负载测试的需求并没有其他类型的测试那么广泛,没有太多的工具可让您进行这样的测试,但是简单而方便的操作通常可以用一只手指望。
当涉及到性能测试时-首先每个人都会想到JMeter-毫无疑问,它是拥有最多插件的最著名的工具。 我从来不喜欢JMeter,因为它的接口很明显并且入口门槛很高,因此有必要在测试非Hello World应用程序时立即对其进行测试。
现在,受两个不同项目测试成功的启发,我决定共享有关一个相对简单便捷的软件
-Locust的信息对于那些懒惰的人,我录制了一个视频:
这是什么
开源工具可让您使用支持分布式负载的Python代码指定负载方案,并且如作者所言,该工具用于Battlefild系列游戏的Battlelog压力测试(立即着迷)
从优点:
- 简单的文档,包括复制粘贴示例。 即使几乎没有编程技能,也可以开始测试。
- “内幕”使用请求库(用于人员的HTTP)。 它的文档可以用作扩展的备忘单和借方测试
- Python支持-我喜欢这种语言
- 上一段给出了运行测试的跨平台
- 自己的Flask Web服务器用于显示测试结果
缺点:
- 没有捕获和重放-所有人
- 上一段的结果-您需要大脑。 与Postman一样,您需要了解HTTP的工作原理。
- 最少的编程技巧
- 线性负载模型-立即根据“高斯”使风扇烦恼,从而产生用户
测试过程
任何测试都是一项复杂的任务,需要计划,准备,监视实施和结果分析。 在压力测试期间,如果可能,有可能并且有必要收集可能影响结果的所有可能数据:
- 服务器硬件(CPU,RAM,ROM)
- 服务器软件(操作系统,服务器版本,JAVA,.NET等,数据库及其本身的数据量,服务器和测试应用程序日志)
- 网络带宽
- 代理服务器,负载平衡器和DDOS保护的存在
- 负载测试数据(用户数,平均响应时间,每秒请求数)
下面描述的示例可以分类为黑盒功能负载测试。 即使不了解有关被测应用程序的任何信息,也无需访问日志,我们仍可以衡量其性能。
开始之前
为了在实践中测试负载测试,我部署了本地简单的Web服务器
https://github.com/typicode/json-server 。 我将为他提供以下几乎所有示例。 我从一个已部署的在线示例中获取了服务器的数据-https:
//jsonplaceholder.typicode.com/要运行它,需要nodeJS。
显而易见的破坏者 :与安全测试一样-最好在本地进行对猫进行压力测试的实验,而无需加载在线服务,这样就不会被禁止
首先,还需要Python-在所有示例中,我将使用3.6版以及蝗虫本身(在撰写本文时,使用0.9.0版)。 可以使用以下命令安装
python -m pip install locustio
安装详细信息可以在官方文档中找到。
解析一个例子
接下来,我们需要一个测试文件。 我从文档中举了一个例子,因为它非常简单明了:
from locust import HttpLocust, TaskSet def login(l): l.client.post("/login", {"username":"ellen_key", "password":"education"}) def logout(l): l.client.post("/logout", {"username":"ellen_key", "password":"education"}) def index(l): l.client.get("/") def profile(l): l.client.get("/profile") class UserBehavior(TaskSet): tasks = {index: 2, profile: 1} def on_start(self): login(self) def on_stop(self): logout(self) class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 5000 max_wait = 9000
仅此而已! 这真的足以开始测试! 在开始之前,让我们看一个例子。
跳过导入,一开始我们会看到2个几乎相同的登录和注销功能,由一行组成。
l.client-一个HTTP会话对象,我们将使用它创建负载。 我们使用POST方法,该方法几乎与请求库中的方法相同。 几乎-因为在此示例中,我们将特定服务作为第一个参数而不是完整URL传递,而只是其中一部分。
第二个参数传递数据-我不禁注意到使用Python字典非常方便,这些字典会自动转换为json
您还可以注意到,我们不会以任何方式处理请求的结果-如果请求成功,结果(例如cookie)将保存在此会话中。 如果发生错误,它将被记录并添加到有关负载的统计信息中。
如果我们想知道我们是否正确编写了请求,则可以始终按以下方式进行检查:
import requests as r response=r.post(base_url+"/login",{"username":"ellen_key","password":"education"}) print(response.status_code)
我仅添加了
base_url变量,该变量应包含被测试资源的完整地址。
接下来的几个功能是查询,这将创建一个负载。 同样,我们不需要处理服务器响应-结果将立即进入统计数据。
接下来是
UserBehavior类(该类的名称可以是任何名称)。 顾名思义,它将描述球形用户在被测应用程序的真空中的行为。 我们将用户将调用的方法及其调用频率的字典传递给
task属性。 现在,尽管事实是我们不知道每个用户将调用哪个函数和调用顺序-它们是随机选择的,但我们保证
索引函数的平均调用频率比
配置文件函数高2倍。
除了行为外,父类TaskSet还允许您指定4个可以在测试之前和之后执行的功能。 呼叫顺序如下:
- 设置 -在UserBehavior(TaskSet)的开始处被调用1次-该示例中没有
- on_start-启动时由负载的每个新用户调用1次
- 任务 -任务本身的执行
- on_stop-测试完成时,每个用户调用一次
- 拆卸 -在TaskSet退出时被调用1次-在示例中也没有
这里值得一提的是,有两种声明用户行为的方法:上面的示例中已经指出了第一种-函数是预先声明的。 第二种方法是直接在
UserBehavior类内部声明方法:
from locust import HttpLocust, TaskSet, task class UserBehavior(TaskSet): def on_start(self): self.client.post("/login", {"username":"ellen_key", "password":"education"}) def on_stop(self): self.client.post("/logout", {"username":"ellen_key", "password":"education"}) @task(2) def index(self): self.client.get("/") @task(1) def profile(self): self.client.get("/profile") class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 5000 max_wait = 9000
在此示例中,使用
任务注释设置用户功能及其调用频率。 在功能上,没有任何改变。
该示例中的最后一个类是
WebsiteUser (类的名称可以是任何名称)。 在此类中,我们定义用户行为模型
UserBehavior *** +,以及每个用户调用单个任务之间的最小和最大等待时间。 为了使它更清晰,以下是对其进行可视化的方法:
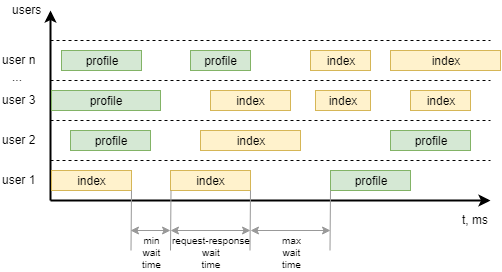
开始使用
运行服务器,我们将测试其性能:
json-server --watch sample_server/db.json
我们还修改了示例文件,以便它可以测试服务,删除登录和注销以及设置用户行为:
- 开始工作时打开主页1次
- 获取所有x2帖子的列表
- 在第一篇文章x1上发表评论
from locust import HttpLocust, TaskSet, task class UserBehavior(TaskSet): def on_start(self): self.client.get("/") @task(2) def posts(self): self.client.get("/posts") @task(1) def comment(self): data = { "postId": 1, "name": "my comment", "email": "test@user.habr", "body": "Author is cool. Some text. Hello world!" } self.client.post("/comments", data) class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
要在命令提示符处启动,请运行命令
locust -f my_locust_file.py --host=http://localhost:3000
其中host是测试资源的地址。 对他来说,将添加测试中指示的服务地址。
如果测试中没有错误,则负载服务器将启动,并且可以通过以下
网址访问:
http://本地主机:8089 /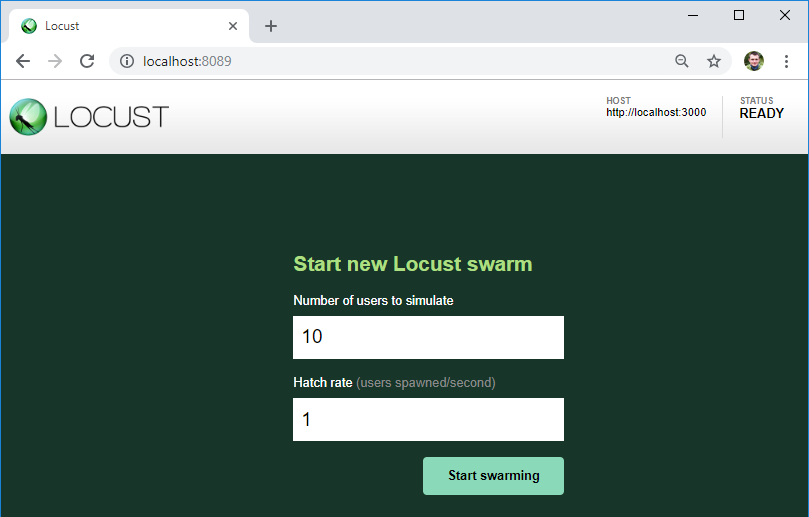
如您所见,将在此处指示我们将测试的服务器-将在该URL中添加来自测试文件的服务的地址。
同样在这里,我们可以指示负载的用户数量及其每秒的增长。
在按钮上,我们开始加载!
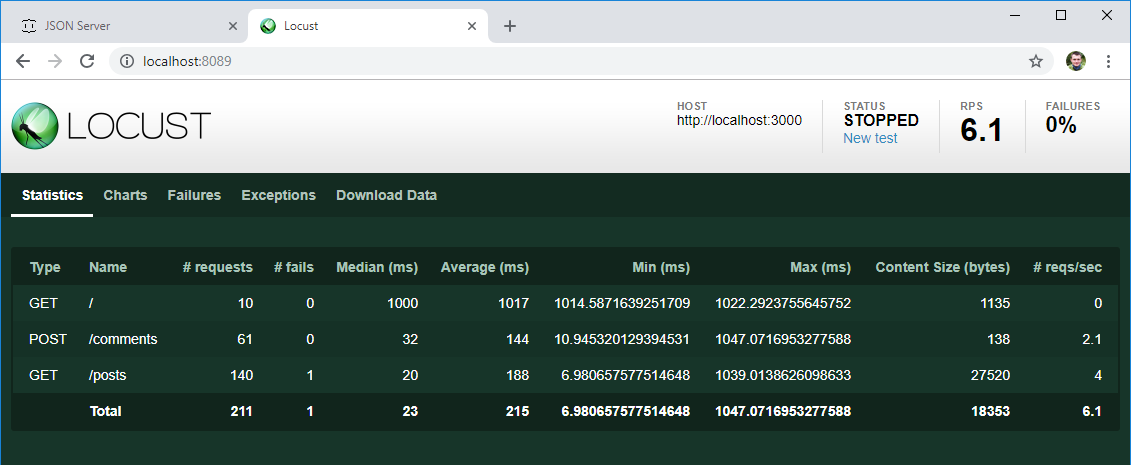
结果
一段时间后,我们停止测试并查看第一个结果:
- 不出所料,开始时创建的10个用户中的每个用户都转到了主页
- 帖子列表的平均打开次数是评论的两倍。
- 每个操作都有一个平均响应时间和中值响应时间,每秒的操作数已经是有用的数据,即使现在将其与需求的预期结果进行比较
在第二个选项卡上,您可以实时查看负载图。 如果服务器在特定负载下崩溃或其行为发生更改,则将立即在图形上可见。
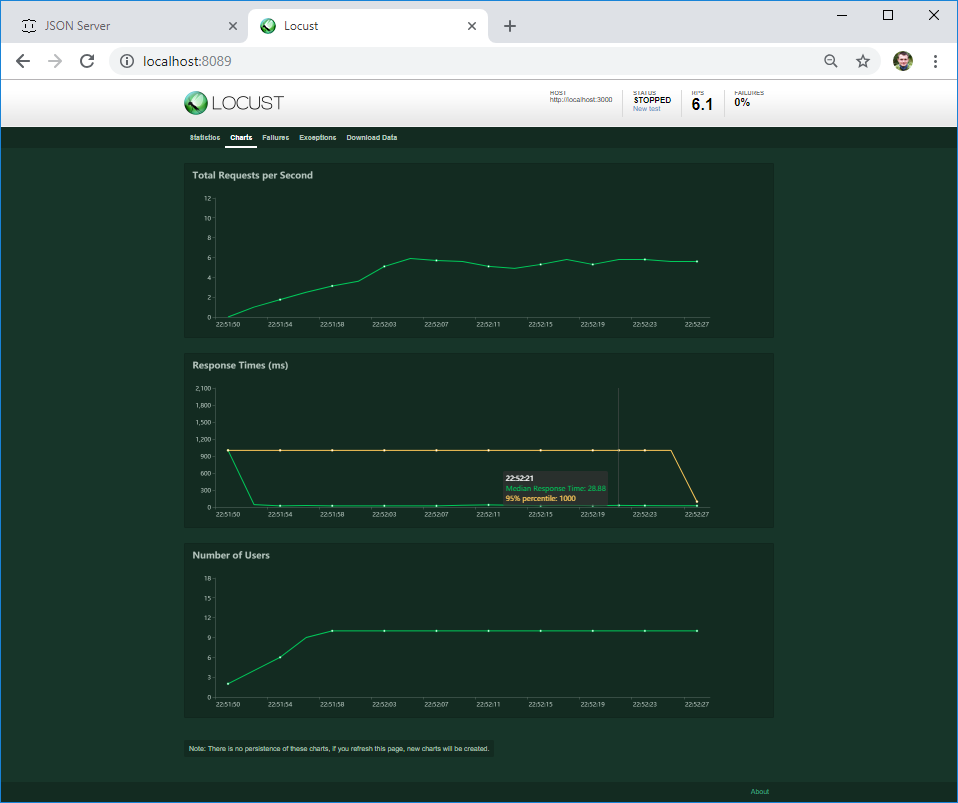
在第三个标签上,您可以看到错误-就我而言,这是客户端错误。 但是,如果服务器返回4XX或5XX错误,则其文本将写入此处
如果文本代码中出现错误,则该错误将落入“例外”选项卡。 到目前为止,我有与代码中使用print()命令相关的最常见错误-这不是记录日志的最佳方法:)
在最后一个标签上,您可以以CSV格式下载所有测试结果
这些结果相关吗? 让我们弄清楚。 通常,性能要求(如果有任何说明)听起来像这样:在加载M个用户的情况下,平均页面加载时间(服务器响应)应小于N秒。 没有真正指定用户应该做什么。 我喜欢蝗虫-它会创建一定数量用户的活动,这些活动会随机执行用户期望的预期操作。
如果我们需要执行基准测试(以测量不同负载下的系统行为),则可以创建几类行为并在不同负载下进行多个测试。
一开始就足够了。 如果您喜欢这篇文章,我打算写一下:
- 复杂的测试场景,在其中使用了一步的结果
- 服务器响应处理 即使到达HTTP 200 OK也可能是错误的
- 遇到的显而易见的困难以及如何解决它们
- 不使用UI进行测试
- 分布式负载测试