对于那些喜欢我
上一篇文章的人 ,我将继续分享他们对Locust压力测试工具的印象。
我将尝试清楚地演示使用代码编写负载测试python的优点,在代码中您可以方便地为测试准备任何数据并处理结果。
服务器响应处理
有时在负载测试中,仅从HTTP服务器获得200 OK还是不够的。 发生这种情况时,有必要检查响应的内容,以确保服务器在负载下发出正确的数据或执行准确的计算。 仅在这种情况下,Locust添加了覆盖服务器响应成功参数的功能。 考虑以下示例:
from locust import HttpLocust, TaskSet, task import random as rnd class UserBehavior(TaskSet): @task(1) def check_albums(self): photo_id = rnd.randint(1, 5000) with self.client.get(f'/photos/{photo_id}', catch_response=True, name='/photos/[id]') as response: if response.status_code == 200: album_id = response.json().get('albumId') if album_id % 10 != 0: response.success() else: response.failure(f'album id cannot be {album_id}') else: response.failure(f'status code is {response.status_code}') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
它只有一个请求,它将在以下情况下产生负载:
从服务器,我们请求带有随机ID的照片对象(范围为1到5000),并检查该对象中的相册ID(假设它不能为10的倍数)
在这里,您可以立即给出一些解释:
- 以request()作为响应的出色构造:您可以成功地将其替换为response = request()并与响应对象一起安静地工作
- 如果没有记错的话,URL是使用python 3.6中添加的字符串格式语法形成的-f'/ photos / {photo_id}' 。 在以前的版本中,此设计将不起作用!
- 我们之前从未使用过的新参数catch_response = True告诉Locust我们自己将确定服务器响应的成功。 如果您未指定它,那么我们将以相同的方式接收响应对象,并且能够处理其数据,但不能重新定义结果。 下面是一个详细的示例。
- 另一个参数名称='/ photos / [id]' 。 需要对统计信息中的请求进行分组。 名称可以是任何文本,无需重复URL。 没有它,每个具有唯一地址或参数的请求将被分别记录。 运作方式如下:
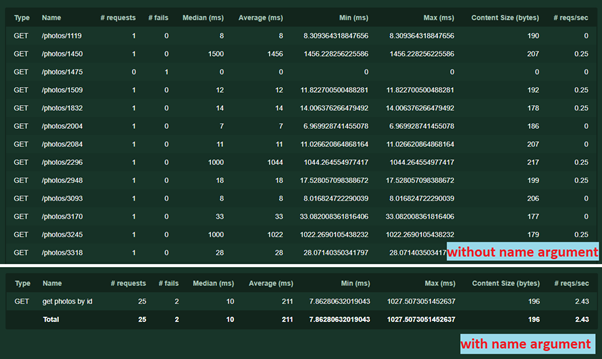
使用相同的参数,您可以执行另一把戏-有时碰巧一个具有不同参数(例如POST请求的不同内容)的服务执行不同的逻辑。 为了避免混淆测试结果,您可以编写几个单独的任务,为每个任务指定自己的参数
名 。
接下来,我们进行检查。 我有两个,首先,如果
response.status_code == 200 ,我们验证服务器是否返回了答案:
如果是,则检查相册的ID是否为10的倍数。如果不是,则将该答案标记为成功
响应。成功
()在其他情况下,我们指出了为什么响应失败
response.failure(“错误文本”) 。 测试期间,此文本将显示在“失败”页面上。
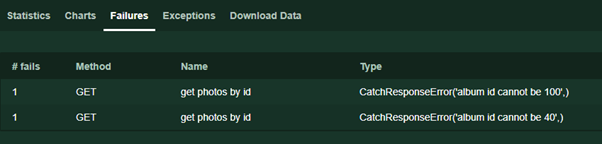
同样,细心的读者可能会注意到缺少与网络接口一起工作的代码所特有的异常。 实际上,在超时,连接错误和其他意外事件的情况下,Locust将处理错误并仍然返回响应,但是指示响应代码的状态为0。
如果代码仍然抛出异常,则会在运行时将其写入“异常”选项卡,以便我们进行处理。 最典型的情况是答案的json'e没有返回我们正在寻找的值,但是我们已经对其进行了以下操作。
在结束主题之前-在本示例中,为清晰起见,我使用json服务器,因为处理响应更加容易。 但是,您可以使用基于HTTP的协议使用的HTML,XML,FormData,文件附件和其他数据获得同样的成功。
处理复杂的场景
几乎每当任务是对Web应用程序进行负载测试时,很快就会发现,仅使用GET服务(仅返回数据)是不可能提供良好覆盖的。
经典示例:要测试在线商店,用户最好
- 开设总店
- 我在找货
- 打开项目的详细信息
- 添加到购物车
- 已付费
从该示例中,我们可以假定以随机顺序调用服务将不起作用,而只能依次进行。 此外,商品,购物篮和付款方式可能对每个用户都有唯一的标识符。
使用前面的示例,并进行少量修改,您可以轻松地实现对这种情况的测试。 我们为测试服务器修改示例:
- 用户正在撰写新帖子。
- 用户在新帖子上发表评论
- 用户阅读评论
from locust import HttpLocust, TaskSet, task class FlowException(Exception): pass class UserBehavior(TaskSet): @task(1) def check_flow(self):
在此示例中,我添加了一个新的
FlowException类。 在每个步骤之后,如果没有按预期进行,我将抛出此异常类以中断脚本-如果发布无效,则将无可奉告,依此类推。 如果需要,可以用通常的
return代替该构造,但是在这种情况下,在执行过程中以及分析结果时,不清楚执行的脚本在“异常”选项卡上的位置。 出于相同的原因,
除了构造
之外 ,我不使用
try...。使负载逼真
现在可以责骂我了-在商店的情况下,一切都是线性的,但是带有帖子和评论的示例牵强附会-他们阅读帖子的频率是其创建内容的10倍。 合理地,让我们使该示例更可行。 至少有两种方法:
- 如果可能,您可以“硬编码”用户阅读的帖子列表,并简化测试代码,并且后端的功能不取决于特定的帖子
- 保存创建的帖子并阅读它们,如果无法预先设置帖子列表,或者实际负载取决于阅读哪些帖子(我从示例中删除了注释的创建,以使其代码更小,更直观)
from locust import HttpLocust, TaskSet, task import random as r class UserBehavior(TaskSet): created_posts = [] @task(1) def create_post(self): new_post = {'userId': 1, 'title': 'my shiny new post', 'body': 'hello everybody'} post_response = self.client.post('/posts', json=new_post) if post_response.status_code != 201: return post_id = post_response.json().get('id') self.created_posts.append(post_id) @task(10) def read_post(self): if len(self.created_posts) == 0: return post_id = r.choice(self.created_posts) self.client.get(f'/posts/{post_id}', name='read post') class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
在
UserBehavior类中
,我创建了
created_posts列表。 请特别注意-这是一个对象,它不是在
__init __()类的构造函数中创建的
,因此,与客户端会话不同,此列表对于所有用户都是通用的。 第一个任务创建一个帖子,并将其ID写入列表。 第二个-频繁10倍,从列表中读取一个随机选择的帖子。 第二项任务的另一个条件是检查是否创建了任何帖子。
如果希望每个用户仅使用自己的数据进行操作,则可以在构造函数中声明它们,如下所示:
class UserBehavior(TaskSet): def __init__(self, parent): super(UserBehavior, self).__init__(parent) self.created_posts = list()
其他功能
对于顺序启动任务,官方文档建议我们还使用@seq_task(1)任务批注,在参数中指定任务序列号
class MyTaskSequence(TaskSequence): @seq_task(1) def first_task(self): pass @seq_task(2) def second_task(self): pass @seq_task(3) @task(10) def third_task(self): pass
在此示例中,每个用户将首先执行
first_task ,然后执行
second_task ,然后执行10次
third_task 。
坦率地说,这种机会的可用性令人愉悦,但与前面的示例不同,尚不清楚如何在必要时将第一个任务的结果转移到第二个任务。
同样,对于特别复杂的场景,可以创建嵌套的任务集,实际上,可以创建多个TaskSet类并相互连接。
from locust import HttpLocust, TaskSet, task class Todo(TaskSet): @task(3) def index(self): self.client.get("/todos") @task(1) def stop(self): self.interrupt() class UserBehavior(TaskSet): tasks = {Todo: 1} @task(3) def index(self): self.client.get("/") @task(2) def posts(self): self.client.get("/posts") class WebsiteUser(HttpLocust): task_set = UserBehavior min_wait = 1000 max_wait = 2000
在上面的示例中,概率为1到6的
Todo脚本将被启动并执行直到概率为1到4的
Todo脚本返回到
UserBehavior脚本。 调用
self.interrupt()非常重要-没有它,测试将集中在子任务上。
感谢您的阅读。 在最后一篇文章中,我将介绍分布式测试和不带UI的测试,以及在使用Locust进行测试时遇到的困难以及如何解决它们。