在先前的一篇文章中,我谈到了如何使用面向功能和面向语言的编程方法为虚拟堆栈机构建程序执行程序。 该语言的数学结构基于半群和类半体的概念,为实现其翻译器提供了基本结构。 这种方法使我能够构建漂亮且可扩展的实现并打破掌声,但是观众提出的第一个问题使我离开了讲台,再次进入Emacs。
我进行了一个简单的测试,并确保在仅使用堆栈的简单任务上,虚拟机可以正常运行,并且在使用“内存”(具有随机访问权限的阵列)时会出现大问题。 关于我们如何在不改变程序体系结构基本原理的情况下设法解决它们,并实现程序的千倍加速,将在本文中进行讨论。
Haskell是一种特殊的语言,具有特殊的利基。 它的创建和开发的主要目标是使用通用语言来表达和测试函数式编程的思想。 这证明了其最引人注目的功能:懒惰,极度纯正,强调类型和对其进行操作。 它不是为日常开发而设计的,不是为工业编程设计的,也不是为广泛使用的。 如果您愿意的话,它确实可以用于在网络行业和数据处理中创建大型项目,这是开发人员的良好意愿,也是概念验证。 但是到目前为止,用Haskell编写的最重要,使用最广泛且功能惊人的产品是ghc编译器。 从其目的的角度来看,这是完全合理的-成为计算机科学领域的研究工具。 西蒙·佩顿-约翰逊(Simon Payton-Johnson)宣布的原则:“不惜一切代价避免成功”对于使该语言保持如此重要是必要的。 Haskell就像是开发半导体技术或纳米材料的研究中心实验室中的无菌室。 工作非常不便,并且在日常实践中也限制了行动自由,但是如果没有这些不便,并且不妥协地遵守各种限制,将无法观察和研究后来将成为工业发展基础的微妙影响。 同时,在行业中,仅在最必要的量中才需要无菌,这些实验的结果将以小工具的形式出现在我们的口袋里。 我们研究恒星和星系不是因为我们希望从中获得直接的收益,而是因为在这些不切实际的物体的规模上,量子和相对论效应变得可以观察和研究了,以至于后来我们可以利用这些知识来发展非常实用的东西。 因此,Haskell的“错误”行,不切实际的计算惰性,某些类型推断算法的刚性以及非常陡峭的输入曲线,最终使您无法轻松地在膝盖或操作系统上创建智能应用程序。 但是,镜头,单子函数,组合解析,monoid的广泛使用,自动定理证明的方法,声明性功能包管理器,线性和从属类型正在接近实际世界。 这在Python,Scala,Kotlin,F#,Rust等语言的不那么恶劣的条件下找到了应用。 但是我不会使用任何这些奇妙的语言来教授函数式编程的原理:我将带学生到实验室,以生动干净的示例演示它的工作原理,然后您可以在工厂中看到这些原理的实际应用大型且难以理解但非常快的机器。 不惜一切代价避免成功是为了防止将咖啡机放入电子显微镜以使其普及。 在语言较酷的比赛中,Haskell总是会超出常规提名。
但是,这个人很虚弱,恶魔也生活在我体内,这使我想在他人面前比较,评估和捍卫“我最喜欢的语言”。 因此,在编写完一个基于单调式组合的机器的优雅实现之后,唯一的目的就是看这个想法是否对我有用,让我感到很沮丧的是,我意识到实现效果很好,但是效率很低! 好像我真的要使用它来完成艰巨的任务,或者在可提供Python或Java虚拟机的市场上出售我的堆叠式计算机一样。 但是,该死的,关于整个过程开始的关于小猪的文章给出了如此可口的数字:小猪数百毫秒,Python几秒钟……而我美丽的类人猿在一小时内无法完成同一任务! 我必须成功! 我的显微镜能煮出的浓缩咖啡,不比学院走廊里的咖啡机差! 水晶宫可以分散并发射到太空中!
但是,数学家天使问我,你准备放弃什么了? 宫殿建筑的纯度和透明度? 从程序到其他解决方案的同态性提供的灵活性和可扩展性? 恶魔和天使都固执,我也允许自己生活的明智的道士提议走一条适合两者的道路,并尽可能长地走下去。 但是,其目的不是为了识别获胜者,而是为了了解路径本身,找出其前进的方向并获得新的经验。 因此,我知道优化的徒劳的悲伤和喜悦。
在开始之前,我们补充说,在有效性方面进行语言比较是没有意义的。 您需要比较翻译器(解释器或编译器)或使用该语言的程序员的性能。 最后,例如通过用BASIC编写完整的C解释器,可以很容易地驳斥C程序最快的主张。 因此,我们不是在比较Haskell和javascript,而是在比较由ghc编译的翻译器执行的程序和在特定浏览器中执行的程序的性能。 所有猪的术语都来自有关堆叠式机器的鼓舞人心的文章 。 随书附带的所有Haskell代码都可以在存储库中研究。
我们离开舒适区
起始位置将是以EDSL形式实现单面堆栈计算机-一种简单的小语言,它允许组合两个打扰基元来渲染虚拟堆栈计算机的程序。 他进入第二篇文章后,便给他起了monopig的名字。 这是基于这样的事实:用于堆叠机器的语言以连接操作和空操作为单位形成了一个单面体。 相应地,他本人以机器状态的类id变换的形式构建。 状态包括堆栈,向量形式的存储器(提供对元素的随机访问的结构),紧急停止标志和用于累积调试信息的单面电池。 整个结构沿着内构链从一个操作传递到另一个操作,从而执行计算过程。 程序代码的同构结构是从程序形成的结构中构造出来的,并且从其同构性变成其他有用的结构,这些结构代表了根据参数和内存数量对程序的要求。 构造的最后阶段是在Claysley类别中创建变换monoid,您可以将计算沉浸在任意monad中。 因此,机器具有输入输出和模糊计算的功能。 我们将从此实施开始。 她的代码可以在这里找到。
我们将在天真的实现Eratosthenes筛子时测试该程序的有效性,该方法将内存(数组)填充为零和一,以质数表示为零。 我们在javascript给出算法的过程代码:
var memSize = 65536; var arr = []; for (var i = 0; i < memSize; i++) arr.push(0); function sieve() { var n = 2; while (n*n < memSize) { if (!arr[n]) { var k = n; while (k < memSize) { k+=n; arr[k] = 1; } } n++; } }
该算法立即进行了稍微优化。 它消除了在已装满的存储单元中走错的情况。 我的数学家天使不同意PorosenokVM项目中一个示例的真正幼稚版本,因为此优化仅花费了五个堆栈语言指令。 这是算法转换为monopig :
sieve = push 2 <> while (dup <> dup <> mul <> push memSize <> lt) (dup <> get <> branch mempty fill <> inc) <> pop fill = dup <> dup <> add <> while (dup <> push memSize <> lt) (dup <> push 1 <> swap <> put <> exch <> add) <> pop
这是您可以使用与monopig相同的类型在惯用的Haskell上编写此算法的等效实现的monopig :
sieve' :: Int -> Vector Int -> Vector Int sieve' km | k*k < memSize = sieve' (k+1) $ if m ! k == 0 then fill' k (2*k) m else m | otherwise = m fill' :: Int -> Int -> Vector Int -> Vector Int fill' knm | n < memSize = fill' k (n+k) $ m // [(n,1)] | otherwise = m
它使用Data.Vector类型和工具来处理它,这对于Haskell的日常工作来说并不常见。 表情m ! k m ! k返回向量m第k个元素,并且m // [(n,1)] -将数字n为1。我在这里写这个是因为即使我在Haskell工作,我也得去找他们寻求帮助。几乎每天 事实是,在功能实现中具有随机访问权限的结构效率低下,因此不受欢迎。
根据有关仔猪的文章中指定的竞争条件,该算法运行100次。 并且为了摆脱特定的计算机,让我们比较这三个程序的执行速度,将它们与在Chrome中运行的javascript程序的性能进行比较。
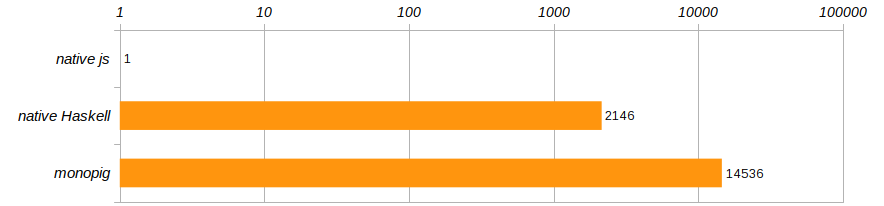
恐怖恐怖! monopig不仅monopig降低了速度,因此本机版本也没有更好的表现! Haskell当然很酷,但是不比在浏览器中运行的程序逊色吗? 正如教练教导我们的那样,您不能那样生活,是时候离开Haskell为我们提供的舒适区了!
克服懒惰
让我们做对。 为此,请使用-rtsopts标志在monopig上编译程序,以-rtsopts运行时统计信息,并查看一次运行Eratosthenes筛子所需的内容:
$ ghc -O -rtsopts ./Monopig4.hs [1 of 1] Compiling Main ( Monopig4.hs, Monopig4.o ) Linking Monopig4 ... $ ./Monopig4 -RTS -sstderr "Ok" 68,243,040,608 bytes allocated in the heap 6,471,530,040 bytes copied during GC 2,950,952 bytes maximum residency (30667 sample(s)) 42,264 bytes maximum slop 15 MB total memory in use (7 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 99408 colls, 0 par 2.758s 2.718s 0.0000s 0.0015s Gen 1 30667 colls, 0 par 57.654s 57.777s 0.0019s 0.0133s INIT time 0.000s ( 0.000s elapsed) MUT time 29.008s ( 29.111s elapsed) GC time 60.411s ( 60.495s elapsed) <-- ! EXIT time 0.000s ( 0.000s elapsed) Total time 89.423s ( 89.607s elapsed) %GC time 67.6% (67.5% elapsed) Alloc rate 2,352,591,525 bytes per MUT second Productivity 32.4% of total user, 32.4% of total elapsed
最后一行告诉我们,该程序只有三分之一的时间用于生产计算。 其余时间,垃圾收集器从内存中运行并清理以进行惰性计算。 在童年时代我们被告知有多少次懒惰不好! 在这里,Haskell的主要功能给我们带来了损害,试图创建数十亿个延迟向量和堆栈转换。
此时的数学家天使举起手指,高高兴兴地谈到自阿隆佐教堂时代以来存在一个定理,该定理指出计算策略不会影响其结果,这意味着出于效率考虑,我们可以自由选择它。 完全将计算更改为严格并不困难-签字! 声明堆栈和内存的类型,从而使这些字段严格。
data VM a = VM { stack :: !Stack , status :: Maybe String , memory :: !Memory , journal :: !a }
我们将不会更改任何其他内容,并立即检查结果:
$ ./Monopig41 +RTS -sstderr "Ok" 68,244,819,008 bytes allocated in the heap 7,386,896 bytes copied during GC 528,088 bytes maximum residency (2 sample(s)) 25,248 bytes maximum slop 16 MB total memory in use (14 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 129923 colls, 0 par 0.666s 0.654s 0.0000s 0.0001s Gen 1 2 colls, 0 par 0.001s 0.001s 0.0006s 0.0007s INIT time 0.000s ( 0.000s elapsed) MUT time 13.029s ( 13.048s elapsed) GC time 0.667s ( 0.655s elapsed) EXIT time 0.001s ( 0.001s elapsed) Total time 13.700s ( 13.704s elapsed) %GC time 4.9% (4.8% elapsed) Alloc rate 5,238,049,412 bytes per MUT second Productivity 95.1% of total user, 95.1% of total elapsed
生产力显着提高。 由于数据的不变性,总的内存成本仍然令人印象深刻,但是最重要的是,既然我们已经限制了数据的惰性,垃圾回收器就有机会变得懒惰,仅剩下5%的工作要做。 在评分中输入一个新条目。

好吧,严格的计算使我们更接近本机的Haskell代码的速度,该代码在没有任何虚拟机的情况下可耻地变慢了速度。 这意味着使用不变向量的开销大大超过了维护堆叠机器的成本。 这意味着该该告别存储的不变性了。
让变化进入生活
Data.Vector类型Data.Vector好的,但是使用它,我们以保留计算过程的纯净为名,花费了大量时间进行复制。 用Data.Vector.Unpacked类型代替它Data.Vector.Unpacked我们至少节省了结构的包装,但这并没有从根本上改变图片。 正确的解决方案是从计算机状态中删除内存,并使用Kleisley类别提供对外部向量的访问。 同时,除了纯矢量,还可以使用所谓的可变(可变)矢量Data.Vector.Mutable 。
我们将连接适当的模块,并考虑如何在干净的功能程序中处理可变数据。
import Control.Monad.Primitive import qualified Data.Vector.Unboxed as V import qualified Data.Vector.Unboxed.Mutable as M
这些脏污类型应该与纯公众隔离。 它们包含在PrimMonad类的monad中(这些包含ST或IO ),其中干净的程序会仔细地将用水晶功能语言编写的动作指令插入珍贵的羊皮纸上。 因此,这些不洁动物的行为完全由正统的情况决定,并不危险。 并非我们机器上的所有程序都使用内存,因此无需将整个体系结构都沉浸在IO monad中。 连同monopig语言的干净子集monopig我们将创建四个提供对内存访问的指令,只有它们才能访问危险区域。
清洁机的类型越来越短:
data VM a = VM { stack :: !Stack , status :: Maybe String , journal :: !a }
程序设计者和程序本身几乎不会注意到这种变化,但是它们的类型将会变化。 此外,定义几种同义词来简化签名是有意义的。
type Memory m = M.MVector (PrimState m) Int type Logger ma = Memory m -> Code -> VM a -> m (VM a) type Program' ma = Logger ma -> Memory m -> Program ma
构造函数将具有另一个表示内存访问的参数。 执行器将发生重大变化,尤其是那些保留了计算日志的执行器,因为现在他们需要询问变量向量的状态。 可以在存储库中查看和研究完整的代码 ,但是在这里,我将提供最有趣的信息:用于处理内存的基本组件的实现,以演示如何完成此工作。
geti :: PrimMonad m => Int -> Program' ma geti i = programM (GETI i) $ \mem -> \s -> if (0 <= i && i < memSize) then \vm -> do x <- M.unsafeRead mem i setStack (x:s) vm else err "index out of range" puti :: PrimMonad m => Int -> Program' ma puti i = programM (PUTI i) $ \mem -> \case (x:s) -> if (0 <= i && i < memSize) then \vm -> do M.unsafeWrite mem ix setStack s vm else err "index out of range" _ -> err "expected an element" get :: PrimMonad m => Program' ma get = programM (GET) $ \m -> \case (i:s) -> \vm -> do x <- M.read mi setStack (x:s) vm _ -> err "expected an element" put :: PrimMonad m => Program' ma put = programM (PUT) $ \m -> \case (i:x:s) -> \vm -> M.write mix >> setStack s vm _ -> err "expected two elemets"
优化器守护程序立即提供了节省检查内存中允许的索引值的更多信息,因为对于puti和puti geti索引在程序创建阶段就已知,并且可以预先消除不正确的值。 动态定义put和get命令的索引不能保证安全性,并且数学家天使不允许对其进行危险的调用。
将内存放在一个单独的参数中的所有这些大惊小怪似乎很复杂。 但是它非常清楚地表明,数据将按其位置进行更改- 它们应该在外部 。 我提醒您,我们正在尝试将披萨送货员带到无菌实验室。 纯粹的功能知道如何处理它们,但是这些对象永远不会成为一流的公民,因此不值得在实验室里准备比萨。
让我们检查一下通过这些更改购买了什么:
$ ./Monopig5 +RTS -sstderr "Ok" 9,169,192,928 bytes allocated in the heap 2,006,680 bytes copied during GC 529,608 bytes maximum residency (2 sample(s)) 25,248 bytes maximum slop 2 MB total memory in use (0 MB lost due to fragmentation) Tot time (elapsed) Avg pause Max pause Gen 0 17693 colls, 0 par 0.094s 0.093s 0.0000s 0.0001s Gen 1 2 colls, 0 par 0.000s 0.000s 0.0002s 0.0003s INIT time 0.000s ( 0.000s elapsed) MUT time 7.228s ( 7.232s elapsed) GC time 0.094s ( 0.093s elapsed) EXIT time 0.000s ( 0.000s elapsed) Total time 7.325s ( 7.326s elapsed) %GC time 1.3% (1.3% elapsed) Alloc rate 1,268,570,828 bytes per MUT second Productivity 98.7% of total user, 98.7% of total elapsed
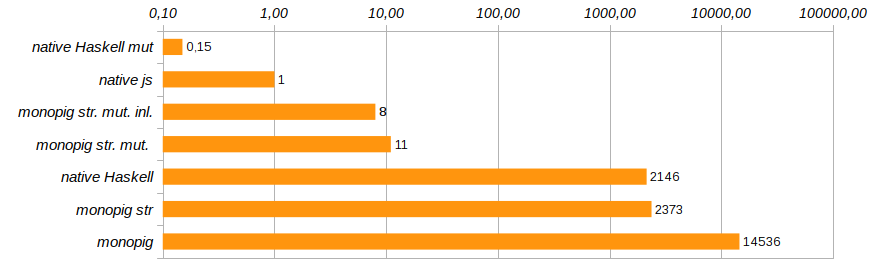
这已经是进步了! 内存使用量减少了八倍,程序执行速度提高了180倍,垃圾收集器几乎完全没有工作。

溶液出现monopig st。 mut。 ,它比js上的本机解决方案慢十倍,但除此之外,还使用可变向量在Haskell上的本机解决方案。 这是他的代码:
fill' :: Int -> Int -> Memory IO -> IO (Memory IO) fill' knm | n > memSize-k = return m | otherwise = M.unsafeWrite mn 1 >> fill' k (n+k) m sieve' :: Int -> Memory IO -> IO (Memory IO) sieve' km | k*k < memSize = do x <- M.unsafeRead mk if x == 0 then fill' k (2*k) m >>= sieve' (k+1) else sieve' (k+1) m | otherwise = return m
它开始如下
main = do m <- M.replicate memSize 0 stimes 100 (sieve' 2 m >> return ()) print "Ok"
现在,Haskell终于表明他不是玩具语言。 您只需要明智地使用它。 顺便说一句,以上代码使用IO ()类型通过顺序执行程序(>>)的操作形成半组这一事实,并且借助stimes我们对测试问题的计算重复了100次。
现在很清楚,为什么不喜欢函数数组,为什么没人记得如何使用它们:Haskell程序员真正需要随机访问结构后,他立即将重点放在可变数据上,并在ST或IO monad中工作。
将命令的一部分带入一个特殊区域会引起同构合法性的质疑 该程序 。 毕竟,我们不能将代码同时转换为纯程序和单子程序,这不允许类型系统执行。 但是,类型类足够灵活,可以存在这种同构。 同态码 现在, 该程序针对该语言的不同子集分为几种同构。 可以在程序的完整[code]()中看到如何完成此操作。
不要停在那里
使用{-# INLINE #-}编译指示消除不必要的函数调用并直接嵌入其代码将有助于稍微改变程序的生产率。 此方法不适用于递归函数,但对于基本组件和设置器函数非常有用。 它将测试程序的执行时间减少了25%(请参见Monopig51.hs )。
下一步的合理步骤是在不需要日志工具时将其删除。 在表示程序的同构状态的阶段,我们使用一个外部参数,该参数在启动时确定。 可以警告智能构造函数program和programM ,可能没有参数记录器。 在这种情况下,转换器代码不包含任何多余的内容:仅包含功能和检查计算机的状态。
program code f = programM code (const f) programM code f (Just logger) mem = Program . ([code],) . ActionM $ \vm -> case status vm of Nothing -> logger mem code =<< f mem (stack vm) vm _ -> return vm programM code f _ mem = Program . ([code],) . ActionM $ \vm -> case status vm of Nothing -> f mem (stack vm) vm _ -> return vm
现在,执行函数必须不使用none存根而是使用Maybe (Logger ma)类型Maybe (Logger ma)显式指示是否存在日志。 为什么要这样做,因为如果有日志记录,程序组件将在执行之前“在最后一刻”找出来? 在编写程序的阶段是否会缝制不必要的代码? Haskell是一种懒惰的语言,在这里它会发挥作用。 在执行之前,最终代码针对特定任务进行了优化。 这种优化使程序执行时间又减少了40%(请参见Monopig52.hs )。
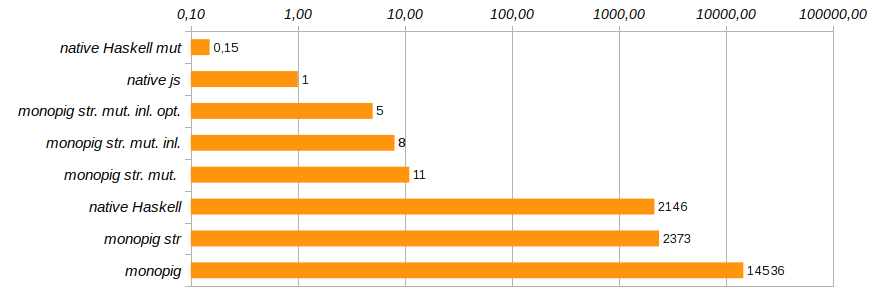
至此,我们将完成加速单节仔猪的工作。 他已经足够快地奔跑,以使天使和恶魔都能平静下来。 当然,这不是C,我们仍然使用一个干净的列表作为堆栈,但是用数组替换它会导致对代码的彻底挖掘,并且拒绝在基本命令的定义中使用优雅的模板。 我想通过最少的更改来实现,主要是在类型级别上。
日志记录仍然存在一些问题。 简单地计算步数或使用堆栈效果很好(我们将日志字段设置为严格),但是将它们配对已经开始占用内存,您必须使用seq来烦扰一下,这已经很烦人了。 但是请告诉我,如果您可以在前数百个调试任务,谁将记录140亿步? 因此,我不会花时间加速工作。
剩下的只是在关于仔猪的文章中补充说,作为优化计算的一种方法,给出了跟踪:代码的线性部分的分配, 跟踪可以在其中绕过主命令分配周期( switch块)执行计算的跟踪 。 在我们的情况下,程序组件的单调组合在从EDSL组件形成程序的过程中,或者在fromCode同态的操作过程中都会创建这样的痕迹。 可以说,这种优化方法是免费提供给我们的。
Haskell生态系统中有许多Conduits而快速的解决方案,例如Conduits或Pipes流,出色的String替换和灵活的XML创建者(例如blaze-html),以及attoparsec解析器是LL(∞)语法组合分析的标准。 所有这些对于正常操作都是必需的。 但是,更需要进行研究以做出这些决定。 Haskell一直是并且仍然是一种满足一般公众不需要的特定要求的研究工具。 我在堪察加看到,一架Mi-4直升机上的A是如何在争吵中关闭火柴盒的,在悬空时用轮子推着起落架。 可以做到,而且很酷,但这不是必须的。
但是,尽管如此,这很酷!