
对于我们来说,一个典型的系统集成项目如下所示:客户拥有用于向客户计费的系统,任务是将客户卡收集到一个数据库中。 并且不仅要收集,还要清除重复项和垃圾。 要获得整洁,结构完整的客户卡。
对于初学者,我将解释迁移是根据以下方案进行的:
源→数据转换( ETL或总线响应)→接收器 。
在一个项目中,我们损失了三个月,仅仅是因为第三方集成商团队没有研究源系统中的数据。 最令人讨厌的是可以避免这种情况。
他们像这样工作:
- 系统集成商可定制ETL流程。
- ETL转换源数据并将其提供给我。
- 我研究卸载并将错误发送给集成商。
- 集成商会更正ETL,然后重新开始迁移。
在本文中,我将展示如何在系统集成期间分析数据。 我研究了ETL上传,这非常有用。 但是在源数据上,相同的技术将使工作速度提高两倍。
提示对测试人员,企业产品实施人员,系统集成人员和分析人员将非常有用。 接收对于关系数据库是通用的,并且已从100万个客户的数量中充分披露。
但是首先,关于系统集成的主要神话之一。
文档和架构师将提供帮助(实际上没有帮助)
集成商通常在迁移之前不研究数据-这样可以节省时间。 他们阅读了文档,看了看结构,与架构师交谈-这就足够了。 之后,他们已经在计划整合。
原来不好。 只有分析才能显示数据库中的实际情况。 如果您不使用卷起的袖子和放大镜进入数据,则迁移会出错。
该文件是在撒谎。 典型的企业系统运行5至20年。 这些年来,各个部门和承包商都记录了其中的变化。 每个都有自己的钟楼。 因此,文档中没有完整性,没有人完全了解数据存储的逻辑和结构。 更不用说截止日期总是在,而且没有足够的时间来记录文件。
一个普通的故事:在客户表中有一个“ SNILS”字段,在纸上非常重要。 但是当我查看数据时,我看到了-该字段为空。 结果,客户同意目标库将没有SNILS字段,因为仍然没有数据。
文档的一种特殊情况是业务流程的法规和描述:数据如何在何种情况下以何种格式进入数据库。 所有这些都将无济于事。
业务流程仅在纸上是完美的。 清晨,昏昏欲睡的操作员Anatoly来到Vyksa郊区的银行办公室。 他们在窗户下尖叫了一整夜,早晨,阿纳托利与女孩打架。 他讨厌整个世界。
神经尚未整理好,Anatoly将新客户端的名称完全驱动到姓氏字段中。 他完全忘记了自己的生日-表格中保留了默认的“ 01.01.1900 g”。 当周围的一切都如此令人发指的时候,我不会对规则一无所知!
混乱征服了业务流程,在纸面上比例很高。
系统架构师并不了解所有内容。 再次是关于企业系统的古老寿命。 经过多年的工作,建筑师已经发生了变化。 即使您与当前的项目进行交谈,在项目期间,前一个项目的决定也会出乎意料。
并确保:即使在各个方面都令人愉悦的架构师,也要保守他对系统的狂热和拐杖的秘密。
没有数据分析的“通过工具”集成是一个错误。 我将展示HFLabs我们如何通过系统集成来学习数据。 在上一个项目中,我仅分析了ETL上传。 但是,当客户允许访问源数据时,我绝对会按照相同的原则进行检查。
填充的字段和空值
最简单的检查是对整个表的完整性和单个字段的完整性进行检查。 我从他们开始。
表中总共有多少行。 最简单的请求。
SELECT COUNT(*) FROM <table_name>;
我得到第一个结果。
在这里,我看一下数据的充分性。 如果只有200万客户来一家大型银行卸货,那显然是错误的。 但是,尽管一切看起来都如预期,但继续前进。
每个字段分别填充多少行。 我检查表的所有列。
SELECT <column_name>, COUNT(*) AS <column_name> cnt FROM <table_name> WHERE <column_name> IS NOT NULL;
第一个遇到生日快乐字段,立即感到好奇:由于某种原因,数据根本没有。
如果上载中字段中的所有值均为“ NULL”,那么我首先要看的是源系统。 也许数据正确地存储在那里,但是在迁移过程中它们丢失了。
我看到在源系统中生日已经到位。 我去找集成商:伙计们,错了。 事实证明,在ETL过程中,解码功能无法正常工作。 该代码是固定的,在下一次上传中,我们将检查更改。
我和TIN一起走到更远的地方。
数据库中有1亿人口,只有6.5万人充满了TIN-这是0.07%。 如此小的占用率是信号,表明接收器基座中的场可能根本不需要。
我检查了源系统,一切都是正确的:TIN与实际的相似,但几乎没有。 因此,这与迁移无关。 仍然需要找出客户是否需要目标数据库中TIN下的几乎为空的字段。
我到达了客户端删除标志。
标志为空。 但是,该公司不会移除客户吗? 我看一下源系统,与客户交谈。 事实证明是:该标志是正式的,而不是删除客户,而是删除了他们的帐户。 没有帐户-就像删除客户端一样。
在目标系统中,需要远程客户端标志,这是体系结构的功能。 因此,如果客户在接收方系统中的帐户为零,则需要通过附加逻辑将其关闭或完全不导入。 然后客户如何决定。
接下来是地址板。 通常,此类表出了问题,因为地址是一件复杂的事情,因此它们以不同的方式输入。
我检查地址组成部分的完整性。
地址并没有统一填写,但是得出结论还为时过早:首先,我要问客户他们要做什么。 如果按国家进行细分,那么一切都很好:有足够的数据。 如果是邮件列表,那么问题就在于:房屋几乎是空的,没有公寓。
结果,客户看到ETL正在从一个不相关的旧平板电脑获取地址。 她像纪念碑一样在基地。 但是还有另一个表,又新又好,必须从中获取数据。
在分析过程中,我特别填写了链接到目录的字段。 “ IS NOT NULL”条件不适用于它们:单元通常不是“ NULL”,而是“ 0”。 因此,请分别检查参考字段。
字段填充的变化。 因此,我检查了每个字段的总体占用率。 发现问题后,集成商修复了ETL流程,并再次开始了迁移。
我对上面列出的所有步骤进行第二次卸载。 我将统计信息写入同一文件以查看更改。
所有领域的完整性。
在两次上载之间,有500万条记录消失了。 我去集成商,问一些典型的问题:
- “为什么记录丢失了?”;
- “筛选出了哪些数据?”;
- “您留下了什么数据?”
事实证明,这没有问题:他们只是将“技术”客户从全新的卸载中删除了。 他们在数据库中进行测试,他们不是活人。 但是,以相同的概率,数据可能会被错误地丢失,这种情况会发生。
但正如我所料,新卸货中的生日出现了。
但是! 当以前丢失的数据突然出现在新的上传文件中时,不一定很好。 例如,生日可以用默认日期填充-没有什么值得高兴的。 因此,我总是检查哪些数据来了。
简而言之,要检查的内容。
- 表中的条目总数。 这个数量是否足以达到期望?
- 每个字段中的填充线数。
- 每个字段中已填充的行数与表中的行数之比。 如果太小,这是考虑是否将字段拖到目标库的机会。
对每个上传重复前三个步骤。 跟随动态:在何处以及为何增加或减少。字符串字段中值的长度
我遵循测试的基本规则之一-检查边界值。
哪些值太短。 最短的值中有很多是垃圾,因此在这里进行挖掘很有趣。
SELECT * FROM <table_name> WHERE LENGTH(<column_name>) < 3;
这样,我检查了姓名,电话号码,TIN,OKVED,网站地址。 废话弹出,如“ A * 1”,“ 0”,“ 11”,“-”和“ ...”。
最大值可以吗? 关闭字段表示数据在传输期间不适合,并且这些数据会自动被切断。 MySQL擅自破解此漏洞而没有警告。 同时,迁移似乎进展顺利。
SELECT * FROM <table_name> WHERE LENGTH(<column_name>) = 65;
这样,我在文件类型的字段中找到了“移民承认他的申请书的注册证明”行。 她告诉积分员,字段长度已更正。
值如何沿长度分布。 在HFLabs中,我们将行的长度分布表称为。
SELECT LENGTH(<column_name>), COUNT(<column_name>) FROM <table_name> GROUP BY LENGTH(<column_name>);
我在这里寻找沿长度分布的异常情况。 例如,这是带有邮件地址的表的频率。
长度为125的值太多。 我查看了源数据库,发现由于某种原因,三年前某些地址被截断为125个字符。 在其他年份,一切都很好。 我们理解这个问题给客户和集成商。
简而言之,要检查的内容。
- 字符串字段中最短的值。 少于三个字符的行通常是垃圾。
- 沿字段宽度的长度“邻接”的值。 他们经常被割礼。
- 行中沿行的分布异常。
大众价值观
我将最受欢迎的值分为三类:
- 确实很常见 ,例如名称“ Tatyana”或中间名称“ Vladimirovich”。 这里必须记住,在一般情况下,塔季扬娜的流行度不应该是安娜的100倍,而伊斯梅尔几乎不比埃戈尔流行。
- 垃圾 ,例如“。”,“ 1”,“-”等;
- 输入表单上的默认值 ,日期为“ 01/01/1900”。
三分之二的案例是问题的标记,寻找它们很有用。
我在三种类型的字段中搜索流行的值:
- 普通字符串字段。
- 参考字符串字段。 这些是普通的字符串字段,但是其中的不同值的数量当然是受限制的。 这些字段存储国家,城市,月份,电话类型。
- 分类器字段-它们包含指向第三方分类器表中条目的链接。
我对每种类型的字段进行了一些不同的研究。
对于字符串字段-最受欢迎的100个值是什么? 如果需要,可以增加更多的值,但是通常会在前一百个值中放置所有异常。
SELECT * FROM (SELECT <column_name>, COUNT(*) cnt FROM <table_name> GROUP BY <column_name> ORDER BY 2 DESC) WHERE ROWNUM <= 100;
我以这种方式检查字段:
- 全名,以及分别的姓,名和赞助人;
- 出生日期,通常是任何日期;
- 地址 完整地址及其各个组成部分(如果它们都存储在数据库中);
- 手机
- 文件的系列,编号,类型,签发地点。
几乎总是流行的-测试和默认值,一些存根。

碰巧发现的问题根本不是问题。 一旦我在数据库中找到一个可疑的流行电话号码。 事实证明,客户将这个数字表示为工作人员,并且在数据库中仅存在一个组织的许多员工。
一路上,这样的分析将显示隐藏的参考字段。 从逻辑上讲,这些字段不应该是目录,但实际上它们在数据库中。 例如,我从“位置”(Position)字段中选择流行的值,但其中只有五个。
也许公司只服务五个专业。 不是很对吧? 相反,以操作员的形式(而不是一行),他们创建了一个目录并忘记了转储值。 这里的重要问题是:通过目录填写帖子是否明智? 因此,通过数据分析,我发现了操作员软件可能存在的问题。
对于参考字段和分类器,我检查所有值的普及程度。 首先,我弄清楚哪些字段是目录。 您无法使用脚本,我照着文档装作。 通常,目录是为值创建的,其数量当然是相对较小的:
在理想世界中,参考字段的内容清晰且一致。 但是我们的世界不是那样,所以我提出了要求。
SELECT <column_name>, COUNT(*) cnt FROM <table_name> GROUP BY <column_name> ORDER BY 2 DESC;
通常在目录的字符串字段中。
常见问题:
发现一团糟后,我手头上有一些例子,去了集成商。 让他们在源头留下垃圾,并消除差异。 然后在严格的目标数据库中,可以将参考线变为分类器。
我检查了分类器字段中的流行值,以发现缺少选项。 面对这种情况。
这样的分类器看起来很奇怪,应该显示给客户。 每当出现此类情况时,我都会出错:数据库中有问题或从错误的位置下载了数据。
简而言之,要检查的内容。
- 哪些字符串字段是参考字段,哪些不是。
- 对于简单的字符串字段,请使用热门值。 通常在最上面的垃圾和默认数据中。
- 对于字符串引用字段,按流行度分配所有值。 该选择将显示参考值之间的差异。
- 对于分类器-数据库中是否有足够的选项。
一致性和交叉和解
从表内数据的分析,我转向关系的分析。
数据是否必然相关。 我们将此参数称为“一致性”。 我以电话的下属表为例。 一对夫妇-客户的父表。 而且我看到下级表中有多少个客户端是不在父级中的标识符。
SELECT COUNT(*) FROM ((SELECT <ID1> FROM <table_name_1>) MINUS (SELECT <ID2> FROM <table_name_2>));
如果请求给出了增量,则表示没有运气-上传中包含无关的数据。 因此,我使用电话,合同,地址,账单等检查表格。 有一次,在一个项目中,她发现2300万个数字悬在空中。
它也朝着相反的方向工作-我正在寻找由于某种原因而没有单一合同,地址和电话号码的客户。 有时候这很正常-嗯,客户没有地址,这是怎么回事。 在这里,您需要从客户那里查找文档,这很容易欺骗。
不同表中是否存在主键重复项。 有时,相同的实体存储在不同的表中。 例如,异性恋客户。 (没有人知道为什么,因为勃列日涅夫仍然主张该结构。)但是接收者中的表是单个的,并且在迁移时,客户端标识符将发生冲突。
我转过头看了看基地的结构:类似实体可能分裂的地方。 它可以是客户表,联系电话,护照等。
如果有多个具有相似实体的表,则进行交叉检查:检查标识符的交集。 相交-粘贴补丁。 例如,我们根据“源表名称+ ID”方案收集单个表的标识符。
简而言之,要检查的内容。
- 链接表中有多少不相关的数据。
- 是否存在潜在的主键冲突?
还有什么要检查的
是否有不属于他们的拉丁字符。 例如,使用姓氏。
SELECT <column_name> FROM <table_name> WHERE REGEXP_LIKE(<column_name>, '[AZ]', 'i');
因此,我看到了奇妙的拉丁字母“ C”,与西里尔字母重合。 错误是令人不愉快的,因为根据带有拉丁文“ C”的名称,操作员将永远找不到客户。
用于数字的字符串字段中是否有多余的字符? SELECT <column_name> FROM <table_name> WHERE REGEXP_LIKE(<column_name>, '[^0-9]');
问题在带有俄罗斯联邦或TIN护照号码的字段中弹出。 电话是一样的,但我允许加号,方括号和连字符。 该请求还将显示字母“ O”,该字母已设置而不是零。
数据是否足够。 您永远都不知道问题会在哪里出现,所以我时刻保持警惕。 我遇到过这样的情况:
- 客户“ Sofya Vladimirovna”是否有50,000部电话-这正常吗? 答:不正常。 客户是技术人员,他们将“无主”的电话号码放在他身上,以发送短信。 不必将客户拉到新的基础上。
- 填写纳税人识别号,实际上,该列包含“ 79853617764”,“ 89109462345”,“ 4956780966”等。 什么样的手机,奥田? 客栈在哪 答:尚不清楚是哪种数字-不知道是谁输入的。 没有人使用它们。 当前的TIN存储在另一个表的另一个字段中,取而代之。
- “一行中的地址”字段与部分存储地址的字段不对应。 为什么地址不同? 答:一旦操作员用一行填写地址,并且外部系统将地址分类到单独的字段中。 用于细分。 随着时间的流逝,人们改变了住址。 运营商会定期对其进行更新,但只能以字符串形式进行:地址部分仍旧。
您只需要SQL和Excel
要分析数据,不需要昂贵的软件。 足够好的旧Excel和SQL知识。
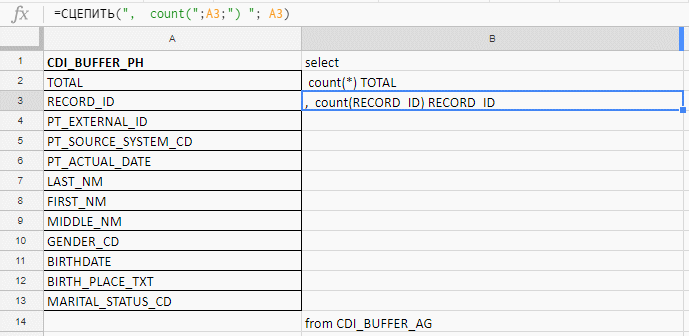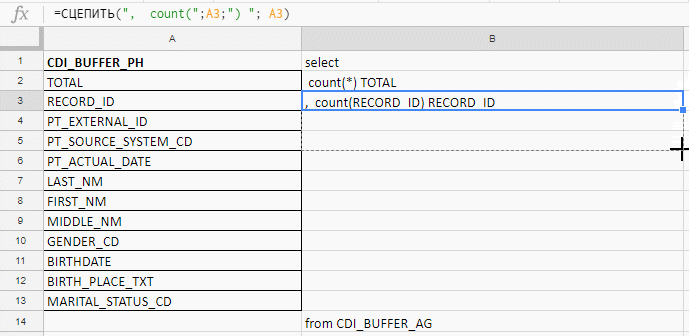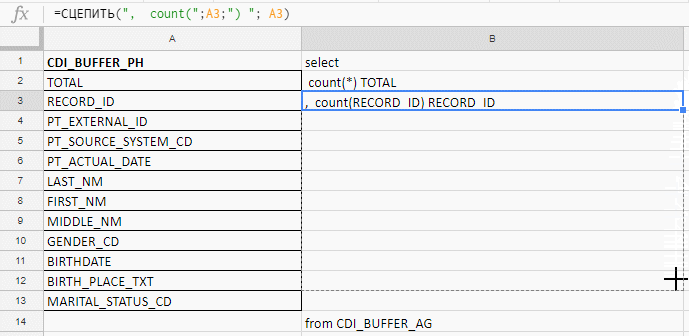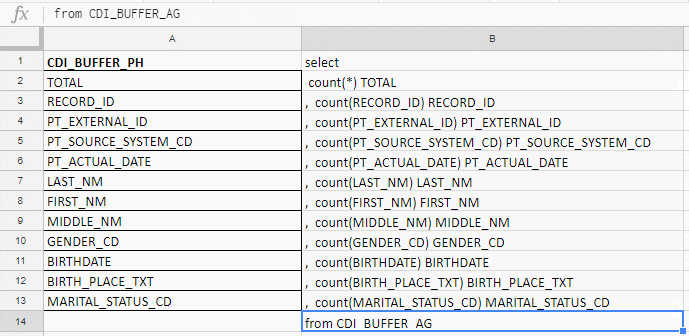
我用Excel来编译长查询。 例如,我检查了字段的完整性,表中有140个,我将在胡萝卜阴谋之前用手写来书写,因此我在excel-plate中收集了带有公式的请求。
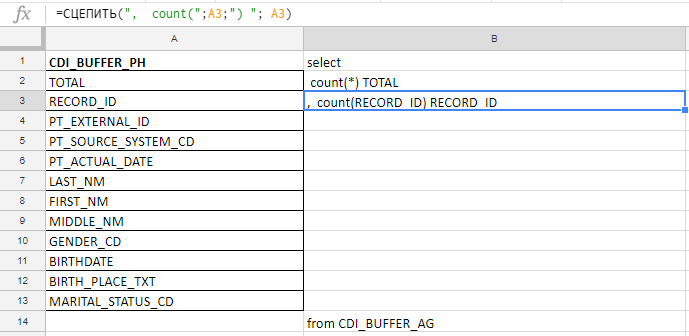 在“ A”列中,插入字段的名称,并将其放在文档或服务表中。 在“ B”列中-用于粘贴请求的公式
在“ A”列中,插入字段的名称,并将其放在文档或服务表中。 在“ B”列中-用于粘贴请求的公式我插入字段的名称,在“ B”列中写入第一个公式,将其移到角落-完成。
 在Excel,Google文档和Excel Online(在Yandex.Disk上可用)中工作
在Excel,Google文档和Excel Online(在Yandex.Disk上可用)中工作数据分析节省了时间,节省了管理人员的神经。 有了它,更容易达到截止日期。 如果项目规模很大,分析将节省数百万卢布和声誉。
不是数字,而是结论
她为自己制定了一条规则:不向客户显示任何数字,您仍然无法获得效果。 我的任务是分析数据并得出结论,并附上数字作为证据。 结论是主要的,数字是次要的。
我为报告收集的内容:
- 问题以假设或问题的形式表达 :“ TIN占0.07%。 您如何使用这些数据,它的相关性如何,如何解释它? 一张桌子上只有一个INN吗?” 您不能责怪:“您的TIN根本没有填满。” 作为回应,你只会受到侵略。
- 问题的例子。 这些是本文中的许多平板电脑。
- 这样做的选项: “可能值得从目标库中删除TIN,以免产生空白字段。”
我无权决定从源数据库中准确选择什么以及在迁移过程中如何更改数据。 因此,有了这份报告,我去了客户或集成商,我们发现了如何进行。
有时,客户看到问题后会回答:“不用担心,不要专心。 我们将购买额外的TB内存。 它比优化便宜。” 您不同意这一点:如果连续进行所有操作,接收器将没有质量。 所有相同的垃圾冗余数据正在迁移。
因此,我们轻轻而稳定地问:“告诉我们如何在目标系统中使用此特定数据。” 不是“为什么需要”,而是“您将如何使用”。 答案“那么我们会想出”或“以防万一”是不合适的。 客户迟早会了解可以分配哪些数据。
最主要的是找到并解决所有问题,直到在产品中启动系统为止。 要生动地更改架构和数据模型,您将失去理智。
这就是基本检查,研究数据!