在上一篇文章中,我谈到了Kubernetes, ThoughtSpot如何将其用于自身的开发支持需求。 今天,我想继续讨论一个简短的话题,但是从最近发生的同样有趣的调试历史中可以看出。 本文基于容器化=虚拟化这一事实。 此外,它显示了即使对cgroup进行了最佳限制和实现了较高的计算机性能,容器化的进程也如何竞争资源。
之前,我们在Kubernetes内部集群中启动了一系列与b CI / CD开发相关的操作 。 一切都会很好,但是当您启动“ dockerized”应用程序时,性能突然急剧下降。 我们并不小气:在每个容器中,通过Pod配置设置的计算能力和内存(5 CPU / 30 GB RAM)都受到限制。 在具有此类参数的虚拟机上,我们从微小数据集(10 Kb)进行测试的所有请求都会执行。 但是,在具有72个CPU / 512 GB RAM的Docker&Kubernetes中,我们设法启动了3-4个产品副本,然后刹车开始了。 过去几毫秒内完成的请求现在挂了1-2秒,这导致CI任务管道中的各种失败。 我不得不密切配合调试。
通常,怀疑将应用程序打包在Docker中时会发生各种配置错误。 但是,我们没有发现任何可能导致至少某种程度的速度下降(与裸机或虚拟机上的安装相比)。 一切似乎都是正确的。 接下来,我们尝试了Sysbench软件包中的各种测试。 我们检查了CPU,磁盘,内存的性能-一切都与裸机相同。 我们产品的某些服务存储有关所有操作的详细信息:然后可以将其用于性能分析。 通常,当资源(CPU,RAM,磁盘,网络)短缺时,在某些呼叫中会出现严重的时间故障-因此我们可以找出导致速度下降的确切原因和原因。 但是,在这种情况下没有任何反应。 时间比例与工作配置没有区别-唯一的区别是每个呼叫的速度都比裸机慢得多。 没有任何迹象表明问题的真正根源。 当我们突然发现这一点时,我们准备放弃。
在本文中,作者分析了一个类似的神秘案例,当原理上,两个轻进程在同一台机器上的Docker内部运行时互相杀死,并且资源限制设置为非常适中的值。 我们得出两个重要结论:
- 主要原因在于Linux内核本身。 由于内核中的dentry缓存对象的结构,一个进程的行为大大抑制了对
__d_lookup_loop内核的调用,这直接影响了另一个内核的性能。 - 作者使用
perf来检测内核中的错误。 我们从未使用过的出色调试工具(可惜!)。
perf(有时称为perf_events或perf工具;以前称为Linux性能计数器,PCL)是Linux性能分析工具,可从内核版本2.6.31获得。 用户空间管理实用程序perf可从命令行获得,它是子命令的集合。
它对整个系统(内核和用户空间)进行统计分析。 该工具支持硬件和软件性能计数器(例如hrtimer)平台,跟踪点和动态样本(例如kprobes或uprobes)。 2012年,两名IBM工程师将perf(以及OProfile)视为Linux上两个最常用的性能计数器性能分析工具之一。
所以我们想:也许我们有同一件事? 我们在容器中启动了数百个不同的过程,并且每个过程都有相同的核心。 我们感觉到我们已经袭击了这条小径! 装备了perf ,我们重复了调试过程,最后我们等待着最有趣的发现。
以下是在运行正常(快速)的机器上(左)在容器内(右)运行的ThoughtSpot的前10秒的性能记录。
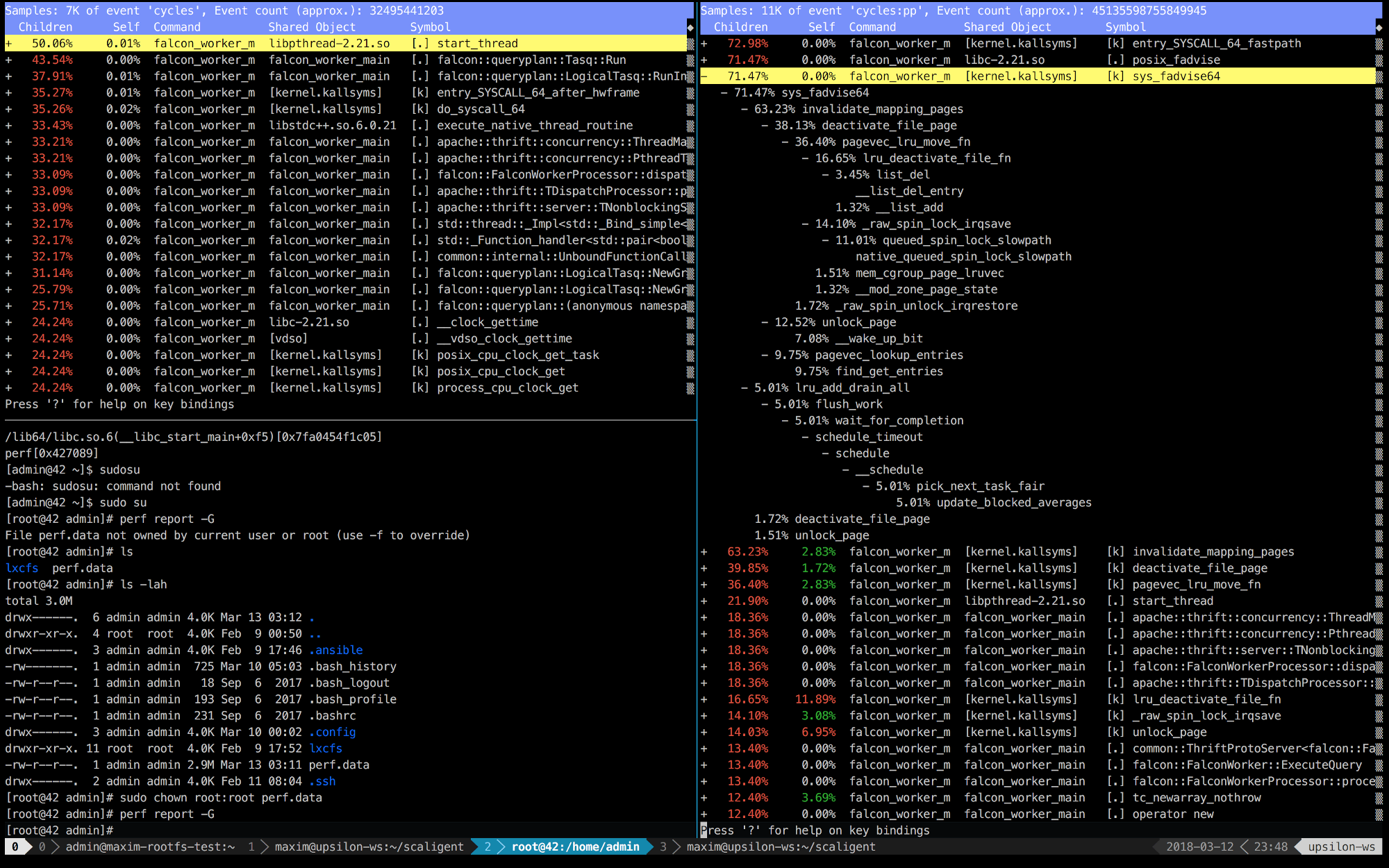
很明显,在右边,前5个调用与内核连接。 时间主要花在内核空间上,而左侧则是大部分时间花在我们在用户空间中运行的进程上。 但是最有趣的是posix_fadvise调用始终花费时间。
程序使用posix_fadvise(),声明将来打算根据特定模式访问文件数据。 这使内核有机会进行必要的优化。
该调用可用于任何情况,因此,它不会明确指出问题的根源。 但是,深入研究代码,我发现只有一个地方在理论上影响了系统中的每个进程:
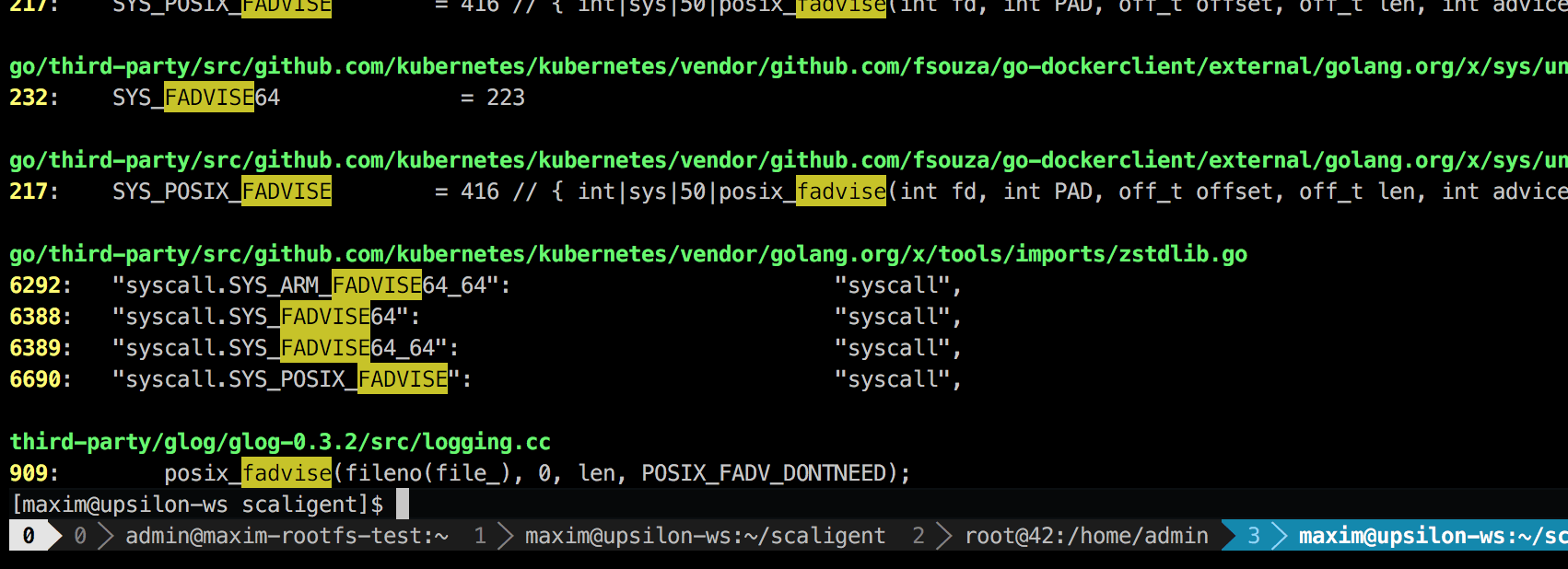
这是一个称为glog的第三方日志记录库。 我们将其用于项目。 具体来说,这一行(在LogFileObject::Write )可能是整个库中最关键的路径。 所有事件都称为“日志到文件”(日志到文件),并且我们产品的许多实例经常记录。 快速查看源代码表明,可以通过设置--drop_log_memory=false参数来禁用fadvise部分:
if (file_length_ >= logging::kPageSize) {
当然,我们做到了,而且……在靶心上!
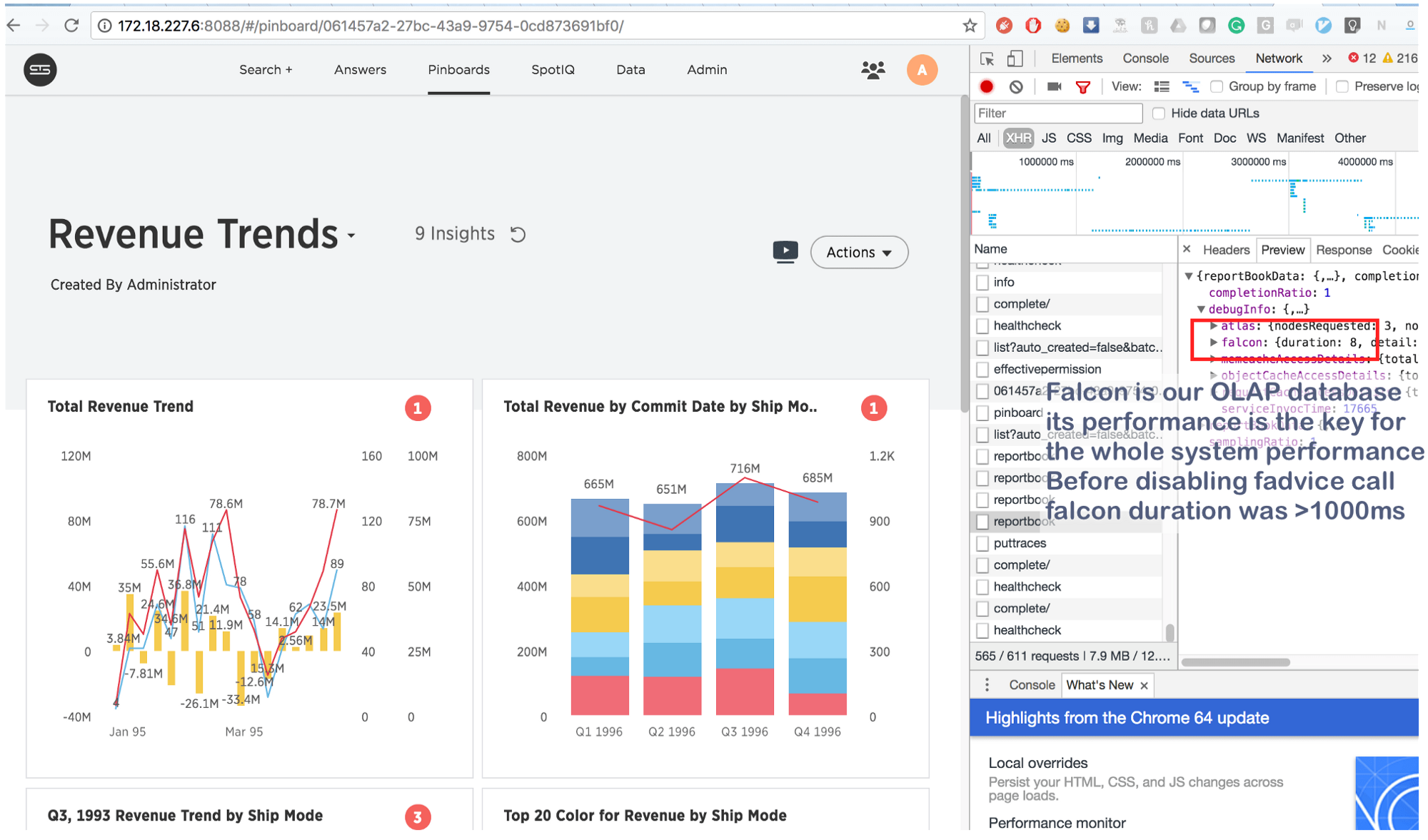
现在以前需要花费几秒钟的时间现在只需8毫秒即可完成。 稍作谷歌搜索,我们发现了这个: https : //issues.apache.org/jira/browse/MESOS-920以及这个: https : //github.com/google/glog/pull/145 ,它再次得到证实我们对抑制的真正原因的预感。 最有可能在虚拟机/裸机上发生了同样的事情,但是由于我们每个机器/内核只有一个进程的副本,因此fadvise调用强度要低得多,这说明没有额外的资源消耗。 将日志记录过程增加了3-4倍,并为它们强调了一个共同的核心,我们看到它确实使fadvise停滞了。
并得出结论:
这些信息并不是什么新鲜事物,但是由于某些原因,很多人忘记了主要的事情:在使用容器的情况下,“隔离的”进程会争夺所有核心资源 ,而不仅仅是争夺CPU , RAM , 磁盘空间和网络 。 而且由于内核是一个极其复杂的结构,因此崩溃可能发生在任何地方(例如, SysSys文章中的__d_lookup_loop中 )。 但是,这并不意味着容器比传统的虚拟化要差或更好。 它们是解决任务的出色工具。 请记住:内核是共享资源,并准备调试内核空间中的意外冲突。 此外,这样的冲突为攻击者提供了一个突破“稀疏”隔离并在容器之间创建隐藏通道的绝佳机会。 最后,还有perf一个出色的工具,它将显示系统中正在发生的事情并帮助调试任何性能问题。 如果您打算在Docker中运行高负载的应用程序,请务必花时间学习perf 。