零售业拥有广泛的客户群。 其中有很多-从年轻人到老年人的各种职业和收入水平。 不能用两个或三个业务规则正确地描述这种变化,因为您根本无法涵盖所有标准组合,并且不可避免地会失去一些客户。 因此,对于零售而言,尽可能准确地细分受众群体非常重要,但这不可避免地会使模型复杂化。 机器学习技术可以为企业提供帮助,从而为企业提供更准确的预测和重要问题的答案。
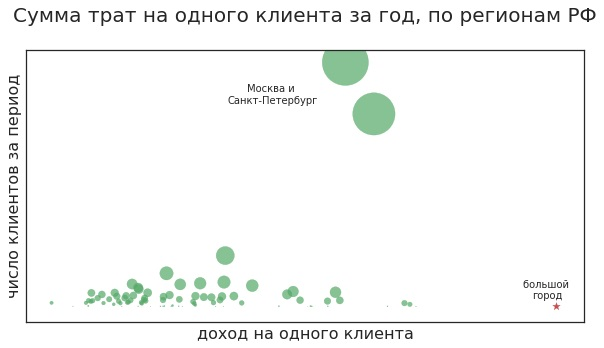
你是什么意思 例如:客户会离开吗? 如果商店没有正确的产品,顾客通常会离开。 例如,一个女人每月花一万卢布购买一种特殊的乳霜,并且可以从两家化妆品店中选择。 在其中一个中,经常缺少所需的产品,而在第二个中,可用性没有问题。 她很有可能会在第二次购买中不断购买,尽管价格会更高一些。
另一个紧迫的问题:如何优化员工的工作? 例如,您需要计划收银员和销售顾问的工作班次。 一种方法涉及使用统计分析。 分析师根据一周中的一天来评估客户的活动,发现在星期六他们购买最多,而在星期五和星期日则少一些。 通过统计检验来检验该假设,并将结论传递给管理层。
但是这样的分析可能没有考虑多种因素的组合。 例如,如果3月7日是星期三-他们在这一天的购买量是否会比星期五多(毕竟,在正常情况下,星期五比其他工作日更受欢迎)? 和毕业? 还是当地假期? 因素越多,在简单规则的帮助下将它们全部考虑在内就越困难。 您可以构建一个模型来预测特定日期的需求,而不是使规则无限复杂化。
我们的非食品零售项目
在这种情况下,有必要分析客户群(约250万人),并预测在接下来的两周内将有哪些人返回商店。 我们采用了CatBoost库的两种方法-CatBoostClassifier和CatBoostRegressor,第一种方法用于预测受众的构成,第二种方法用于选择接下来两周内最受欢迎的产品。 CatBoost在我们项目的开始就出现了,这是使用分类属性的一种新方法。 并且由于我们客户的产品范围包含许多分类功能,因此我们很乐意尝试新产品。 选择参数后,该模型可通过准确的预测立即达到我们的期望。 难怪CatBoost是当今最受欢迎的梯度增强模型之一。
对于该模型,我们采用了2017年的统计数据:
- 支票:谁拥有支票中的红利卡,购买时,购买的物品,折扣大小,购买或退款。
- 人口统计学:客户的居住地区和城市,出生日期和性别,同意通过电话或邮件邮寄。
- 产品:哪个类别或细分包括购买,范围等。
我们清除了噪音数据(卖家的卡,退货,购买服务而不是商品),并计算了必要的标准(折扣百分比,年龄)。 之后,我们计算出每个客户的最大和最小收益,平均,中位数和最大折扣,一个人进来多少次以及他从哪个类别购买了多少产品。 这些参数按时间间隔计数:上周,两周,一个月,三个月。 如此细致的工作使得建立具有高预测精度的模型成为可能。
模型和启动计算的汇总数据。 第一个模型预测了接下来的两周内将有哪些购买者,第二个模型提出了建议:特定人将购买什么产品(达到商品水平)。 顺便说一句,预测特定文章的受欢迎程度的要求使任务复杂化(通常,业务需要根据商品的类别和名称而不是职位来进行预测)。
该模型推荐的针对目标邮件的客户在一次访问中的支票中位数更大,在分析期间内,他们购买的总金额高于其他客户。
结果,邮寄后,大约30%的客户购买了该模型预测的三种产品中的至少一种。
现在,公司可以更准确地预测销售额:零售商知道不久的将来会有谁来找他,以及会买到什么。 这不仅有助于优化物流,还可以降低相关成本。 例如,如果特定客户通常在冬天不买东西,那么您就不必在一月份向他发送SMS。 模型还优化了邮件:基于预测的专家会立即了解谁应该发送电子邮件以及向谁发送电子邮件(紧急SMS)。
陷阱
他们从事任何ML任务-他们属于我们的任务。 例如,我们测试了产品推荐邮件是否有助于增加销售额。 为此,将预测的客户群分为三组:
- 控制-未收到新闻通讯。
- 与提醒分组-从商店收到通用文本。
- 与建议分组-收到SMS以及该模型预测的三种特定产品。
事实证明,收到建议的人购买的商品少于没有收到新闻通讯的顾客。 平均账单和购买的商品数量较少。 T检验表明差异具有统计学意义(p值= 0.017)。
坦率地说,这样的结果使每个人都感到沮丧。 他们开始寻找原因,发现商店向特定信使中的客户发送消息,而我们细分市场中的用户最初购买的商品少于其他顾客。 甚至客户的营销人员也对此一无所知。 因此,实验证明是不正确的,但是根据其结果,我们在模型中添加了参数“ messenger user”。 该案例演示了如何谨慎选择与客户进行沟通的渠道。
还有什么其他结论?
- 没有太多数据。
- 有时,分析师从侧面的观点会导致一个新主意。
客户细分
数据分析使您可以检测以前可用信息中隐藏的模式。 一个很好的例子是比较使用RFM细分(新近频率货币)和使用ML算法进行细分的客户群体。
RFM细分使用三个关键指标:
根据这些数据,可以区分主要类别:“挥霍者”,“忠实客户”,“几乎失去的客户”等。 营销人员已经在特定的新闻通讯中包含了所需的目标人群,或者专门为此人群提供了报价。
例如,使用RFM细分,您可以选择客户细分并将其表示为三维空间中的点:
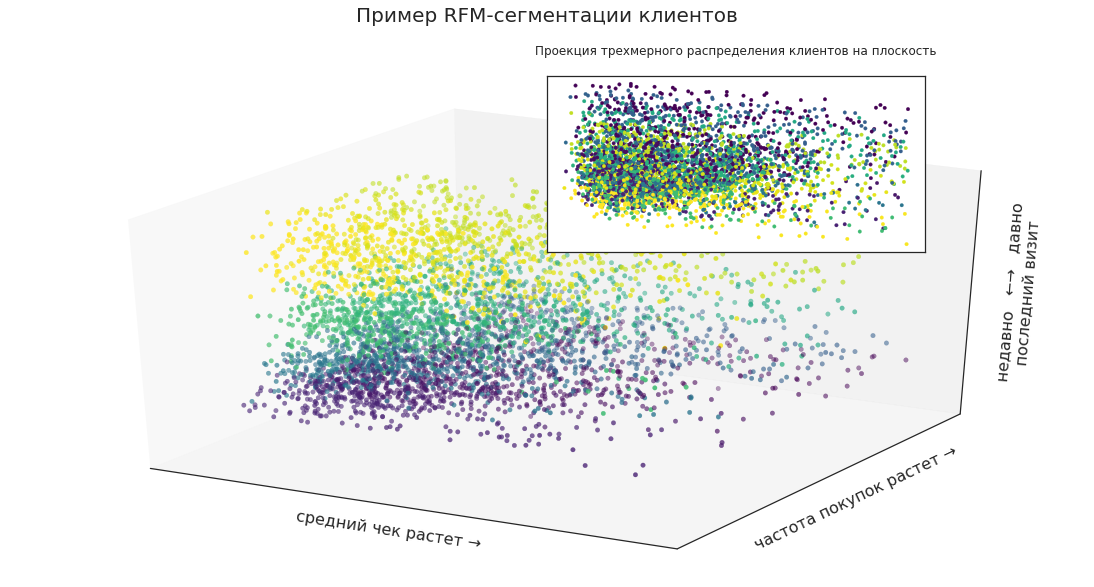
这样,您就可以直观地看到某些组在客户总数中的位置,它们的比例以及变化的动态。
现在,在平面上投影线段的三维分布。 客户可以除以公司带来的收入,将最赚钱的收入包括在营销活动中,但这是否足以进行有效的计划?
即使在这样的数据中,机器学习算法也发现了其他可能性:它将客户划分为新的大型群体。 您可以分析此分区,以找出算法为何以这种方式划分客户端。 例如,一些高利润客户是陪同客户购物并使用折扣卡的专家。 有些人积极与朋友和熟人分享他们的卡。 也就是说,在首次使用ML之后,您可以基于所有相同数据获取有关客户的其他信息。
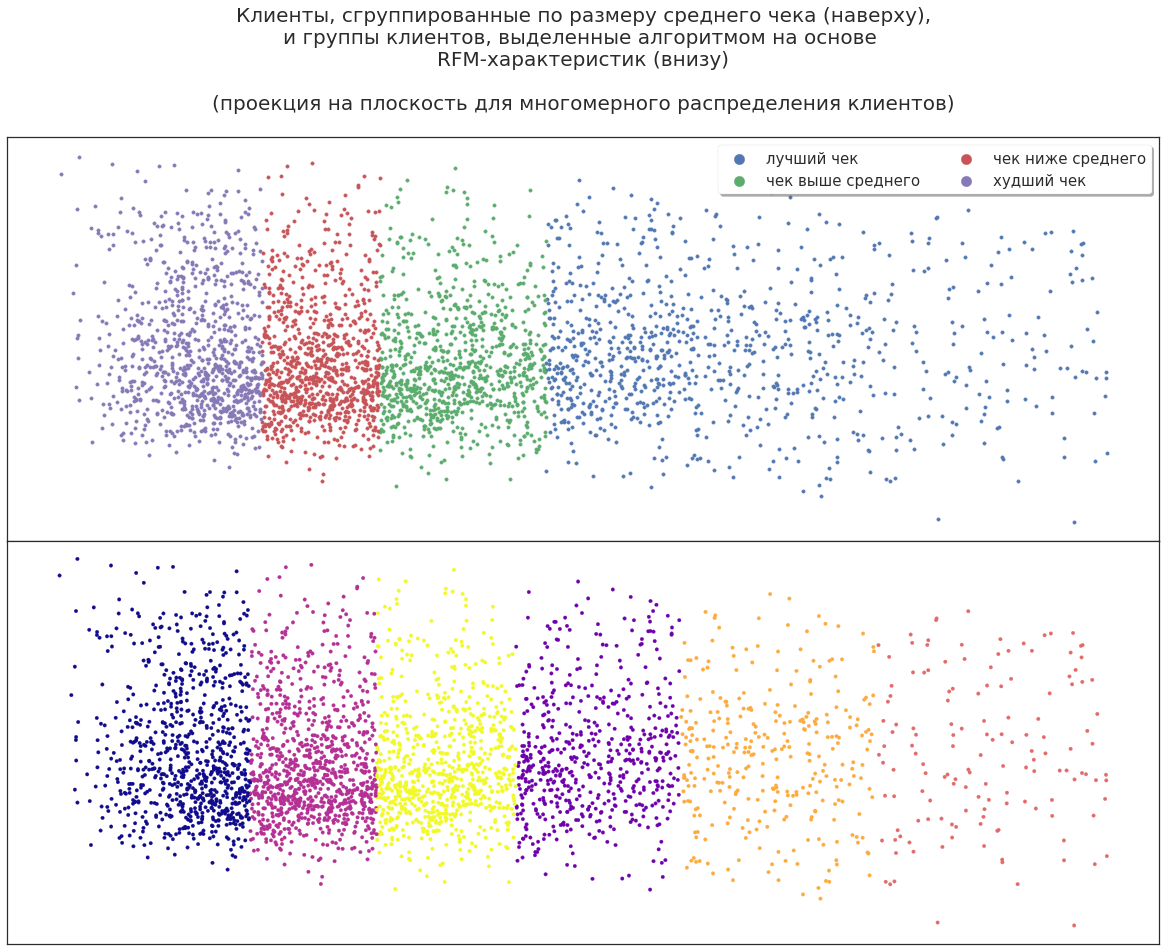
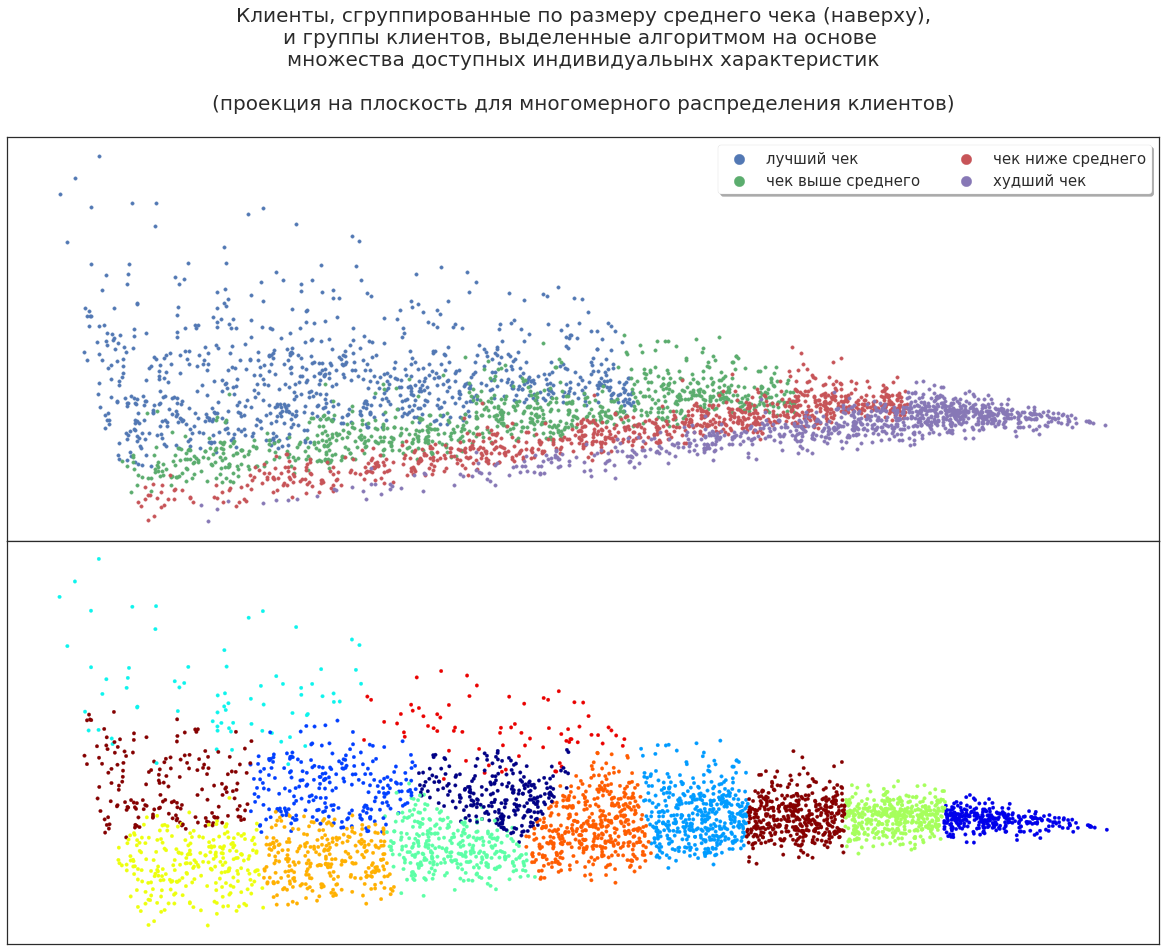
让我们扩展客户特征集:添加性别,年龄,行为等。 现在该算法将如何分配买家?
例如,有一个涵盖最佳客户(最赚钱的客户)及其“邻居”的群体,这带来了较少的利润。 为什么算法分配了这个组是分析师的一个问题。 也许这些受到其他刺激的客户将显示出更大的盈利能力。 或者,相反,这些客户并不是特别有前途,盈利能力的提高是一个随机的偏差-刺激他们也毫无意义。 可以提出各种理论,但是必须进行实验验证。
仓库计划-销售预测
此外,该项目有几个开发选项。 例如,您可以预测下一个时期在特定商店中的购买情况。 然后,商店管理员将能够按时从中央仓库订购必要的商品。
对特定商店的购买进行分析将有助于制定陈列窗上的商品陈列。 例如,如果有很多男性购买者来商店,则不应将男性产品部门放在遥远的角落。
不要忘记所谓的商店蚕食。 也就是说,如果附近有同一网络的两个销售点(例如,在同一条街道的不同末端),则其中一个可以将顾客拉走,而第二个将处于闲置状态。 您可以构建一个模型来跟踪此类现象并发出信号。
***
简而言之,机器学习是可以做很多事情的强大工具。 通常在构建模型时,会发现甚至企业用户都不知道的非显而易见的模式。 但是,模型的质量很大程度上取决于数据的质量和数量。
Jet信息系统软件开发和实施局的分析师