论文等。 我们以定向的方式对Internet进行索引-我们正在寻找大量的科学文本,摘要,文章,论文,科学期刊等。 编制索引是这样的:
- 我们的机器人来了,自我介绍,并在robots.txt(我们有一个很好的机器人)的引导下,在每个主机上下载了具有合理负载的文档(数百个站点同时运行,因此我们可以在页面加载之间等待一段时间);
- 机器人将文档及其元数据传递到处理队列,然后从文档中提取文本。
- 对文本进行“质量”分析 -正如您在有关垃圾填埋场的文章中所记起的那样,我们可以确定文档的类型,在此处添加简单的试探法,并了解是否找到合适的文本或垃圾。
- 定性文本走得更远,并变成哈希。 哈希和元数据发送到主要的Internet索引;
- 我们将接收到的文本与我们之前索引的文本进行比较。 仅当新手真的很新时才添加新手 ,即 90% - . , url .
因此,我们为高质量的文本建立了索引,而所有索引的文本对我们来说都大不相同。下图显示了Internet上索引的交易量的增长。现在,我们平均每月向索引添加15-20百万个文档。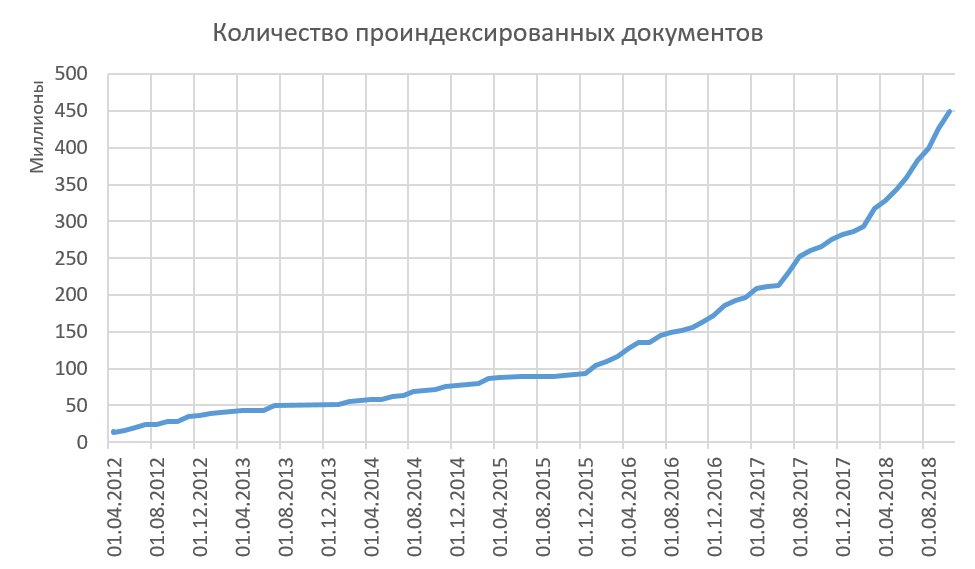 注意,从任何地方都没有描述从索引中删除的过程吗?她不是!我们基本上不从索引中删除文档。我们相信,如果我们能够在Internet上看到某些内容,那么其他人可以看到此文本并以一种或另一种方式使用它。在这方面,有一个有趣的统计信息,曾经是Internet,现在已经不存在了。是的,想象一下“一旦互联网将永远存在在那里”这句话是不正确的!某些东西会永远从互联网上消失。您是否有兴趣了解我们的统计数据?
注意,从任何地方都没有描述从索引中删除的过程吗?她不是!我们基本上不从索引中删除文档。我们相信,如果我们能够在Internet上看到某些内容,那么其他人可以看到此文本并以一种或另一种方式使用它。在这方面,有一个有趣的统计信息,曾经是Internet,现在已经不存在了。是的,想象一下“一旦互联网将永远存在在那里”这句话是不正确的!某些东西会永远从互联网上消失。您是否有兴趣了解我们的统计数据?结论
令人惊讶的是,十多年前采用的技术解决方案仍然具有现实意义。我们现在准备发布该索引的第4版,它更快,技术更先进,更好,但是它基于所有相同的解决方案。出现了新的搜索方向-可转让的借款,措辞,但是我们的索引也用于此处,即使只是很小但很重要的一部分。亲爱的读者,您对我们的服务有什么了解?