[第2部分,共2部分]
[第1部分,共2部分]

我们是怎么做到的
我们决定改用GCP来提高应用程序性能-在扩大规模的同时,却不会产生大笔成本。 整个过程耗时超过2个月。 为了解决这个问题,我们组成了一个特殊的工程师小组。
在本出版物中,我们将讨论所选的方法及其实施以及我们如何实现主要目标-尽可能平稳地执行此过程并将整个基础架构转移到Google Cloud Platform,而不会影响用户服务的质量。
规划中
- 准备了详细的清单,以标识每个可能的步骤。 已创建流程图来描述顺序。
- 已经制定了重置计划,我们可以使用该重置计划。
进行了几次集思广益的会议-我们已经确定了实施主动-主动方案的最容易理解和最简单的方法。 它包含以下事实:一小群用户托管在一个云上,其余用户托管在另一个云上。 但是,这种方法引起了问题,尤其是在客户端(与DNS管理有关),并且导致了数据库复制的延迟。 因此,几乎不可能安全地实施它。 显而易见的方法没有提供必要的解决方案,因此我们必须制定专门的策略。
根据依赖关系图和操作安全要求,我们将基础结构服务分为9个模块。
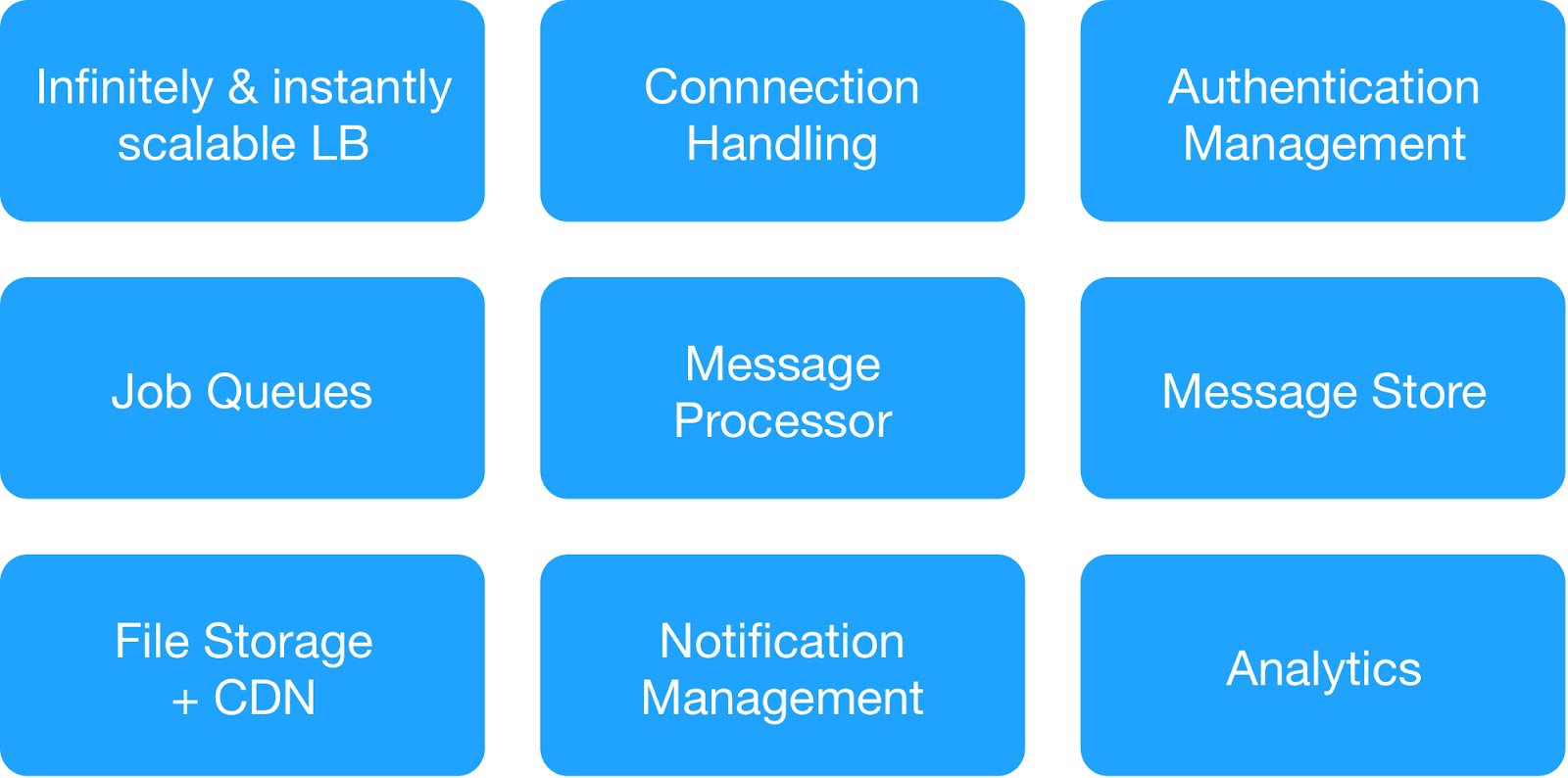
(用于部署托管基础结构的基本模块)
每个基础架构组管理共同的内部和外部服务。
⊹ 基础架构消息服务 :MQTT,HTTP,Thrift,Gunicorn服务器,排队模块,异步客户端,Jetty服务器,Kafka集群。
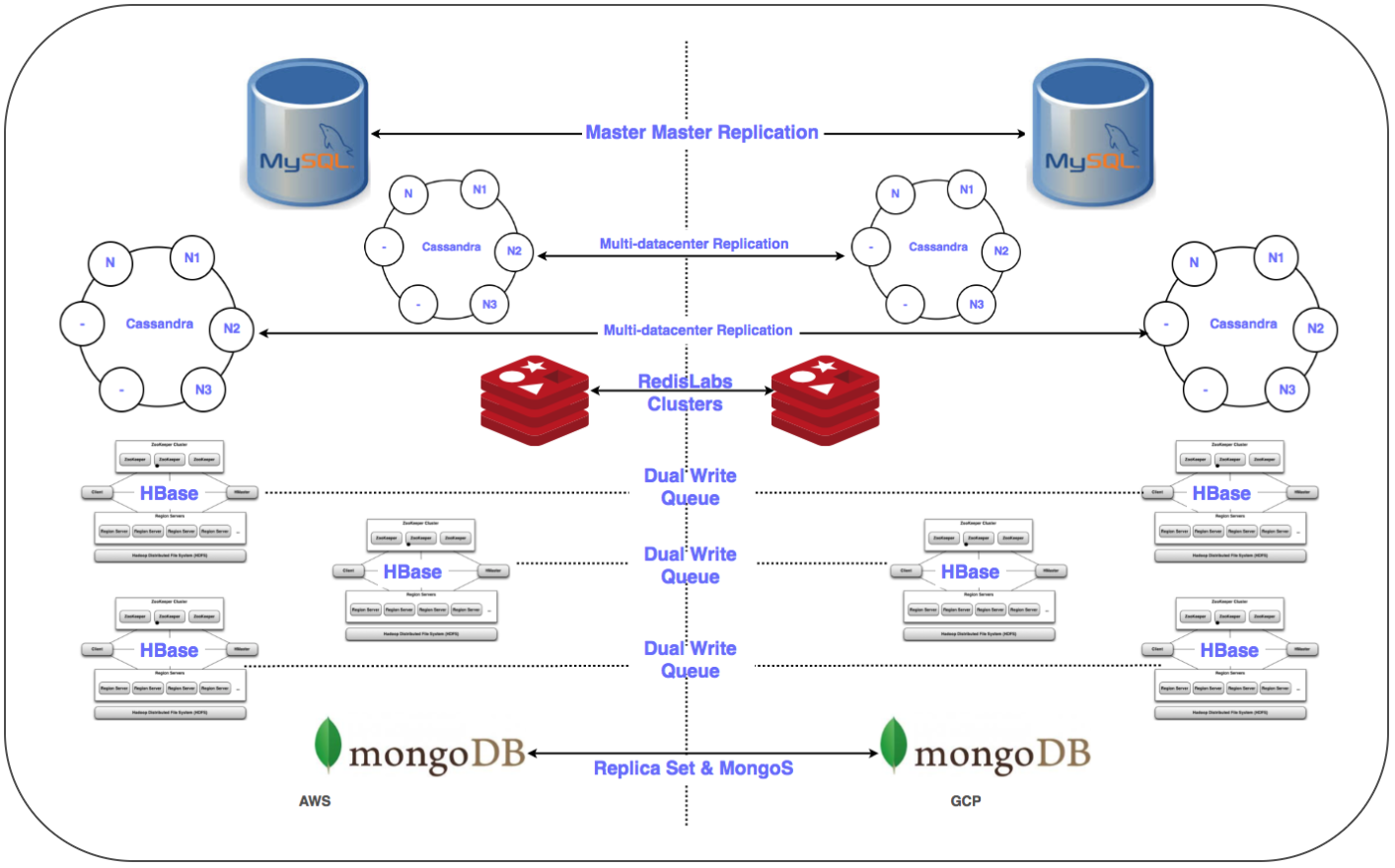
⊹ 数据仓库服务 :分布式集群MongoDB,Redis,Cassandra,Hbase,MySQL和MongoDB。
⊹ 基础架构分析服务 :Kafka集群,数据仓库集群(HDFS,HIVE)。
为重要的一天做准备:
✓每个服务切换到GCP的详细计划:顺序,数据仓库,重置计划。
✓GCP中的跨项目网络交互(共享的虚拟私有云VPC [XPN])可隔离基础架构的不同部分,优化管理,提高安全性和连接性。
✓GCP与正在运行的虚拟私有云(VPC)之间的多个VPN隧道可简化复制过程中网络上大量数据的传输,以及随后可能部署的并行系统。
✓使用Chef系统自动安装和配置整个堆栈。
✓用于部署,监视,记录等的脚本和自动化工具。
✓为系统流配置所有必需的子网和托管防火墙规则。
✓在所有存储系统的多个数据中心(Multi-DC)中进行复制。
✓配置负载平衡器(GLB / ILB)和托管实例组(MIG)。
✓使用检查点将对象存储容器传输到GCP Cloud Storage的脚本和代码。
很快,我们满足了所有必要的先决条件,并准备了将基础架构移至GCP平台的元素清单。 经过大量讨论,并考虑了服务的数量及其依赖关系图,我们决定在三晚之内将云基础架构转移到GCP,以涵盖所有服务器端和数据存储服务。
过渡期
负载均衡器转移策略:
我们用全局负载平衡器替换了以前使用的HAProxy管理的群集,以每天处理数千万的活动用户连接。
⊹ 阶段1:
- 使用数据包转发规则创建MIG,以将所有流量转发到现有云中的MQTT IP地址。
- 已使用MIG作为服务器部分创建了SSL和TCP代理平衡器。
- 对于MIG,将以MQTT服务器作为服务器部分启动HAProxy。
- 在DNS中,基于权重的路由策略已添加了外部GLB IP地址。
用户连接在跟踪其性能的同时逐步部署。
⊹ 步骤2:里程碑过渡,开始在GCP中部署服务。
⊹ 阶段3:过渡的最后阶段,所有服务都转移到GCP。
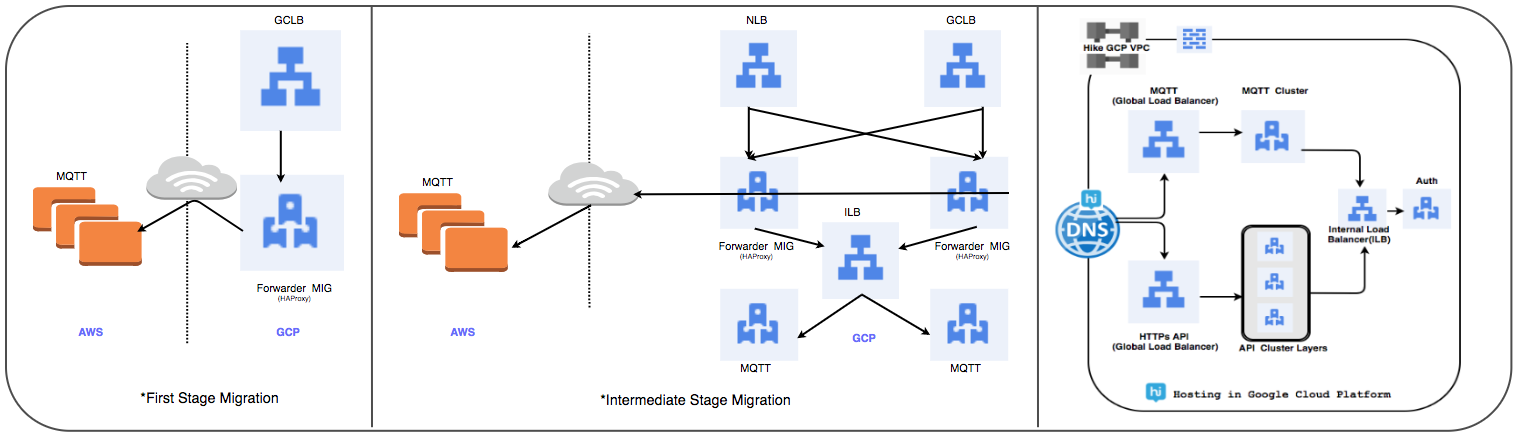
(负载均衡器的转移阶段)
在这个阶段,一切都按预期进行。 很快,考虑到系数的权重,是时候在带有路由的GCP中部署几个内部HTTP服务了。 我们密切监控所有指标。 当我们开始逐渐增加流量时,即计划进行过渡的前一天,通过VPN进行VPC交互的延迟(记录了40毫秒-100毫秒的延迟,尽管之前的延迟小于10毫秒)有所增加。
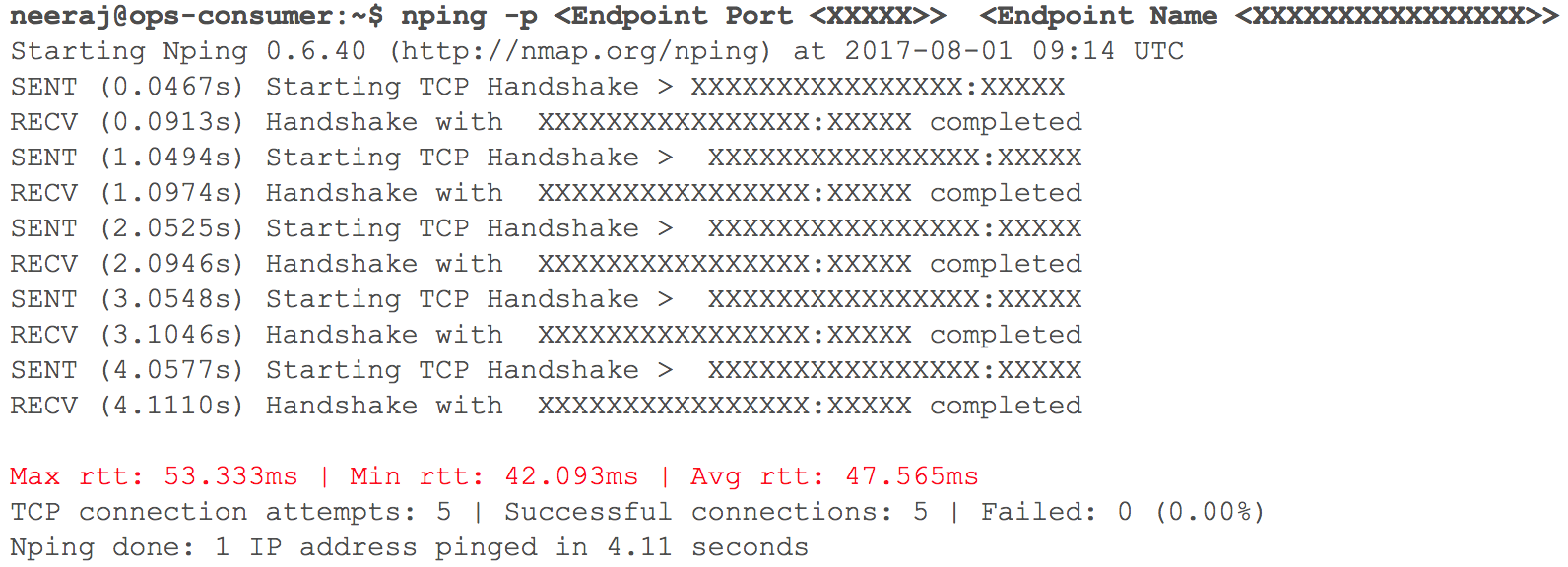
(两个VPC交互时检查网络延迟的快照)
监控清楚地表明:使用VPN隧道的两个云网络通道都出了问题。 甚至VPN隧道的吞吐量也没有达到最佳标记。 这种情况已开始对我们的某些用户服务产生负面影响。 我们立即将所有先前迁移的HTTP服务恢复为原始状态。 我们联系了TAM和云服务支持团队,提供了必要的初始数据,并开始理解为什么延迟越来越大。 支持专家得出的结论是,在两个云服务提供商之间的云通道中实现了最大的网络带宽。 因此,内部系统传输期间网络延迟的增长。
此事件迫使中止向云的过渡。 云服务提供商无法足够快地将带宽加倍。 因此,我们回到了计划阶段并修改了策略。 我们决定将云基础架构从一晚而不是三晚转移到GCP,并且计划中包括服务器部分和数据存储的所有服务。 当“ X”小时到来时,一切顺利进行:工作负载成功转移到Google Cloud,我们的用户没有注意到!
数据库迁移策略:
必须为关系型DBMS,内存中的存储以及NoSQL以及低延迟的分布式和可伸缩群集转移50多个数据库端点。 我们已将所有数据库的副本放置在GCP中。 除HBase之外,所有其他部署均已完成此操作。
⊹ 主从复制:针对MySQL,Redis,MongoDB和MongoS集群实现。
多多DC复制:为Cassandra群集实现。
⊹ 双群集:已在GCP中为Gbase配置了并行群集。 迁移了现有数据,并根据维护两个群集中数据一致性的策略配置了两次输入。
对于HBase,问题出在Ambari。 在将群集放置在多个数据中心中时,我们遇到了一些困难,例如,DNS,机架识别脚本等存在问题。
最后的步骤(在移动服务器之后)包括将副本移动到主服务器并关闭旧数据库。 按照计划,确定数据库传输的优先级,我们将Zookeeper用于应用程序集群的必要配置。
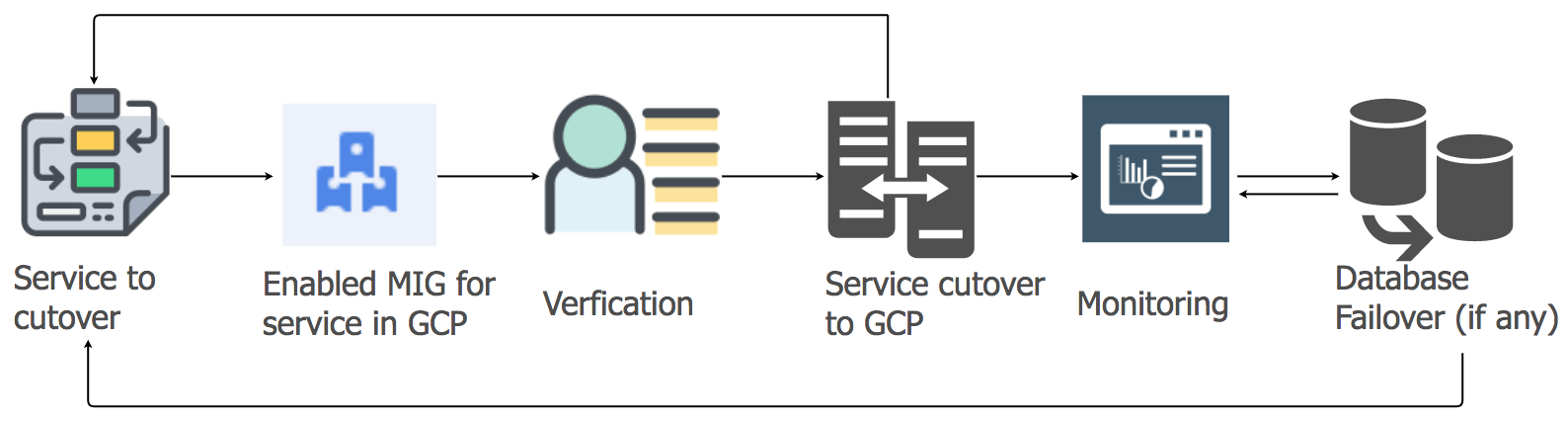
应用服务迁移策略
为了将应用程序服务的工作负载从当前托管转移到GCP云,我们使用了“提升并转移”的方法。 对于每个应用程序服务,我们创建了一组具有自动扩展功能的托管实例(MIG)。
根据详细计划,我们开始考虑到数据仓库的顺序和依赖性,将服务迁移到GCP。 所有消息传递堆栈服务均已迁移到GCP,而没有任何停机时间。 是的,有一些小故障,但我们立即对其进行了处理。
早晨,随着用户活动的增加,我们认真遵循了所有仪表板和指示器以快速发现问题。 确实出现了一些困难,但是我们能够迅速消除它们。 问题之一是由于内部负载均衡器(ILB)的限制,该负载均衡器最多可以处理20,000个并发连接。 我们还需要8倍! 因此,我们在连接管理层中添加了其他ILB。
在过渡之后的高峰负载的最初几个小时,我们特别仔细地控制了所有参数,因为消息传递堆栈的整个负载已转移到GCP。 我们很快处理了一些小故障。 在迁移其他服务时,我们采用了相同的方法。
对象存储迁移:
我们主要通过三种方式使用对象存储服务。
⊹存储发送到个人或群聊的媒体文件。 保留期限由生命周期管理策略确定。
⊹存储用户配置文件的图像和缩略图。
⊹存储“历史记录”和“时间轴”部分中的媒体文件以及相应的缩略图。
我们使用Google的存储传输工具将旧对象从S3复制到GCS。 当需要特殊逻辑时,我们还使用了基于Kafka的自定义MIG将对象从S3传输到GCS。
从S3到GCS的过渡包括以下步骤:
●对于对象存储库的第一个用例,我们开始将新数据写入S3和GCS,到期后,我们开始使用应用程序侧的逻辑从GCS读取数据。 传输旧数据没有意义,并且这种方法具有成本效益。
●对于第二和第三个用例,我们开始将新对象写入GCS,并更改了读取数据的路径,以便首先在GCS中执行搜索,然后在找不到对象的情况下才在S3中进行搜索。
计划,验证概念的正确性,准备和制作原型花了几个月的时间 ,但后来我们决定过渡,并很快实施了它。 我们评估了风险,并意识到快速迁移是可取的,而且几乎不可察觉。
这个大型项目帮助我们在许多领域获得了强大的地位,并提高了团队的生产力,因为管理云基础架构的大多数手动操作现在都已过去。
●对于用户,现在我们已收到确保其最高质量服务所必需的一切。 停机时间几乎消失了,新功能的实施速度更快。
●我们的团队在维护任务上花费的时间更少,可以专注于自动化项目和创建新工具。
●我们获得了前所未有的用于处理大数据的工具集,以及用于机器学习和分析的现成功能。 在这里查看详细信息。
●Google Cloud与Kubernetes开源项目合作的承诺也符合我们今年的发展计划。