在第一部分中,我们熟悉了通过深度学习进行领域适应的方法。 我们讨论了主要数据集,以及基于差异和对抗的非生成方法。 这些方法可以很好地完成某些任务。 这次我们将分析最复杂和最有希望的基于对抗的方法:生成模型,以及在VisDA数据集上显示最佳结果的算法(从合成数据到真实照片的适应)。

生成模型
这种方法的基础是GAN从必要的分布生成数据的能力。 借助此属性,您可以获得适当数量的合成数据并将其用于培训。 生成模型系列方法的主要思想是使用与目标域代表尽可能相似的源域生成数据。 因此,新的合成数据将基于与原始域相同的标记而获得。 然后,仅在此生成的数据上训练目标域的模型。
在ICML-2018上引入的CyCADA方法:周期一致的对抗域适应 ( 代码 )是生成模型家族的代表成员。 它结合了GAN和域自适应的几种成功方法。 其中重要的一部分是循环一致性损失的使用,这是在CycleGAN的文章中首次介绍的。 周期一致性损失的想法是,从源到目标域生成的图像,然后进行逆变换,应该与初始图像接近。 另外,CyCADA包括在像素级别和矢量表示级别的自适应,以及语义损失,可将结构保存在生成的图像中。
让 和 -分别用于目标域和源域的网络, 和 -目标域和源域, -源域上的标记, 和 -从源到目标域的生成器,反之亦然, 和 -分别属于目标域和源域的区分符。 然后,在CyCADA中最小化的损失函数是六个损失函数的总和(具有损失数的训练方案如下所示):
- -模型分类 源域中生成的数据和伪标签。
- -发电机训练的对抗性损失 。
- -发电机训练的对抗性损失 。
- (循环一致性损失)- -损失,确保从 和 将关闭。
- -矢量表示的对抗损失 和 生成的数据(类似于ADDA中使用的数据)。
- (语义一致性损失)- 损失,对以下事实负责 与从 两者都来自 。
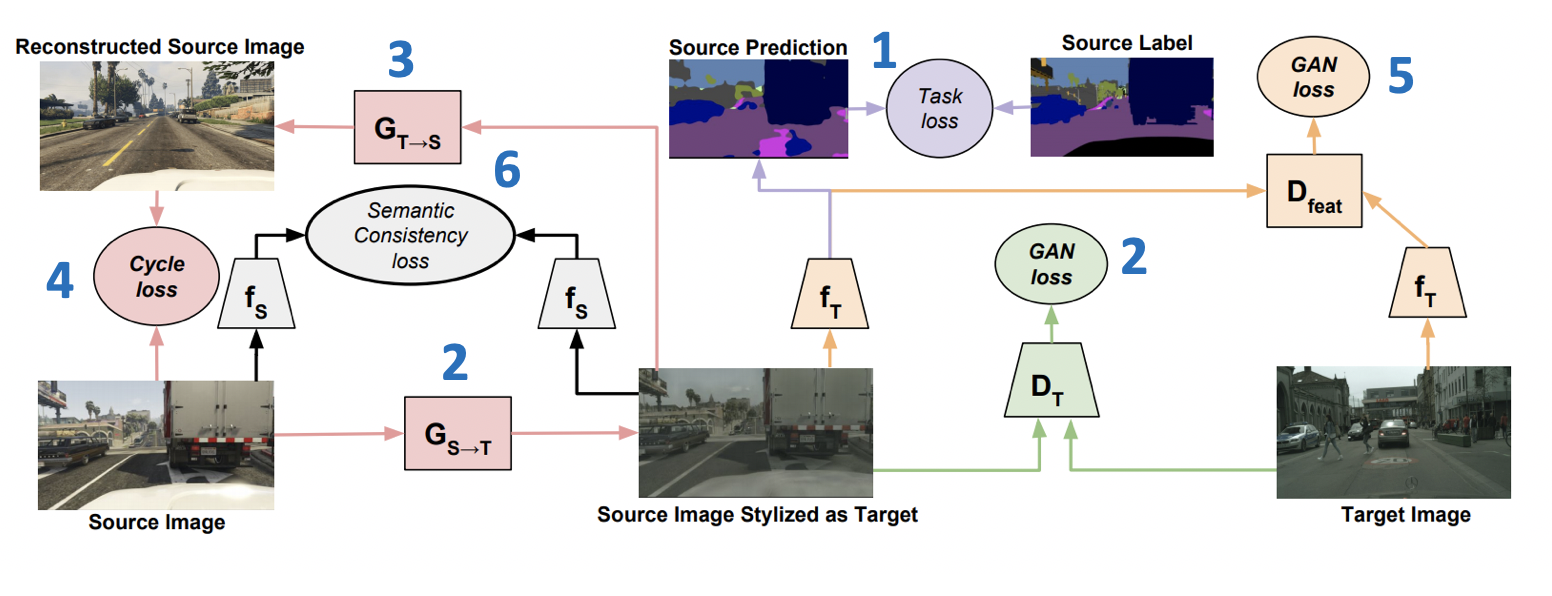
CyCADA结果:
- 在一对USPS数字域上-> MNIST:95.7%。
- 关于细分GTA 5-> Cityscapes的任务:平均IoU = 39.5%。
作为该方法的一部分, 生成适应:使用生成对抗网络 ( 代码 ) 对齐域 (如代码 )训练这样的生成器 以便在输出端产生接近原始域的图像。 这样的 允许您转换来自目标域的数据,并将对源域的标记数据进行训练的分类器应用于它们。
为了训练这样的发电机,作者使用了改进的鉴别器 摘自文章AC-GAN 。 这个的特征 包括以下事实:如果输入来自源域,他不仅回答1,否则回答0,而且在肯定回答的情况下,他根据源域的类别对输入数据进行分类。
我们表示 就像产生图像矢量表示的卷积网络一样, -对源自的向量进行分类的分类器 。 学习和推理算法:
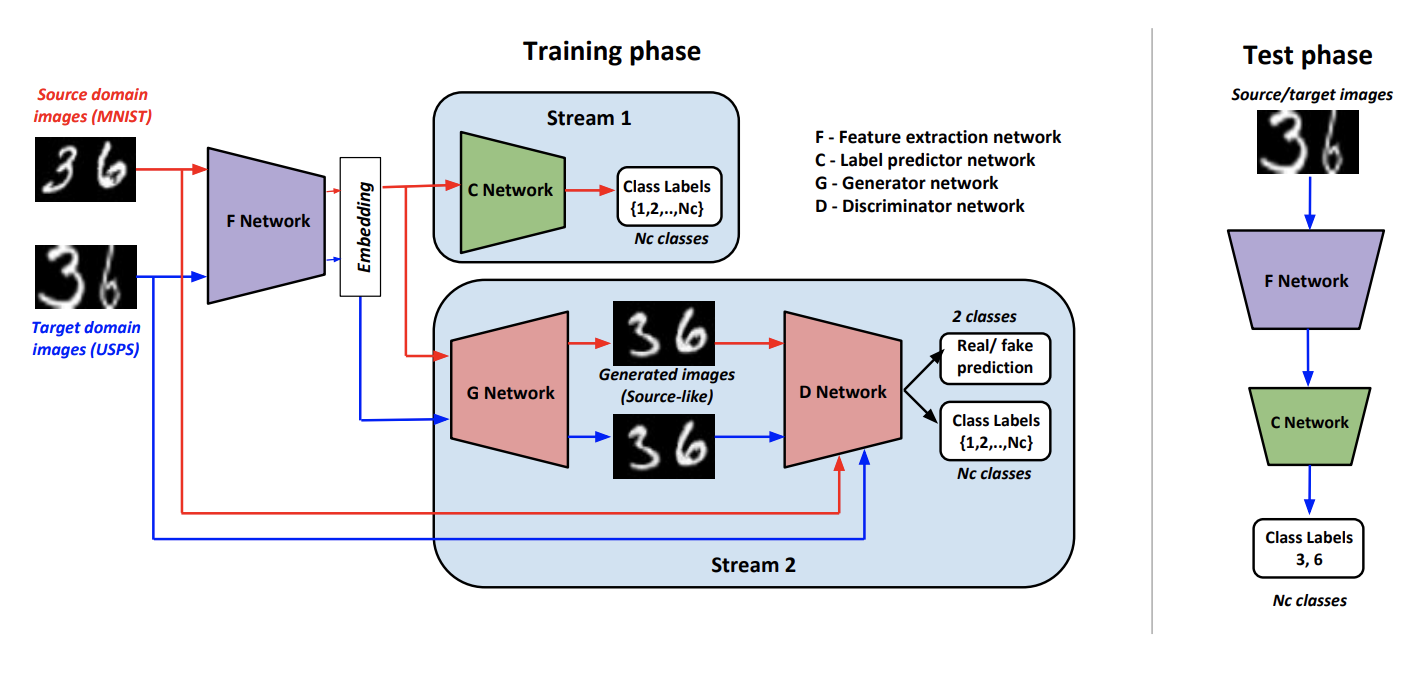
培训过程包括以下几部分:
- 鉴别器 学会确定所有从 数据,并且对于源域,如上所述,仍会添加分类损失。
- 来自源域的数据 结合对抗性损失和分类损失,对其进行训练以生成类似于源域的结果,并正确分类 。
- 和 学习对源域中的数据进行分类。 也 在另一个分类损失的帮助下,进行更改以提高分类质量 。
- 使用对抗损失 学会“作弊” 来自目标域的数据。
- 作者根据经验得出结论,在提交给 连接一个向量是有意义的 具有正常噪声和一类热点矢量( 用于目标数据)。
基准测试方法的结果:
- 在USPS数字域上-> MNIST:90.8%。
- 在Office数据集上,Amazon和Webcam域对的平均适应质量为86.5%。
- 在VisDA数据集上,没有未知类别的12个类别的平均质量值为76.7%。
在“ 从源到目标以及从源到目标:对称双向自适应GAN” ( 代码 )一文中,介绍了SBADA-GAN模型,该模型与CyCADA非常相似,其目标功能(如CyCADA)由6个组件组成。 在作者的符号 和 -从源域到目标的生成器,反之亦然, 和 -区分真实数据和源域和目标域中生成的真实数据的区分符, 和 -根据源域中的数据及其转换为目标域的版本进行训练的分类器。
像CyCADA一样,SBADA-GAN使用CycleGAN,一致性损失和伪标签的思想来处理在目标域中生成的数据,由相应的术语组成目标函数。 SBADA-GAN的功能包括:
- 图像+噪声被馈送到生成器的输入。
- 该测试使用基于变换的目标模型和源模型的预测的线性组合 。
SBADA-GAN培训计划:
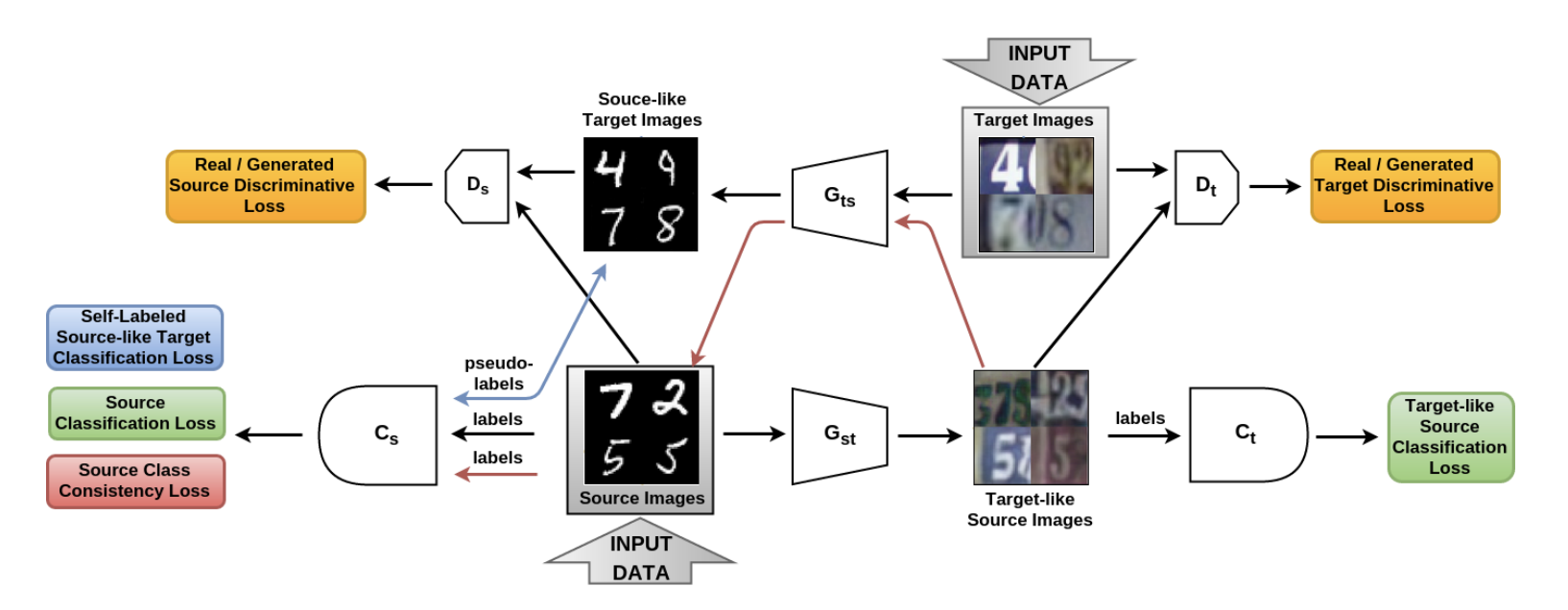
SBADA-GAN的作者进行了比CyCADA的作者更多的实验,并获得了以下结果:
- 在USPS-> MNIST域上:95.0%。
- 在MNIST-> SVHN域上:61.1%。
- 在路标上Synth Signs-> GTSRB:97.7%。
从生成模型家族中,考虑以下重要文章是有意义的:
视觉域适应挑战
作为研讨会的一部分,ECCV和ICCV会议举办了“ 视觉域适应挑战赛”域适应竞赛。 在其中,参与者被邀请在合成数据上训练分类器,并使它适应ImageNet的未分配数据。
VisDA-2017中赢得了针对视觉域自适应的自组装中提出的算法 ( 代码 )。 该方法基于自我组装的思想:有一个教师网络(教师模型)和一个学生网络。 在每次迭代中,输入图像都通过这两个网络运行。 使用分类损失和一致性损失的总和来训练学生,其中分类损失是具有众所周知的班级标签的通常的交叉熵,一致性损失是教师和学生预测之间的平均平方差(平方差)。 教师网络的权重被计算为学生网络权重的指数移动平均值。 此培训过程如下所示。
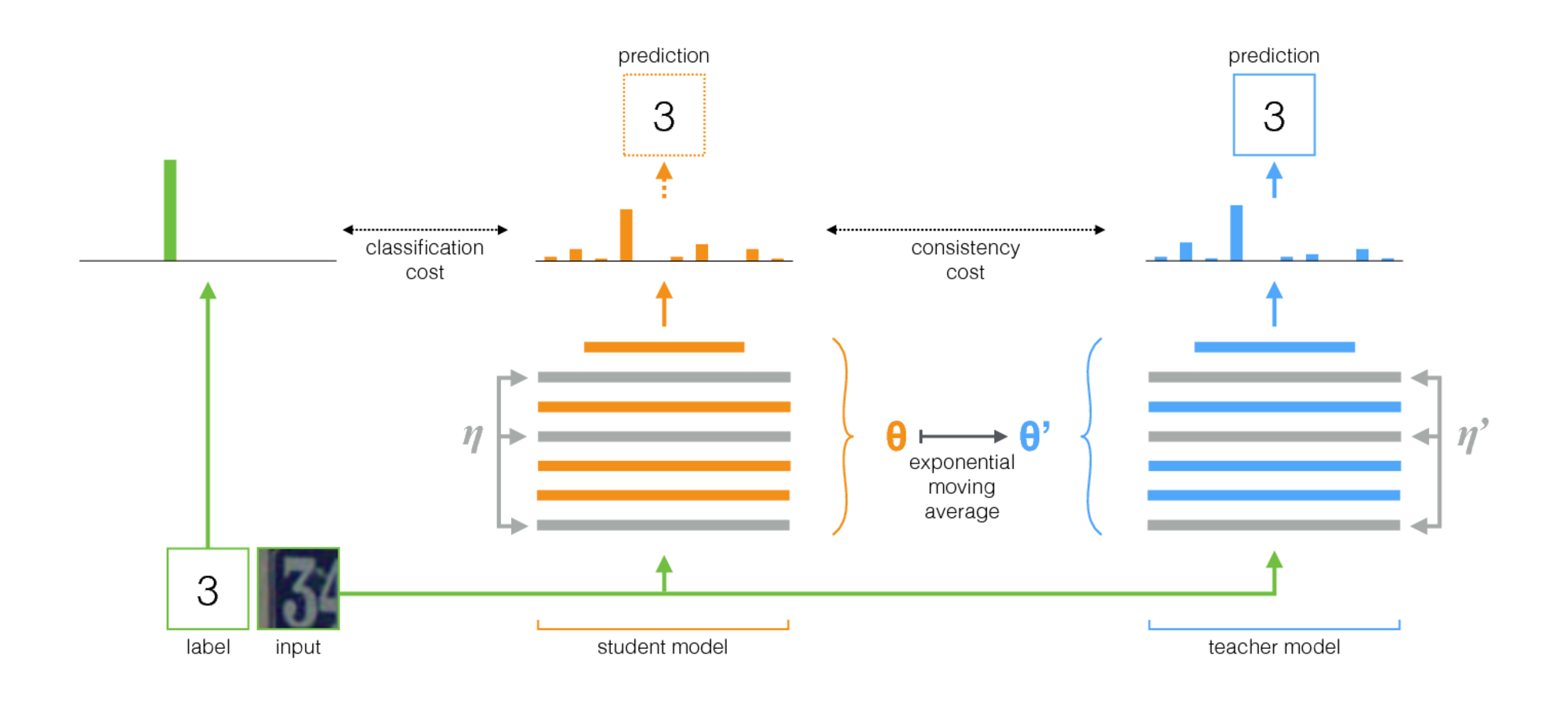
应用此方法进行域自适应的重要特征是:
- 在训练批次中,来自源域的数据被混合 带班级标签 和来自目标域的数据 没有标签。
- 在将图像输入到神经网络之前,会应用各种强大的增强功能:高斯噪声,仿射变换等。
- 这两个网络都使用了强大的正则化方法(例如辍学)。
- -学生网络输出, -网络老师。 如果输入来自目标域,则只有 和 ,交叉熵损失= 0。
- 为了保证学习的可持续性,使用了置信度阈值:如果教师的预测小于阈值(0.9),则一致性损失loss = 0。
所描述程序的方案:

在主要数据集上,该算法实现了高性能。 的确,作者为每个任务分别选择了一组扩充。
- USPS-> MNIST:99.54%。
- MNIST-> SVHN:97.0%。
- 合成编号-> SVHN:97.11%。
- 在路标上Synth Signs-> GTSRB:99.37%。
- 在VisDA数据集上,没有未知类的12个类别的平均质量值为92.8%。 重要的是要注意,这个结果是使用5个模型的集合并使用测试时间增加获得的。
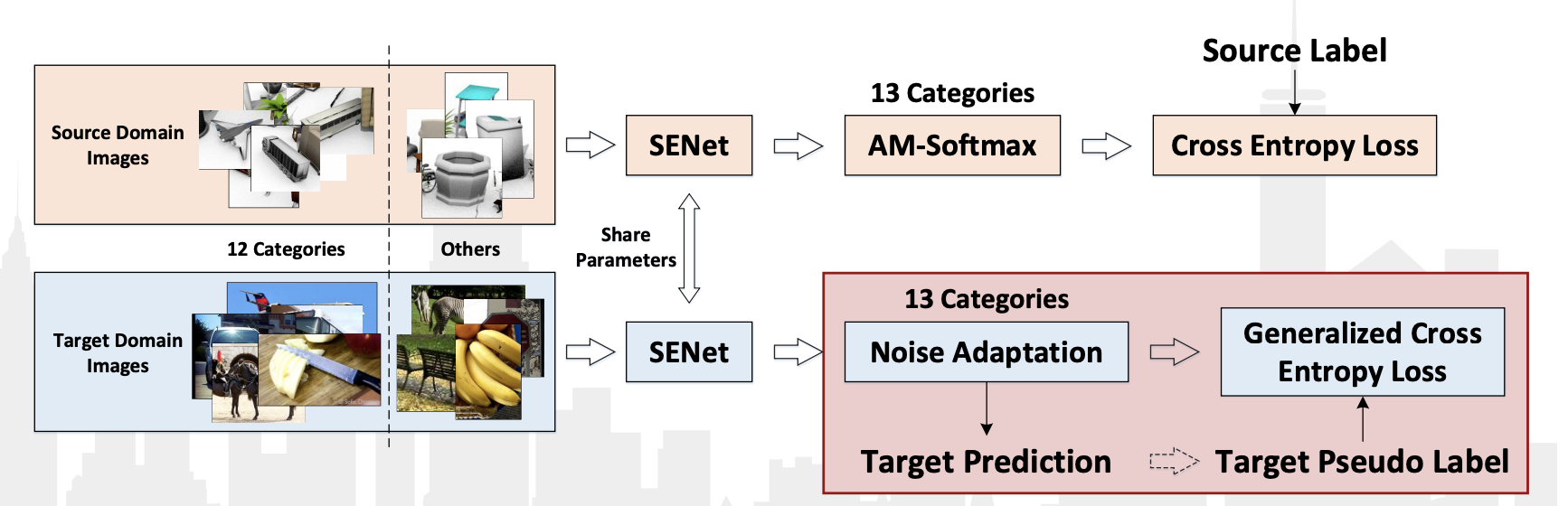
VisDA-2018竞赛是ECCV-2018会议的一部分,于今年举行。 这次他们增加了第13类:Unknown,它获得了所有不属于12类的内容。 此外,还举行了一次单独的比赛来检测属于这12个类别的物体。 在这两个类别中,中国团队JD AI Research均获胜。 在分类比赛中,他们取得了92.3%的成绩(13个类别的质量平均值)。 没有出版物详细说明其方法, 研讨会上只有一个介绍 。
其算法的特征可以指出:
- 对来自目标域的数据使用伪标签,并在其上对来自源域的数据的分类器进行重新训练。
- 使用卷积网络SE-ResNeXt-101,AM-Softmax和噪声适应层,可以对来自目标域的数据进行广义交叉熵损失。
演示中的算法图:
结论
在大多数情况下,我们已经讨论了基于对抗方法的适应方法。 但是,在最近的两次VisDA竞赛中,与之不相关的算法以及使用伪标签训练和更经典的深度学习方法的修改获得了胜利。 在我看来,这是由于基于GAN的方法仍处于开发初期,并且非常不稳定。 但是,每年我们都获得越来越多的新成果,这些成果改善了GAN的工作。 另外,科学界在领域适应领域的兴趣主要集中在基于对抗的方法上,新文章主要研究这种方法。 因此,与GAN相关的算法可能会逐渐适应问题。
但是,基于非对抗方法的研究也在进行中。 以下是该领域的一些有趣的文章:
基于差异的方法可以归类为“历史性”,但是最新方法中使用了许多想法:MMD,伪标签,度量学习等。 另外,有时候在简单的适应问题中,由于这些方法相对容易训练并且结果的可解释性更好,因此应用这些方法是有意义的。
总之,我想指出的是,领域适应方法仍在寻求在应用领域中的应用,但是要求使用适应的预期任务正在逐渐变得越来越多。 例如,领域自适应被积极地用于训练自动驾驶汽车模块 :由于在城市街道上收集真实数据以训练自动驾驶汽车既昂贵又费时,因此自动驾驶汽车尤其使用合成数据(以SYNTHIA和GTA 5数据库为例)。 解决摄像头从汽车“看到”的分割问题。
基于“计算机视觉”的深入培训来获取高质量的模型在很大程度上取决于用于培训的大型标签数据集的可用性。 标记几乎总是需要大量的时间和金钱,这极大地增加了模型以及基于模型的产品的开发周期。
领域自适应的方法旨在解决这个问题,并且可能在许多应用问题和人工智能领域做出突破。 将知识从一个领域转移到另一个领域是一项非常困难且有趣的任务,目前正在积极研究中。 如果您的任务缺少数据,并且可以模拟数据或找到相似的域,那么我建议您尝试使用域适应方法!