在年初,我们决定学习如何比以前更有效地存储和读取VK调试日志。 调试日志例如是视频转换日志(基本上是ffmpeg命令的输出以及用于预处理文件的步骤列表),有时我们在处理问题文件后仅需要2-3个月。
当时,我们有两种存储和处理日志的方式-我们自己的日志引擎和rsyslog,我们将它们并行使用。 我们开始考虑其他选择,并意识到Yandex的ClickHouse非常适合我们-我们决定实施它。
在本文中,我将讨论我们如何开始在VKontakte上使用ClickHouse,我们踩过的耙子以及KittenHouse和LightHouse是什么。 两种产品都在本文末尾的开源链接中进行了介绍。
日志收集任务
系统要求:
- 存储数百TB的日志。
- 可以存放几个月或(很少)年。
- 高写入速度。
- 读取速度快(很少读取)。
- 索引支持
- 支持长字符串(> 4 Kb)。
- 操作简单。
- 紧凑的存储。
- 可以从成千上万的服务器插入(UDP将是一个加号)。
可能的解决方案
让我们简要列出我们考虑的选项及其缺点:
日志引擎
我们为日志编写的微服务。
-只能给出适合RAM的最后N行。
-不太紧凑的存储(无透明压缩)。
Hadoop的
-并非所有格式都有索引。
-读取速度可能更高(取决于格式)。
-设置的复杂性。
-不可能从成千上万的服务器中插入(需要Kafka或类似产品)。
Rsyslog +文件
-没有索引。
-低读取速度(常规grep / zgrep)。
-架构上不支持的字符串> 4 Kb,UDP甚至更少(1.5 Kb)。
±通过在表冠上对数旋转实现紧凑的存储
我们将rsyslog用作长期存储的备用,但是长行被截断了,因此很难称其为理想的。
LSD +文件
-没有索引。
-低读取速度(常规grep / zgrep)。
-不是专门为从成千上万的服务器插入而设计的。
±通过在表冠上对数旋转实现紧凑的存储。
在我们的案例中,与rsyslog的区别在于LSD支持长字符串,但是要插入成千上万的服务器,需要对内部协议进行重大更改,尽管可以做到。
弹性搜索
-操作问题。
-录制不稳定。
-没有UDP。
-压缩不良。
ELK堆栈已经几乎是日志存储的行业标准。 根据我们的经验,读取速度一切都很好,但是例如在合并索引时,书写就有问题。
ElasticSearch主要设计用于全文搜索和相对频繁的读取请求。 对于我们而言,准确的巧合是,稳定的记录和或多或少地快速读取我们的数据的能力更为重要。 ElasticSearch上的索引经过了锐化,可以进行全文搜索,并且与原始内容的gzip相比,其磁盘空间很大。
Clickhouse
-没有UDP。
总的来说,ClickHouse唯一不适合我们的是缺少UDP通信。 实际上,在以上选项中,只有rsyslog拥有,但是rsyslog不支持长行。
根据其他条件,ClickHouse提出了建议,我们决定使用它,并且在此过程中解决了运输问题。
为什么需要KittenHouse
您可能知道,VKontakte在PHP / KPHP上工作,在C / C ++中带有“引擎”(微服务),在Go上也有一点。 除了共享内存和开放连接之外,PHP在请求之间没有“状态”的概念。
由于我们有成千上万的服务器,希望从这些服务器将日志发送到ClickHouse,因此保持每个PHP工作者的开放连接(每个服务器可以有100多个工作者)是无利可图的。 因此,我们需要ClickHouse和PHP之间的某种代理。 我们称这个代理为KittenHouse。
小猫屋v1
首先,我们决定尝试使用最简单的方案来了解我们的方法是否行得通。 如果在解决这个问题时想到卡夫卡,那么您并不孤单。 但是,我们不想使用其他中间服务器-在这种情况下,我们可以轻松地依靠这些服务器的性能,而不是ClickHouse本身的性能。 此外,我们收集了日志,并且需要在数据插入方面进行可预见的且小的延迟。 该方案如下:

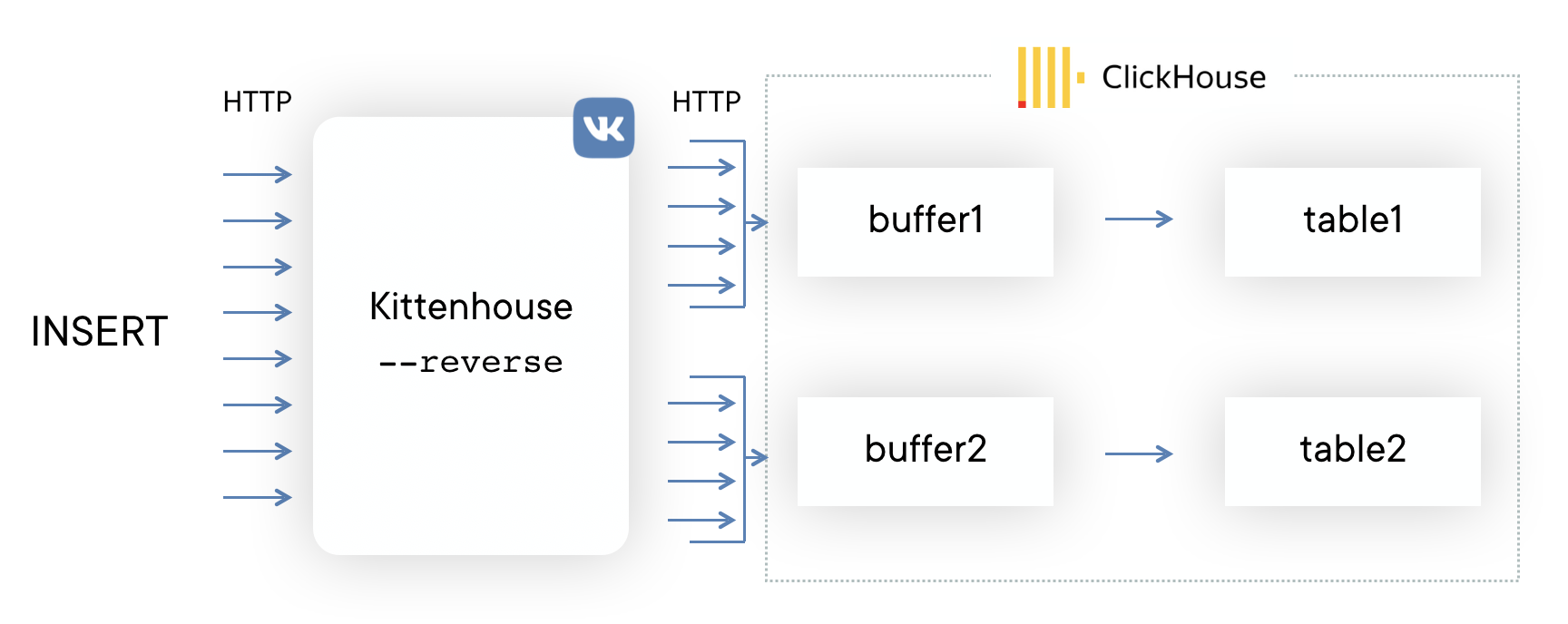
在每个服务器上都安装了本地代理(小猫),每个实例与必要的ClickHouse服务器严格保持一个HTTP连接。 粘贴是在假脱机表中完成的,因为通常不建议插入MergeTree。
特色KittenHouse,v1
KittenHouse的第一个版本知道很多,但这足以进行测试:
- 通过我们的RPC(TL计划)进行通信。
- 每个服务器维持1个TCP / IP连接。
- 默认情况下,内存中缓冲的缓冲区大小有限(其余部分将被丢弃)。
- 写入磁盘的能力,在这种情况下,保证了交付(至少一次)。
- 插入间隔是每2秒一次。
第一个问题
当我们“偿还” ClickHouse服务器几个小时然后重新打开它时,我们遇到了第一个问题。 在下面,您可以看到服务器“上升”后的平均负载:
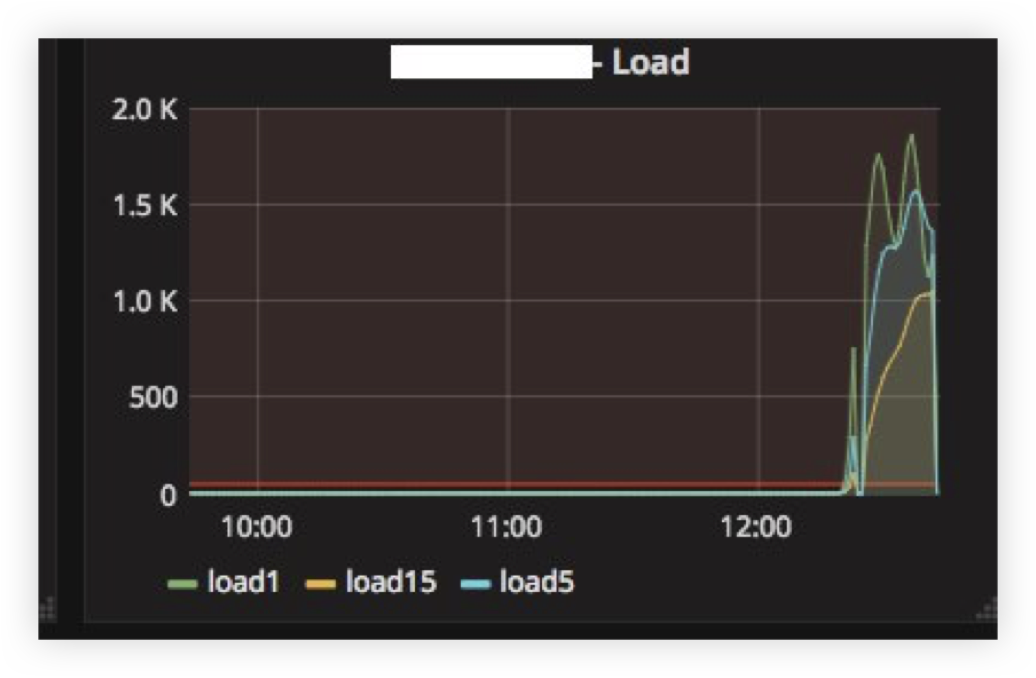
解释很简单:ClickHouse每个线程模型都有一个网络,因此当我尝试同时从数千个节点进行INSERT时,对CPU资源的竞争非常激烈,服务器几乎没有响应。 但是,所有数据最终都插入了,什么也没掉。
为了解决这个问题,我们将nginx放在ClickHouse的前面,总的来说,它有所帮助。
进一步发展
在操作过程中,我们遇到了许多问题,主要与ClickHouse无关,而与我们的操作方式有关。 这是我们踩到的另一把耙子:
大量的“块”缓冲区表导致MergeTree中频繁的缓冲区刷新
在我们的例子中,有16个缓冲区和每2秒重置一次间隔,并且有20个表,每秒最多可提供160个插入。 这会定期严重影响插入性能-后台合并很多,磁盘利用率达到80%或更高。
解决方案:增加默认的缓冲区重置间隔,将块数减少到2。
当连接到上游端时,Nginx返回502
这本身不是问题,但是结合频繁刷新缓冲区,在尝试插入任何表以及尝试执行SELECT时,这会产生相当高的502错误背景。
解决方案:他们使用
fasthttp库编写了反向代理,该库将插入分组到表中,并且非常经济地使用了连接。 它还可以区分SELECT和INSERT,并具有用于插入和读取的独立连接池。
密集插入会耗尽内存
fasthttp库有其优点和缺点。 缺点之一是在将控制权交给请求处理程序之前,请求和响应已在内存中完全缓冲。 对我们来说,这导致这样一个事实,即如果向ClickHouse插入“没有时间”,则缓冲区开始增长,最终服务器上的所有内存都用完了,这导致OOM杀死了反向代理。 同事们提了一个动力:
 解决方案:
解决方案:修补fasthttp以支持流式传输POST请求的内容原来是一项艰巨的任务,因此,如果请求带有KITTEN HTTP方法,我们决定使用Hijack()连接并将连接升级到我们的协议。 由于服务器必须作为响应来回复MEOW,因此如果服务器理解此协议,则整个方案称为KITTEN / MEOW协议。
我们一次只能读取50个随机连接,因此,由于使用了TCP / IP,其余的客户端“等待”,并且在队列到达相应的客户端之前,我们不会在缓冲区上花费内存。 这将内存消耗减少了至少20倍,而且我们再也没有此类问题。
如果查询很长,ALTER表可能会变长
ClickHouse具有无阻塞的ALTER,因为它既不会干扰SELECT查询也不会干扰INSERT查询。 但是,ALTER在完成对在ALTER之前发送的该表的查询执行之前,无法启动。
如果您对服务器上的任何表进行“长时间”查询,那么您可能会遇到这种情况,即该表上的ALTER没有时间在默认的60秒超时时间内执行。 但这并不意味着ALTER将失败:它将在这些SELECT查询完成后立即执行。
这意味着您不知道ALTER实际发生在什么时间,并且您无法自动重新创建Buffer表,因此它们的布局始终相同。 这可能会导致插入问题。

 解决方案:
解决方案:因此,我们计划完全放弃使用缓冲区表。 通常,缓冲表具有作用域,到目前为止,我们一直在使用它们,并且不会遇到巨大的问题。 但是现在我们终于到了要点,在反向代理服务器上实现缓冲区表的功能比继续克服它们的缺点要容易得多。 示例电路如下所示(虚线显示了INSERT上的ACK异步)。

读取数据
假设我们找出了插入内容。 如何从ClickHouse读取这些日志? 不幸的是,我们没有找到任何方便且易于使用的工具来从ClickHouse读取原始数据(没有图形等),因此我们编写了自己的解决方案-LightHouse。 它的功能相当适中:
- 快速查看表内容。
- 过滤,分类。
- 编辑SQL查询。
- 查看表结构。
- 显示使用的大约行数和磁盘空间。
但是,LightHouse速度很快,能够满足我们的需求。 这是几个屏幕截图:
查看表结构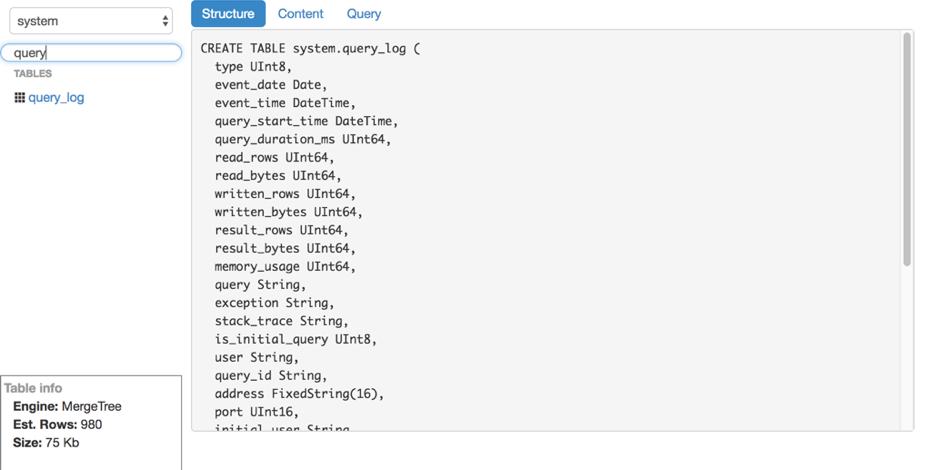 内容过滤
内容过滤
结果
ClickHouse实际上是唯一在VKontakte扎根的开源数据库。 我们对它的工作速度感到满意,并准备弥补缺点,下面将对此进行讨论。
工作困难
总而言之,ClickHouse是一个非常稳定且非常快速的数据库。 但是,与任何产品一样,尤其是年纪轻轻的产品,需要考虑作品中的某些功能:
- 并非所有版本都同样稳定:不要在生产中直接升级到新版本,最好等待几个bugfix版本发布。
- 为了获得最佳性能,强烈建议根据说明配置RAID和其他一些东西。 最近有报道称这是高负荷的 。
- 复制没有内置的速度限制,如果您不自己对其进行限制(但他们承诺会对其进行修复),则可能导致服务器性能显着降低。
- Linux具有虚拟内存机制的令人不快的功能:如果您主动写入磁盘并且没有足够的时间刷新数据,则在某个时候服务器完全“进入自身”,开始主动将页面缓存刷新到磁盘并几乎完全阻塞ClickHouse进程。 大型合并有时会发生这种情况,您需要监视此情况,例如,自己定期刷新缓冲区或进行同步。
开源的
KittenHouse和LightHouse现在可以在我们的github存储库中以开源形式使用:
谢谢你
Yuri Nasretdinov,VKontakte后端基础架构部门的开发人员