
哈Ha! 两年前,我们
撰写了有关如何切换到PHP 7.0并节省一百万美元的文章。 在我们的负载配置文件中,新版本的CPU使用效率是原来的两倍:过渡开始后,我们曾经为大约600台服务器提供服务的负载约为300个。 结果,两年来我们有很多能力。
但是Badoo正在成长。 活动用户的数量在不断增加。 我们正在改进和开发我们的功能,这要感谢用户在应用程序中花费越来越多的时间。 反过来,这也反映在请求数量上,在过去两年中,请求数量增加了2-2.5倍。
我们发现自己处于这样一种情况,性能的两倍增长被请求的两倍以上的增长所抵消,然后我们再次开始接近集群的极限。 在PHP的核心中,再次期望进行有用的
优化 (JIT,预加载),但是它们仅计划用于PHP 7.4,并且此版本将在一年内发布。 因此,过渡技巧现在无法重复-您需要优化应用程序代码本身。
切入点,我将告诉您我们如何处理此类任务,使用哪些工具,并举例说明适用于我们,对我们有帮助的优化,思想和方法。
为什么要优化
解决性能问题的最简单,最明显的方法是添加铁。 如果您的代码在同一服务器上运行,那么再添加一个将使集群的性能提高一倍。 将这些成本转移到开发人员的工作时间上,我们问自己:由于优化,他在这段时间内能否将生产率提高两倍? 也许是,但也许不是:这取决于系统已经在最佳状态下工作以及开发人员的水平。 另一方面,购买的服务器将保留为公司财产,所花费的时间将不退还。
事实证明,在小体积情况下,正确的解决方案通常是添加铁。
但以我们的情况。 现在,从迁移到PHP 7.0所获得的收益被活动的增长和用户数量所抵消之后,我们又有了600台服务器,可以为PHP应用程序提供请求。 为了将容量提高一半半,我们需要添加300台服务器。
以计算一台服务器的平均成本-$ 4,000。 300 * 4000 = $ 1,200,000-将容量增加一倍半的成本。
就是说,在我们的条件下,我们可以投入大量的工作时间来优化系统,与买铁相比,它仍然会更有利可图。
能力计划
在做任何事情之前,重要的是要了解是否有问题。 如果她不在那,那么值得尝试预测她何时会出现。 此过程称为容量计划。
出现性能问题的具体指标是响应时间。 确实,CPU(或其他资源)的负载是6%还是146%无关紧要:如果客户在满意的时间内获得了所需质量的服务,则一切正常。
关注响应时间的缺点是通常只有在问题已经出现时才开始增加响应时间。 如果尚未出现,则很难预测其外观。 另外,响应时间反映了所有因素(制动服务,网络,驱动器等)影响的结果,并且不能提供问题原因的理解。
在我们的情况下,CPU通常是瓶颈,因此在规划集群的大小和性能时,我们主要关注与使用情况相关的指标。 我们从所有机器上收集CPU使用率,并用平均值,中位数,第75和第95个百分位数构建图形:
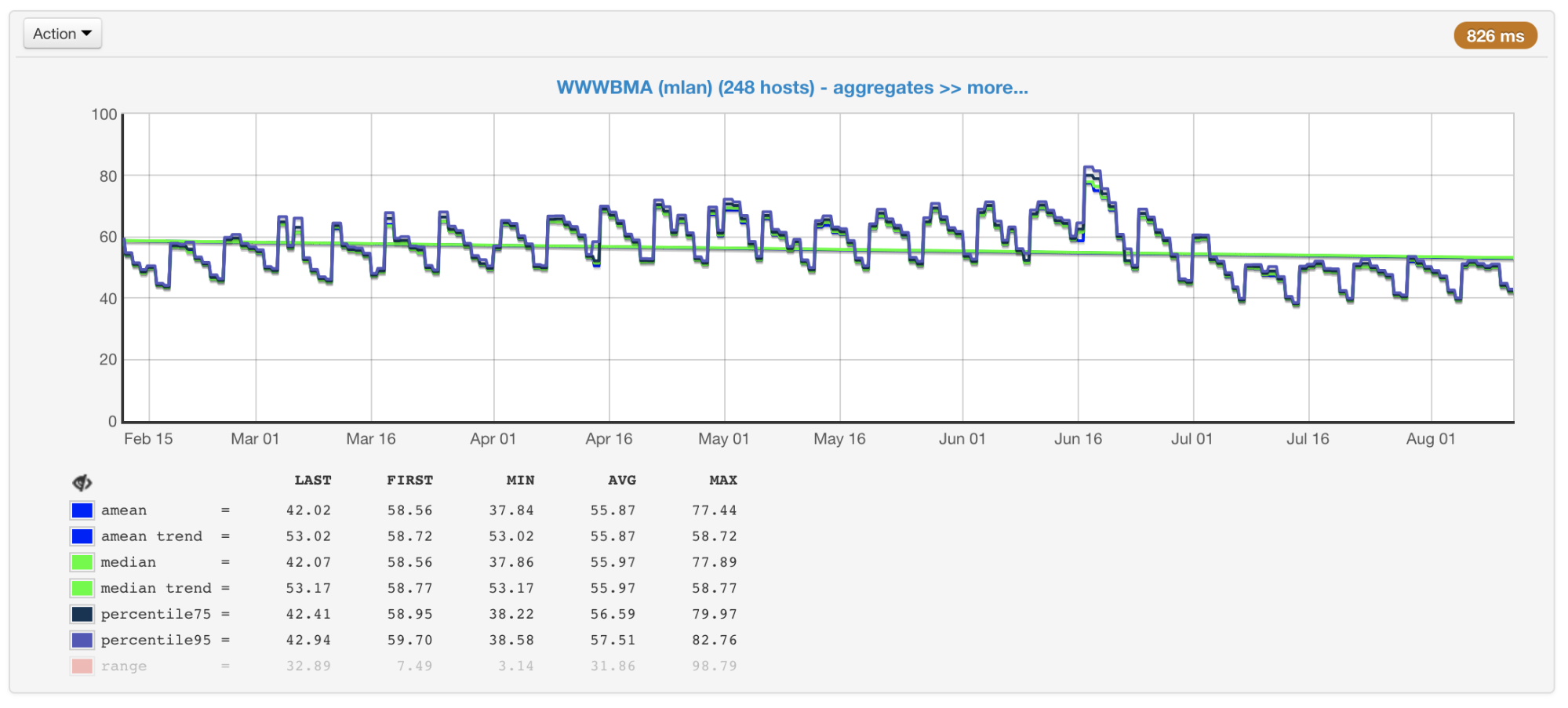 群集计算机的CPU使用率百分比:平均值,中位数,百分位数
群集计算机的CPU使用率百分比:平均值,中位数,百分位数集群中添加了数百年的机器已经有很多年了。 它们的配置和性能不同(群集不是同质的)。 我们的平衡器考虑了这一点(
文章和
视频 ),并根据机器的功能加载机器。 为了控制此过程,我们还有最大和最小装载机器的时间表。
 负载最大和最少的集群计算机
负载最大和最少的集群计算机如果查看这些图(或仅查看top命令的输出)并看到50%的CPU负载,您可能会认为我们仍然有两倍的负载裕量。 但是实际上通常并非如此。 这就是为什么。
超线程
想象一个没有超跑的单核。 我们用一个CPU绑定线程加载它。 我们会在顶部看到100%的负载。
现在,在此内核上打开超级读取并以完全相同的方式加载它。 在顶部,我们已经看到了两个逻辑核心,总负载将为50%(通常一个为0%,另一个为100%)。
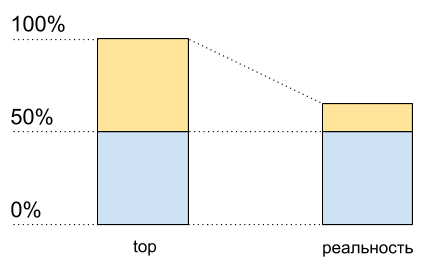 CPU利用率:主要数据以及实际情况
CPU利用率:主要数据以及实际情况好像处理器仅加载了50%。 但实际上没有其他可用的免费内核出现。
在某些情况下 ,超踩踏允许一次
在一个物理核心上执行多个进程。 但这远没有使典型情况下的性能提高一倍,尽管在CPU使用情况图上看起来它只有一半的资源:从50%到100%。
这意味着在启用超跑时,CPU使用率达到50%之后,其增长速度将与以前不同。
我编写了以下代码进行演示(这是一种综合案例,实际上结果会有所不同):
脚本代码<?php $concurrency = $_SERVER['argv'][1] ?? 1; $hashes = 100000000; $chunkSize = intval($hashes / $concurrency); $t1 = microtime(true); $children = array(); for ($i = 0; $i < $concurrency; $i++) { $pid = pcntl_fork(); if (0 === $pid) { $first = $i * $chunkSize; $last = ($i + 1) * $chunkSize - 1; for ($j = $first; $j < $last; $j++) { $dummy = md5($j); } printf("[%d]: %d hashes in %0.4f sec\n", $i, $last - $first, microtime(true) - $t1); exit; } else { $children[$pid] = 1; } } while (count($children) > 0) { $pid = pcntl_waitpid(-1, $status); if ($pid > 0) { unset($children[$pid]); } else { exit("Got a error pid=$pid"); } }
我的笔记本电脑上有两个物理核心。 使用不同的输入数据运行此代码,以便使用不同数量的并行C进程衡量其性能。
我们绘制启动结果:
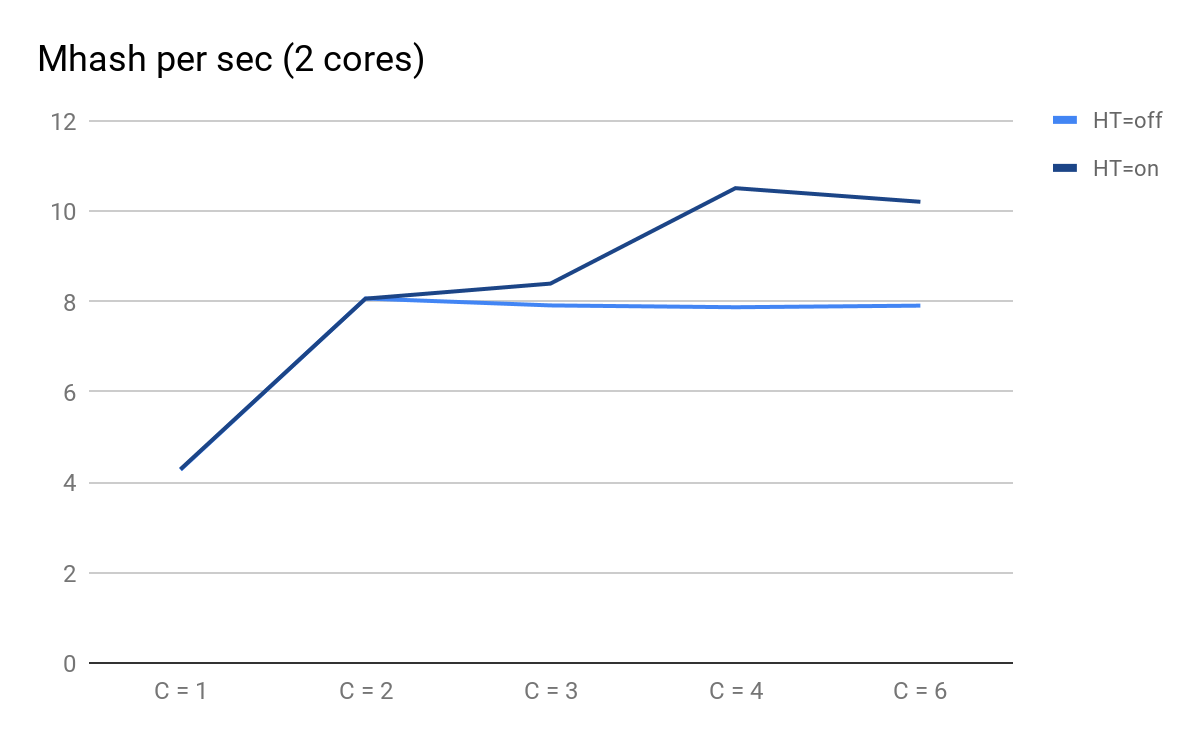 脚本性能取决于并行进程数
脚本性能取决于并行进程数您需要注意的是:
- 当HT = on和HT = off时,C = 1和C = 2可以预期是相同的,当添加物理内核时,性能会翻倍;
- 在C = 3时,HT的优势变得显而易见:对于HT =开启,我们可以获得额外的性能,而对于HT =断开,且C = 3起,它开始缓慢地下降。
- 在C = 4时,我们看到了HT的所有好处; 我们可以将生产力提高30%,但与此时的C = 2相比,CPU使用率从50%增加到100%。
总计,从最高的CPU负载的50%来看,执行此脚本时,我们得到8,065 Mhash /秒,而达到100%-10,511 Mhash /秒。 这意味着在最高性能的大约50%处,我们将获得最大系统性能的8.065 / 10.511〜77%,实际上,储备中还剩下大约100%-77%= 23%,而不是看起来的50%。
规划时必须考虑这一事实。
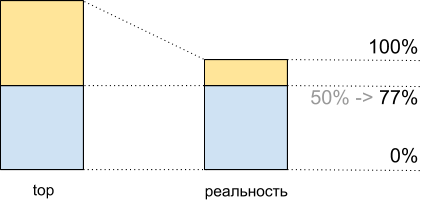 主题的CPU使用率:最高数据以及实际发生的情况
主题的CPU使用率:最高数据以及实际发生的情况流量不一致
除了超跑外,根据一天中的时间,一周中的某天,季节和其他频率,计划还会使交通不平衡变得更加复杂。 例如,对我们来说,高峰是周日晚上。
 每秒请求数,星期天晚上达到高峰
每秒请求数,星期天晚上达到高峰请求数量并非总是以明显的方式改变。 例如,用户可以以某种方式与其他用户进行交互:某些用户的活动可能会向其他用户生成推送/电子邮件,从而使他们参与此过程。 除此以外,还增加了宣传活动,这些活动增加了访问量,您还需要为此做好准备。
在计划时要考虑的所有这些因素也很重要:例如,要在高峰日建立趋势,并记住高峰增长可能存在的非线性。
分析和测量工具
假设我们发现存在性能问题,了解这不是数据库/服务/内容,但是我们决定优化代码。 为此,首先,我们需要一个探查器或一些工具来查找瓶颈,然后查看我们的优化结果。
不幸的是,对于今天的PHP,还没有一个好的通用工具。
性能
perf是Linux内核中内置的性能分析工具。 它是由单独的进程启动的
采样分析器,因此它不会直接给要分析的程序增加开销。 间接增加的开销被均匀地“抹上”,因此不会使测量失真。
尽管有其所有优点,但是perf只能与编译后的代码和JIT一起使用,而不能与“在虚拟机下”运行的代码一起使用。 因此,无法在其中分析PHP代码本身,但是您可以清楚地看到PHP在内部的工作方式,包括各种PHP扩展,以及在其上花费了多少资源。
例如,在性能方面,我们发现了几个瓶颈,包括压缩位置,我将在下面进行讨论。
一个例子:
perf record --call-graph dwarf,65528 -F 99 -p $(pgrep php-cgi | paste -sd "," -) -- sleep 20
perf report(如果进程和性能在不同的用户下执行,则性能需要从sudo下运行)。
 PHP-FPM的Perf报告输出示例
PHP-FPM的Perf报告输出示例XHProf和XHProf聚合器
XHProf是PHP的扩展,它在所有对函数/方法的调用周围放置计时器,并且还包含用于可视化由此获得的结果的工具。 与perf不同,它允许您使用PHP代码进行操作(同时,扩展中发生的事情是不可见的)。
缺点包括两点:
- 所有度量都是在单个请求的框架内收集的,因此它们不提供有关整个图片的信息;
- 开销,尽管不如使用Xdebug时大 ,但开销却很大,并且在某些情况下,结果会严重失真(调用函数的次数越多,且函数越简单,失真就越大)。
这是说明最后一点的示例:
function child1() { return 1; } function child2() { return 2; } function parent1() { child1(); child2(); return; } for ($i = 0; $i < 1000000; $i++) { parent1(); }
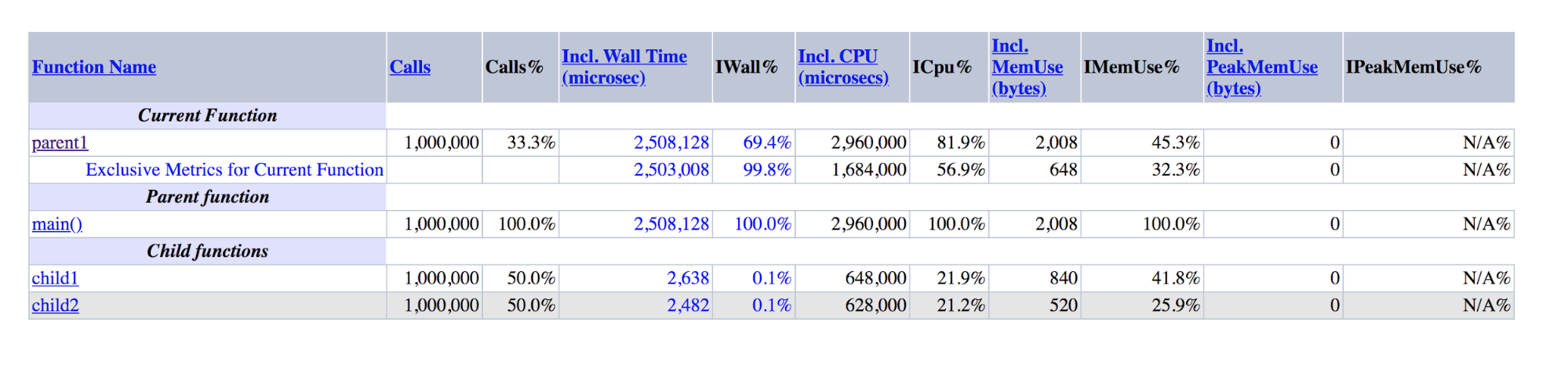 演示的XHProf输出:parent1比child1和child2之和大几个数量级
演示的XHProf输出:parent1比child1和child2之和大几个数量级可以看出,parent1()的执行时间是child1()+ child2()的〜500倍,尽管实际上这些数字应大致相等,与main()和parent1()相同。
如果最后一个缺点很难克服,那么为了克服第一个缺点,我们为XHProf创建了一个附加程序,该附加程序汇总了不同请求的配置文件并可视化了汇总数据。
除了XHProf外,还有许多其他鲜为人知的探查器也基于类似原理工作。 它们具有类似的优点和缺点。
平巴
Pinba允许您
通过脚本(动作)和预设计时器来
监视性能 。 脚本上下文中的所有度量均是开箱即用的;为此,不需要其他步骤。 对于每个脚本和计时器,都会
执行getrusage ,因此我们确切地知道在特定代码段上花费了多少处理器时间(与采样分析器不同,该时间可能是网络,磁盘等)。 Pinba非常适合保存历史数据并获取一般和特定类型查询中的图片。
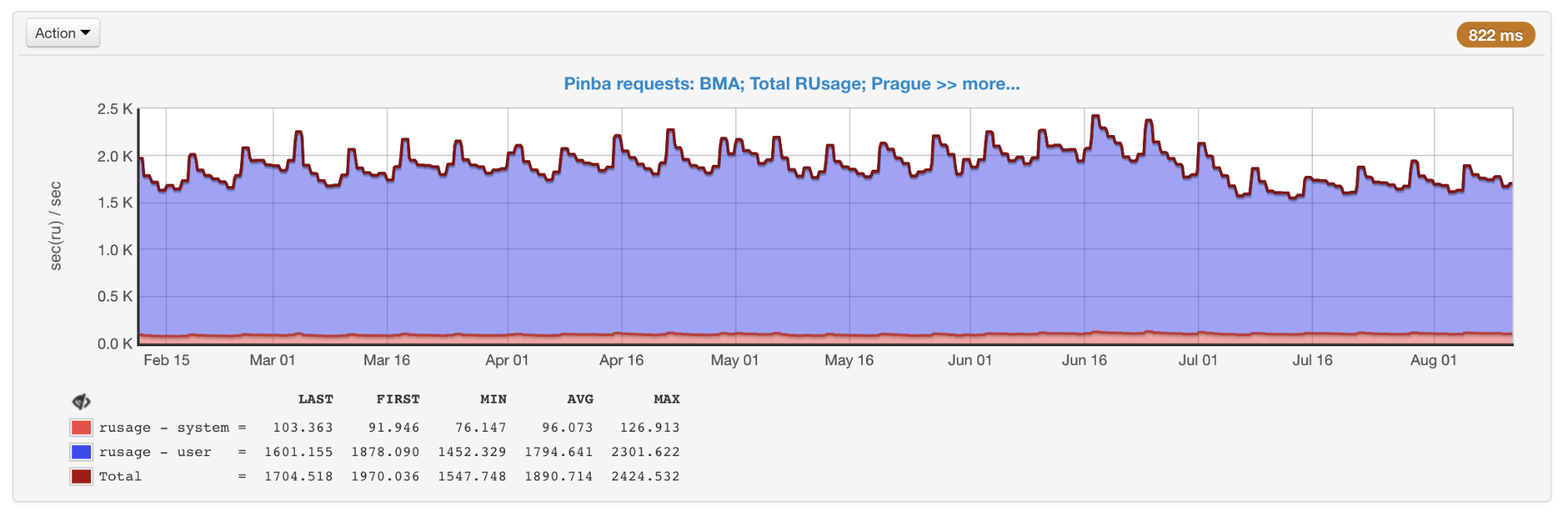 从Pinba获得的所有脚本的总体使用情况
从Pinba获得的所有脚本的总体使用情况缺点包括以下事实:配置代码的特定部分(而不是整个脚本)的计时器必须事先在代码中安排,以及存在可能使数据失真的开销(例如XHProf)。
phpspy
phpspy是一个相对较新的项目(在GitHub上的第一次提交是在半年前),它看起来很有希望,因此我们正在密切监视它。
从用户的角度来看,phpspy类似于perf:启动了并行进程,该进程会定期复制PHP进程的内存部分,对其进行解析并从那里接收堆栈跟踪和其他数据。 这是以相当特定的方式完成的。 为了最大程度地减少开销,phpspy不会停止PHP进程并在运行时直接复制内存。 这导致了一个事实,即探查器可能会获得不一致的状态,堆栈跟踪可能会中断。 但是phpspy可以检测到这一点并丢弃此类数据。
将来,使用此工具将有可能收集整个图片上的数据以及特定类型查询的配置文件。
比较表
为了构造工具之间的差异,让我们创建一个数据透视表:
 比较器的主要功能比较火焰图
比较器的主要功能比较火焰图优化和方法
使用这些工具,我们可以不断监控资源的性能和使用情况。 如上文所述,当不合理地使用它们或接近阈值时(对于CPU,我们经验性地选择55%的值,以便在增长时有一定的余量),解决问题的方法之一就是优化。
好吧,如果优化已经由其他人完成(例如PHP 7.0),则该版本比以前的版本生产力更高。 我们通常尝试使用现代技术和工具,包括及时更新PHP的最新版本。 根据
公共 基准 ,PHP 7.2比PHP 7.1快5-12%。 但是,这种过渡给我们带来的好处要少得多。
一直以来,我们都实现了大量的优化。 不幸的是,它们大多数与我们的业务逻辑紧密相关。 我将讨论那些不仅与我们相关的内容,或者可以在我们的代码之外使用的思想和方法。
Zlib压缩=> zstd
我们对大的Memkey键使用压缩。 由于用于压缩/解压缩的额外CPU成本,这使我们可以减少三到四倍的存储空间。 我们为此使用zlib(我们与memekes一起使用的扩展名不同于PHP附带的扩展名,但官方的扩展名
也 使用 zlib)。
在性能方面,生产是这样的:
+ 4.03% 0.22% php-cgi libz.so.1.2.11 [.] inflate
+ 3.38% 0.00% php-cgi libz.so.1.2.11 [.] deflate7-8%的时间用于压缩/解压缩。
我们决定测试不同的级别和压缩算法。 事实证明,zstd在我们的数据上运行的速度几乎快了十倍,丢失了约1.1倍。 算法上的一个相当简单的变化为我们节省了大约7.5%的CPU(我记得,在我们的卷上,这相当于大约45个服务器)。
重要的是要理解,不同的压缩算法的性能比可以根据输入数据而有很大的不同。 有各种
比较 ,但是最准确的说,只能使用实际示例进行估算。
IS_ARRAY_IMMUTABLE作为很少修改的数据的存储库
在执行实际任务时,您必须处理经常需要的数据,同时很少更改并且数据量有限。 我们有很多类似的数据,一个很好的例子是
拆分测试的配置。 我们检查用户是否处于特定测试条件下,并以此为基础向用户展示实验性功能或正常功能(这几乎发生在每个请求中)。 在其他项目中,配置和各种目录可以是这样的示例:国家,城市,语言,类别,品牌等。
由于经常请求此类数据,因此它们的接收可能给应用程序本身以及存储此数据的服务造成明显的额外负担。 后一个问题可以通过使用APCu解决,例如,APCu使用运行PHP-FPM的同一台计算机的内存作为存储。 但是即使这样:
- 会有序列化/反序列化的费用;
- 您需要在更改时以某种方式使数据无效;
- 与仅在PHP中访问变量相比,存在一些开销。
PHP 7.0引入了
IS_ARRAY_IMMUTABLE优化。 如果声明一个数组,所有元素在编译时都是已知的,则将对其进行处理并将其放入OPCache内存一次,PHP-FPM工作人员将引用此共享内存,而无需花费时间来尝试更改。 还可以得出结论,无论大小如何(通常为〜1微秒),包含此类数组都将花费固定的时间。
为了进行比较:通过include和apcu_fetch获得10,000个元素的数组的时间示例:
$t0 = microtime(true); $a = include 'test-incl-1.php'; $t1 = microtime(true); printf("include (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6); $t0 = microtime(true); $a = apcu_fetch('a'); $t1 = microtime(true); printf("apcu_fetch (%d): %d microsec\n", count($a), ($t1-$t0) * 1e6);
如果查看生成的操作码,则检查是否已应用此优化可能非常简单:
$ cat immutable.php <?php return [ 'key1' => 'val1', 'key2' => 'val2', 'key3' => 'val3', ]; $ cat mutable.php <?php return [ 'key1' => \SomeClass::CONST_1, 'key2' => 'val2', 'key3' => 'val3', ]; $ php -d opcache.enable=1 -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 immutable.php $_main: ; (lines=1, args=0, vars=0, tmps=0) ; (after optimizer) ; /home/ubuntu/immutable.php:1-8 L0 (4): RETURN array(...) $ php -d opcache.enable_cli=1 -d opcache.opt_debug_level=0x20000 mutable.php $_main: ; (lines=5, args=0, vars=0, tmps=2) ; (after optimizer) ; /home/ubuntu/mutable.php:1-8 L0 (4): T1 = FETCH_CLASS_CONSTANT string("SomeClass") string("CONST_1") L1 (4): T0 = INIT_ARRAY 3 T1 string("key1") L2 (5): T0 = ADD_ARRAY_ELEMENT string("val2") string("key2") L3 (6): T0 = ADD_ARRAY_ELEMENT string("val3") string("key3") L4 (6): RETURN T0
在第一种情况下,很明显文件中只有一个操作码-完成数组的返回。 在第二种情况下,每次执行此文件时,都会逐个元素地形成。
因此,可以以在运行时不需要进一步转换的形式生成结构。 例如,您不必为每次自动加载而每次都用符号“ _”和“ \”来分解类名,而是可以预先生成对应关系图“ Class => Path”。 在这种情况下,转换功能将简化为单个哈希表调用。 如果启用了
optimize-autoloader选项,则Composer会进行这种优化。
对于此类数据的无效化,您无需做任何特别的事情-PHP本身将在更改时重新编译文件,就像在常规代码部署中一样。 您一定不能忘记的唯一缺点:如果文件很大,则更改后的第一个请求将导致重新编译,这可能会花费很多时间。
性能包括/要求
与静态数组示例不同,使用类和函数声明附加文件不是那么快。 尽管有OPCache,PHP引擎仍必须将它们复制到进程内存中,以递归方式连接依赖关系,最终每个文件可能要花费数百微秒甚至毫秒。
如果在
Symfony 4.1上创建一个新的空项目,并将
get_included_files()作为操作的第一行,则可以看到已经连接了310个文件。 在实际的项目中,每个请求的数量可以达到数千。 值得注意以下几点。
缺乏自动焊接功能有
功能自动加载RFC ,但是几年来还没有开发。 因此,如果Composer中的依赖项在类之外定义了函数,并且用户应该可以访问这些函数,则可以通过
将具有这些函数
的文件
强制连接到自动加载器的每个初始化来完成此操作。
例如,从composer.json中删除一个依赖项,该依赖项声明了许多功能,并且很容易被一百行代码替换,我们赢得了百分之几的CPU。
自动加载器的调用次数比看起来要多。为了演示这个想法,请使用一个类创建这样的文件:
<?php class A extends B implements C { use D; const AC1 = \E::E1; const AC2 = \F::F1; private static $as3 = \G::G1; private static $as4 = \H::H1; private $a5 = \I::I1; private $a6 = \J::J1; public function __construct(\K $k = null) {} public static function asf1(\L $l = null) :? LR { return null; } public static function asf2(\M $m = null) :? MR { return null; } public function af3(\N $n = null) :? NR { return null; } public function af4(\P $p = null) :? PR { return null; } }
注册自动加载器: spl_autoload_register(function ($name) { echo "Including $name...\n"; include "$name.php"; });
我们将为此类提供一些用例: include 'A.php' Including B... Including D... Including C... \A::AC1 Including A... Including B... Including D... Including C... Including E... new A() Including A... Including B... Including D... Including C... Including E... Including F... Including G... Including H... Including I... Including J...
您可能会注意到,当我们以某种方式连接该类但不创建其实例时,将连接父类,接口和特征。 对于作为解析连接的所有文件,将以递归方式完成此操作。
创建实例时,将向其添加所有常量和字段的解析度,从而导致为此所需的所有文件的连接,从而又将导致新连接的类的特征,父级和接口的递归连接。
 连接相关类以用于实例创建过程和其他情况
连接相关类以用于实例创建过程和其他情况没有通用的解决方案来解决这个问题,您只需要记住它并监视类之间的连接即可:一行可以拉动数百个文件的连接。
OPCache设置如果使用
原子部署方法
通过更改 PHP创建者Rasmus Lerdorf提出
的符号链接来使用
原子部署方法,那么要
解决将符号链接“粘贴”在旧版本上的问题,您必须包含opcache.revalidate_path,例如,在
本文中有关此建议的建议中,例如
本文推荐的.Ru集团。
问题在于,此选项会显着(平均一两次半到两次)增加包含每个文件的时间。 总体而言,这可能会消耗大量资源(在我们的示例中,禁用此选项可获得7-9%的收益)。
要禁用它,您需要做两件事:
- 使 Web服务器解析符号链接;
- 停止沿着包含符号链接的路径连接PHP脚本内的文件,或强制它们通过readlink()或realpath()。
如果所有文件都用Composer自动加载器连接,则第二项将在第一个项完成后自动执行:omposer使用__DIR__常量,它将被正确解析。
OPCache具有更多选项,可以提高性能以换取灵活性。 您可以在我上面提到的
文章中了解有关此内容的更多信息。
尽管进行了所有这些优化,include仍然不是免费的。 为了解决这个问题,PHP 7.4计划添加
preload 。
APCu锁
尽管这里我们不讨论数据库和服务,但是代码中也可能发生各种类型的锁,这增加了脚本的执行时间。
随着请求的增加,我们注意到高峰时段的响应速度急剧下降。 在找出原因之后,事实证明,尽管APCu是获取数据的最快方法(与Memcache,Redis和其他外部存储相比),但在频繁覆盖相同密钥的情况下,它也可以缓慢运行。
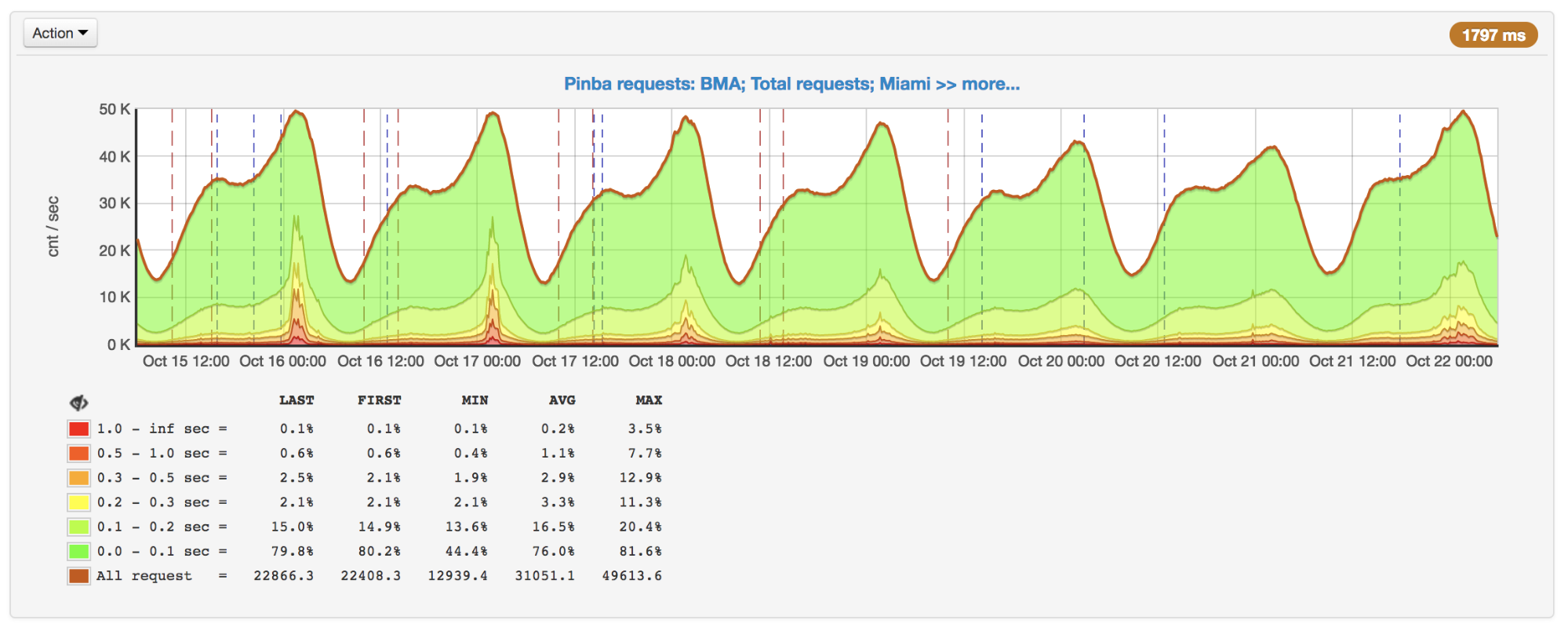 每秒请求数和运行时间:10月16日和17日达到峰值
每秒请求数和运行时间:10月16日和17日达到峰值当使用APCu作为缓存时,此问题并不那么重要,因为缓存通常涉及罕见的写入和频繁的读取。 但是某些任务和算法(例如
Circuit Breaker (
用PHP实现 ))也涉及频繁记录,这会导致锁定。
对于此问题,还没有通用的解决方案,但是在使用断路器的情况下,例如可以通过将其放入安装在装有PHP的计算机上的
单独服务中来解决。
批处理
即使不考虑include,通常查询的大部分时间仍会花在初始化上:框架(例如,构建DI容器并初始化其所有依赖项,路由,执行所有侦听器),引发会话,User等。进一步。
如果您的后端是用于某些内容的内部API,则对于某些请求,可以将客户端上的某些请求打包并作为单个请求发送。 在这种情况下,将对多个请求执行一次初始化。
, , . - , . .
Badoo , . PHP-FPM, CPU, , , : IO, CPU .
PHP-FPM — , PHP.
(CPU, IO), . , , , , - , . , . , , .
结论
. PHP .
:
- ;
- ;
- - , : , ;
- : (, , );
- : ;
- , OPCache PHP, , , ;
- : (, , PHP 7.2 , );
- : , .
?
感谢您的关注!