有如此流行的一类任务,其中有必要对任何信息系统(IS)记录的全部工作链进行充分深入的分析。 作为IP,可以有文档流,服务台,错误跟踪器,电子日记帐,仓库会计等。细微差别体现在数据模型,API,数据量和其他方面,但是解决此类问题的原理大致相同。 您可以踩的耙子也非常相似。
为了解决此类问题,R非常适合。 但是,为了不令人失望地耸耸肩,R可能很好,但是,非常慢,重要的是要注意所选数据处理方法的性能。
它是以前出版物的延续。
通常,表面的“额头”方法不是最有效的方法。 与数据分析和处理相关的任务中有99%从导入开始。 在这篇简短的文章中,我们以对Jira安装数据进行“深度”分析的典型任务为例,考虑在以json格式导入数据的基础阶段出现的问题。 json与csv不同,它支持复杂的对象模型,因此在复杂结构的情况下进行解析会变得非常困难且冗长。
问题陈述
鉴于:
- jira被实现并在软件开发过程中用作任务管理系统和错误跟踪器。
- 没有直接访问jira数据库的权限,而是通过REST API(电隔离)进行交互。
- 要获取的json文件具有非常复杂的树结构,需要使用嵌套元组来上载动作的整个历史记录。 度量的计算需要散布在层次结构不同级别上的参数数量相对较少。
图中常规jira json的示例。
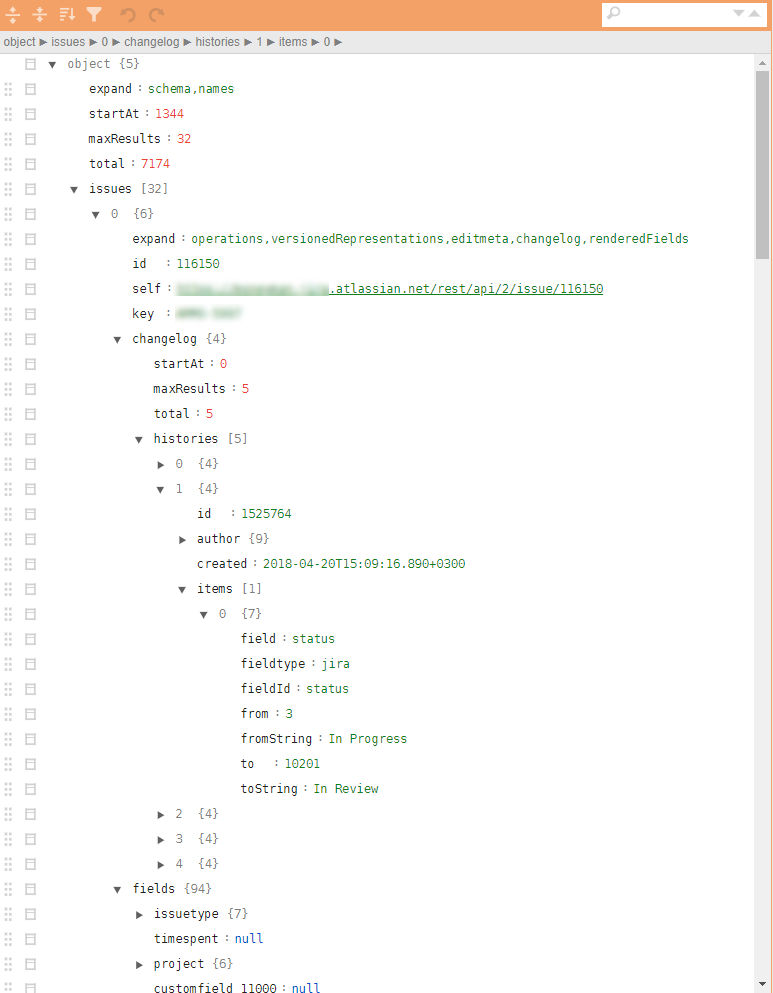
这是必需的:
- 根据jira数据,有必要根据对所有已注册操作的分析,找出可能会提高开发流程效率的瓶颈和要点,并改善最终产品的质量。
解决方案
从理论上讲,R中有几个不同的包,用于加载json并将其转换为data.frame 。 最方便的软件包是jsonlite 。 但是,由于多级嵌套和强大的记录结构参数化,很难将json层次结构直接转换为data.frame 。 与例如动作历史有关的特定参数的抓取可能需要各种扩展。 检查和循环。 即 这个问题可以解决,但是对于32个任务的json文件(包括所有工件和任务的整个历史记录),使用jsonlite和tidyverse进行的非线性分析在平均性能的笔记本电脑上大约需要10秒钟。
仅仅10秒是不多的。 但是恰好直到这些文件没有太多的那一刻。 使用类似的“直接”方法对样本解析和加载进行评估,需要大约4000个文件(〜4 GB),需要8-9个小时的工作。
出现如此大量的文件是有原因的。 首先,jira对于REST会话有时间限制,不可能用束缚拉出所有内容。 其次,期望将其内置到生产电路中,每天上传有关更新任务的数据。 第三,这将在下面提到,该任务对于线性缩放非常好,您需要从第一步开始考虑并行化。
在数据分析阶段甚至10-15次迭代,确定所需的最小参数集,检测异常或错误情况以及开发后处理算法也需要花费2-3周的时间(仅计算时间)。
自然,这种“性能”不适用于生产电路中内置的运营分析,并且在初始数据分析和原型开发阶段非常无效。
跳过所有中间细节,我立即转向答案。 我们回想起Donald Knuth,收起袖子,开始对所有关键操作进行微缩处理,无情地削减一切可能。
最终的解决方案减少到以下10行(这是伪造的骨架,而没有后续的无法正常使用的车身套件):
library(tidyverse) library(jsonlite) library(readtext) fnames <- fs::dir_ls(here::here("input_data"), glob = "*.txt") ff <- function(fname){ json_vec <- readtext(fname, text_field = "texts", encoding = "UTF-8") %>% .$text %>% jqr::jq('[. | {issues: .issues}[] | .[]', '{id: .id, key: .key, created: .fields.created, type: .fields.issuetype.name, summary: .fields.summary, descr: .fields.description}]') jsonlite::fromJSON(json_vec, flatten = TRUE) } tictoc::tic("Loading with jqr-jsonlite single-threaded technique") issues_df <- fnames %>% purrr::map(ff) %>% data.table::rbindlist(use.names = FALSE) tictoc::toc() system.time({fst::write_fst(issues_df, here::here("data", "issues.fst"))})
这里有趣的是什么?
- 为了加快加载过程,最好使用专门的配置文件包,例如
readtext 。 - 使用
jq流解析器可以将所有必要属性的钩子翻译成一种功能语言,将其降低到CPP级别,并最大程度地减少对嵌套列表或data.frame列表的手动操作。 - 出现了一个非常有前途的微
bench套件。 它不仅使您可以研究操作的执行时间,还可以研究内存的操作。 在内存中复制数据会造成很多损失,这已经不是什么秘密了。 - 对于大量数据和简单处理,最终决定中经常有必要放弃
tidyverse并将耗时的部分转移到data.table ,特别是在这里使用data.table合并表。 而且在后处理阶段的所有转换(包括在ff函数循环中的转换)也都使用data.table工具进行,该工具通过按引用更改数据的方式进行处理,或者使用Rcpp构建的程序包,例如用于处理日期和时间的anytime程序包。 fst软件包非常适合将数据转储到文件然后读取。 特别是,仅需花费不到一秒钟的时间即可保存所有的jira历史记录分析4年,并且数据的保存方式与R数据类型完全相同,这对于它们的后续重用非常有用。
在解决方案期间,考虑了使用rjson包的方法。 jsonlite::fromJSON速度比rjson = rjson::fromJSON(json_vec)慢大约2倍,但是有必要保留它,因为数据中有NULL值,并且在rjson的列表中将NULL转换为NA的阶段,我们丢失了优势,代码变得更重。
结论
- 这种重构导致同一台笔记本电脑上单线程模式下所有json文件的处理时间从8-9小时更改为10分钟。
- 实际上,使用
foreach添加任务的并行化并不会增加代码的负担(+ 5行),而是将执行时间减少到5分钟。 - 将解决方案转移到功能较弱的linux服务器(仅4个内核),但是以多线程模式在SSD上运行,将执行时间减少到40秒。
- 在生产电路(20核,3 GHz,SSD)上发布,已将执行时间减少到6-8秒,这对于运营分析任务来说是可以接受的。
总体而言,保留在R平台的框架内,简单的代码重构成功地将执行时间从〜9小时减少到了〜9秒。
关于R的决定可能很快。 如果您无法解决问题,请尝试从另一个角度看待它,并使用新鲜的技术。
以前的出版物- “经理的降落伞” 。