由不同编解码器以近似相同的BPP值(每像素位数)压缩的视频片段的重建示例。 比较测试结果见猫WaveOne的研究人员
声称即将在视频压缩领域掀起一场革命。 在处理高清1080p视频时,他们的
新型机器学习编解码器将视频压缩比最现代的传统视频编解码器(例如H.265和VP9)好约20%。 在“标清”视频(SD / VGA,640×480)中,差异达到60%。
开发人员称,根据现代技术的标准,在H.265和VP9中实现的当前视频压缩方法是“古老的”:“在过去20年中,现有视频压缩算法的基础没有显着改变,”这本科学文章的作者在其文章的引言中写道。 “尽管它们经过精心设计和精心调整,但仍保持硬编码,因此无法适应视频材料日益增长的需求和越来越广泛的应用范围,包括社交媒体中的交换,对象检测,虚拟现实流式传输等。”
机器学习的使用最终应该将视频压缩技术带入21世纪。 新的压缩算法明显优于现有的视频编解码器。 他们说:“据我们所知,这是第一个显示出这种结果的机器学习方法。”
视频压缩的主要思想是删除冗余数据,并用简短的描述替换它,以便您稍后播放视频。 大多数视频压缩分两个阶段进行。
第一阶段是运动压缩,当编解码器搜索运动对象并尝试预测它们在下一帧中的位置时。 然后,在每个帧中,该算法仅记录对象的形状以及运动方向,而不是记录与该运动对象相关的像素。 确实,有些算法会着眼于未来的帧来更准确地确定运动,尽管这显然不适用于直播。
第二个压缩步骤删除了一帧和下一帧之间的其他冗余。 因此,代替记录蓝天中每个像素的颜色,压缩算法可以确定该颜色的区域并指示其在接下来的几帧中没有变化。 因此,这些像素保持相同的颜色,直到被告知要更改。 这称为残余压缩。
科学家引入的新方法首次使用机器学习来改进这两种压缩方法。 因此,在压缩运动时,团队的机器学习方法发现了基于运动的新冗余,而传统的编解码器则无法检测到这种冗余,其使用量大大减少了。 例如,将一个人的头部从正面的视图变成一个轮廓总是会得到类似的结果:“传统的编解码器无法基于正面的视图预测一个人的轮廓,”科学论文的作者写道。 相反,新的编解码器研究了这些类型的时空模式,并使用它们来预测未来的帧。
另一个问题是在运动和残余压缩之间分配可用带宽。 在某些场景中,运动压缩更为重要,而在另一些场景中,残余压缩可提供最大的增益。 它们之间的最佳折衷因帧而异。
传统算法彼此独立地处理两个过程。 这意味着没有一种简单的方法可以给彼此带来好处并找到折衷方案。
作者通过同时压缩两个信号来规避此问题,并根据帧的复杂性确定如何以最有效的方式在两个信号之间分配带宽。
这些和其他改进使研究人员能够创建一种压缩算法,该算法远远超过了传统的编解码器(请参见下面的基准)。
 由具有大约相同的BPP值的不同编解码器压缩的片段的重建示例显示了WaveOne编解码器的显着优势
由具有大约相同的BPP值的不同编解码器压缩的片段的重建示例显示了WaveOne编解码器的显着优势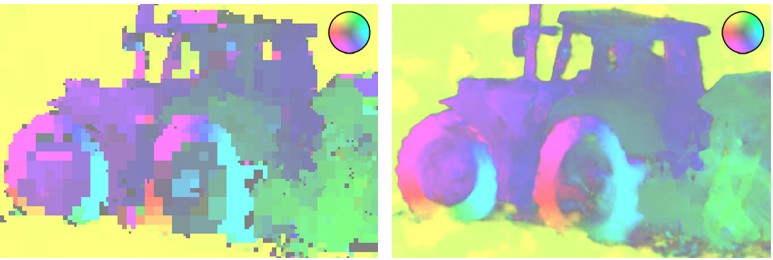 相同比特率的H.265光流卡(左)和WaveOne编解码器(右)
相同比特率的H.265光流卡(左)和WaveOne编解码器(右)但是,《
MIT技术评论》 指出 ,这种新方法并非没有缺点。 可能的主要缺点是计算效率低,即编码和解码视频所需的时间。 在Nvidia Tesla V100平台和VGA大小的视频上,新解码器的平均速度约为每秒10帧,编码器的速度约为每秒2帧。 这样的速度根本无法在实时视频广播中使用,并且通过离线编码材料,新编码器的范围将非常有限。
而且,解码器的速度甚至不足以在普通的个人计算机上
观看用该编解码器压缩
的视频。 即,为了观看这些视频,即使以最低的SD质量,当前也需要具有多个图形加速器的整个计算集群。 要观看高清(1080p)品质的视频,您需要一个完整的计算机场。
他们只能寄希望于将来增加图形处理器的功能并改善技术:“目前的速度不足以实时部署,但应该在以后的工作中显着提高。”
基准测试
HEVC/H.265, AVC/H.264, VP9 HEVC HM 16.0 . Ffmpeg, — . , . , B- H.264/5
bframes=0,
-auto-alt-ref 0 -lag-in-frames 0 . MS-SSIM, ,
-ssim.
SD HD, . SD- VGA e Consumer Digital Video Library (CDVL). 34 15 650 . HD Xiph 1080p: 22 11 680 . 1080p 1024 ( , 32 ).
:
- MS-SSIM ;
- MS-SSIM ;
- WaveOne ( ).
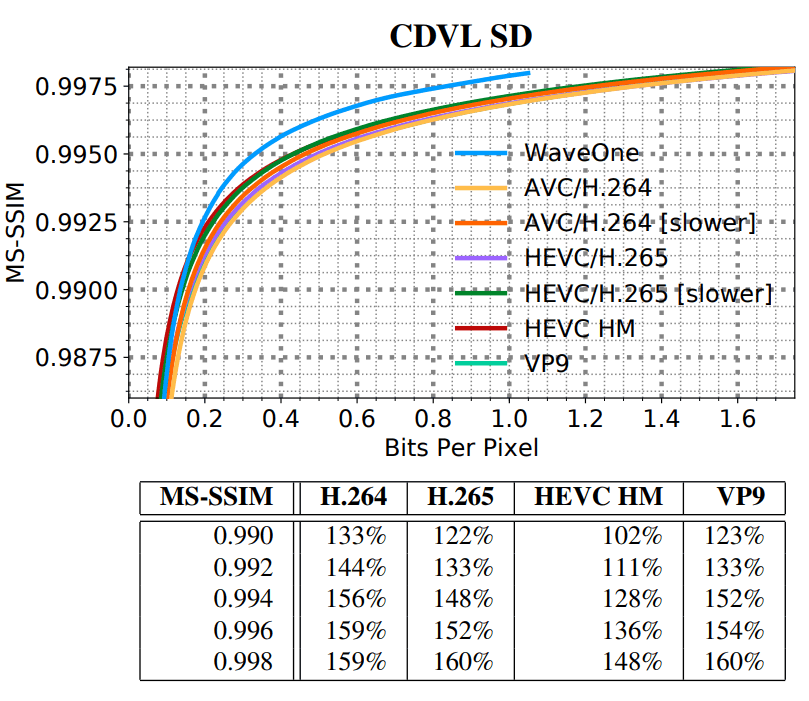 (SD)
(SD)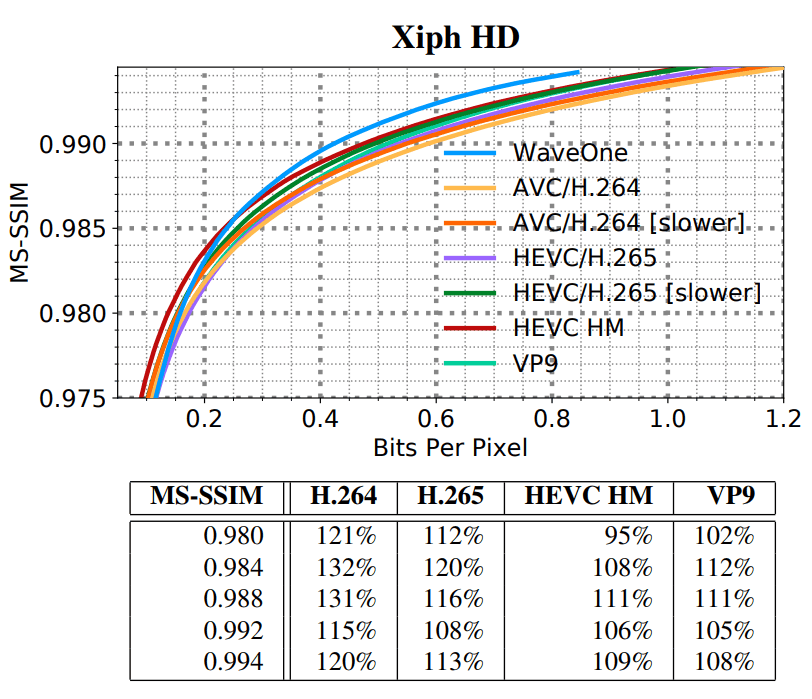 (HD)
(HD)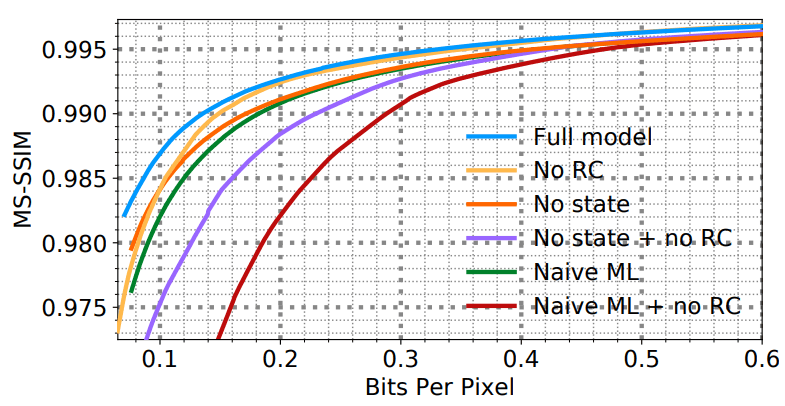 WaveOne
WaveOne. , . . , . G. Toderici, S. M. O’Malley, S. J. Hwang, D. Vincent, D. Minnen, S. Baluja, M. Covell, R. Sukthankar.
Variable rate image compression with recurrent neural networks, 2015; G. Toderici, D. Vincent, N. Johnston, S. J. Hwang, D. Minnen, J. Shor, M. Covell.
Full resolution image compression with recurrent neural networks, 2016; J. Balle, V. Laparra, E. P. Simoncelli.
End-to-end optimized image compression, 2016; N. Johnston, D. Vincent, D. Minnen, M. Covell, S. Singh, T. Chinen, S. J. Hwang, J. Shor, G. Toderici.
Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks, 2017 . , , .
ML- , . . . C.-Y. Wu, N. Singhal, and P. Krahenbuhl.
Video compression through image interpolation, ECCV (2018). , . AVC/H.264. , .
« » 16 2018 arXiv.org (arXiv:1811.06981). — (Oren Rippel), (Sanjay Nair), (Carissa Lew), (Steve Branson), (Alexander G. Anderson), (Lubomir Bourdev).
Stas911:
Altaisky: . ?
Stas911: . .