前几章
学习曲线
28诊断偏差和散布:学习曲线
我们研究了将错误分离为可避免的偏差和分散的几种方法。 我们通过评估最佳误差比例,在算法的训练样本和验证样本上计算误差来做到这一点。 让我们讨论一种更有用的方法:学习曲线图。
学习曲线的图形是误差份额与训练样本示例数量的依赖关系。
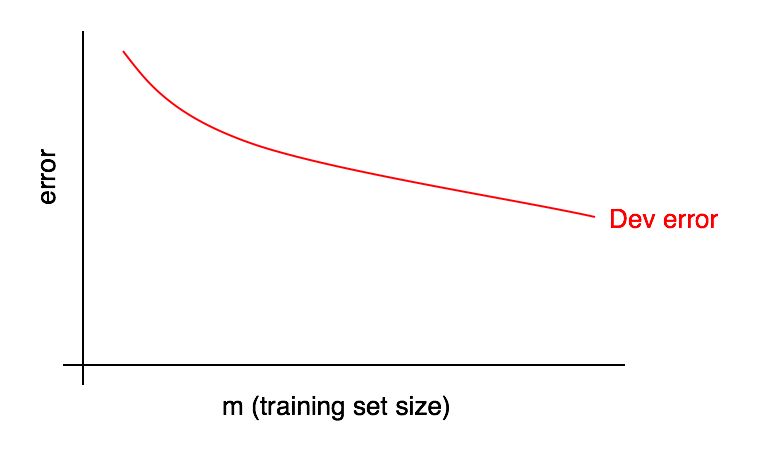
随着训练样本的大小增加,验证样本中的误差应减小。
我们通常将重点放在“希望的错误份额”上,我们希望这些错误最终会到达我们的算法中。 例如:
- 如果我们希望达到人类可以接受的质量水平,那么人为错误的份额应成为“期望的错误份额”
- 如果在某些产品(例如猫咪图像提供商)中使用了学习算法,我们可能会了解您需要达到什么质量水平,以便用户获得最大收益
- 如果您长期从事重要的应用程序开发工作,则可能会对下一个季度/年可以取得的进展有一个合理的了解。
在我们的学习曲线中添加所需的质量水平:

您可以在视觉上推断验证样本中的红色误差曲线,并假设通过添加更多数据可以更接近所需的质量水平。 在图片所示的示例中,训练样本的大小加倍似乎可以达到所需的质量水平。
但是,如果验证样本的误差比例曲线达到平稳状态(即已变为平行于横坐标轴的直线),则立即表明添加其他数据将无助于达到目标:
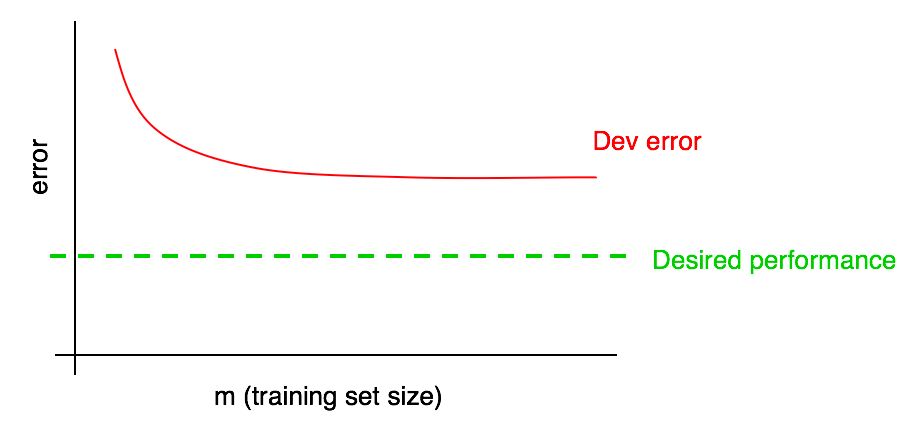
因此,查看学习曲线可以帮助您避免花费数月的时间收集两倍的培训数据,而只是意识到添加数据并没有帮助。
这种方法的缺点之一是,如果仅查看验证样本中的误差曲线,则在添加更多数据时可能难以推断和准确预测红色曲线的行为。 因此,还有另一个图形可以帮助评估附加训练数据对错误比例的影响:学习错误。
29学习错误表
验证(和测试)样本中的错误应随着训练样本的增加而减少。 但是在训练样本中,添加数据的错误通常会增加。
让我们用一个例子来说明这种效果。 假设您的训练样本仅包含两个示例:一张带猫的图片和一张不带猫的图片。 在这种情况下,学习算法可以轻松记住训练样本的两个示例,并在训练样本上显示0%的误差。 即使两个训练示例均未正确标记,该算法也将轻松记住它们的类别。
现在,假设您的训练集包含100个示例。 假设某些示例被错误地分类,或者在某些示例中(例如,在模糊的图像中)甚至当人都无法确定猫是否存在时,也无法建立类别。 假设学习算法仍能“记住”大多数训练样本示例,但是现在要获得100%的准确性更加困难。 将训练样本从2个示例增加到100个示例,您会发现训练样本中算法的准确性将逐渐降低。
最后,假设您的训练集包含10,000个示例。 在这种情况下,算法很难对所有示例进行理想地分类,尤其是在训练集包含模糊图像和分类错误的情况下。 因此,在这样的训练样本上,您的算法效果会更差。
让我们在之前的图中添加学习错误图。
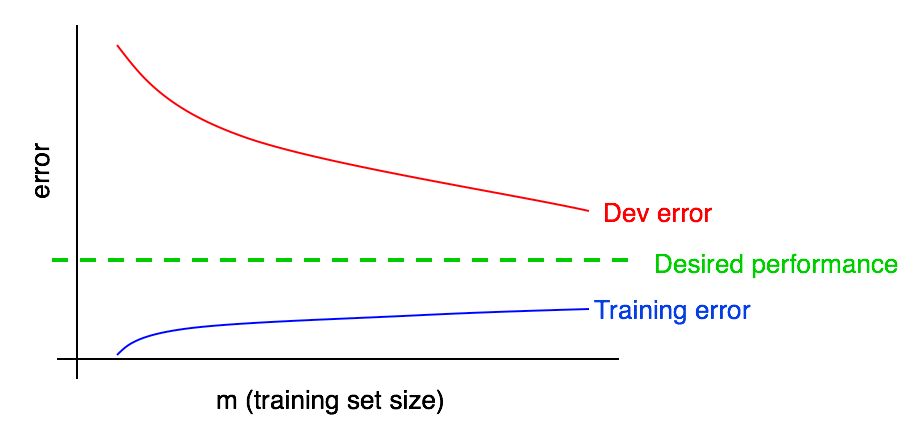
您会看到蓝色的“学习错误”曲线随着训练样本的增加而增加。 而且,一种学习算法通常在训练样本中表现出比在验证算法中更好的质量。 因此,验证样本中的红色误差曲线严格位于训练样本中的蓝色误差曲线上方。
接下来,让我们讨论如何解释这些图。
延续