速度是专门针对分布式系统的会议。 它是由O'Reilly组织的,每年举行三次,一次在加利福尼亚,一次在纽约,一次在欧洲(城市每年都在变化)。
2018年的会议于10月30日至11月2日在伦敦举行。 Badoo的总公司位于那儿,所以我和我的同事有两个理由选择Velocity。
事实证明,她的装置比我在俄罗斯会议上碰到的装置要复杂得多。 除了通常的两天的演讲外,还有另外两天的培训,这些培训可以全部,部分或全部不参加。 在一起,这变成了认真选择您需要的机票类型的追求。
在这篇评论中,我将谈论我记得的那些报告和大师班。 我将一些其他材料的链接附加到一些报告中。 这些部分是作者提到的材料,部分是我自己发现的需要进一步研究的材料。
会议的总体印象是:作者的表现非常好(主题演讲是整个表演,有演讲者演示音乐并在舞台上进行表演),但与此同时,我遇到了从技术角度来看很深的几篇报道。
这次会议最热门的话题是Kubernetes ,几乎每隔一个报告都会提到它。
与社交网络的合作建立得非常好:在会议期间的官方Twitter帐户中,有许多带有报告的可操作性转发。 这样可以快速查看其他房间的情况。
大师班
10月31日是没有报告的日子,但是有6或8个大师班,每个班有3个小时的纯时间,其中必须选择两个。
PS在最初,它们被称为教程,但是在我看来,将它们翻译为“大师班”是正确的。
混沌工程训练营
演讲人: Ana Medina , Gremlin工程师| 内容描述
该研讨会致力于介绍混沌工程。 Ana熟练地告诉了它什么是它,带来了什么好处,展示了如何使用它,什么软件可以提供帮助以及如何在公司中开始使用它。
总的来说,这对初学者来说是一个不错的介绍,但是我并不真正喜欢实际的部分,即使用Kubernetes在几台机器的群集中部署演示Web应用程序,并从DataDog监视它。 主要问题是,我们花了将近大师课一半的时间在此上,并且只需要玩模拟集群中各种问题的脚本5-10分钟,然后查看图中的变化即可。
在我看来,为了达到相同的效果,它足以访问预先配置的DataDog和/或从场景中演示所有内容,例如,这段时间应该花在更详细的评论和使用相同的Chaos Monkey的示例上,而这恰好是在字面上讨论的。几个短语。


有趣的是:在这次会议上,演讲者经常提到“爆炸半径”一词,这是我以前从未见过的。 他们指定了发生特定问题时受影响的系统部分。
其他材料:
建立进化基础设施
演讲人: 基夫·莫里斯 ( Kief Morris) ,基础架构顾问,《 基础架构》的编写人 | 内容描述
大师班的要点可以简化为两点:
- 系统一直在变化,因此基础架构也需要更改是很正常的。
- 一旦基础架构发生了变化,则需要确保其简单安全,而这只能通过自动化来实现。
他故事的主要部分专门致力于基础架构变更的自动化,针对该问题的可能解决方案以及测试变更。 我不是该主题的专家,但是在我看来,他的讲话非常自信,详细(非常快)。
我从该大师班记得的要点是建议,从代码到环境变量,最大程度地区分环境(生产,暂存等)之间的区别。 这将减少更改环境时基础架构中出现错误的可能性,并使它更具可测试性。



报告书
11月1日和2日是报告的日子。 它们分为两个主要部分:一系列的三到四个简短主题报告,这些报告在早晨以一个流的形式出现(对他们来说,是一个大厅,由两个较小的大厅聚集在一起),而较长的主题报告则以五种流形式出现,并在一天的剩余时间内流传开来。 。 白天,报告之间有几个大停顿,那时可以在会议合作伙伴的展位周围逛逛博览会。
Runtastic后端的演变
Simon Lasselsberger(Runtastic GmbH)| 说明和幻灯片
作者不只是告诉自己如何做,还显示了特定项目的详细信息以及发生了什么事的少数报告之一。
刚开始,Runtastic拥有一个公共的Percona Server数据库和一个带有为移动应用程序和站点提供代码的代码块。 然后他们开始在Cassandra中写(我不记得为什么要写在其中)那部分存储键值足以满足需求的数据。 逐渐地,数据库变得越来越松散,他们添加了MongoDB,并开始在其中向大多数服务写入数据。 随着时间的推移,他们建立了一个通用级别,可以同时满足来自Web和移动应用程序的请求(据我所知,类似于我们的应用程序 )。
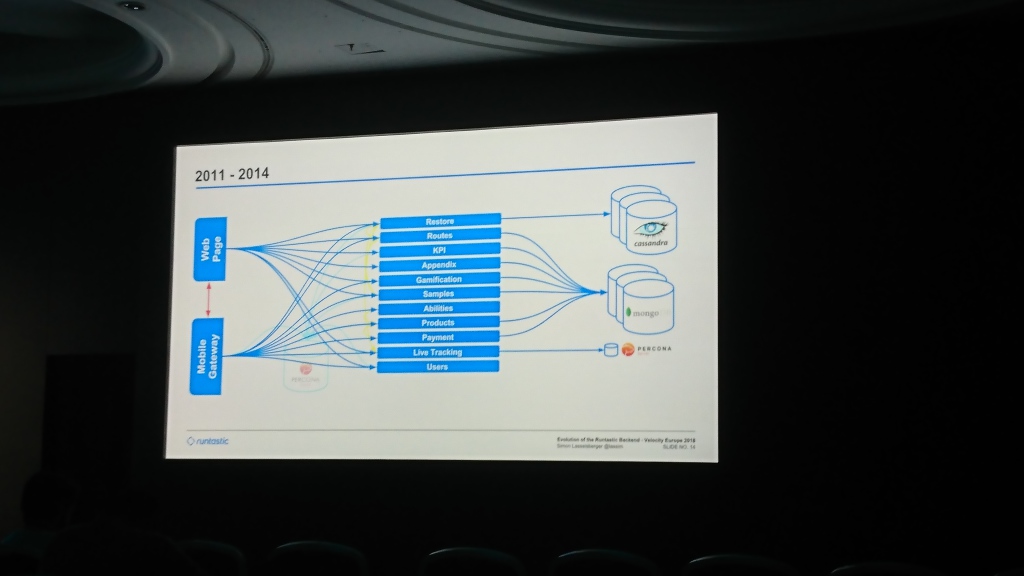
该报告的大部分致力于在数据中心之间转移。 最初,他们将服务器保存在Hetzner中,一段时间后,该服务器被认为不够稳定,数据被迁移到T-Systems。 几年后,他们已经面临空间不足的问题,并再次搬到了Linz AG。 这里最有趣的部分是数据迁移。 他们开始复制持续了几个月的数据。 他们等不及了,因为 它们空间不足,无法添加,因此他们回退了代码,该代码试图从旧数据中心读取数据(如果不在新数据中心中)。
将来,他们计划将数据分成几个单独的数据中心(Simon多次说过,这对于俄罗斯和中国来说是必要的),并严格按照单独的服务划分数据库(现在所有服务都使用一个公共池)。
Simon设计了一种有趣的方法来设计系统中的模块: 六角形体系结构 。
允许应用程序同样由用户,程序,自动测试或批处理脚本驱动,并与最终的运行时设备和数据库隔离地进行开发和测试。
阿利斯泰尔·科克本
其他材料:
监控自定义指标; 或者,我如何学会先进行测试然后再提出问题
马克西姆·佩塔佐尼(SignalFx)| 描述和介绍
这个故事致力于收集理解应用程序所必需的度量。 主要信息是,通常的RED指标(费率,错误和持续时间)完全不够,此外,您还需要立即收集其他有助于理解应用程序内部情况的指标。
摘要,作者建议为系统中的一些重要操作收集计数器和计时器(以及必要的故障计数器),从中建立分布图和直方图,确定用户指标的元模型(以便不同的指标具有相同的必需参数集)并且相同的含义在任何地方都被称为相同)。

用文字复述细节是非常困难的,在演示文稿中查看细节和示例会更容易,该链接位于会议网站的报告页面上。
其他材料:
无服务器如何改变IT部门
保罗·约翰斯顿(Roundabout Labs)| 描述和介绍
作者以CTO和环保主义者的身份自我介绍,他说无服务器不是技术,而是业务解决方案(“如果不使用它,您将无需支付任何费用”)。 然后,他描述了与无服务器一起工作的最佳实践,与他一起工作需要哪些能力以及这如何影响新员工的选择以及与现有员工的合作。

我记得“影响IT部门”的关键时刻是将必要的能力从仅编写代码转移到使用基础结构及其自动化(“更多”的工程是“开发”,而不是“开发”),其他一切都很平庸(您需要不断地进行下去)代码审查,以记录可用于系统的数据流和事件,进行更多的交流和快速学习),但由于某种原因,作者将其归因于无服务器功能。

总体而言,该报告似乎有些复杂。 演讲者谈论的许多事情都可以归因于任何无法完全融入头部的复杂系统。
其他材料:
不要惊慌! 您现在负责生产该如何应对
Euan Finlay(金融时报)| 描述和介绍
如果出现问题,如何处理生产事故的报告。 主要要点按时间分为几个部分。
事发前:
- 通过关键程度区分警报-也许有些可以等待,您无需紧急处理它们;
- 事先准备计划以分析事件,并保持文档为最新;
- 进行练习-打破某些东西,看看会发生什么(又名混沌工程);
- 建立一个有关所有有关变更和问题的信息聚集的地方。
事件发生期间:
- 通常您一无所知-必要时吸引其他人;
- 建立一个单一的位置,以便在解决事件的人员之间进行沟通;
- 寻找可使生产恢复工作状态的最简单解决方案,而不要尝试完全解决问题。
事件发生后:
- 弄清楚问题产生的原因及其对您的影响;
- 重要的是写一份关于此的报告(“事件报告”);
- 确定可以改进的地方并计划具体的行动。
最后,伊万(Ewan)在英国《金融时报》(Financial Times) 上讲了一个有趣的故事,该事件的发生是因为生产基地(称为prod )被错误地修改,而不是预先生产( pprod ),并建议避免使用类似的名称。
从网络生活中学习(主题演讲)
Claire Janisch(BiomimicrySA)| 内容描述
我收到这份报告很晚,但是在Twitter上他们对此表示很好。 您需要查看是否遇到问题。
带有演讲片段的视频可以在会议网站上观看 。
简·亚当斯(两个Sigma投资)| 内容描述
关于“我们可以信任决策算法”主题的哲学报告。 总体结论是:没有:该算法可以优化特定指标,但同时严重影响难以衡量或超出这些指标的范围(例如,在亚马逊招聘员工的算法存在歧视,这对公司的文化产生了负面影响并被迫放弃此算法)。
Kubernetes的自由(主题演讲)
Kris Nova | 内容描述
从那里,我想起了两个想法:
- 灵活性不是自由,而是混乱。
- 如果复杂度本身具有任何值(在最初,它被称为“必需的复杂度”)会超出此复杂度的成本,那么它本身就不是问题。
该报告颇具哲理,因此,一方面,我不能从中受益匪浅,但另一方面,我的经验不仅适用于Kubernetes。

当我们先离线时会有什么变化? (主题演讲)
Martin Kleppmann(剑桥大学),《 设计数据密集型应用程序》的作者 | 内容描述
该报告包括两个逻辑部分:第一,马丁讨论了彼此之间数据同步的问题,可以在多个来源中独立地进行更改;第二,他讨论了可以用于此目的的解决方案和算法( 操作转换 ,OT ,以及无冲突的复制数据类型 (CRDT)),并提出了其解决方案-自动合并库来解决此类问题。
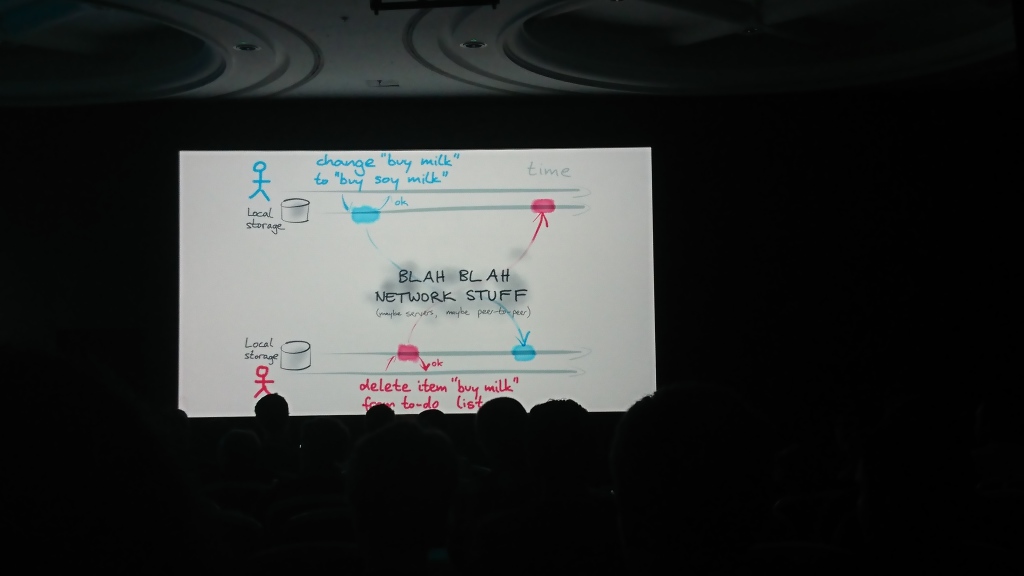


其他材料:
程序员安全连接指南
演讲者: Liz Rice | 说明和幻灯片
该报告以现场编码会议的形式举行,Liz展示了HTTPS的工作原理,使用安全连接时会发生什么错误以及如何解决它们。 没有深度,但是演示本身很好。
最有用的:带有主要错误的幻灯片( 又名Liz在另一次会议上的报告 ):

其他材料:
您想要了解的有关Monorepos的所有信息,但又害怕问
Simon Stewart(硒项目)| 内容描述
该报告的主要论点是,在monorepo中,管理代码中的依赖关系要容易得多,这涵盖了单个存储库的所有优点。 他呼吁谷歌和微软将数据存储在一个存储库中(分别为86 Tb和300 Gb),而Facebook存储库(54 Gb文件)使用“脱壳的做法”。
在“谁在公司中的存储库比员工多的存储库?”问题之后,会议室“爆炸了”。
“使用大型存储库可以缓慢运行”的论点如下:
- 您不必将整个更改历史记录都带到本地计算机上:使用阴影克隆和稀疏签出 ;
- 您不必使用存储库中的所有文件:整理文件的层次结构,仅使用必要的目录,而排除其他所有内容。
其他材料:
构建分布式实时流处理系统
艾米·博伊尔(新遗物)| 描述和介绍
有关使用来自NewRelic的工程师的流数据的好故事(他们显然在处理此类数据方面有很多经验)。 艾米说,它正在处理流数据,如何聚合数据,如何处理滞后数据,如何对事件流进行分片以及在处理器发生故障时如何重新平衡事件,监视什么内容等。
该报告内容丰富,我不会尝试重述,而只是建议您查看演示文稿本身(它已经在会议网站上了)。


电视建筑
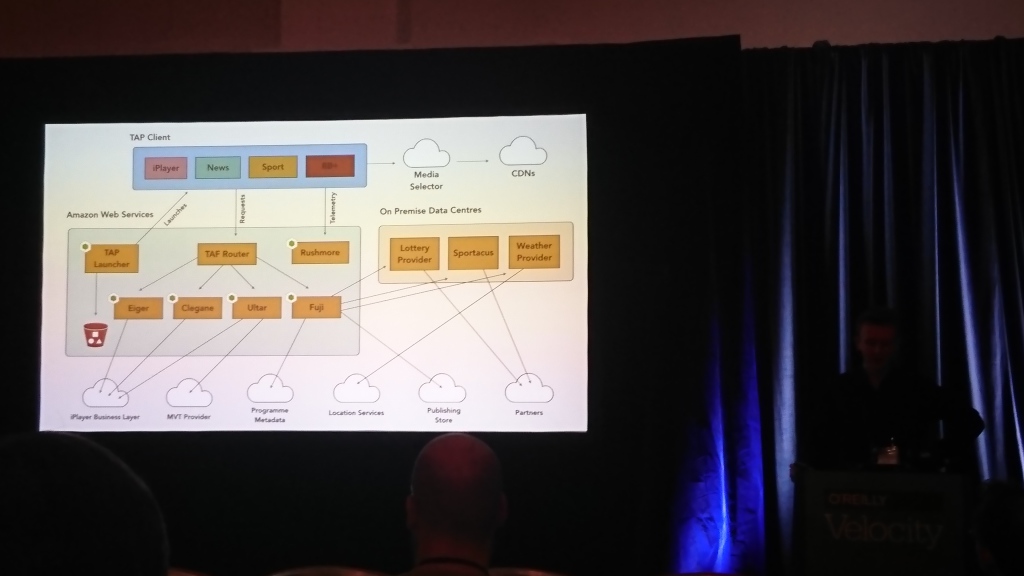
大卫·巴克赫斯特(BBC),罗斯·威尔逊(BBC)| 内容描述
大部分讨论是关于BBC前端的。 这些家伙拥有交互式电视以及可以在其上工作的许多电视和其他设备(计算机,电话,平板电脑)。 您需要以完全不同的方式使用不同的设备,因此他们想出了自己的基于JSON的语言来描述接口并将其转换为特定设备可以理解的内容。
对我而言,主要结论是,与电视用户相比,移动应用程序对老客户而言没有任何问题。