这篇文章是关于对海上寻找船只比赛的材料的分析和研究而写的。

让我们尝试了解网络寻找的方式和内容以及发现的内容。 本文只是出于好奇和闲置兴趣的结果,在实践中一无所获,对于实际任务,没有任何内容可供复制粘贴。 但是结果并不是完全预期的。 互联网上充斥着对网络操作的描述,作者在其中详细介绍了图像,并生动描述了网络如何确定原始元素(角度,圆,胡须,尾巴等),然后对其进行搜索以进行分段/分类。 使用来自其他大型和广域网络的权重,可以赢得很多比赛。 理解并了解网络是如何构建的以及什么构建了哪些原语是很有趣的。
我们将进行一次小型研究,并考虑各种选项-列出作者的推理和代码,您可以自己检查/补充/更改所有内容。
kaggle海洋搜索比赛最近结束了。 空中客车公司建议分析有船和无船的海洋卫星图像。 在总共192555张图片中,768x768x3 –如果是uint8,则为340 720 680 960字节;如果是float32,则为四倍(通过float32比float64更快,内存访问较少);在15606张图片上,您需要找到船。 像往常一样,所有重要的地方都由参与ODS(ods.ai)的人员接替,这是自然而有希望的,我希望我们能够尽快学习思路和获胜者和获奖者的守则。
我们将考虑一个类似的问题,但要对其进行显着简化-取海np.random.sample()* 0.5,我们不需要波浪,风,海滩和其他隐藏的图案和面孔。 让我们使海洋图像在0.0到0.5的RGB范围内真正随机。 我们将为船只涂上相同的颜色,并将它们与海区分开,将它们放置在0.5到1.0的范围内,并且它们的形状都相同-椭圆的大小和方向不同。

使用非常通用的网络版本(您可以使用自己喜欢的网络),我们将使用它进行所有实验。
接下来,我们将更改图片的参数,创建干扰并建立假设-因此,我们重点介绍了网络查找椭圆的主要特征。 也许读者会得出结论并反驳作者。
我们加载库,确定图片数组的大小import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import math from tqdm import tqdm_notebook, tqdm from skimage.draw import ellipse, polygon from keras import Model from keras.callbacks import EarlyStopping, ModelCheckpoint, ReduceLROnPlateau from keras.models import load_model from keras.optimizers import Adam from keras.layers import Input, Conv2D, Conv2DTranspose, MaxPooling2D, concatenate, Dropout from keras.losses import binary_crossentropy import tensorflow as tf import keras as keras from keras import backend as K from tqdm import tqdm_notebook w_size = 256 train_num = 8192 train_x = np.zeros((train_num, w_size, w_size,3), dtype='float32') train_y = np.zeros((train_num, w_size, w_size,1), dtype='float32') img_l = np.random.sample((w_size, w_size, 3))*0.5 img_h = np.random.sample((w_size, w_size, 3))*0.5 + 0.5 radius_min = 10 radius_max = 30
确定损失和准确性函数 def dice_coef(y_true, y_pred): y_true_f = K.flatten(y_true) y_pred = K.cast(y_pred, 'float32') y_pred_f = K.cast(K.greater(K.flatten(y_pred), 0.5), 'float32') intersection = y_true_f * y_pred_f score = 2. * K.sum(intersection) / (K.sum(y_true_f) + K.sum(y_pred_f)) return score def dice_loss(y_true, y_pred): smooth = 1. y_true_f = K.flatten(y_true) y_pred_f = K.flatten(y_pred) intersection = y_true_f * y_pred_f score = (2. * K.sum(intersection) + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth) return 1. - score def bce_dice_loss(y_true, y_pred): return binary_crossentropy(y_true, y_pred) + dice_loss(y_true, y_pred) def get_iou_vector(A, B):
我们在图像分割中使用经典指标,有很多文章,有关所选指标的带有注释的文本和代码,在同一kaggle上,有很多带有注释和解释的选项。 我们将预测像素的遮罩-这是“海”或“船”,并评估预测的真实性或虚假性。 即 以下四个选项是可能的-我们正确地预测像素是“海”,正确地预测像素是“船”,或者在预测“海”或“船”时出错。 因此,对于所有图片和所有像素,我们估计所有四个选项的数量并计算结果-这将是网络的结果。 错误的预测越少越准确,结果越准确,网络越好。
为了进行研究,让我们采用经过精心研究的u-net,它是用于图像分割的出色网络。 该网络在此类比赛中非常普遍,并且存在许多描述,应用程序的精妙之处等。 选择了经典U-net的变体,当然,可以对其进行升级,添加剩余块等。 但是“您不能拥抱巨大的事物”并立即进行所有实验和测试。 U-net对图片执行非常简单的操作-它通过逐步进行变换来减小图片的大小,然后尝试从压缩图像中恢复遮罩。 即 在本例中,图片的尺寸被设为32x32,然后我们尝试使用之前所有压缩中的数据来还原蒙版。
在图中,U-net方案来自原始文章,但我们对其进行了一些重编,但本质仍然相同-我们压缩图像→扩展为蒙版。
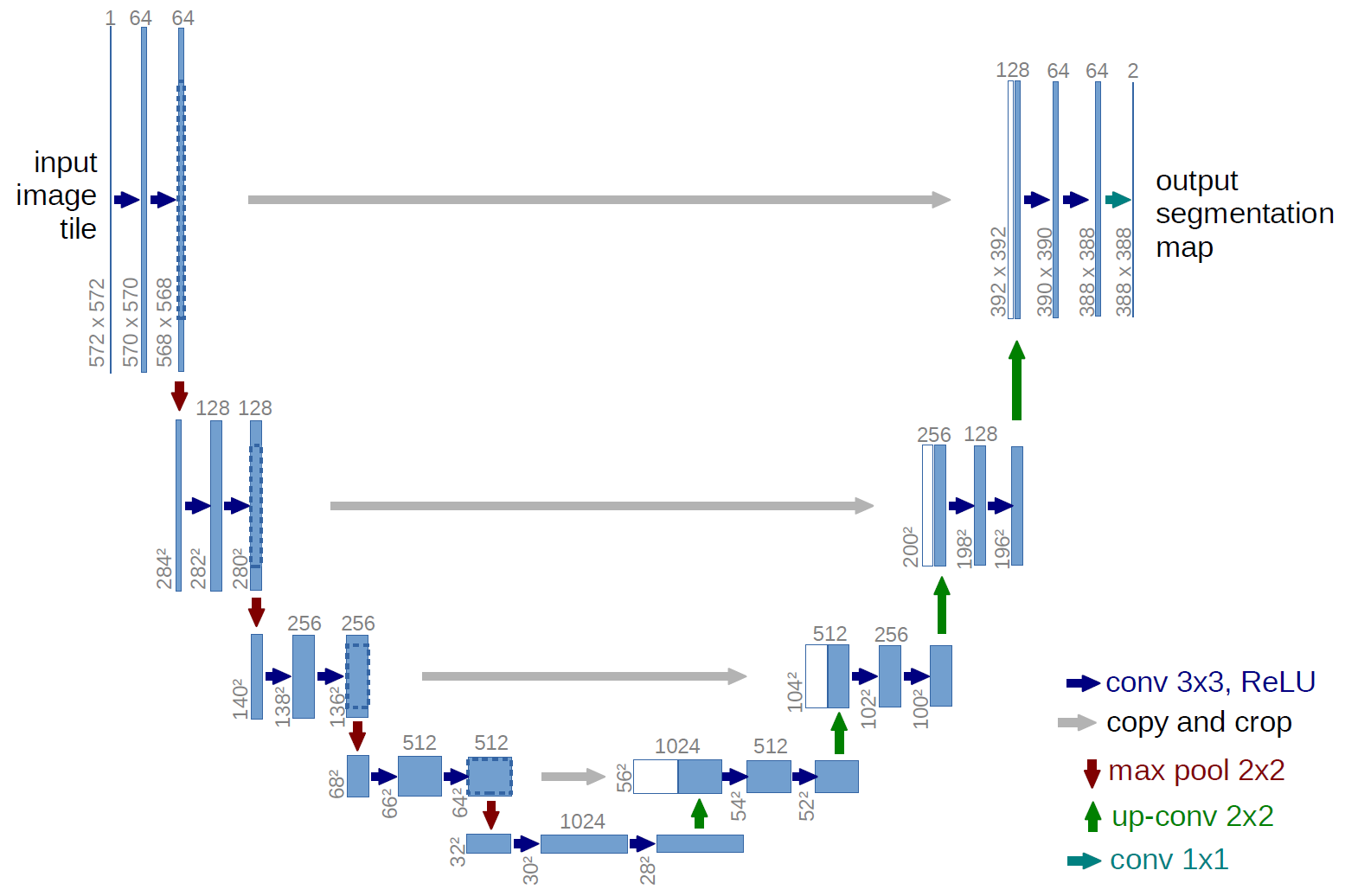
只是U网 def build_model(input_layer, start_neurons): conv1 = Conv2D(start_neurons*1,(3,3),activation="relu", padding="same")(input_layer) conv1 = Conv2D(start_neurons*1,(3,3),activation="relu", padding="same")(conv1) pool1 = MaxPooling2D((2, 2))(conv1) pool1 = Dropout(0.25)(pool1) conv2 = Conv2D(start_neurons*2,(3,3),activation="relu", padding="same")(pool1) conv2 = Conv2D(start_neurons*2,(3,3),activation="relu", padding="same")(conv2) pool2 = MaxPooling2D((2, 2))(conv2) pool2 = Dropout(0.5)(pool2) conv3 = Conv2D(start_neurons*4,(3,3),activation="relu", padding="same")(pool2) conv3 = Conv2D(start_neurons*4,(3,3),activation="relu", padding="same")(conv3) pool3 = MaxPooling2D((2, 2))(conv3) pool3 = Dropout(0.5)(pool3) conv4 = Conv2D(start_neurons*8,(3,3),activation="relu", padding="same")(pool3) conv4 = Conv2D(start_neurons*8,(3,3),activation="relu", padding="same")(conv4) pool4 = MaxPooling2D((2, 2))(conv4) pool4 = Dropout(0.5)(pool4)
第一个实验。 最简单的
为了简化起见,我们选择了第一个实验版本-海洋更浅,船舶更暗。 一切都非常简单明了,我们假设网络将毫无问题地以任何精度找到船只/椭圆。 next_pair函数生成一对图片/遮罩,其中随机选择位置,大小,旋转角度。 此外,将对此功能进行所有更改-更改颜色,形状,干涉等。 但是,现在最简单的选择是,我们在浅色背景上测试暗船的假设。
def next_pair(): p = np.random.sample() - 0.5
我们生成了整个火车,看看发生了什么。 它看起来像海上的小船,仅此而已。 一切都清晰可见,清晰易懂。 该位置是随机的,每张图片中只有一个椭圆。
for k in range(train_num):
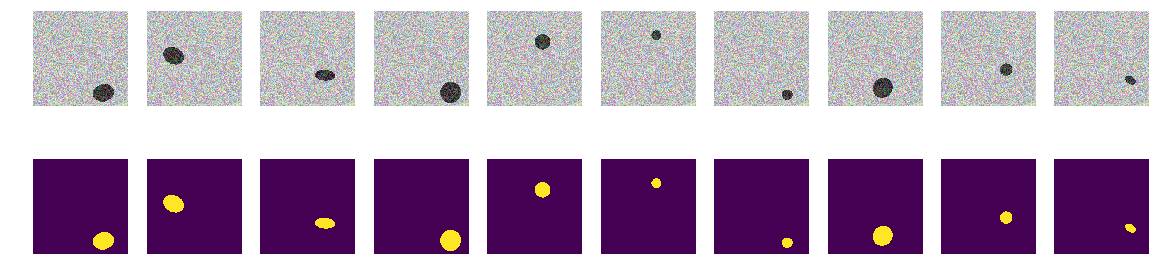
毫无疑问,网络将成功学习并发现椭圆。 但是,让我们检验一下我们的假设,即该网络经过训练可以找到椭圆/船,并且同时具有很高的准确性。
input_layer = Input((w_size, w_size, 3)) output_layer = build_model(input_layer, 16) model = Model(input_layer, output_layer) model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-3), metrics=[my_iou_metric]) model.save_weights('./keras.weights') while True: history = model.fit(train_x, train_y, batch_size=32, epochs=1, verbose=1, validation_split=0.1 ) if history.history['my_iou_metric'][0] > 0.75: break
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 55s 7ms/step - loss: 0.2272 - my_iou_metric: 0.7325 - val_loss: 0.0063 - val_my_iou_metric: 1.0000
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 53s 7ms/step - loss: 0.0090 - my_iou_metric: 1.0000 - val_loss: 0.0045 - val_my_iou_metric: 1.0000
网络成功找到椭圆。 但这并不能完全证明她正在寻找关于人类的椭圆,因为椭圆区域是一个以椭圆方程为边界并填充有与背景不同的内容的区域,因此无法确定网络权重是否类似于二次椭圆方程的系数。 很明显,椭圆的亮度小于背景的亮度,并且没有秘密或谜语-我们假设我们只是检查了代码。 让我们修复明显的面孔,也使椭圆的背景和颜色随机。
第二选择
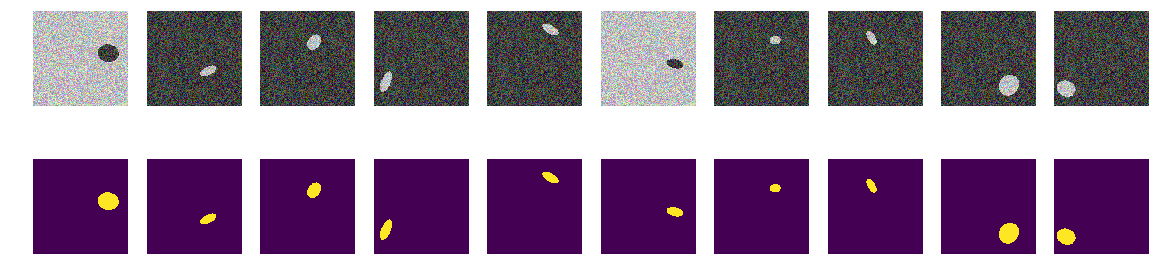
现在,相同的椭圆在同一条海洋上,但是海洋的颜色以及船的颜色是随机选择的。 如果海洋更黑,则船会更亮,反之亦然。 即 根据这组点的亮度,不可能确定它们是否在椭圆之外,即大海还是这些在椭圆内部。 再次,我们检验我们的假设,即网络将发现椭圆而不管颜色如何。
def next_pair(): p = np.random.sample() - 0.5
现在,通过像素及其周围环境,无法确定背景或椭圆形。 我们还生成图片和蒙版,并查看屏幕上的前10个。
建筑面具 for k in range(train_num): img, msk = next_pair() train_x[k] = img train_y[k] = msk fig, axes = plt.subplots(2, 10, figsize=(20, 5)) for k in range(10): axes[0,k].set_axis_off() axes[0,k].imshow(train_x[k]) axes[1,k].set_axis_off() axes[1,k].imshow(train_y[k].squeeze())
input_layer = Input((w_size, w_size, 3)) output_layer = build_model(input_layer, 16) model = Model(input_layer, output_layer) model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-3), metrics=[my_iou_metric]) model.load_weights('./keras.weights', by_name=False) while True: history = model.fit(train_x, train_y, batch_size=32, epochs=1, verbose=1, validation_split=0.1 ) if history.history['my_iou_metric'][0] > 0.75: break
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 56s 8ms/step - loss: 0.4652 - my_iou_metric: 0.5071 - val_loss: 0.0439 - val_my_iou_metric: 0.9005
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 55s 7ms/step - loss: 0.1418 - my_iou_metric: 0.8378 - val_loss: 0.0377 - val_my_iou_metric: 0.9206网络可以轻松应对并找到所有椭圆。 但是这里存在实现上的缺陷,而且一切都很明显-图片中两个区域中较小的一个是椭圆形,另一个背景。 也许这是一个错误的假设,但仍然可以解决,将另一个多边形添加到与椭圆颜色相同的图片上。
第三选择
在每张图片中,我们从两个选项中随机选择海洋的颜色,并添加一个椭圆和一个矩形,两者均与海洋的颜色不同。 原来是相同的“海洋”,也是涂漆的“船”,但是在同一张图片中,我们添加了与“船”相同颜色的矩形,并且具有随机选择的大小。 现在我们的假设更加复杂,在图片中有两个颜色相同的对象,但是我们假设网络仍将学习选择正确的对象。
和以前一样,我们计算图片和蒙版并查看前10对。
建筑面具图片椭圆和矩形 for k in range(train_num): img, msk = next_pair() train_x[k] = img train_y[k] = msk fig, axes = plt.subplots(2, 10, figsize=(20, 5)) for k in range(10): axes[0,k].set_axis_off() axes[0,k].imshow(train_x[k]) axes[1,k].set_axis_off() axes[1,k].imshow(train_y[k].squeeze())

input_layer = Input((w_size, w_size, 3)) output_layer = build_model(input_layer, 16) model = Model(input_layer, output_layer) model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-3), metrics=[my_iou_metric]) model.load_weights('./keras.weights', by_name=False) while True: history = model.fit(train_x, train_y, batch_size=32, epochs=1, verbose=1, validation_split=0.1 ) if history.history['my_iou_metric'][0] > 0.75: break
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 57s 8ms/step - loss: 0.7557 - my_iou_metric: 0.0937 - val_loss: 0.2510 - val_my_iou_metric: 0.4580
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 55s 7ms/step - loss: 0.0719 - my_iou_metric: 0.8507 - val_loss: 0.0183 - val_my_iou_metric: 0.9812不可能混淆网络的矩形,我们的假设得到了证实。 从实例和讨论来看,空客竞赛中的每个人都只有一艘船,几艘船都非常准确地在附近。 矩形的椭圆-即 即使多边形的颜色与椭圆相同,船还是来自岸上的房屋,网络也很明显。 这与颜色无关,因为椭圆和矩形均被随机地绘制。
第四选择
也许网络是用矩形来区分的-正确,使它们变形。 即 不论形状如何,网络都可以轻松找到两个封闭区域,并丢弃矩形区域。 这是作者的假设-我们将对其进行检查,为此我们将不添加矩形,而是添加任意形状的四边形多边形。 同样,我们的假设是网络将椭圆与相同颜色的任意四边形多边形区分开。
您当然可以进入网络的内部,然后查看各层并分析权重和班次的含义。 作者对网络的最终行为感兴趣;判断将基于工作的结果,尽管从内部看总是很有趣的。
更改图像生成 def next_pair(): p = np.random.sample() - 0.5 r = np.random.sample()*(w_size-2*radius_max) + radius_max c = np.random.sample()*(w_size-2*radius_max) + radius_max r_radius = np.random.sample()*(radius_max-radius_min) + radius_min c_radius = np.random.sample()*(radius_max-radius_min) + radius_min rot = np.random.sample()*360 rr, cc = ellipse( r, c, r_radius, c_radius, rotation=np.deg2rad(rot), shape=img_l.shape ) p0 = np.rint(np.random.sample()*(radius_max-radius_min) + radius_min) p1 = np.rint(np.random.sample()*(w_size-radius_max)) p2 = np.rint(np.random.sample()*(w_size-radius_max)) p3 = np.rint(np.random.sample()*2.*radius_min - radius_min) p4 = np.rint(np.random.sample()*2.*radius_min - radius_min) p5 = np.rint(np.random.sample()*2.*radius_min - radius_min) p6 = np.rint(np.random.sample()*2.*radius_min - radius_min) p7 = np.rint(np.random.sample()*2.*radius_min - radius_min) p8 = np.rint(np.random.sample()*2.*radius_min - radius_min) poly = np.array(( (p1, p2), (p1+p3, p2+p4+p0), (p1+p5+p0, p2+p6+p0), (p1+p7+p0, p2+p8), (p1, p2), )) rr_p, cc_p = polygon(poly[:, 0], poly[:, 1], img_l.shape) in_sc = list(set(rr) & set(rr_p)) if len(in_sc) > 0: if np.mean(rr_p) > np.mean(in_sc): poly += np.max(in_sc) - np.min(in_sc) else: poly -= np.max(in_sc) - np.min(in_sc) rr_p, cc_p = polygon(poly[:, 0], poly[:, 1], img_l.shape) if p > 0: img = img_l.copy() img[rr, cc] = img_h[rr, cc] img[rr_p, cc_p] = img_h[rr_p, cc_p] else: img = img_h.copy() img[rr, cc] = img_l[rr, cc] img[rr_p, cc_p] = img_l[rr_p, cc_p] msk = np.zeros((w_size, w_size, 1), dtype='float32') msk[rr, cc] = 1. return img, msk
我们计算图片和蒙版,并查看前10对。
我们建立图片蒙版椭圆和多边形 for k in range(train_num): img, msk = next_pair() train_x[k] = img train_y[k] = msk fig, axes = plt.subplots(2, 10, figsize=(20, 5)) for k in range(10): axes[0,k].set_axis_off() axes[0,k].imshow(train_x[k]) axes[1,k].set_axis_off() axes[1,k].imshow(train_y[k].squeeze())

我们启动我们的网络。 让我提醒您,所有选项都相同。
input_layer = Input((w_size, w_size, 3)) output_layer = build_model(input_layer, 16) model = Model(input_layer, output_layer) model.compile(loss=bce_dice_loss, optimizer=Adam(lr=1e-3), metrics=[my_iou_metric]) model.load_weights('./keras.weights', by_name=False) while True: history = model.fit(train_x, train_y, batch_size=32, epochs=1, verbose=1, validation_split=0.1 ) if history.history['my_iou_metric'][0] > 0.75: break
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 56s 8ms/step - loss: 0.6815 - my_iou_metric: 0.2168 - val_loss: 0.2078 - val_my_iou_metric: 0.4983
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 53s 7ms/step - loss: 0.1470 - my_iou_metric: 0.6396 - val_loss: 0.1046 - val_my_iou_metric: 0.7784
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 53s 7ms/step - loss: 0.0642 - my_iou_metric: 0.8586 - val_loss: 0.0403 - val_my_iou_metric: 0.9354
假设得到证实,多边形和椭圆形很容易区分。 细心的读者会在这里注意到-当然,它们是不同的,这是胡说八道,任何正常的AI都可以区分第二阶曲线与第一阶曲线。 即 网络可以轻松地以二阶曲线的形式确定边界的存在。 我们不会争论,将椭圆形替换为七边形并进行检查。
第五实验,最困难
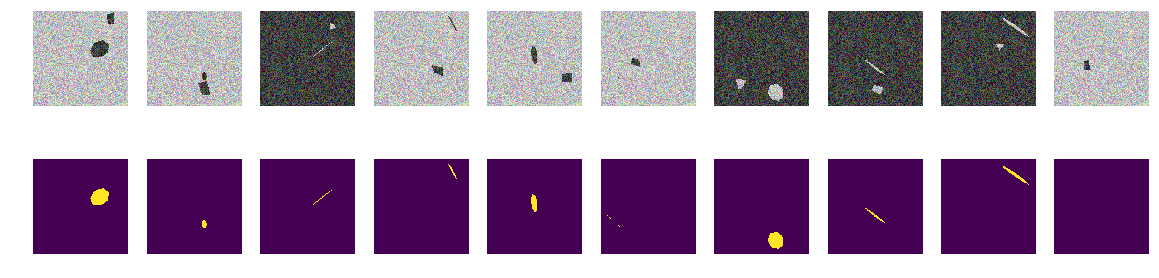
没有曲线,只有规则倾斜和旋转的七边形以及任意四边形多边形的光滑面。 我们将图像/遮罩生成器的更改引入功能中-仅投影正则七边形和相同颜色的任意四边形多边形。
图像生成功能的最终修订版 def next_pair(_n = 7): p = np.random.sample() - 0.5 c_x = np.random.sample()*(w_size-2*radius_max) + radius_max c_y = np.random.sample()*(w_size-2*radius_max) + radius_max radius = np.random.sample()*(radius_max-radius_min) + radius_min d = np.random.sample()*0.5 + 1 a_deg = np.random.sample()*360 a_rad = np.deg2rad(a_deg) poly = []
和以前一样,我们构建数组并查看前10个。
建筑面具 for k in range(train_num): img, msk = next_pair() train_x[k] = img train_y[k] = msk fig, axes = plt.subplots(2, 10, figsize=(20, 5)) for k in range(10): axes[0,k].set_axis_off() axes[0,k].imshow(train_x[k]) axes[1,k].set_axis_off() axes[1,k].imshow(train_y[k].squeeze())
input_layer = Input((w_size, w_size, 3)) output_layer = build_model(input_layer, 16) model = Model(input_layer, output_layer) model.compile(loss=dice_loss, optimizer=Adam(lr=1e-3), metrics=[my_iou_metric]) model.load_weights('./keras.weights', by_name=False) while True: history = model.fit(train_x, train_y, batch_size=32, epochs=1, verbose=1, validation_split=0.1 ) if history.history['my_iou_metric'][0] > 0.75: break
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 54s 7ms/step - loss: 0.5005 - my_iou_metric: 0.1296 - val_loss: 0.1692 - val_my_iou_metric: 0.3722
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 52s 7ms/step - loss: 0.1287 - my_iou_metric: 0.4522 - val_loss: 0.0449 - val_my_iou_metric: 0.6833
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 52s 7ms/step - loss: 0.0759 - my_iou_metric: 0.5985 - val_loss: 0.0397 - val_my_iou_metric: 0.7215
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 52s 7ms/step - loss: 0.0455 - my_iou_metric: 0.6936 - val_loss: 0.0297 - val_my_iou_metric: 0.7304
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 52s 7ms/step - loss: 0.0432 - my_iou_metric: 0.7053 - val_loss: 0.0215 - val_my_iou_metric: 0.7846
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 53s 7ms/step - loss: 0.0327 - my_iou_metric: 0.7417 - val_loss: 0.0171 - val_my_iou_metric: 0.7970
Train on 7372 samples, validate on 820 samples
Epoch 1/1
7372/7372 [==============================] - 52s 7ms/step - loss: 0.0265 - my_iou_metric: 0.7679 - val_loss: 0.0138 - val_my_iou_metric: 0.8280总结
如您所见,网络在测试集上区分出正七边形和任意四边形多边形的投影,精度为0.828。 网络训练被0.75的任意值停止,最有可能的准确性应该要好得多。 如果我们从网络找到原语并且它们的组合确定对象这一论点出发,那么在我们的情况下,有两个区域与背景的平均值不同,在人类的理解中就没有原语了。 没有明显的单色线,也没有角,只有边界非常相似的区域。 即使您构建线,图片中的两个对象都是从相同的基元构建的。
鉴赏家的问题-该网络被视为是“船”与“干扰”区分开的标志? 显然,这不是船只边界的颜色或形状。 当然,我们可以继续研究“海” /“船”的这种抽象构造,我们不是科学院,只能出于好奇而进行研究。 我们可以将七边形更改为八边形,或以规则的五角和六角填充图片,看看它们的网络是否可区分。 我将其留给读者-尽管我也想知道网络是否可以计算多边形的角点数量,并且为了进行测试,在图片中不排列规则的多边形,而是排列它们的随机投影。
这种船还有其他同样有趣的特性,这种实验的用处在于我们自己设置了研究集合的所有概率特征,而经过精心研究的网络的意外行为将增加知识并带来收益。
随机选择背景,随机选择颜色,随机选择船/椭圆位置。 图片中没有线条,存在具有不同特征的区域,但是没有单色线条! 在这种情况下,当然会有简化,并且任务可能会更加复杂-例如,选择0.0 ... 0.9和0.1 ... 1.0之类的颜色-但对于网络而言则没有区别。 网络可以发现与人们清楚看到和发现的模式不同的模式。
如果其中一位读者感兴趣,则可以继续在网络上进行研究和挑选,如果无法解决或不清楚的事物,或者出现了新的好想法并给它留下深刻的印象,那么您可以随时与我们分享或询问大师(也包括大师)并在ODS社区寻求合格的帮助。