关于Montezuma在Habré上的Revenge游戏不是那么写的。 这是一个复杂的经典游戏,以前非常流行,但是现在它可以由唤起怀旧情怀的人或开发AI的研究人员来玩。
据报道 ,今年夏天,DeepMind能够教导其AI如何为Atari玩游戏,包括Montezuma的Revenge。 使用同一游戏的示例,OpenAI的创建者也
教了他们的开发。 现在,Uber承担了类似的项目。
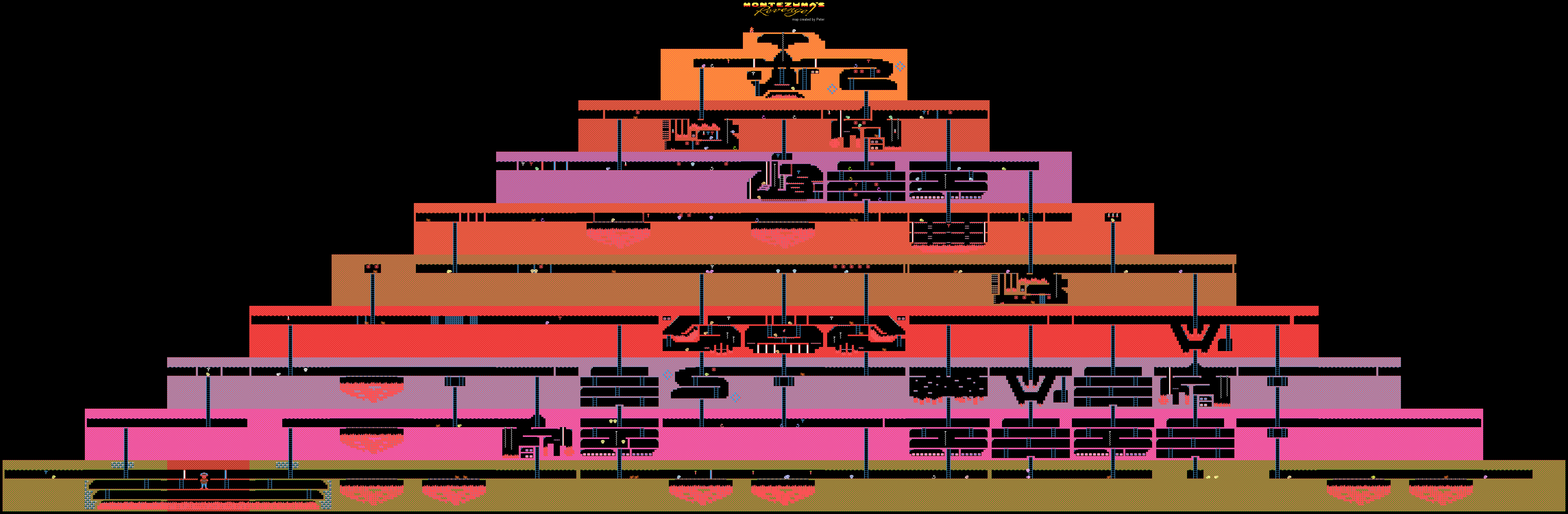
开发者通过他们的神经网络宣布了该游戏的通过,最大得分为200万,对,平均而言,每次尝试该系统赚取的收入不超过40万。 至于通过程度,计算机达到了159级。
此外,Go-Explore学习了如何进行Pitfall,其出色的结果优于普通游戏者,更不用说其他AI代理了。 在这个游戏中,Go-Explore得分了21,000。
Go-Explore及其“同事”之间的区别在于,神经网络不需要展示通过不同级别的训练。 该系统在游戏过程中会自己学习所有东西,显示出的结果远远高于需要视觉训练的神经网络所展示的结果。 根据Go-Explore的开发人员的说法,该技术与所有其他技术都有很大不同,其功能允许在包括机器人技术在内的许多领域中使用神经网络。
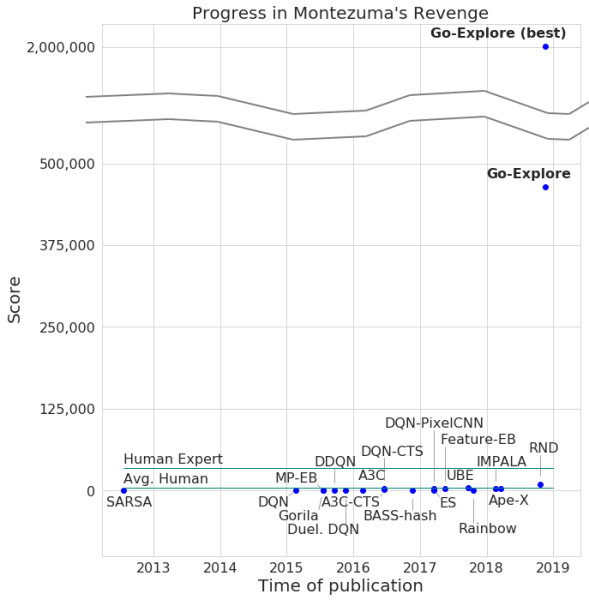
大多数算法都发现应对蒙特祖玛的《复仇》非常困难,因为游戏没有非常明确的反馈。 例如,在经过关卡的过程中被“强化”以获取奖励的神经网络宁可与敌人战斗,也不愿跳上通往出口的梯子,并允许您更快地前进。 其他AI系统更喜欢在此时此地获得奖励,而不是在“希望”中继续前进。
Uber工程师的决定之一是为探索游戏世界增加奖励,这可以称为AI的内部动机。 但是,即使具有附加内在动力的AI元素也不能很好地与Montezuma的Revenge and Pitfall相提并论。 问题在于,人工智能在通过有希望的位置后会“忘记”它们。 结果,AI代理陷入了似乎已对所有内容进行调查的水平。
AI代理就是一个例子,它需要研究两个迷宫-东方和西方。 他开始经历其中之一,但随后突然决定可以经历第二场。 研究的第一份遗骸为50%,第二份为100%。 探员并没有回到第一个迷宫-仅仅是因为他“忘记”了自己还没有完成。 并且由于已经研究了东西方迷宫之间的通道,因此AI没有返回的动力。
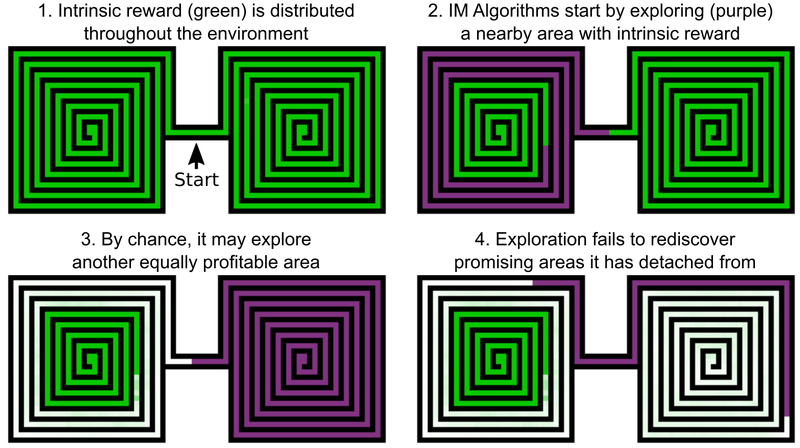
Uber开发人员表示,解决此问题的方法包括两个阶段:研究和扩大。 对于第一部分,此处的AI创建了各种游戏状态(单元(单元))以及导致它们的各种轨迹的存档。 AI选择检测最佳轨迹时获得最大点数的机会。
单元是简化的游戏框架-带有8像素强度的灰色阴影的11 x 8图像,并且框架之间的差异足够大-以免妨碍游戏的进一步进行。

结果,AI记住了有希望的位置,并在检查了游戏世界的其他部分之后将其返回。 在Go-Explore上探索游戏世界和有希望的地点的“愿望”比在此时此地获得奖励的愿望更强烈。 Go-Explore还使用有关在其中训练了AI代理的单元的信息。 对于Montezuma的Revenge,它是像素数据,例如其X和Y坐标,当前房间以及找到的关键点数量。
放大级起到防止“噪声”的作用。 如果AI解决方案对于“噪声”不稳定,那么AI将在人脑神经元示例的多级神经网络的帮助下增强它们。

在测试中,Go-Explore的表现非常出色-平均而言,人工智能学习了37个房间并解决了65%的一级难题。 这比以前征服游戏的尝试要好得多-然后AI平均研究了第一层的22个房间。

当为现有算法增加收益时,AI开始平均成功完成29个级别(而非房间)的平均评分,平均得分为469.209。
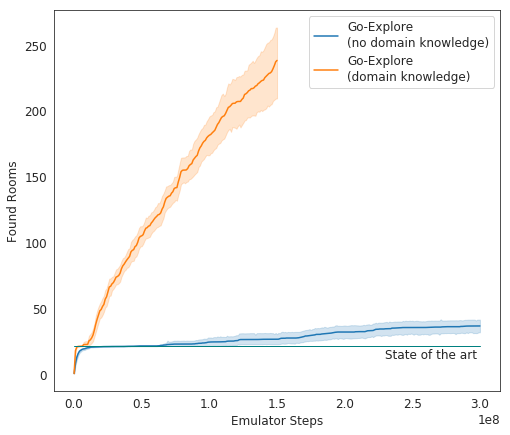
Uber AI的最终化身开始比其他AI代理更好地运行了游戏,也比人类更好。 现在,开发人员正在改进他们的系统,以使其显示出更加令人印象深刻的结果。