



本文讨论了由两个
编译器链
执行的最有趣的转换(第一个编译器将Python代码转换为
新编程语言11l中的代码,第二个将C ++转换为11l代码),还将性能与其他加速工具进行了比较/ Python代码执行(PyPy,Cython,Nuitka)。
用范围替换切片\切片
需要从数组
s[(len)-2]的末尾而不是仅从
s[-2]索引进行显式指示,以消除以下错误:
- 例如,当要求通过
s[i-1]获取前一个字符,但对于i = 0时,此/此记录而不是错误将静默返回字符串的最后一个字符[ 并且在实践中,我遇到了这样的错误- 提交 ] 。 - 当在字符串中找不到字符[ 而不是从第一个字符开始的字符串的''部分,然后是”字符串的最后一个字符时”,则
i = s.find(":")之后的表达式s[i:]将无法正常工作。 ,我认为在Python中使用find()函数返回-1也是不正确的[ 应该返回null / None [ 并且如果需要-1,则应明确编写: i = s.find(":") ?? -1 ] ] ) - 当n = 0时,编写
s[-n:]以获取字符串的最后n字符将无法正常工作。
比较运算符链
乍看之下,它是Python语言的一项杰出功能,但实际上,可以使用
in运算符和range轻松地放弃/分配它:
清单理解
同样,事实证明,您可以拒绝Python的另一个有趣功能-列表推导。
虽然有些
赞美列表的理解,甚至建议放弃`filter()`和`map()` ,但我发现:
在所有我看过Python的列表理解的地方,都可以轻松地通过`filter()`和`map()`函数来获得。 dirs[:] = [d for d in dirs if d[0] != '.' and d != exclude_dir] dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) '[' + ', '.join(python_types_to_11l[ty] for ty in self.type_args) + ']' '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']'
11l中的`filter()`和`map()`比Python更漂亮 dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) dirs = dirs.filter(d -> d[0] != '.' & d != @exclude_dir) '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']' '['(.type_args.map(ty -> :python_types_to_11l[ty]).join(', '))']' outfile.write("\n".join(x[1] for x in fileslist if x[0])) outfile.write("\n".join(map(lambda x: x[1], filter(lambda x: x[0], fileslist)))) outfile.write(fileslist.filter(x -> x[0]).map(x -> x[1]).join("\n"))
因此,11l中对列表理解的需求实际上就消失了[在 Python代码自动转换为11l的过程中,用filter()和/或map()替换列表理解filter() 。
将if-elif-else链转换为switch
尽管Python不包含switch语句,但这是11l中最漂亮的结构之一,因此我决定自动插入switch:
为了完整起见,这是生成的C ++代码 switch (instr[i]) { case u'[': nesting_level++; break; case u']': if (--nesting_level == 0) goto break_; break; case u''': ending_tags.append(u"'"_S); break; // '' case u''': assert(ending_tags.pop() == u'''); break; }
将小词典转换为本地代码
考虑以下这行Python代码:
tag = {'*':'b', '_':'u', '-':'s', '~':'i'}[prev_char()]
最有可能的是,这种录音形式
[ 在演奏方面 ]不是很有效,但是非常方便。
在11l中,与该行相对应的条目(
并由Python传输器→11l获得)不仅方便
[ 但是,不如Python优雅 ] ,但也很快:
var tag = switch prev_char() {'*' {'b'}; '_' {'u'}; '-' {'s'}; '~' {'i'}}
上一行转换为:
auto tag = [&](const auto &a){return a == u'*' ? u'b'_C : a == u'_' ? u'u'_C : a == u'-' ? u's'_C : a == u'~' ? u'i'_C : throw KeyError(a);}(prev_char());
[ 在优化过程中,lambda函数调用将由C ++编译器\内联编译,仅运算符链将保留?/: ]在分配变量的情况下,字典保持原样:
捕获\捕获外部变量
在Python中,为了指示变量不是局部变量,而应将其带到
[ 当前函数之外 ] ,请使用nonlocal关键字
[ 否则,例如, found = True将被视为创建新的局部变量found ,而不是已经分配值现有外部变量 ] 。
在11l中,@前缀用于此目的:
C ++:
auto writepos = 0; auto write_to_pos = [..., &outfile, &writepos](const auto &pos, const auto &npos) { outfile.write(...); writepos = npos; };
全局变量
与外部变量类似,如果您忘记在Python中
使用global关键字声明全局变量,则会看到一个看不见的错误:
与Python
[ left ]不同,11l代码
[ right ]在编译
break_label_index将
break_label_index “未声明的
break_label_index变量”错误。
当前容器项目的索引/编号
我一直忘了
enumerate Python函数返回的变量的顺序{值先出现,然后是索引,反之亦然}。 Ruby中的模拟行为
each.with_index更容易记住:使用index意味着索引在值之后,而不是在值之后。 但是在11l中,逻辑甚至更容易记住:
性能表现
将PC标记转换为HTML的程序用作测试
程序 ,
有关PC标记的
文章的源代码用作源数据
[ 因为本文是当前在PC标记上编写的文章中最大的 ] ,并且重复了10次,即从48.8 KB文章文件大小488Kb获得。
这是一个图表,显示了执行Python代码的相应方式比原始实现
[ CPython ]快多少倍:
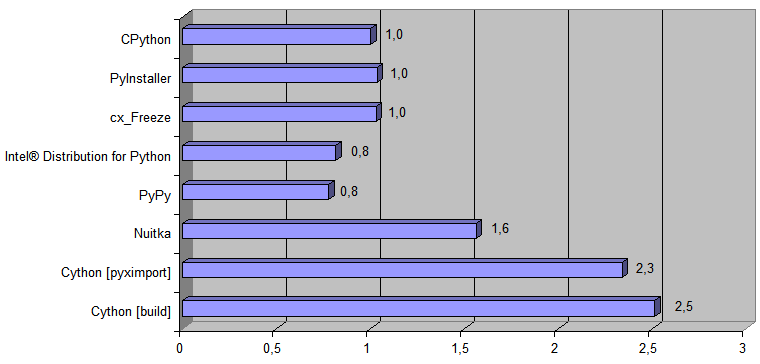
现在,将由Python→11l→C ++编译器生成的实现添加到图中: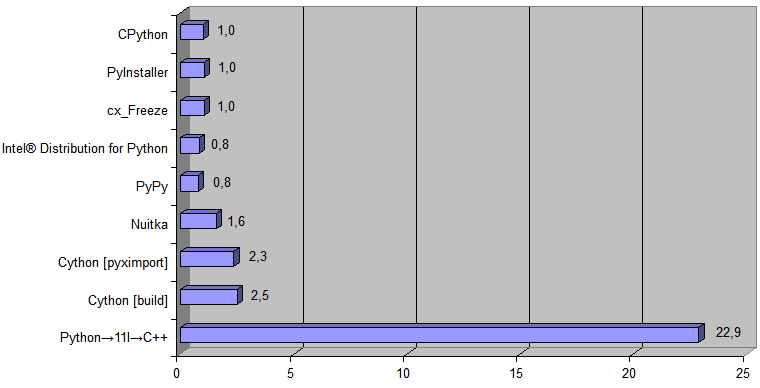
CPython的运行时
[ 488Kb文件转换时间 ]为868毫秒,生成的C ++代码的运行时
[ 488Kb文件转换时间 ]为38毫秒
[ 该时间包括完整的[ 即 不仅是由操作系统运行程序的RAM中的数据和所有输入/输出[ 读取源文件[ .pq ]并将新文件[ .html ]保存到磁盘 ] ] 。
我也想尝试
Shed Skin ,但是它不支持本地功能。
Numba也无法使用(它抛出错误“使用未知的操作码LOAD_BUILD_CLASS”)。
这是带有用于比较性能的程序
的存档 [ 在Windows下 ] (需要Python 3.6或更高版本,以及以下Python软件包:pywin32,cython)。
Python的源代码和Python编译器-> 11l和11l-> C ++的输出: