神经网络架构翻译如今,深层神经网络的算法已广受欢迎,这在很大程度上得益于深思熟虑的体系结构。 让我们看看它们过去几年的发展历史。 如果您对更深入的分析感兴趣,请参阅
此工作 。
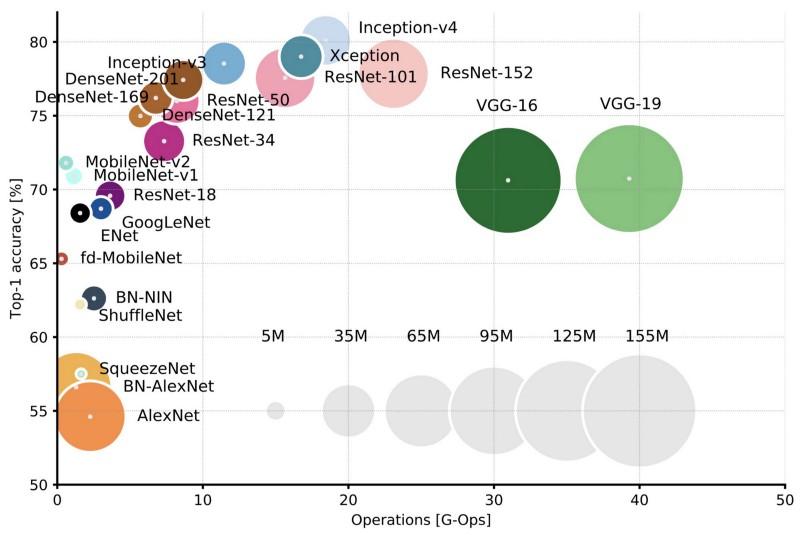 比较Top-1单作精度的流行体系结构和一次直接通过所需的操作数。 更多细节在这里 。
比较Top-1单作精度的流行体系结构和一次直接通过所需的操作数。 更多细节在这里 。Lenet5
1994年,第一个卷积神经网络被开发出来,为深度学习奠定了基础。 自1988年以来经过多次成功的迭代,Yann LeCun的这项开创性工作被称为
LeNet5 !

LeNet5体系结构已成为深度学习的基础,尤其是在整个图片中图像属性的分布方面。 具有学习参数的卷积允许使用多个参数从不同位置有效地提取相同属性。 在那些年里,没有视频卡可以加速学习过程,甚至中央处理器也很慢。 因此,与将每个像素用作大型多层神经网络的单独输入相比,该体系结构的主要优势是能够保存参数和计算结果。 在LeNet5中,第一层不使用像素,因为图像在空间上具有很强的相关性,因此将单个像素用作输入属性将不允许您利用这些相关性。
LeNet5的功能:
- 一个使用三层序列的卷积神经网络:卷积层,池化层和非线性层->自Lekun的著作发表以来,这也许是与图像有关的深度学习的主要特征之一。
- 使用卷积检索空间属性。
- 使用空间地图平均的二次采样。
- 双曲正切或S形形式的非线性。
- 多层神经网络(MLP)形式的最终分类器。
- 层之间的连接性稀疏矩阵减少了计算量。
这种神经网络构成了许多后续架构的基础,并启发了许多研究人员。
发展历程
从1998年到2010年,神经网络处于孵化状态。 尽管许多开发人员逐渐磨练了他们的算法,但大多数人没有注意到其功能的增长。 由于手机摄像头的鼎盛时期和数码相机的便宜,越来越多的培训数据可供我们使用。 同时,计算能力增强,处理器变得更强大,视频卡成为主要的计算工具。 所有这些过程都允许神经网络的发展,尽管速度相当缓慢。 人们对可以借助神经网络解决的任务的兴趣与日俱增,最终情况变得显而易见...
丹·奇里桑网
2010年,Dan Claudiu Ciresan和Jurgen Schmidhuber发表了关于
GPU神经网络实现的最早描述之一。 他们的工作包括在
NVIDIA GTX 280上直接和反向实现9层神经网络。
亚历克斯网
2012年,Alexei Krizhevsky出版了
AlexNet ,这是LeNet的深入和扩展版本,在ImageNet竞赛中大获全胜。
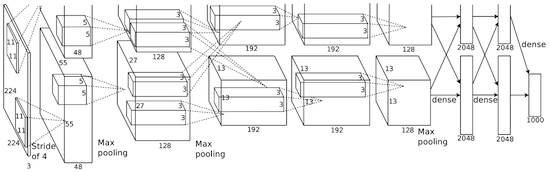
在AlexNet,LeNet计算的结果被缩放到一个更大的神经网络,该网络能够研究更复杂的对象及其层次结构。 该解决方案的特点:
- 使用线性整流单元(ReLU)作为非线性。
- 在训练过程中使用丢弃技术选择性忽略单个神经元,可以避免模型的过度训练。
- 重叠最大池,避免了平均池平均的影响。
- 使用NVIDIA GTX 580加快学习速度。
到那时,视频卡中的内核数量已显着增长,这使它们可以将训练时间减少约10倍,因此可以使用更大的数据集和图片。
AlexNet的成功掀起了一场小革命,卷积神经网络已成为深度学习的主力军-这个术语现在意味着“可以解决有用任务的大型神经网络”。
夸大其词
2013年12月,扬·勒昆(Jan Lekun)的纽约大学实验室发布了对
Overfeat(AlexNet的变体)的描述。 此外,本文还介绍了经过训练的边界框,随后还发布了有关该主题的许多其他作品。 我们认为,学习如何分割对象比使用人工边界框更好。
Vgg
在牛津大学开发的
VGG网络中,第一次在每个卷积层中使用3x3滤镜,甚至将这些层组合成一系列卷积。
这与LeNet中规定的原理相矛盾,根据LeNet的原理,使用大卷积来提取相同的图像属性。 代替AlexNet中使用的9x9和11x11过滤器,开始使用小得多的过滤器,危险地接近1x1卷积,LeNet的作者至少在网络的第一层试图避免这种情况。 但是VGG的最大优势是发现几个在序列中组合的3x3卷积可以模拟更大的接收场,例如5x5或7x7。 这些想法将在以后的Inception和ResNet体系结构中使用。
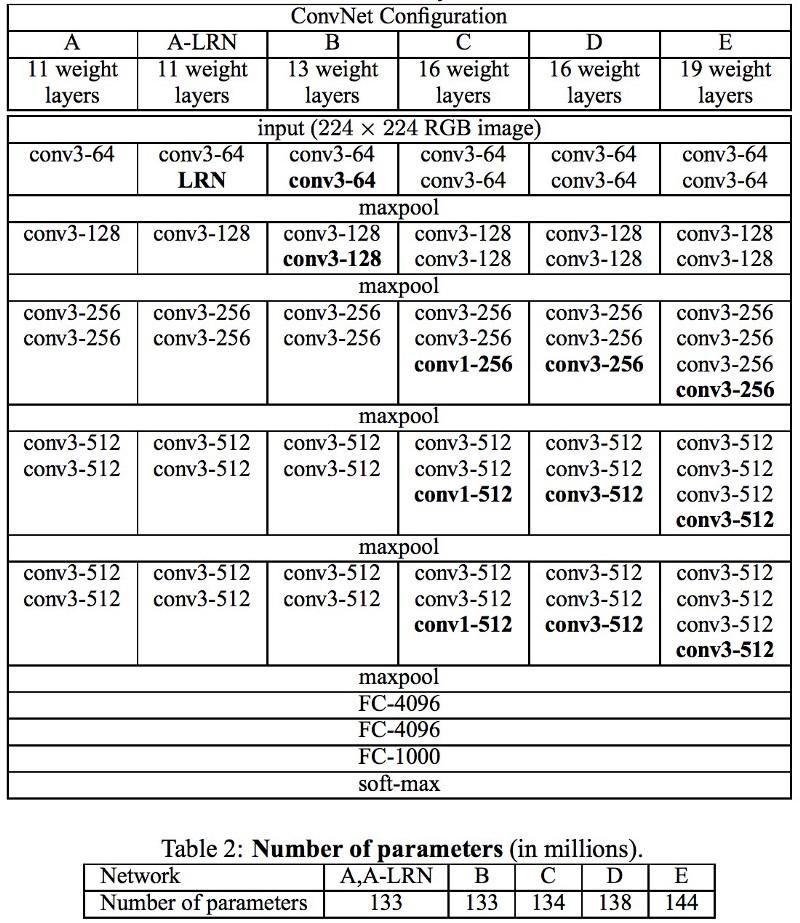
VGG网络使用多个3x3卷积层来表示复杂的属性。 注意VGG-E中的块3、4和5:要提取更复杂的属性并将其组合起来,将使用256×256和512×512 3×3的滤波器序列。 这相当于具有三层的大型卷积分类器512x512! 这为我们提供了大量参数和出色的学习能力。 但是学习这样的网络很困难;我不得不将它们分解成较小的网络,一层一层地添加。 原因是缺少有效的方法来规范化模型或缺少某些方法来限制较大的搜索空间,这是由许多参数推动的。
VGG在许多层中使用了大量的属性,因此训练在
计算上是昂贵的 。 可以通过减少属性的数量来减少负载,就像在Inception体系结构的瓶颈层中所做的那样。
网络中的网络
网络中的网络 (NiN)体系结构基于一个简单的想法:使用1x1卷积可提高卷积层中属性的组合性。
在NiN中,每次卷积后,空间MLP层用于更好地组合属性,然后馈入下一层。 看起来1x1卷积的使用似乎与原始的LeNet原理相矛盾,但实际上,它允许更好地组合属性,而不仅仅是填充更多的卷积层。 此方法不同于将裸像素用作下一层的输入。 在这种情况下,将1x1卷积用于在属性图的框架内进行卷积后对属性进行空间组合,因此可以使用更少的这些属性的所有像素共有的参数!
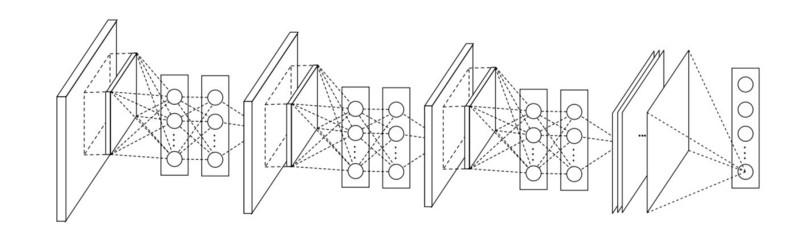
通过将卷积层组合成更复杂的组,MLP可以大大提高各个卷积层的有效性。 此想法后来在其他体系结构中使用,例如ResNet,Inception及其变体。
GoogLeNet和《盗梦空间》
Google Christian Szegedy担心降低深度神经网络中的计算,因此创建
了第一个Inception架构GoogLeNet 。
到2014年秋季,深度学习模型已非常有用,可以对视频中的图像内容和帧进行分类。 许多怀疑论者已经认识到深度学习和神经网络的好处,包括谷歌在内的互联网巨头对在服务器容量上部署高效大型网络变得非常感兴趣。
克里斯汀(Christian)一直在寻找减少神经网络中计算负荷,实现最高性能的方法(例如,在ImageNet中)。 或保留计算量,但仍可提高生产率。
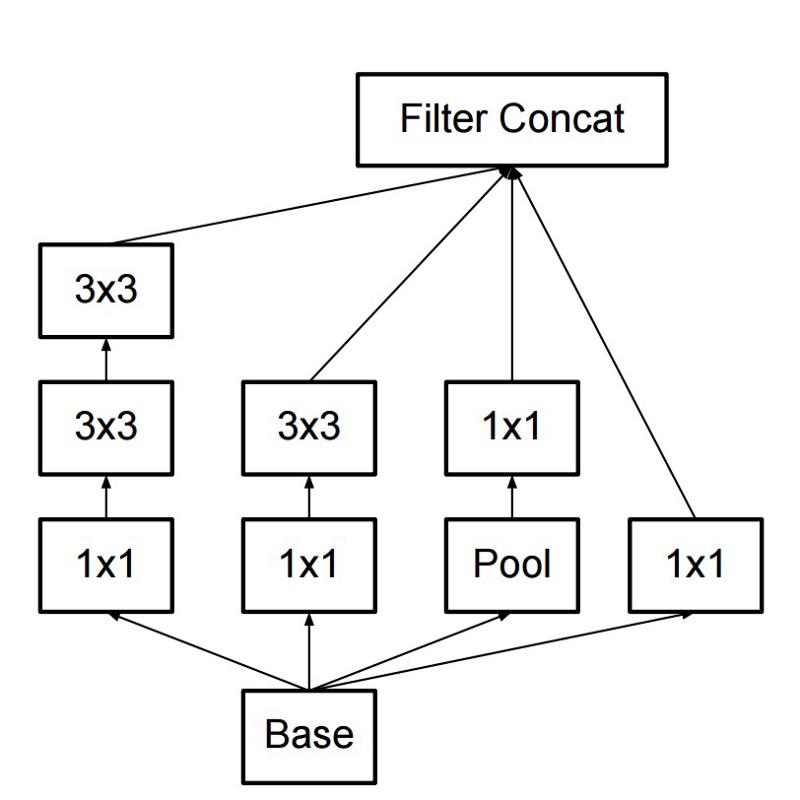
结果,该命令创建了一个Inception模块:

乍一看,这是卷积滤波器1x1、3x3和5x5的并行组合。 但是最重要的是使用卷积块1x1(NiN)来减少在“昂贵”的并行块中使用之前的属性数量。 通常这部分称为瓶颈,下一章将对其进行详细描述。
GoogLeNet使用没有Inception模块的词干作为初始层,并且还使用平均池和类似于NiN的softmax分类器。 与AlexNet和VGG相比,该分类器执行的操作很少。 它还帮助创建了
非常有效的神经网络体系结构 。
瓶颈层
该层减少了每个层中的属性(因此减少了操作)的数量,因此可以将获得结果的速度保持在较高水平。 在将数据传输到“昂贵的”卷积模块之前,属性的数量减少了例如4倍。 这大大减少了计算量,这使得该体系结构很受欢迎。
让我们弄清楚。 假设我们在输入处具有256个属性,在输出处具有256个属性,并且让Inception层仅执行3x3卷积。 我们得到256x256x3x3个卷积(589,000个累加运算,即MAC运算)。 这可能超出了我们的计算速度要求;假设在Google Server上以0.5毫秒的时间处理了一个图层。 然后将可折叠的属性数量减少到64(256/4)。 在这种情况下,我们首先执行256-> 64的1x1卷积,然后在所有Inception分支中执行另一个64卷积,然后再次应用64-> 256属性的1x1卷积。 操作次数:
- 256×64×1×1 = 16,000
- 64×64×3×3 = 36,000
- 64×256×1×1 = 16,000
仅约70,000,减少了将近十倍的操作次数! 但与此同时,我们在这一层也没有失去一般性。 瓶颈层在ImageNet数据集上显示了出色的性能,并且已在更高的体系结构(例如ResNet)中使用。 它们成功的原因是输入属性是相关的,这意味着您可以通过将属性与1x1卷积正确组合来摆脱冗余。 并且在用较少的属性折叠之后,您可以再次将它们部署到下一层的重要组合中。
起始V3(和V2)
Christian和他的团队被证明是非常有效的研究人员。 2015年2月,
批量标准化的Inception架构被引入为
Inception的第二个版本。 批量归一化计算输出层中所有属性分布图的均值和标准差,并使用这些值归一化它们的响应。 这对应于数据的“变白”,也就是说,所有神经图的响应都在同一范围内,并且均值为零。 这种方法使学习变得更容易,因为不需要下一层记住输入数据的偏移量,而只能搜索属性的最佳组合。
2015年12月,发布了
新版本的Inception模块和相应的架构 。 作者的文章更好地解释了原始的GoogLeNet体系结构,该体系结构进一步说明了决策。 关键思想:
- 由于其深度和宽度之间的精心平衡,因此可以最大化网络中的信息流。 在每次合并之前,属性图都会增加。
- 随着深度的增加,特性的数量或层宽度也系统地增加。
- 每层的宽度增加以增加下一层之前的特性组合。
- 在可能的范围内,仅使用3x3卷积。 假设可以使用多个3x3分解5x5和7x7滤镜
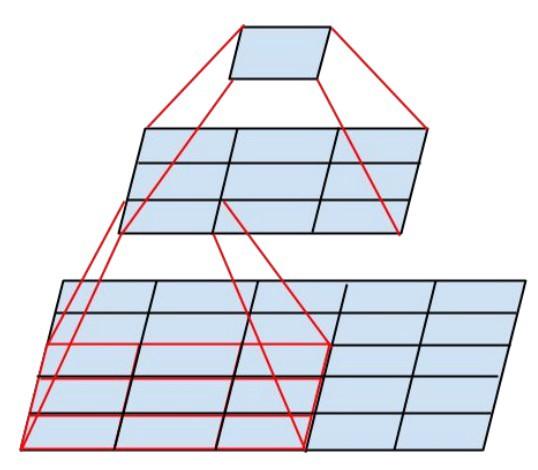
新的Inception模块如下所示:
- 过滤器也可以使用平滑卷积分解为更复杂的模块:

- Inception模块可以在Inception计算期间使用池来减少数据大小。 这类似于使用简单池化层并行进行跨步卷积:

Inception使用具有softmax的池化层作为最终分类器。
Resnet
2015年12月,大约在引入Inception v3架构的同时,发生了一场革命-他们发布了
ResNet 。 它包含一些简单的想法:提交两个成功的卷积层的输出,并绕过下一层的输入!

例如,
这里已经提出了这样的想法。 但是在这种情况下,作者绕过了两个层,并大规模应用了该方法。 绕过一层不会带来太多好处,而绕过两层是一个关键发现。 这可以看作是小型分类器,如网络中的网络!
这也是训练数百乃至数千层网络的第一个示例。
多层ResNet使用的瓶颈层类似于Inception中使用的瓶颈层:

该层减少了每一层中的属性数量,首先使用具有较低输出(通常为输入的四分之一)的1x1卷积,然后使用3x3层,然后再次将1x1卷积为更多的属性。 与Inception模块一样,这可以节省计算资源,同时又可以保持大量的属性组合。 与Inception V3和V4中较为复杂且不太明显的词干进行比较。
ResNet使用带有softmax的池化层作为最终分类器。
每天,都会出现有关ResNet架构的其他信息:
- 可以将其视为同时并行和串行模块的系统:在许多模块中,输入输出信号是并行的,并且每个模块的输出信号都串联连接。
- ResNet可以看作是并行或串行模块的多个集合 。
- 事实证明,ResNet通常使用相对较小的20-30层深度块并行运行,而不是沿网络的整个长度顺序运行。
- 由于输出信号返回并作为输入馈送,就像在RNN中所做的一样,ResNet可以被认为是大脑皮质的一种改进的合理模型 。
盗梦空间V4
克里斯汀(Christian)和他的团队在
新版本的盗梦空间(Inception)中再次
脱颖而出 。
词干之后的Inception模块与Inception V3中的相同:

在这种情况下,Inception模块与ResNet模块结合在一起:

以我的喜好,这种体系结构更加复杂,不太优雅,并且还充满了不透明的启发式解决方案。 很难理解作者为什么做出这些决定或这些决定,并且同样难以给予他们任何评估。
因此,一个干净,简单,易于理解和修改的神经网络的奖项归于ResNet。
挤压网
SqueezeNet最近发布。 这是来自ResNet和Inception的许多概念的全新重制。 作者证明,改进体系结构可减少网络规模并减少参数数量,而无需复杂的压缩算法。
易网
使用很少的参数和计算能力,将最新体系结构的所有功能组合到一个非常高效和紧凑的网络中,但同时却能提供出色的结果。 该体系结构称为
ENet ,由Adam Paszke(
Adam Paszke )开发。 例如,我们使用它来非常精确地标记屏幕上的对象并解析场景。
Enet的一些示例 。 这些视频与
训练数据集无关。
在这里您可以找到ENet的技术细节。 它是一个基于编码器和解码器的网络。 编码器建立在通常的CNN分类方案之上,而解码器则是通过将类别扩展回原始尺寸图像而进行分割的上采样网络。 对于图像分割,仅使用神经网络,没有其他算法。
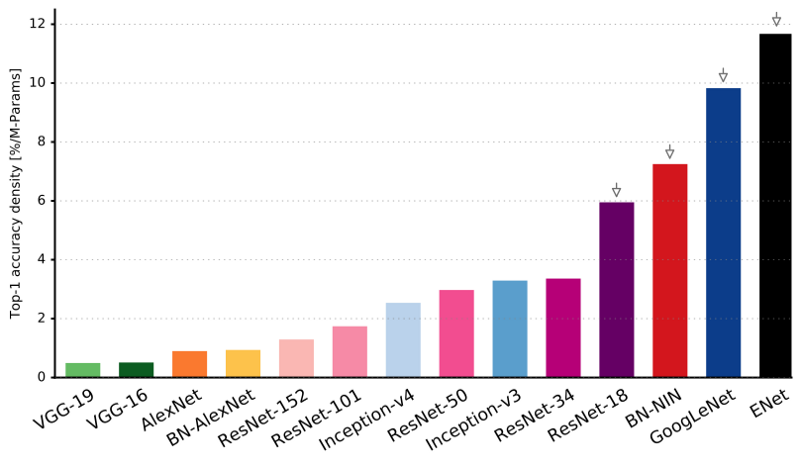
如您所见,与所有其他神经网络相比,ENet具有最高的特定精度。
ENet旨在从一开始就使用尽可能少的资源。 结果,编码器和解码器一起仅以fp16精度占用0.7 MB。 而且,由于ENet的尺寸如此之小,因此它不亚于分割精度,也不比其他纯神经网络解决方案优越。
模块分析
发表了 CNN模块
的系统评估。 事实证明是有益的:
- 在不使用批处理标准化(batchnorm)的情况下使用ELU非线性,或者在进行标准化的情况下使用ReLU。
- 应用学习过的RGB色彩空间转换。
- 使用线性学习率衰减策略。
- 使用中间和最大池化层的总和。
- 使用128或256的迷你数据包,如果这对于您的视频卡来说太大了,请按照数据包大小成比例地降低学习速度。
- 使用完全连接的层作为卷积层并进行平均预测以得出最终解决方案。
- 如果增加训练数据集的大小,请确保您尚未达到训练的平稳状态。 数据清洁度比大小更重要。
- 如果无法增加输入图像的大小,请减小后续图层的步幅,效果将大致相同。
- 如果您的网络具有复杂且高度优化的体系结构(例如GoogLeNet),请谨慎修改。
Xception
Xception在Inception模块中引入了一种更简单,更优雅的架构,其效率不亚于ResNet和Inception V4。
这是Xception模块的样子:
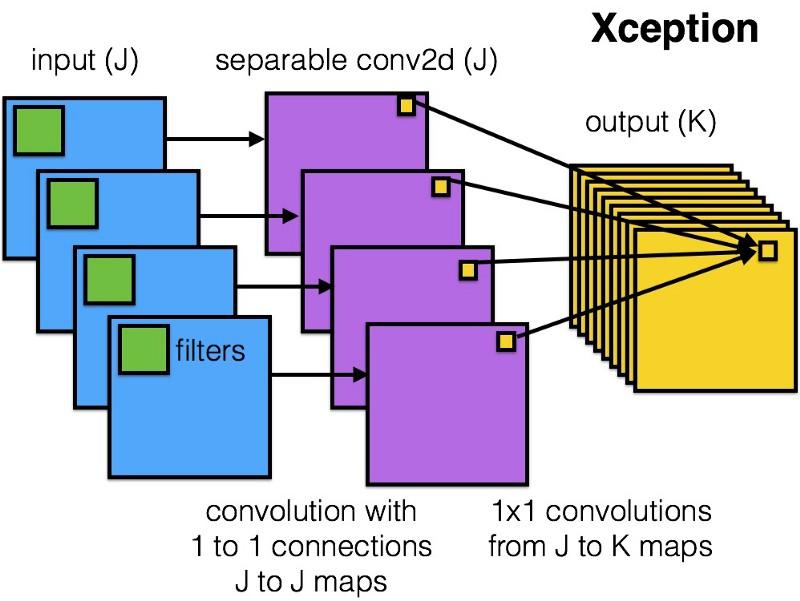
由于其架构的简单和优雅,任何人都会喜欢此网络:

它包含36个卷积步骤,这类似于ResNet-34。 同时,模型和代码很简单,就像在ResNet中一样,并且比Inception V4更令人愉悦。
该网络的torch7实施在
此处可用,而Keras / TF实施在此处可用。
奇怪的是,最近Xception体系结构的作者也受到
我们在可分离卷积滤波器方面的工作的启发。
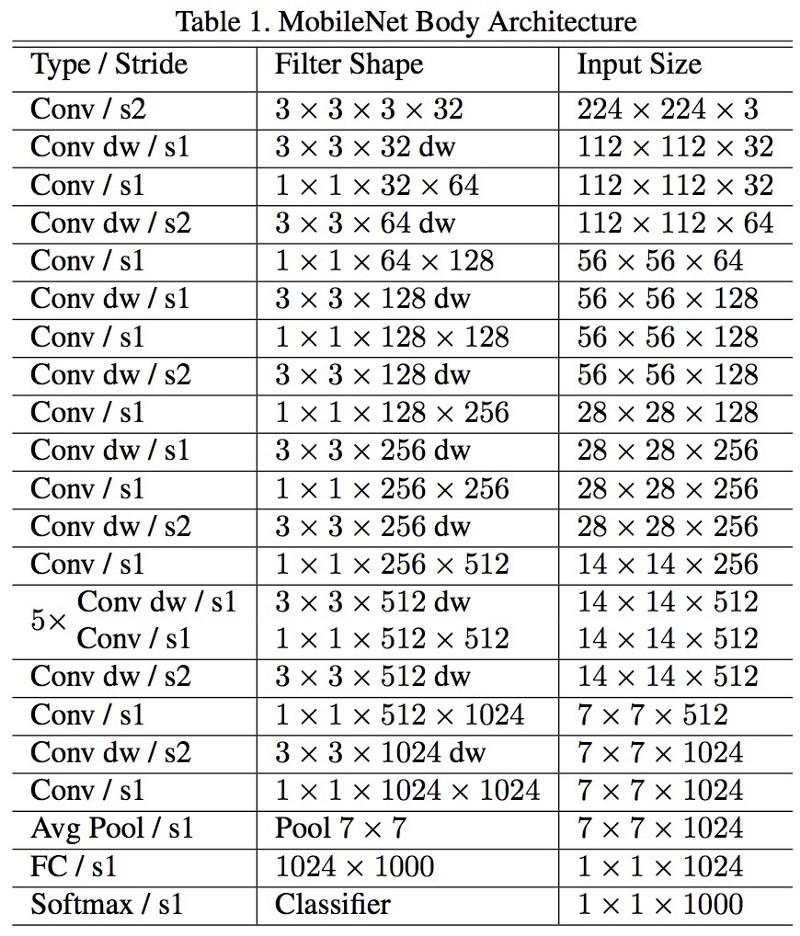
移动网
M
obileNets的新架构于2017年4月发布。 为了减少参数的数量,它使用可分离的卷积,与Xception中的相同。 在工作中还指出,作者能够极大地减少参数的数量:对于FaceNet,大约为一半。 :
, 1 (batch of 1) Titan Xp. :
- resnet18: 0,002871
- alexnet: 0,001003
- vgg16: 0,001698
- squeezenet: 0,002725
- mobilenet: 0,033251
! , .
FractalNet , ImageNet ResNet.
, . , .
, , , , ? , .
.
, . , .
, .
.