
Habr,这是软件工程师Alexei Starkov在莫斯科举行的Moscow Python Conf ++ 2018大会上的一份报告。 帖子末尾的视频。
大家好! 我的名字叫阿列克谢·斯塔科夫(Alexei Starkov),这就是我,在我最好的几年里,我在工厂工作。
现在,我在Qrator Labs工作。 基本上,我一生都在学习C和C ++-我爱Alexandrescu,四人帮,SOLID原理-仅此而已。 这使我成为一名建筑宇航员。 最近几年我一直在编写Python,因为我喜欢它。
实际上,谁是“建筑宇航员”? 我第一次与Joel Spolsky见过这个词时,您可能读过它。 他将“宇航员”描述为想要建立一种理想的体系结构的人,这些体系结构依赖于抽象,过分抽象,过分抽象,而后者正变得越来越普遍。 最后,这些级别很高,以至于它们描述了所有可能的程序,但是并不能解决任何实际问题。 此刻,“宇航员”(这是该词最后一次用引号引起来)耗尽了生命,死了。
我也倾向于进行建筑空间探索,但是在本报告中,我将稍微谈谈它如何困扰我,并且不允许我构建具有必要性能的系统。 最主要的是我如何克服它。
我的报告摘要:was / was。

增加了成千上万倍。 当我制作这张幻灯片时,我唯一想到的是“如何?”

我在哪里可以搞砸呢? 如果您不想像我一样搞砸,请继续阅读。

我将讨论配置系统。 配置系统是Qrator Labs中的内部工具,用于存储软件定义网络(SDN)(我们的过滤网络)的配置。 它致力于在组件之间同步配置并监视其状态。

简而言之,它由什么组成? 我们有一个数据库,其中存储了整个网络的配置快照,还有一个服务器,用于处理向其发送的命令并以某种方式更改配置。
我们的技术管理员和客户会通过控制台,控制台,端点API,REST API,JSON RPC等访问服务器,并向服务器发出命令,从而改变服务器的配置。
团队可以非常简单,也可以更复杂。 然后,我们有一组特定的接收器组成了我们的SDN,服务器将配置推送到这些接收器。 听起来很简单。 基本上,我将谈论这部分。
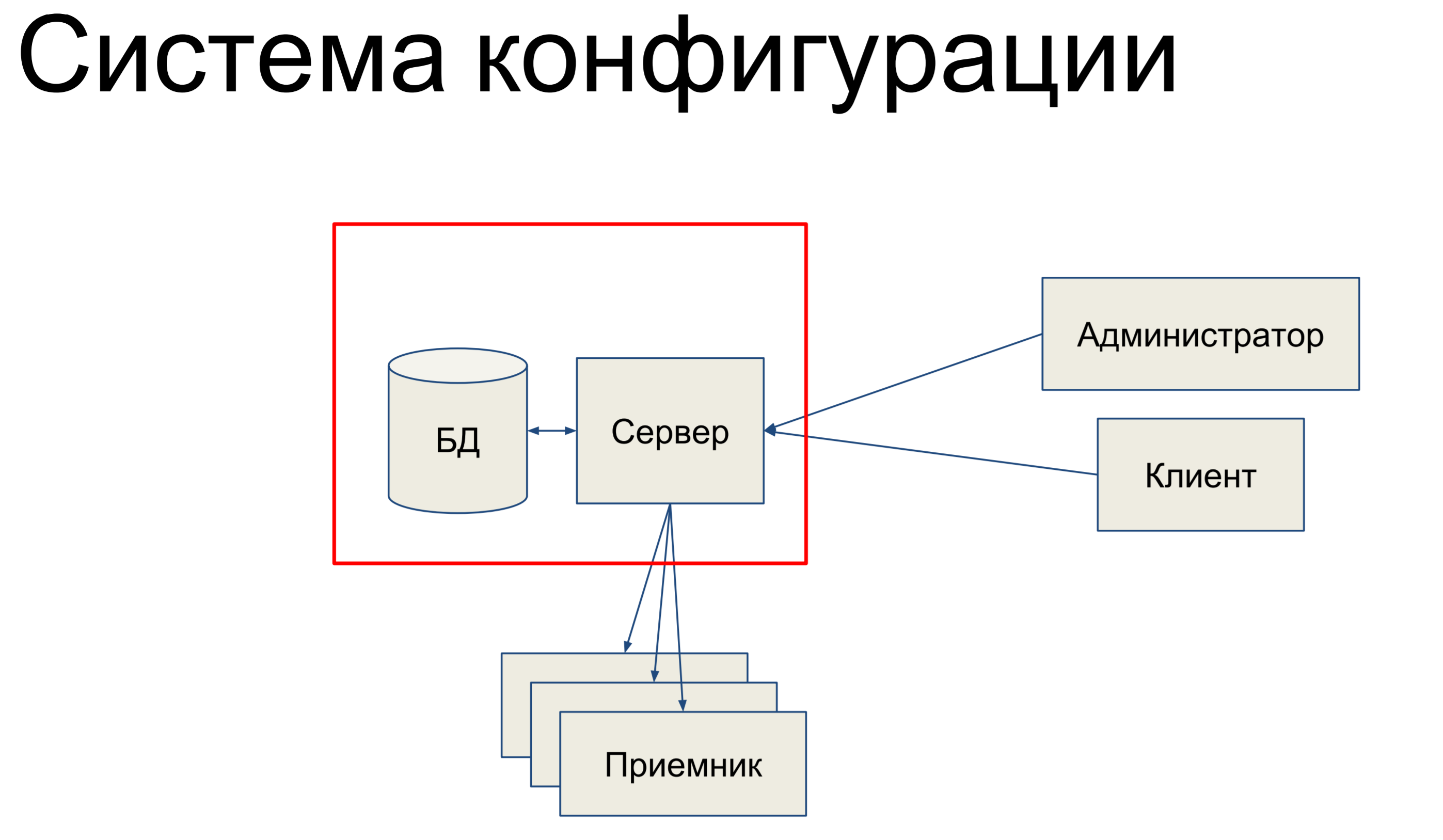
由于她是与数据库和炼金术有关的人。

这个系统的特点是什么? 它很小-平庸。 该数据库中存储了数十万个(最多数百万个)实体。 独特之处在于实体之间的关系图非常复杂。 实体之间有几个继承层次结构,有包含关系,它们之间只是依赖关系。 所有这些限制由业务逻辑确定,我们必须遵守它们。
写请求与读请求的比率约为15:1。 显然,这里有很多命令可以更改配置,并且在很长一段时间内,我们都会将配置推送到端点。
MySQL在内部使用-它在我们公司的其他产品中也可用,我们在该数据库中拥有非常认真的专业知识,有人可以使用它:构建数据方案,设计查询以及其他所有功能。 因此,我们将MySQL作为通用的关系数据库。

设计此系统后出现了什么问题? 根据团队的复杂程度,执行一条命令需要一到30秒。 因此,执行延迟达到了五分钟。 一支队伍到达了-30秒,第二组,依此类推,累积了一堆-延迟了5分钟。
应用配置的延迟最多为十分钟。 决定这对我们来说还不够,因此有必要进行优化。

首先,在进行任何优化之前,有必要进行调查并找出实际上是问题所在。

事实证明,我们缺少该调查最重要的组成部分-我们没有遥测技术。 因此,如果要设计某种系统,请首先在设计阶段将遥测技术放入其中。 即使系统最初很小,然后再增加一点,然后再增加-最后,每个人都会遇到需要观看曲目但没有遥测的情况。
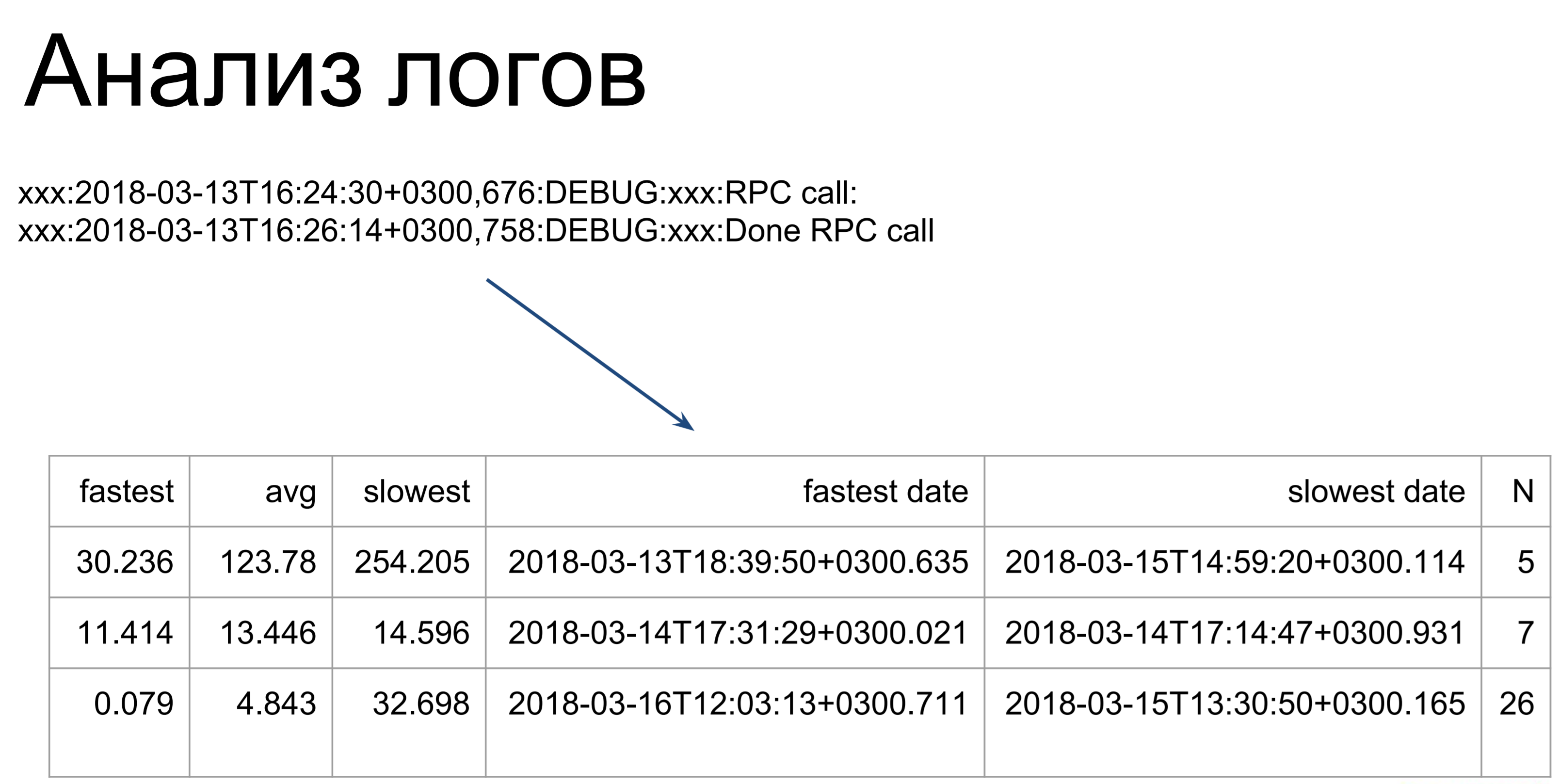
如果您没有遥测,下一步该怎么办? 您可以分析日志。 在这里,相当简单的脚本会遍历我们的日志,并将它们转换成这样的表,说明最快,最慢和平均的命令执行时间。 从这里开始,我们已经可以看到我们在哪些地方存在插科打::哪些团队需要更长的时间来执行,哪些更快。

唯一需要注意的是,在分析日志时,我们仅考虑这些命令在服务器上的执行时间。 这是第一阶段-标记为t2的阶段。 t1-这是客户如何看待我们团队的执行时间:进入队列,等待,在服务器上执行。 该时间将更长,因此我们优化时间t2,然后使用时间t1确定我们是否已达到目标。
t1是我们绩效的质量指标。

相应地,这就是我们分析所有团队的方式-也就是说,我们从服务器上获取日志,将其遍历脚本,查看并确定工作最慢的组件。 服务器是完全模块化地构建的,每个命令负责一个单独的组件,我们可以分别分析这些组件-并为它们制定基准。 因此,这里有一个类-对于我们编写的每个有问题的组件,在code_under_test()中我们进行了一些描述该组件战斗使用的活动。 并且有两种方法:profile()和Bench()。 第一个调用cProfile,显示调用了多少次,瓶颈在哪里。
Bench()运行了几次,并为我们考虑了不同的指标-这就是我们评估效果的方式。
但是事实证明这不是问题!

主要问题是数据库查询的数量。 有很多请求,为了了解为什么有这么多请求,让我们看一下所有内容的组织方式。
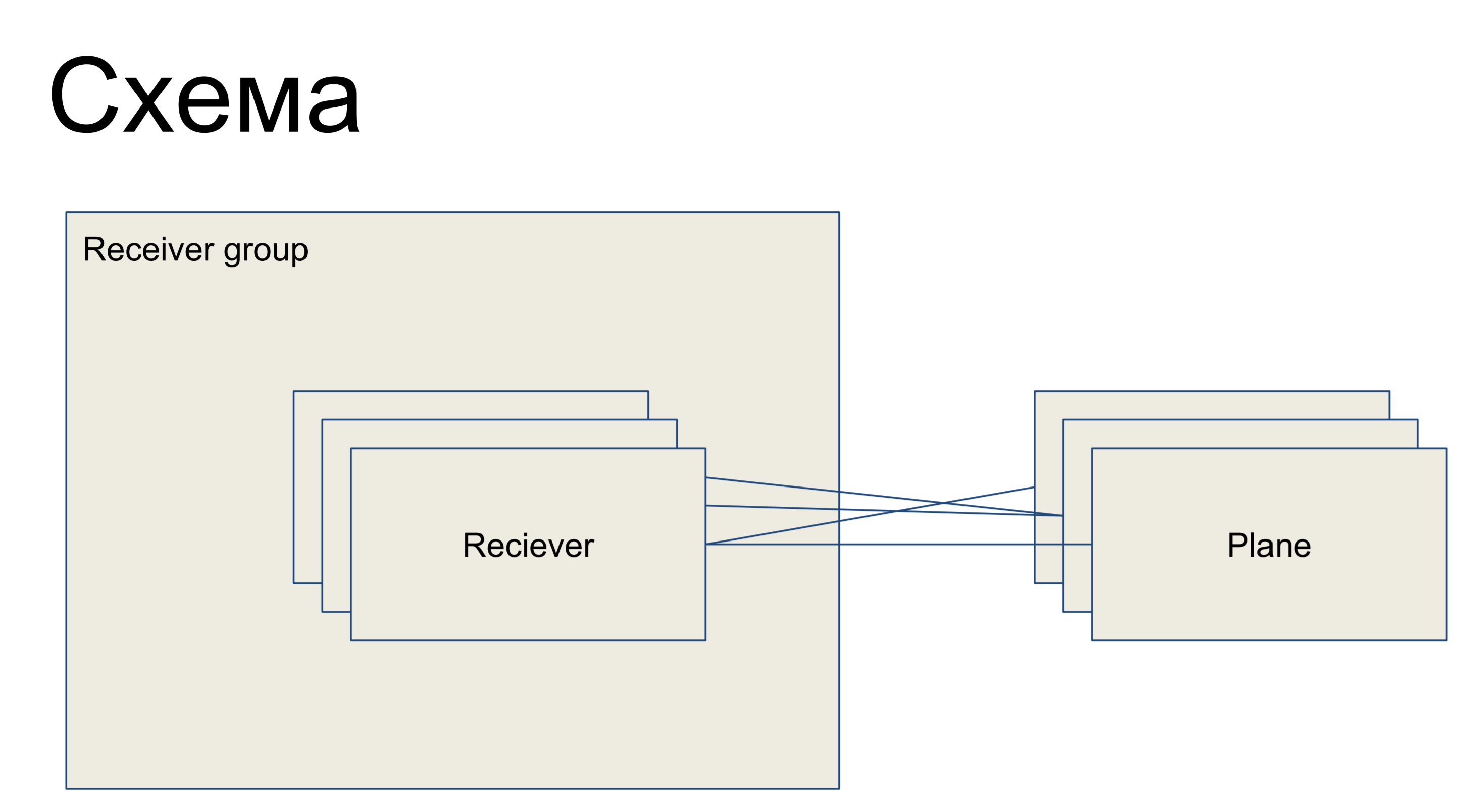
在我们面前的是代表接收器的一个简单电路,以接收器类的形式呈现。 它们合并在某个组中-接收器组。 并且,因此,存在一些配置平面-配置的切片,它们是配置的子集,负责该接收器的一个“角色”。 例如,对于路由-路由平面。 具有接收器的平原可以以任何顺序连接-也就是说,这是多对多关系。
这是我在这里提出的大轮廓中的一部分,以便可以进一步理解示例。
每个建筑宇航员看到别人的API时想做什么? 他想要隐藏它,提取并编写他的接口,以便能够删除该API,或者更确切地说,将其隐藏。
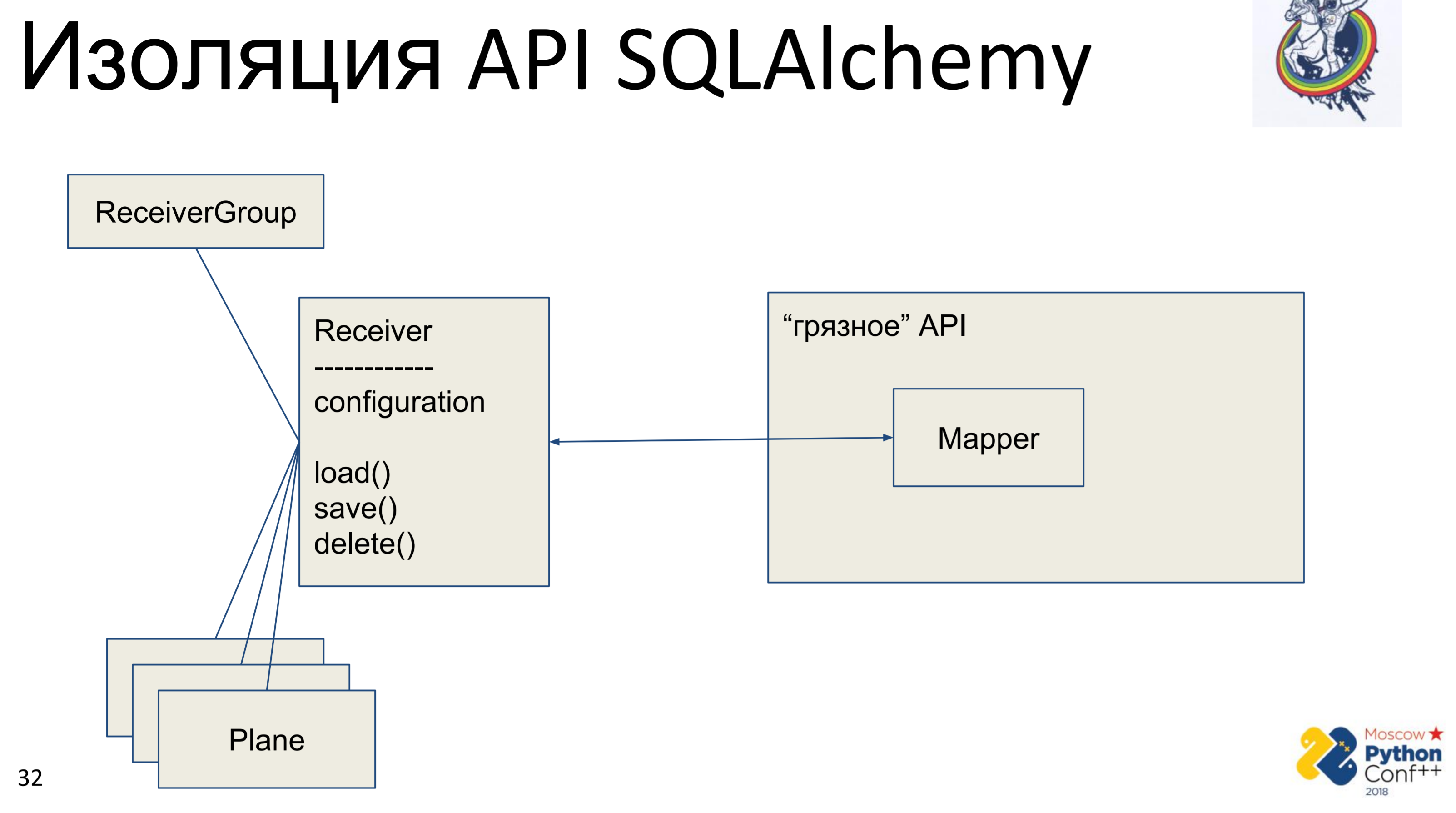
因此,有一个“肮脏的”炼金术API,实际上其中有映射器和我们的“纯”类-Receiver,其中存储了一些配置,并且有以下方法:load(),save(),delete()。 以及与此相关的所有其他类。 我们得到了一个Python对象图,它们以某种方式相互连接-每个对象都有一个load(),save(),delete()方法,该方法引用炼金术映射器,该映射器又调用API。

这里的实现非常简单。 我们有一个load方法,该方法对数据库进行查询,并为每个接收到的对象创建自己的Python对象。 有一个save方法执行相反的操作-使用主键查看数据库中是否存在对象,如果没有,则创建,添加,然后保存该对象的状态。 主键上的delete接收并从数据库中删除对象。

主要问题立即可见-这是映射。 首先,我们从Python对象到映射器执行一次,然后从映射器对基础执行一次。 额外的映射是一个或两个调用,这可能还不那么可怕。 主要问题是手动同步。 我们有两个“干净”界面的对象,其中一个更改了属性-我们如何看到另一个属性已更改? 没办法 必须将更改合并到数据库中,并在另一个对象中获取属性。 当然,如果我们知道对象存在于同一上下文中,则可以以某种方式对其进行跟踪。 但是,如果我们在不同的地方有两个会话-仅通过基本会话,或者在内存中阻塞了基本会话,而我们没有这样做。
加载/保存/删除是另一个映射器,它完全复制了炼金术的内部,这些都经过了良好的编写和测试。 这个工具已经使用了很多年,在互联网上有很多帮助并且复制它也不是很好。
看到右上角的图标吗? 因此,我将标记为“纯度”做了一些处理的幻灯片,以提高建筑航天的抽象水平。 也就是说,没有此图标的幻灯片是实用的,无聊的,无趣的并且无法阅读。
如果很多查询很慢该怎么办。 几根 其实很多。 想象一下一个继承链:一个对象,它有一个父对象,一个对象有另一个父对象。 我们同步子对象-为此,您首先需要同步父对象。 为了同步父级,您需要同步其父级。 好吧,每个人都同步了。 实际上,根据我们如何构建图形,我们可以遍历和同步所有这些对象一百次-因此有大量的请求。
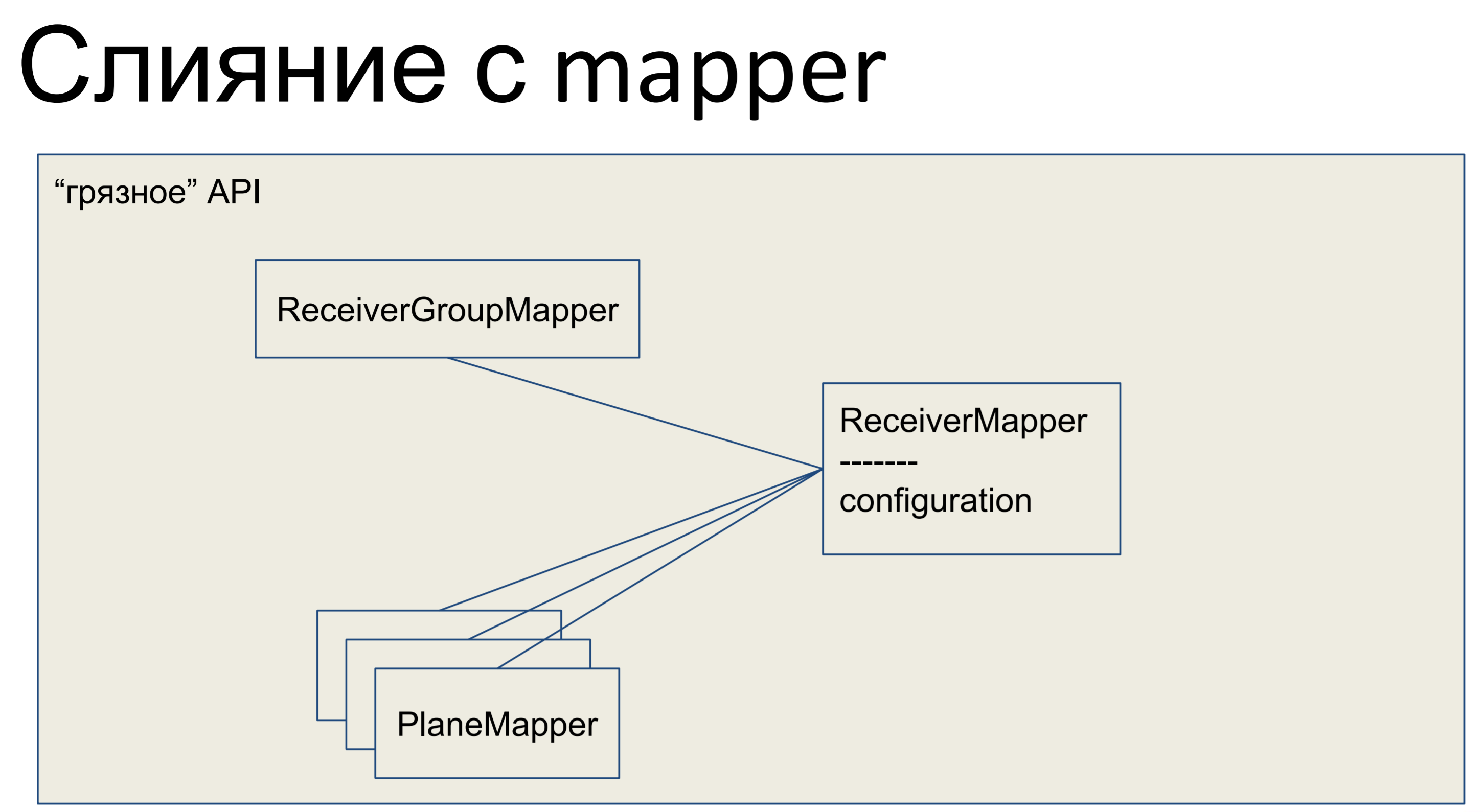
我们做了什么? 我们采用了所有业务逻辑并将其粘贴在映射器中。 这里的所有其他对象也与映射器合并,并且我们的整个API(整个数据抽象层)变得很脏。

这就是在Python中的样子-我们的映射器具有某种业务逻辑,在那里有此板的说明性描述。 列出了列,关系。 在这里,我们有这样的一类。

当然,从任何宇航员的角度来看,肮脏的API都是一个缺点。 在声明性描述基础中的业务逻辑。 方案与业务逻辑混合在一起。 ew 丑
电路的描述混乱。 这实际上是一个问题-如果业务逻辑没有两行,但是有很多行,那么在此类中,我们需要滚动或搜索很长时间才能获得特定的描述。 在此之前,一切都是美好的:在一个地方,对基础的描述,声明式,对方案的描述,在另一个地方,是业务逻辑。 然后电路杂乱无章。
但是,另一方面,我们立即获得了炼金术的机制:工作单元,它使您可以跟踪哪些对象脏了,哪些继电器需要更新; 我们建立了一种关系,使我们可以摆脱数据库中的其他问题,而无需确保填充了相关的馆藏; 以及对我们帮助最大的身份地图。 身份映射确保两个Python对象如果具有相同的主键,则它们将是相同的Python对象。
因此,我们立即将复杂度降低为线性。

这些是中间结果。 性能立即提高了10倍,对数据库的查询数量下降了约40-80倍,RPS上升到1-5。 好,好 但是API很脏。 怎么办
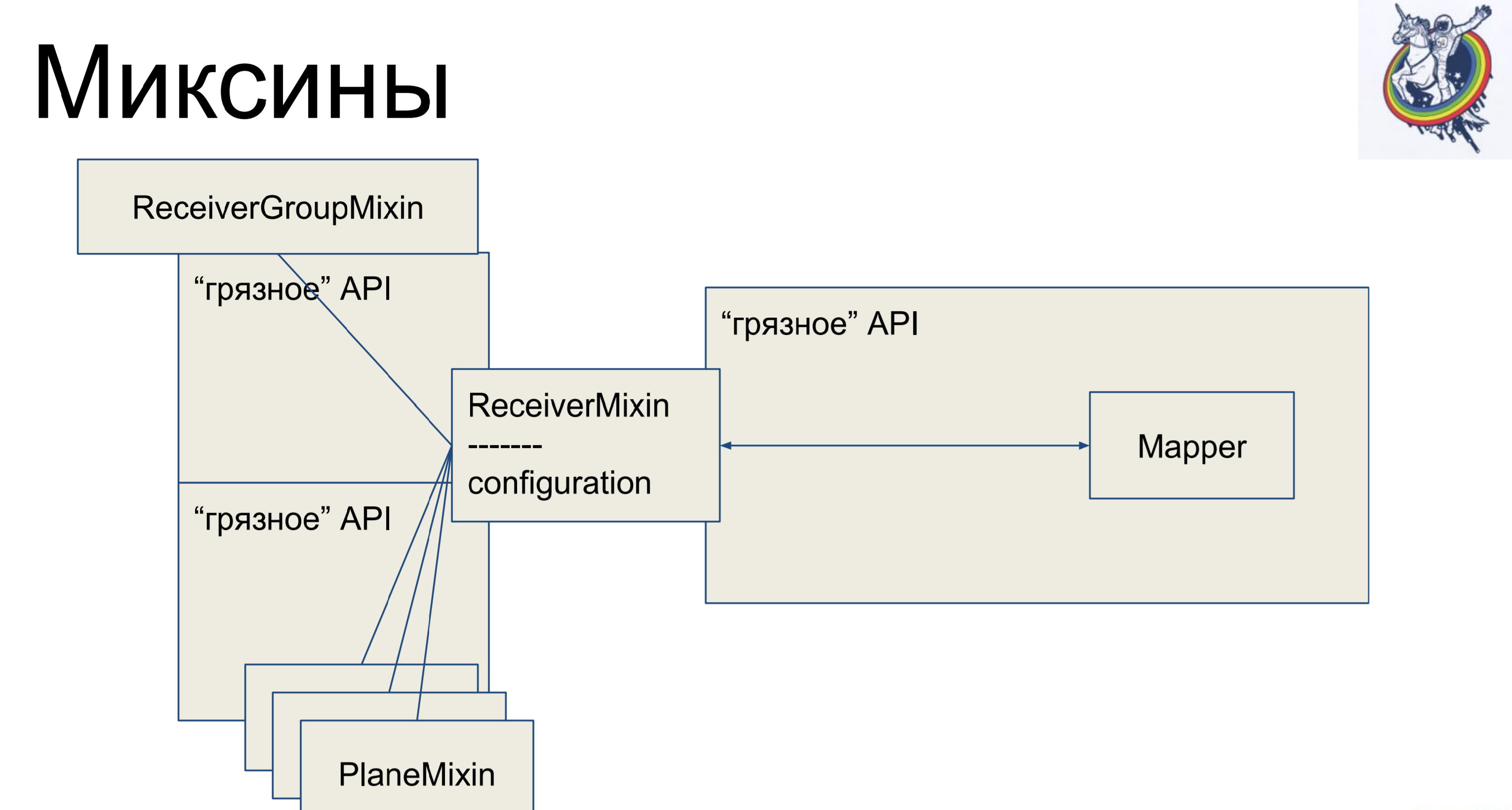
Mixins。 我们采用业务逻辑,再次从映射器中将其删除,但是为了再次没有映射,我们将从mixin继承炼金术内部的映射器。 为什么不反过来呢? 这在炼金术中是行不通的,她会发誓说:“您有两种不同的类,指的是一种片剂,没有多态性-请从这里开始。” 等等-这是可能的。
因此,我们在映射器中有一个声明性描述,该描述从mixin继承并接收所有业务逻辑。 很舒服 其余的类完全相同。 看起来很酷,一切都很干净。 但是有一个警告:炼金术内部仍然存在连接和中继,并且例如当我们通过一个中间板辅助表进行连接时,该板的映射器将以某种方式出现在客户端代码中,这不是很漂亮。
如果没有给我机会对抗这个问题,炼金术将不会是一个如此出色,著名的框架。

什么是mixin。 他具有业务逻辑,而映射器则是分开的,是板的说明性描述。 连接保留在炼金术中,但是业务逻辑是独立的。
总体轮廓是什么样的?
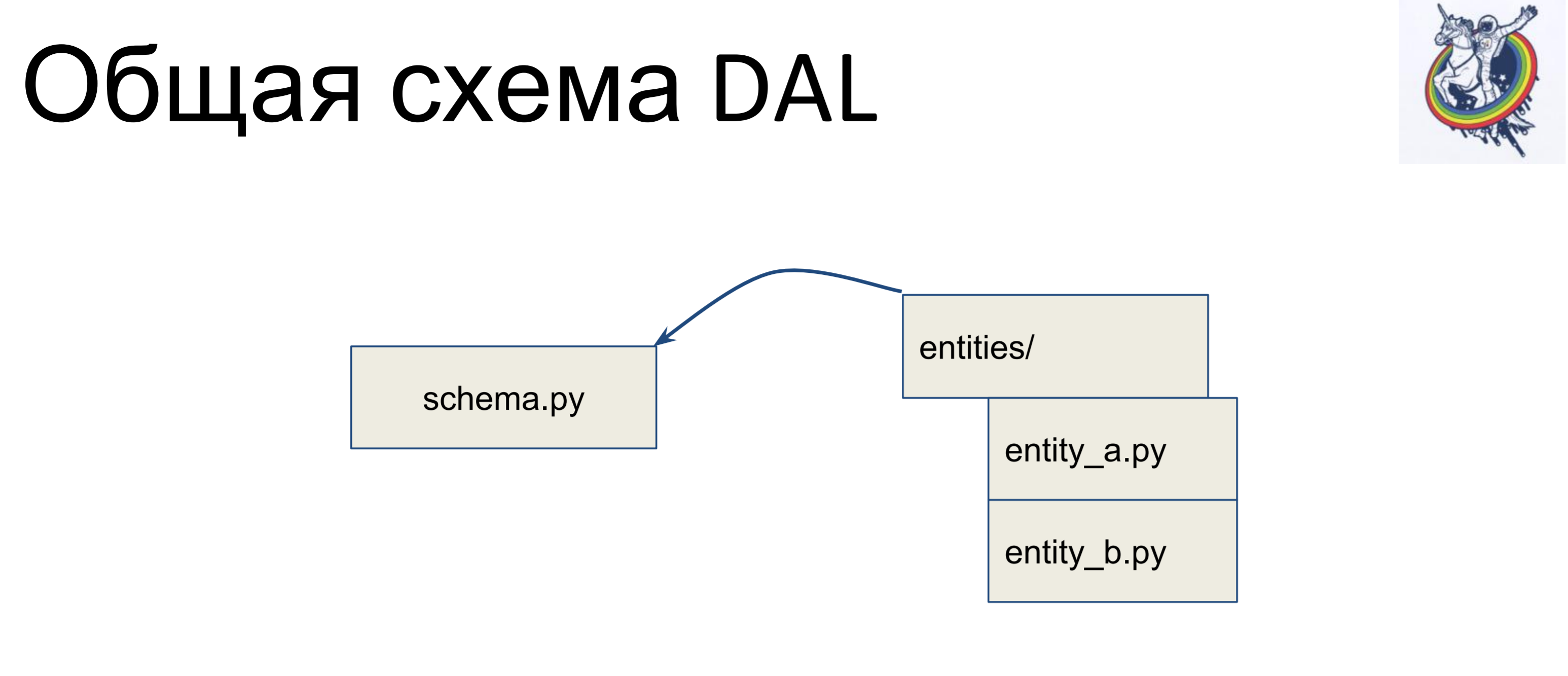
我们有一个带有计划的文件,其中收集了我们所有的声明性类-我们将其称为schema.py。 我们分别在业务逻辑中拥有实体。 而且,这些实体在架构文件中继承-我们为每个实体编写一个单独的类,然后在架构中继承它。 因此,业务逻辑位于一个堆中,方案位于另一个堆中,并且它们可以独立更改。
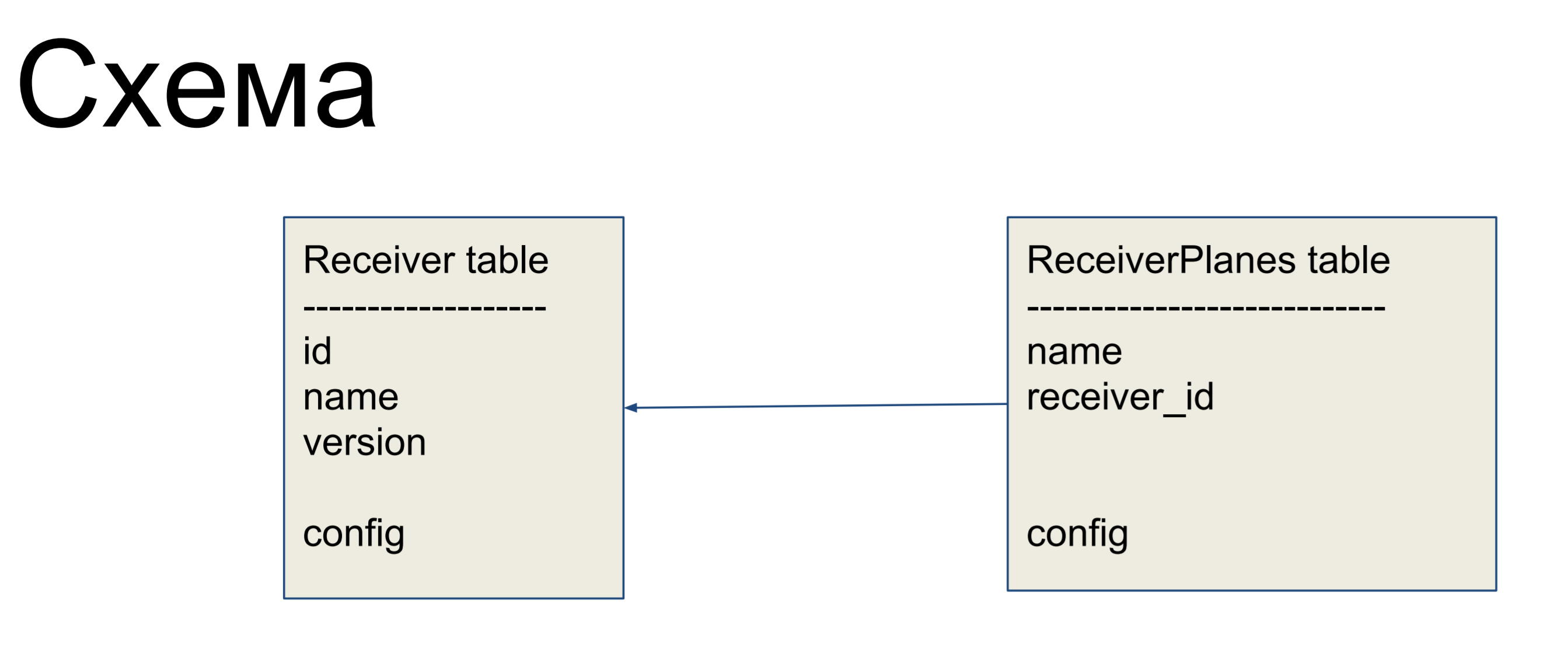
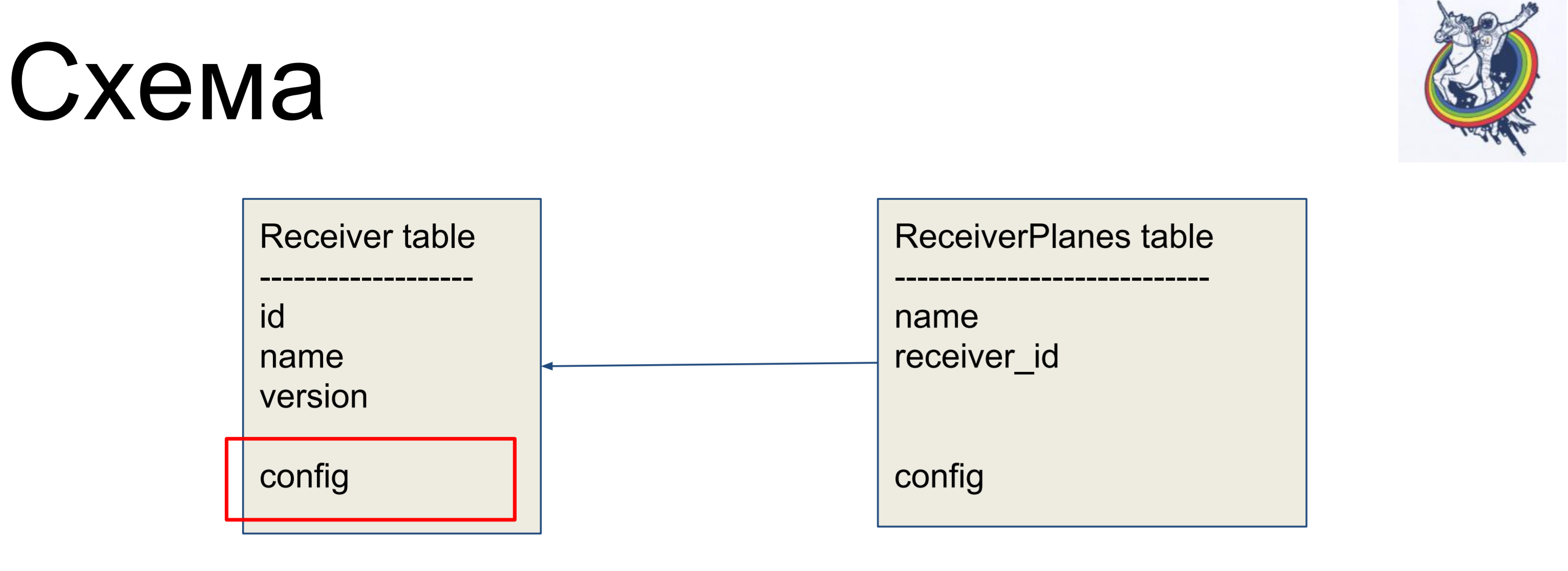
作为改进示例,我们将考虑一个简单的方案,该方案包含两个标签:接收方(Receiver表)和配置切片(ReceiverPlanes表)。 多对一的配置片与接收器标签关联。 没有什么特别复杂的。
为了在炼金术的“肮脏”界面中隐藏关系,我们使用关系和集合。

它们允许我们从客户端代码中隐藏映射器。

特别是,两个非常有用的集合是association_proxy和attribute_mapped_collection。 我们一起使用它们。 古典关系在炼金术中是如何工作的:我们有一个关系-这是一个确定的集合,列表和映射器。 映射器是远端关系对象。 Attribute_mapped_collection允许您用dict替换此列表,其中的键将是映射器的某些属性,而值是映射器本身。
这是第一步。
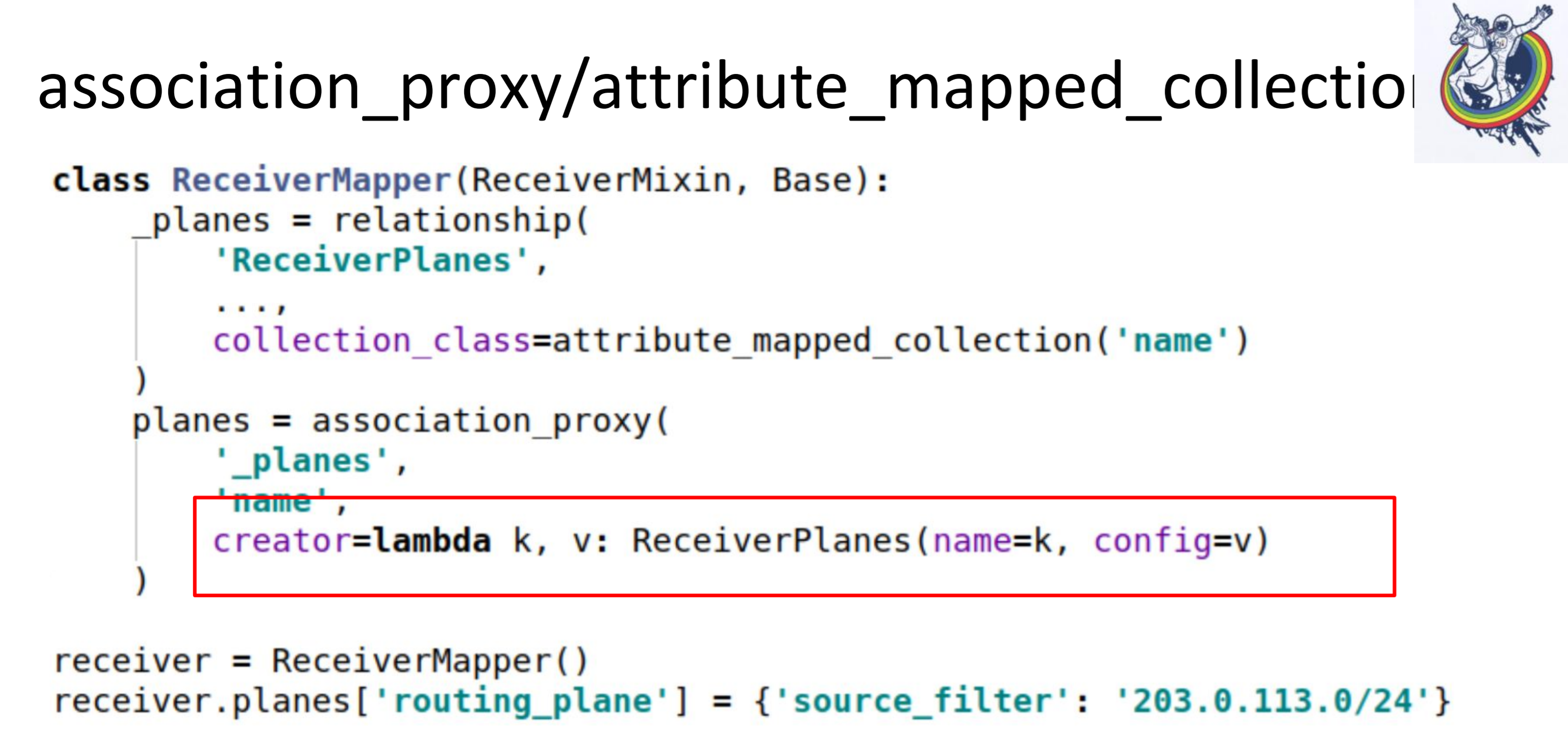
第二步,我们对这个关系进行association_proxy。 它允许我们不要将映射器传递给集合,而是传递一些值,该值稍后将用于初始化我们的映射器ReceiverPlanes。
在这里,我们有lambda,在其中我们传递了键和值。 密钥变成配置片的名称,值变成配置片的值。 结果,在客户端代码中,一切看起来都像这样。

我们只是在某种字典中添加了某种命令。 一切正常:没有映射器,炼金术士,没有数据库。
没错,有陷阱。

如果我们两次给相同的键分配不同的值,甚至是一个值,则两次-为每个此类set项调用lambda,将创建一个对象-映射器。 并且,根据方案的结构,这可能导致各种后果,从“仅仅违反常数”到不可预测的后果。 例如,您从集合中删除了一个对象,但该对象仍然保留在其中:仅删除了一个。 刚开始时,我在此类事情上花了很多时间。
和一点隐式同步。 Association_proxy和attribute_mapped_collection可能会稍有延迟:创建映射器对象时,它会添加到数据库中,但尚未出现在collection属性中。 仅当该属性在此会话中过期时,它才会出现在此处。 当它到期时,将与数据库进行新的同步并将到达该同步。
为了克服这个问题,我们使用了自己的,手写的集合。 这甚至都不是炼金术-您可以创建自己的收藏来克服所有这些。
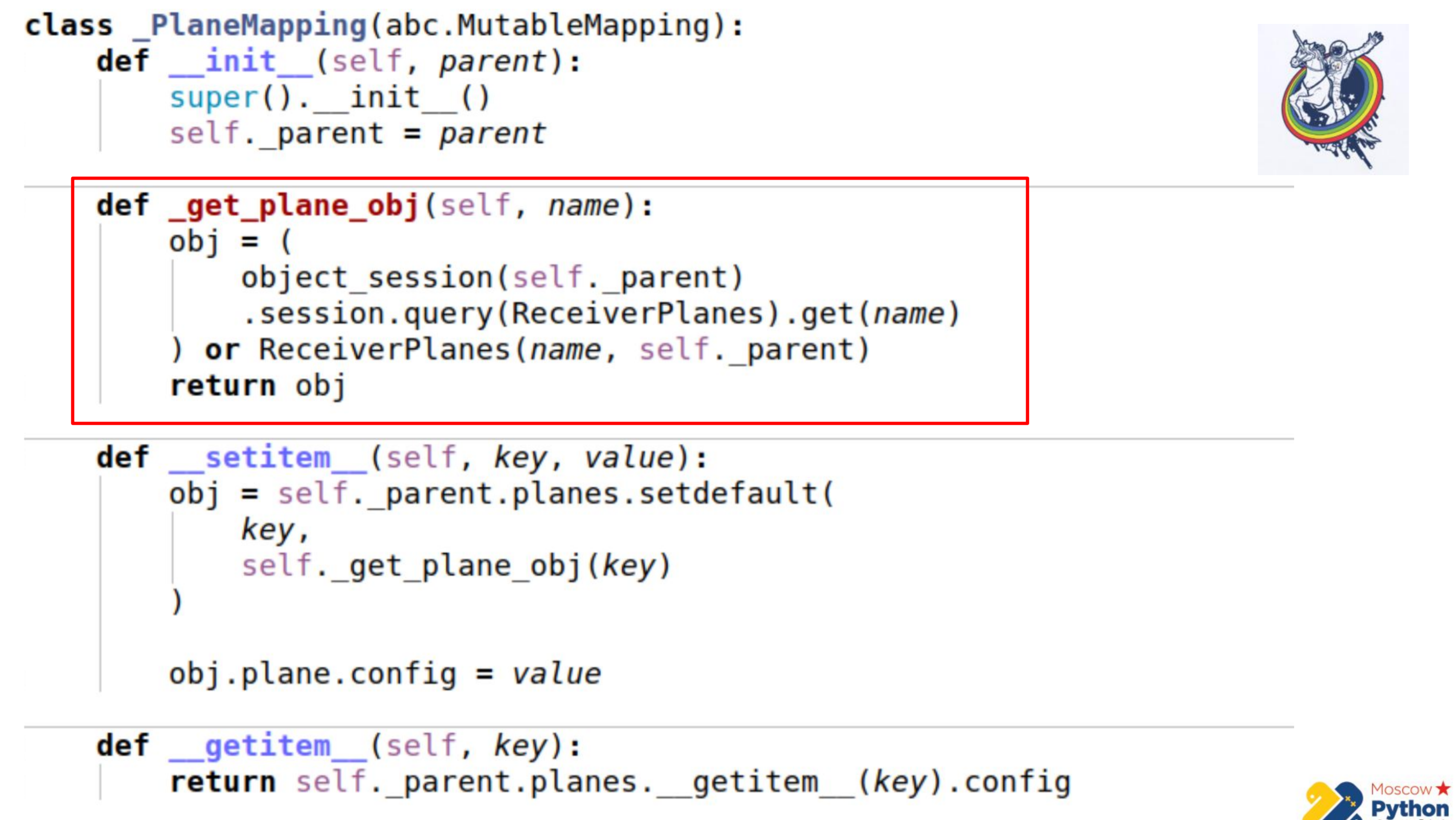
有更多代码,最重要的部分已突出显示。 我们有一个继承自可变映射的特定集合-这是一个dict,您可以在其键中更改值。 并且有一个_get_plane_obj方法-获取配置切片对象。
在这里,我们做一些简单的事情-我们尝试通过名称,某个主键来获取它,如果不是,则创建并返回该对象。
接下来,我们重新定义两种方法:__setitem__和__getitem__
在__setitem__中,我们以关联关系将这些对象放入集合中。 唯一的事情是我们在最后分配值。 因此,我们实现了与association_proxy相同的机制-将值传递给dict,然后将其分配给相应的属性。
__getitem__进行反向操作。 它通过键从中继接收一些对象并返回其属性。 这里也有一个小陷阱-如果您将集合缓存在我们的映射中,则可能会有点不同步。 因为当炼金术中集合的属性过期时,过期后该集合将被另一个替换。 因此,我们可以保留对旧集合的引用,而不必知道旧集合已经过期而新集合已经出现。 因此,在最后一部分中,我们直接进入炼金术实例,再次通过__getattr__获取集合,并对其进行__getitem__。 也就是说,我们无法在此处缓存Planes集合。
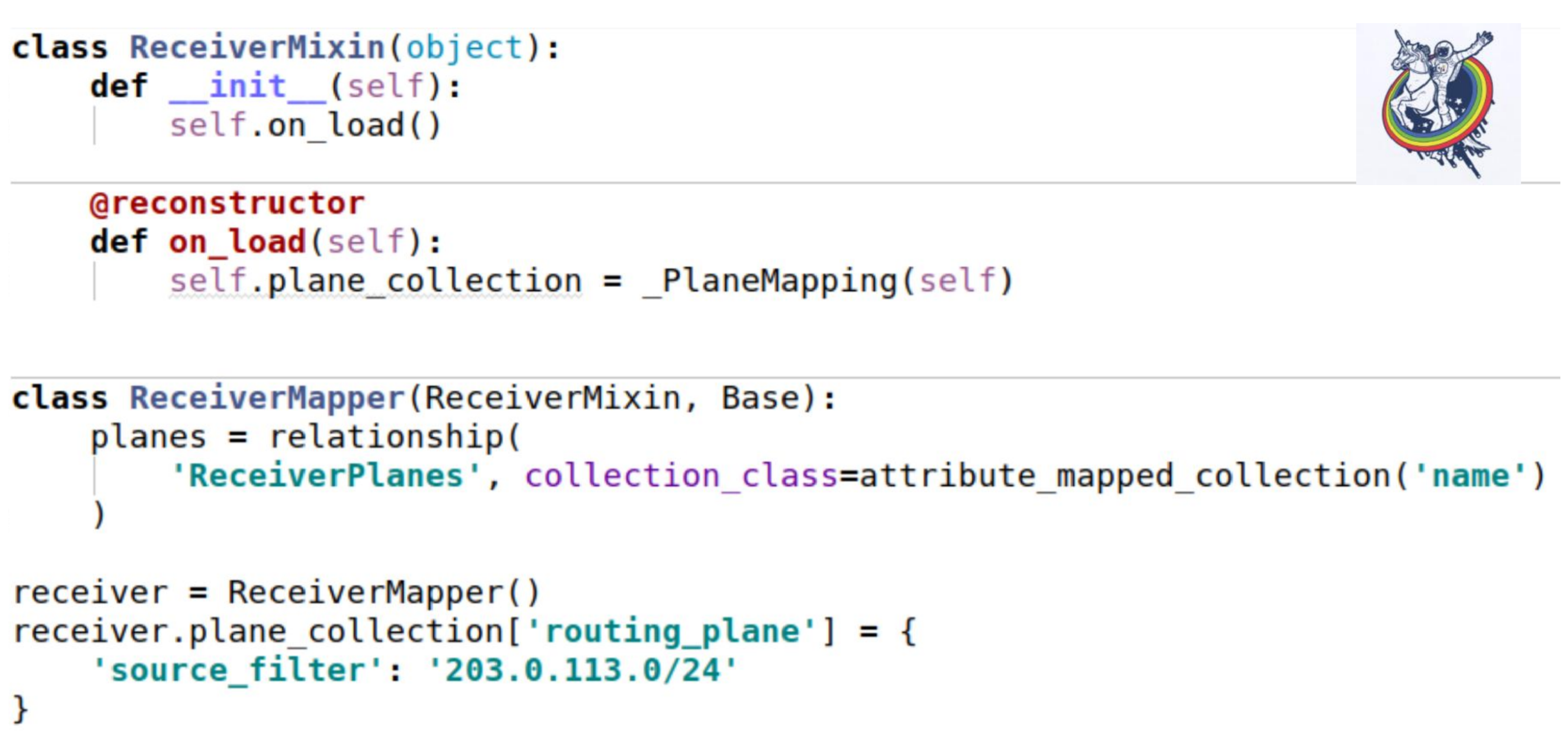
这个集合如何影响我们的mixins? 与往常一样-设置收集属性。 唯一有趣的地方是,当我们从数据库加载实例时,不会调用__init__方法。 所有属性均在事后替换。
Alchemy提供了一个标准的重构器装饰器,它允许您将某些方法标记为从数据库中加载对象后被调用。 而且在启动时,我们必须初始化我们的集合。 自我就是那个例子。 用法与前面的示例完全相同。
但是在我们的方案中,数据库的耳朵仍然可见-这就是配置。 什么类型的配置? 是varchar还是blob? 实际上,客户不感兴趣。
他必须使用该级别的抽象实体。为此,炼金术提供了装饰。 一个简单的例子。我们的数据库将IPAddress存储为varchar。我们使用TypeDecorator类(这是炼金术的一部分),该类首先允许指示哪种底层数据库类型将用于此类型,其次可以定义两个参数:process_bind_param将值转换为数据库类型,并在进行赋值时将process_result_value从数据库类型转换为Python对象。来自address的属性采用python类型IPAddress。而且我们都可以调用这种类型的方法,并为其分配这种类型的对象,一切对我们都有效。它存储在数据库中...我不知道存储什么,varchar(45),但是我们可以替换该行,并且将存储blob。或者,如果某些本机类型支持IP地址,则可以使用它。客户端代码不依赖于此,不需要重写。
一个简单的例子。我们的数据库将IPAddress存储为varchar。我们使用TypeDecorator类(这是炼金术的一部分),该类首先允许指示哪种底层数据库类型将用于此类型,其次可以定义两个参数:process_bind_param将值转换为数据库类型,并在进行赋值时将process_result_value从数据库类型转换为Python对象。来自address的属性采用python类型IPAddress。而且我们都可以调用这种类型的方法,并为其分配这种类型的对象,一切对我们都有效。它存储在数据库中...我不知道存储什么,varchar(45),但是我们可以替换该行,并且将存储blob。或者,如果某些本机类型支持IP地址,则可以使用它。客户端代码不依赖于此,不需要重写。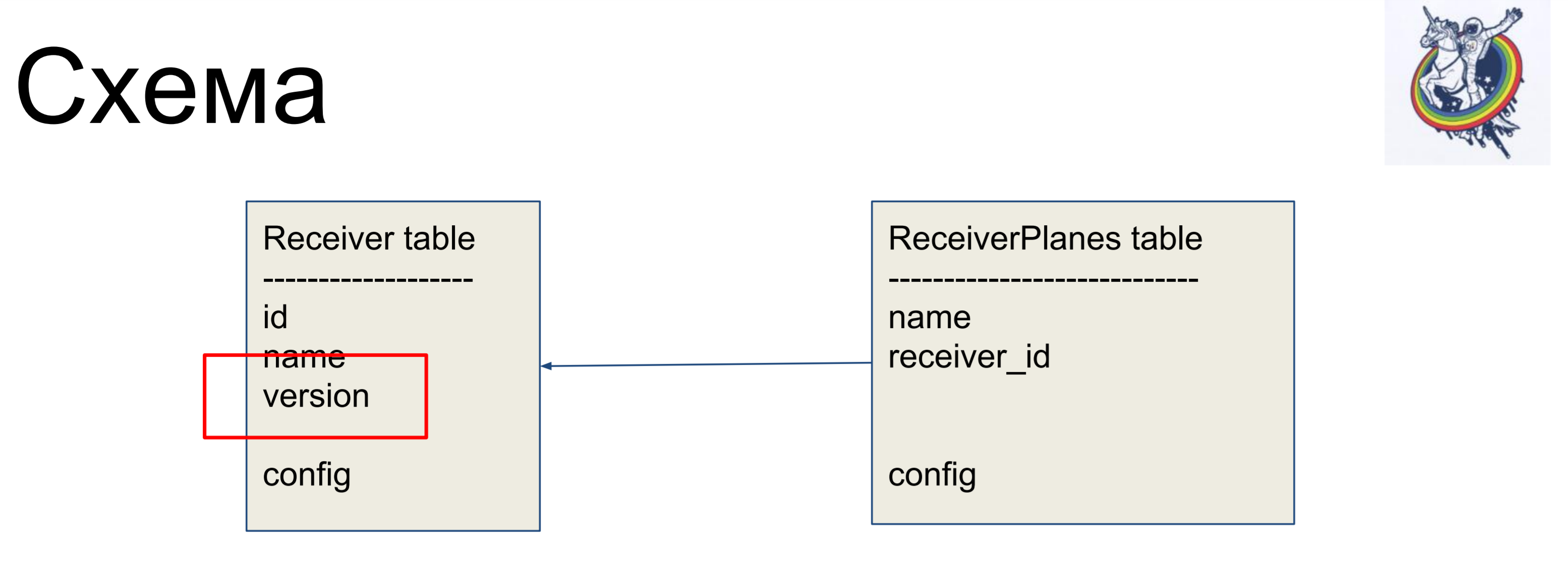 另一个有趣的事情是我们有一个版本。我们希望更改对象后立即增加版本。我们有一些版本计数器,我们更改了对象-它已更改,版本已增加。我们会自动执行此操作,以免忘记。
另一个有趣的事情是我们有一个版本。我们希望更改对象后立即增加版本。我们有一些版本计数器,我们更改了对象-它已更改,版本已增加。我们会自动执行此操作,以免忘记。 为此,我们使用了事件。事件是在映射器生命的不同阶段发生的事件,可以在属性更改时,实体从一种状态更改为另一种状态时触发,例如``创建'',``保存到数据库'',``从数据库加载'',``已删除'';并且-在会话级事件中,在将sql代码发送到数据库之前,提交之前,提交之后以及回滚之后。Alchemy允许我们为所有这些事件分配处理程序,但是不能保证针对同一事件执行处理程序的顺序。也就是说,它是特定的,但不知道是哪一个。因此,如果执行顺序对您很重要,则需要执行注册机制。
为此,我们使用了事件。事件是在映射器生命的不同阶段发生的事件,可以在属性更改时,实体从一种状态更改为另一种状态时触发,例如``创建'',``保存到数据库'',``从数据库加载'',``已删除'';并且-在会话级事件中,在将sql代码发送到数据库之前,提交之前,提交之后以及回滚之后。Alchemy允许我们为所有这些事件分配处理程序,但是不能保证针对同一事件执行处理程序的顺序。也就是说,它是特定的,但不知道是哪一个。因此,如果执行顺序对您很重要,则需要执行注册机制。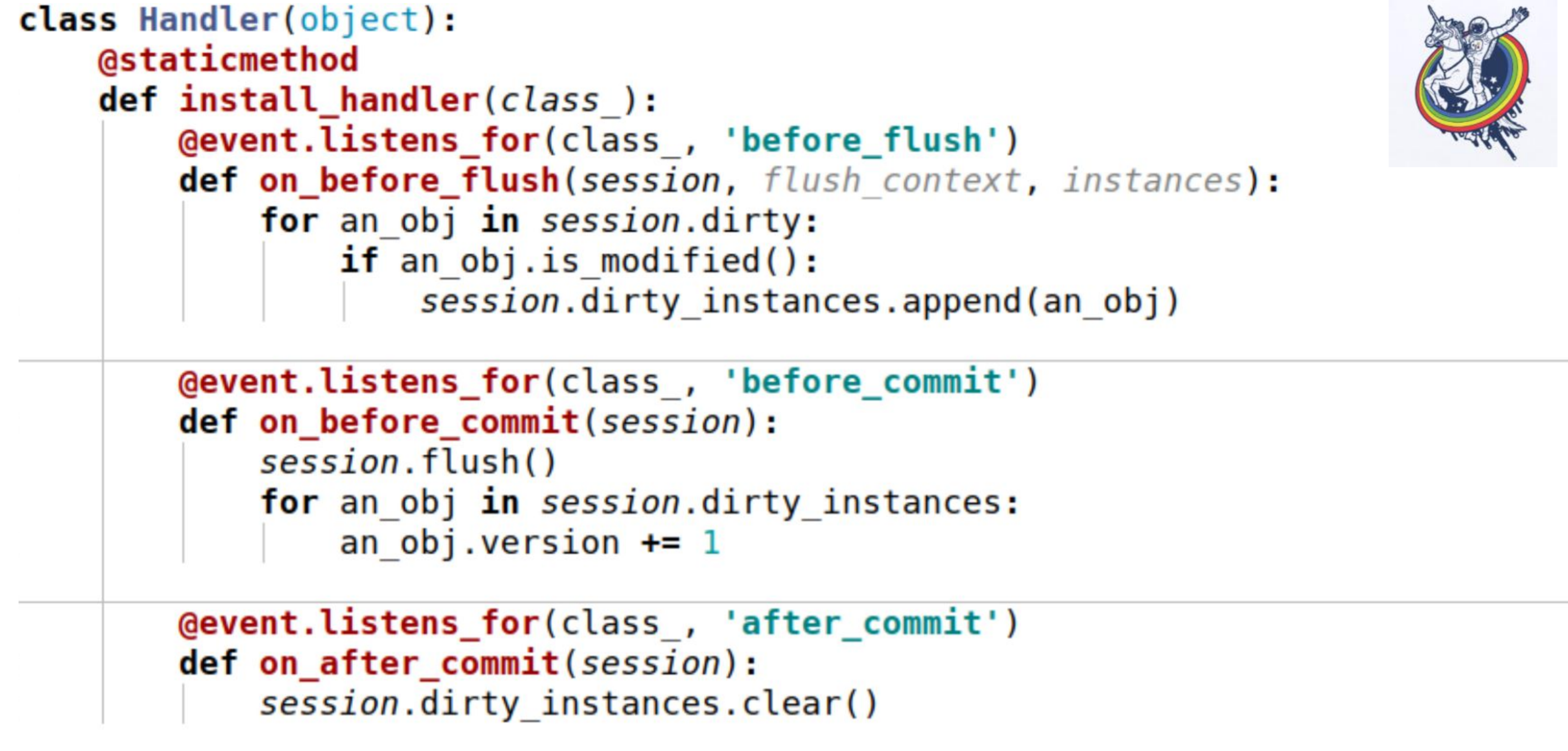 这是一个例子。这里使用三个事件:on_before_flush-在将sql代码发送到数据库之前,我们遍历此会话中所有被炼金术标记为脏的对象,并检查是否修改了该对象。如果炼金术已经标记了一切,为什么这是必要的?某些属性更改后,炼金术会将对象标记为脏。如果我们给该属性分配相同的值,它将被标记为脏。为此有一个is_modified会话方法-它在内部使用,我没有绘制它。此外,从语义的角度来看,从业务逻辑的角度来看,即使属性已更改,对象仍然可以保持不变。例如,有一个特定的列表,其中两个元素是互换的-从炼金术的角度来看,该属性已更改,但是对于业务逻辑而言,例如某种。最后,我们调用特定于每个对象的另一个方法,以了解对象是否被修改。然后将它们添加到与我们自己发起的会话相关联的某个变量中-这是我们的dirty_instances变量,在其中添加了该对象。在提交之前发生以下事件-before_commit。这里也有一个小陷阱:如果对于整个事务我们都没有一个刷新,那么将在提交之前调用刷新-在我的情况下,在刷新之前在提交之前调用处理程序。如您所见,我们在上一段中所做的可能无济于事,session.dirty_instances将为空。因此,在处理程序内部,我们再次进行刷新,以便在刷新之前调用所有处理程序,并简单地将版本增加1。after_commit,after_soft_rollback-提交后,我们只清理它,以确保下次没有多余的开销。因此,您会看到-此install_handler方法可同时安装三个事件的处理程序。作为课程,我们在这里通过会话,因为这是其级别的事件。
这是一个例子。这里使用三个事件:on_before_flush-在将sql代码发送到数据库之前,我们遍历此会话中所有被炼金术标记为脏的对象,并检查是否修改了该对象。如果炼金术已经标记了一切,为什么这是必要的?某些属性更改后,炼金术会将对象标记为脏。如果我们给该属性分配相同的值,它将被标记为脏。为此有一个is_modified会话方法-它在内部使用,我没有绘制它。此外,从语义的角度来看,从业务逻辑的角度来看,即使属性已更改,对象仍然可以保持不变。例如,有一个特定的列表,其中两个元素是互换的-从炼金术的角度来看,该属性已更改,但是对于业务逻辑而言,例如某种。最后,我们调用特定于每个对象的另一个方法,以了解对象是否被修改。然后将它们添加到与我们自己发起的会话相关联的某个变量中-这是我们的dirty_instances变量,在其中添加了该对象。在提交之前发生以下事件-before_commit。这里也有一个小陷阱:如果对于整个事务我们都没有一个刷新,那么将在提交之前调用刷新-在我的情况下,在刷新之前在提交之前调用处理程序。如您所见,我们在上一段中所做的可能无济于事,session.dirty_instances将为空。因此,在处理程序内部,我们再次进行刷新,以便在刷新之前调用所有处理程序,并简单地将版本增加1。after_commit,after_soft_rollback-提交后,我们只清理它,以确保下次没有多余的开销。因此,您会看到-此install_handler方法可同时安装三个事件的处理程序。作为课程,我们在这里通过会话,因为这是其级别的事件。 好吧我会提醒您我们所取得的成就-复杂团队和大型团队的速度为30-40秒。正如您在RPS上所看到的那样,根本没有完成,有些是在一秒钟内完成的,其他是200毫秒内完成的。数据库查询开始统计数百个。
好吧我会提醒您我们所取得的成就-复杂团队和大型团队的速度为30-40秒。正如您在RPS上所看到的那样,根本没有完成,有些是在一秒钟内完成的,其他是200毫秒内完成的。数据库查询开始统计数百个。 结果是一个相当平衡的系统。但是,有一个警告。我们有些要求是分批排放的。也就是说,大约有30个请求到达,每个请求都是这样! (发言人显示拇指)如果我们一次处理它们一秒钟,那么队列中的最后一个请求将持续30秒。第一个,第二个,依此类推。
结果是一个相当平衡的系统。但是,有一个警告。我们有些要求是分批排放的。也就是说,大约有30个请求到达,每个请求都是这样! (发言人显示拇指)如果我们一次处理它们一秒钟,那么队列中的最后一个请求将持续30秒。第一个,第二个,依此类推。 因此,我们仍然需要加速。我们该怎么办?实际上,炼金术有两个部分。首先是对名为SQLAlchemy Core的sql数据库的抽象。第二个是ORM,即关系数据库和对象表示之间的实际映射。因此,炼金术核心与sql大约是一对一的-如果您知道sql,那么您就不会遇到核心问题。如果您不知道sql,请学习sql。另外,核心代表最小的开销。实际上没有抽水-使用查询生成器生成查询,然后执行查询。 dbapi的开销很小。我们可以构建任何类型的任何复杂性的请求,我们可以针对任务优化它们。也就是说,如果在通常情况下,ORM不在乎数据库架构的构建方式-有一些表描述,则会生成一些查询,而又不知道在这种情况下,例如,最好从此处进行选择-从那里进行选择应用过滤器,然后-在这里,我们可以对任务进行请求。缺点是我们又开始进行手动同步。所有事件,中继-核心中的所有这些都不起作用。我们进行了选择,对象来了,我们对它们做了一些操作,然后更新,插入...您需要用手增加版本,自己检查常量。 Core不允许在高级别上方便地完成所有这些操作。好吧,我们不住第一天。
因此,我们仍然需要加速。我们该怎么办?实际上,炼金术有两个部分。首先是对名为SQLAlchemy Core的sql数据库的抽象。第二个是ORM,即关系数据库和对象表示之间的实际映射。因此,炼金术核心与sql大约是一对一的-如果您知道sql,那么您就不会遇到核心问题。如果您不知道sql,请学习sql。另外,核心代表最小的开销。实际上没有抽水-使用查询生成器生成查询,然后执行查询。 dbapi的开销很小。我们可以构建任何类型的任何复杂性的请求,我们可以针对任务优化它们。也就是说,如果在通常情况下,ORM不在乎数据库架构的构建方式-有一些表描述,则会生成一些查询,而又不知道在这种情况下,例如,最好从此处进行选择-从那里进行选择应用过滤器,然后-在这里,我们可以对任务进行请求。缺点是我们又开始进行手动同步。所有事件,中继-核心中的所有这些都不起作用。我们进行了选择,对象来了,我们对它们做了一些操作,然后更新,插入...您需要用手增加版本,自己检查常量。 Core不允许在高级别上方便地完成所有这些操作。好吧,我们不住第一天。 一个简单的用例。每个映射器内部都包含一个__table__对象,该对象在核心中使用。接下来,您会看到-我们进行常规选择,列出各列,将两个板块连接起来,分别指示左右,并根据连接的条件说明我们添加了购买订单的口味。此外,我们将此生成的请求馈送到会话中,并返回给我们可迭代的请求,在该过程中,同时通过列名和数字对类似Tap的对象进行索引。该数字对应于它们在选择中列出的顺序。
一个简单的用例。每个映射器内部都包含一个__table__对象,该对象在核心中使用。接下来,您会看到-我们进行常规选择,列出各列,将两个板块连接起来,分别指示左右,并根据连接的条件说明我们添加了购买订单的口味。此外,我们将此生成的请求馈送到会话中,并返回给我们可迭代的请求,在该过程中,同时通过列名和数字对类似Tap的对象进行索引。该数字对应于它们在选择中列出的顺序。 它变得更好了。最坏情况下的性能下降到2-4秒,最复杂,最长的请求包含14条命令和RPS 10-15。牢固。
它变得更好了。最坏情况下的性能下降到2-4秒,最复杂,最长的请求包含14条命令和RPS 10-15。牢固。 最后我想说的是。不要在不需要的地方生产实体-不要在准备好的地方拧实体。使用SQLA ORM-这是一个非常方便的工具,可让您从高级别跟踪事件,响应与数据库相关的各种事件,隐藏所有炼金术的耳朵。如果所有其他方法均失败,则性能不足-请使用SQLA Core。这仍然比使用纯原始SQL更好,因为它提供了数据库上的关系抽象。自动转义参数,是否正确绑定程序,无论数据库位于哪个数据库下都可以更改,并且Core支持不同的方言。
最后我想说的是。不要在不需要的地方生产实体-不要在准备好的地方拧实体。使用SQLA ORM-这是一个非常方便的工具,可让您从高级别跟踪事件,响应与数据库相关的各种事件,隐藏所有炼金术的耳朵。如果所有其他方法均失败,则性能不足-请使用SQLA Core。这仍然比使用纯原始SQL更好,因为它提供了数据库上的关系抽象。自动转义参数,是否正确绑定程序,无论数据库位于哪个数据库下都可以更改,并且Core支持不同的方言。非常方便。
我今天只想告诉你。