Ceph是一种对象存储,旨在帮助构建故障转移群集。 但是,失败的确会发生。 与Ceph合作的每个人都知道有关CloudMouse或Rosreestr的传说。 不幸的是,与我们分享负面经验是不习惯的,失败的原因通常被掩盖,并且不允许子孙后代从别人的错误中学习。
好吧,让我们建立一个测试集群,但要接近真实的集群,并逐一分析灾难。 我们测量所有性能下降,发现内存泄漏,并分析服务恢复过程。 在Artemy Kapitula的领导下,所有这些花费了将近一年的时间研究陷阱,所有这些导致集群性能以零失败,并且延迟没有跳到不合理的值。 我得到了一个红色的图表,效果更好。
接下来,您将找到
DevOpsConf Russia 2018最佳报告之一的视频和文本版本。
关于发言人: Artemy Kapitula系统架构师RCNTEC。 该公司提供IP电话解决方案(协作,远程办公室的组织,软件定义的存储系统和电源管理/分配系统)。 该公司主要在企业部门工作,因此在DevOps市场不是很知名。 尽管如此,Ceph已经积累了一些经验,在许多项目中Ceph被用作存储基础架构的基本要素。
Ceph是一个软件定义的存储库,包含许多软件组件。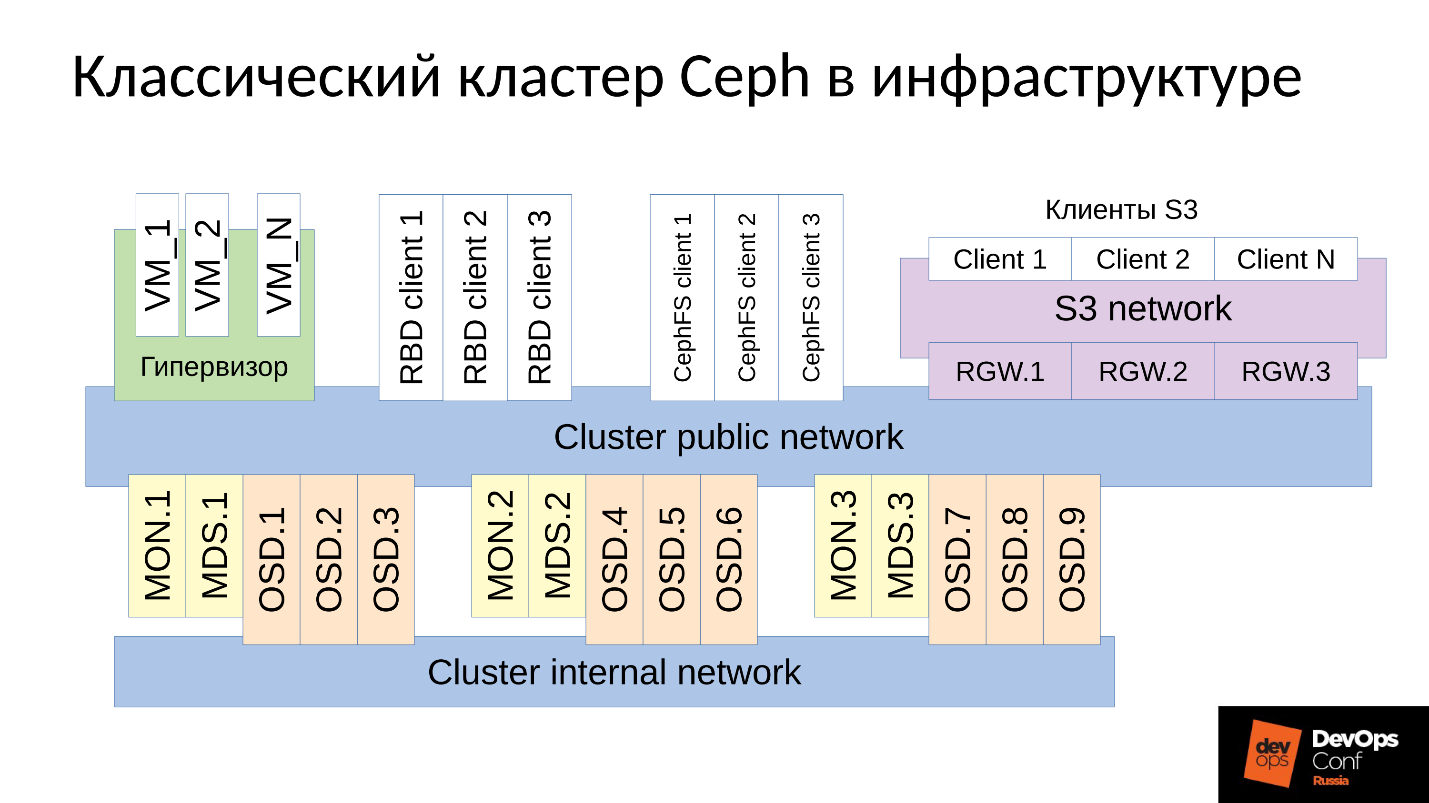
在图中:
- 上层是内部集群网络,集群本身通过该网络进行通信。
- 较低的级别(实际上是Ceph)是一组内部Ceph的守护程序(MON,MDS和OSD),用于存储数据。
通常,所有数据都被复制,在图中,我故意选择了三个组,每个组具有三个OSD,并且这些组中的每个通常包含一个数据副本。 结果,数据被存储在三个副本中。
更高级别的群集网络是Ceph客户端通过其访问数据的网络。 客户端可以通过它与监视器,需要的MDS和OSD通信。 每个客户端分别与每个OSD和每个监视器一起使用。 因此,
系统没有单点故障 ,这是非常令人愉悦的。
客户群
●S3客户
S3是HTTP的API。 S3客户端通过HTTP工作,并连接到Ceph Rados网关(RGW)组件。 他们几乎总是通过专用网络与组件进行通信。 该网络(我称其为S3网络)仅使用HTTP,很少有例外。
●带有虚拟机的管理程序
经常使用这一组客户。 他们与监视器和OSD一起使用,它们从中接收有关群集状态和数据分布的常规信息。 对于数据,这些客户端通过集群公共网络直接进入OSD守护程序。
●RBD客户
也有物理BR金属主机,通常是Linux。 它们是RBD客户端,可以访问存储在Ceph群集中的映像(虚拟机磁盘映像)。
●CephFS客户端
第四组客户端是CephFS群集文件系统客户端,目前尚不多,但人们越来越感兴趣。 可以同时从多个节点安装CephFS集群系统,并且每个节点都可以与每个OSD一起访问同一数据。 也就是说,没有这样的网关(Samba,NFS和其他网关)。 问题在于这样的客户端只能是Linux,并且是相当现代的版本。

我们的公司在公司市场上工作,并且受ESXi,HyperV和其他公司的支配。 因此,需要以某种方式在公司部门中使用的Ceph集群来支持适当的技术。 对于Ceph来说,这还远远不够,因此我们不得不使用我们的组件来完善和扩展Ceph集群,实际上除了构建自己的数据存储平台Ceph之外,还需要构建其他功能。
此外,公司部门的客户不是使用Linux,而是大多数Windows(有时是Mac OS)本身无法使用Ceph集群。 它们必须经过某种网关,在这种情况下成为瓶颈。
我们必须添加所有这些组件,并且集群稍宽一些。

我们有两个主要组件:
SCSI网关组 ,该
组可通过FibreChannel或iSCSI访问Ceph群集中的数据。 这些组件用于将HyperV和ESXi连接到Ceph群集。 PROXMOX客户仍然通过RBD以自己的方式工作。
我们不允许文件客户端直接进入群集网络;为它们分配了几个容错网关。 每个网关都可以通过NFS,AFP或SMB访问文件群集系统。 因此,几乎所有客户端(无论是Linux,FreeBSD还是客户端,服务器(OS X,Windows))都可以访问CephFS。
为了管理所有这些,我们必须实际开发我们自己的Ceph乐团和所有组成部分,那里很多。 但是现在谈论它毫无意义,因为这是我们的发展。 大多数人可能会对“赤裸的” Ceph本身感兴趣。
Ceph在很多地方使用,偶尔会发生故障。 当然,与Ceph合作的每个人都知道有关CloudMouse的传说。 这是一个可怕的城市传奇,但那里的一切看上去并不糟糕。 关于Rosreestr,有一个新的童话。 Ceph无处不在,无处不在。 它在某个地方致命地结束了,在某个地方设法迅速消除了后果。
不幸的是,我们不习惯分享负面经验,每个人都在试图隐藏相关信息。 外国公司要开放一些,特别是DigitalOcean(一个著名的分发虚拟机的提供商)也遭受了Ceph失败将近一天的时间,那是4月1日-美好的一天! 他们发布了一些报告,下面是简短的日志。

问题从早上7点开始,在11点他们知道发生了什么,并开始消除故障。 为此,他们分配了两个命令:一个出于某种原因在服务器周围运行并在其中安装了内存,第二个出于某种原因手动启动了一个服务器,另一个又手动监视了所有服务器。 怎么了 我们都习惯于一键打开所有功能。
当分布式系统有效地构建并且几乎在其功能极限下工作时,在分布式系统中基本上会发生什么?要回答这个问题,我们需要查看Ceph集群如何工作以及如何发生故障。

Ceph失败方案
最初,集群工作正常,一切正常。 然后发生某些事情,在此之后,存储数据的OSD守护程序与集群的中央组件(监视器)失去联系。 此时,将发生超时,整个集群都将受到威胁。 集群停留了一段时间,直到意识到自己出了点问题,然后才纠正其内部知识。 之后,客户服务将在某种程度上恢复,并且群集将再次以降级模式工作。 有趣的是,它的运行速度比普通模式下更快-这是一个了不起的事实。
然后我们消除故障。 假设我们断电了,机架被完全切断了。 电工开始运转,他们全部恢复了生命,他们提供了电源,服务器打开了,然后
乐趣就开始了 。
每个人都习惯这样的事实:服务器故障时,一切都会变坏,而当我们打开服务器电源时,一切都会变好。 这里的一切都是完全错误的。
群集实际上停止了,进行了主同步,然后开始平稳缓慢的恢复,逐渐恢复到正常模式。

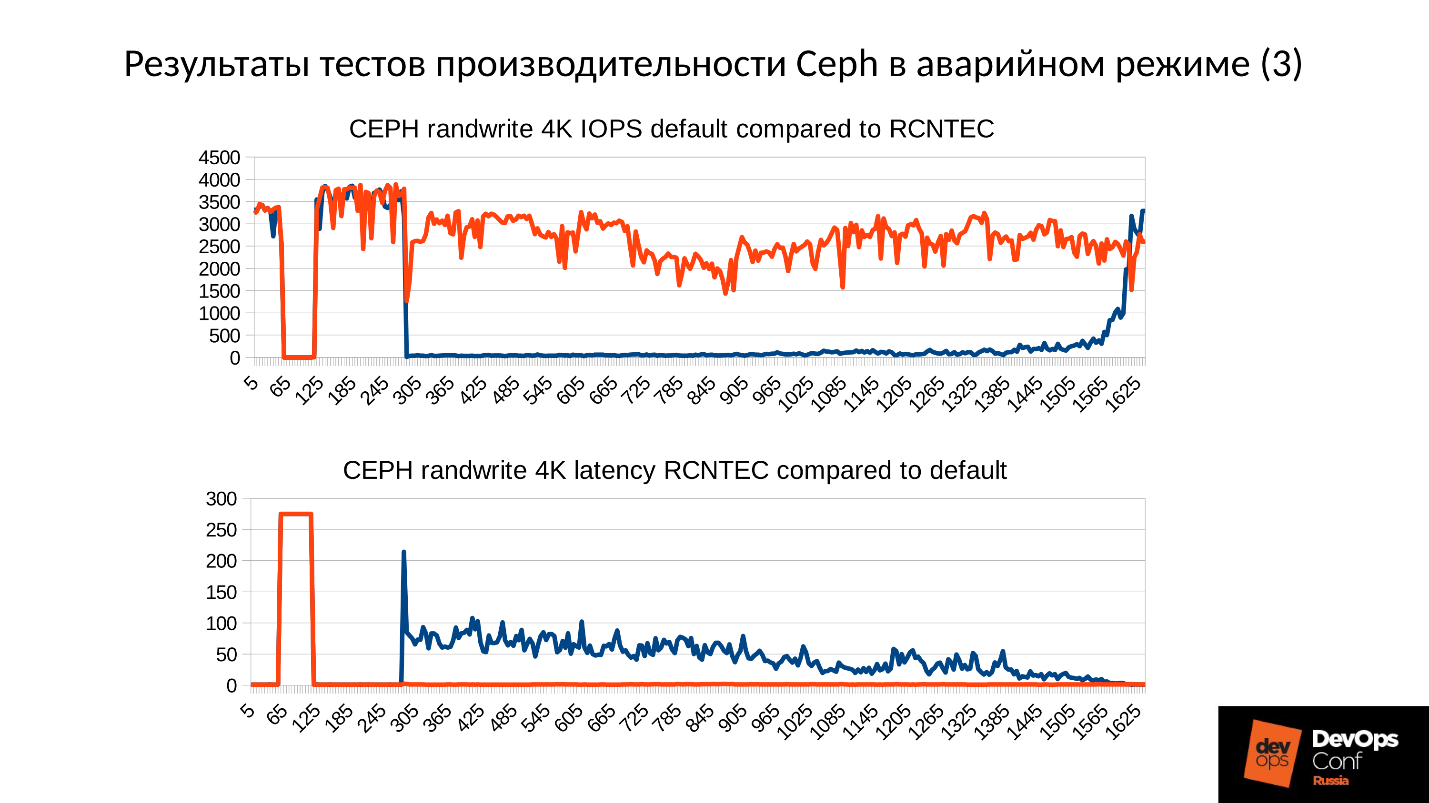
上面是故障发生时Ceph集群性能的图表。 请注意,在此我们非常清楚地跟踪了我们所讨论的间隔:
- 正常运行约70秒;
- 故障一分钟到大约130秒;
- 退化群集的工作是一个明显高于正常运行的平稳期。
- 然后,我们打开缺少的节点-这是一个训练集群,只有3台服务器和15个SSD。 我们在260秒左右的某个时间启动服务器。
- 服务器打开,进入群集-IOPS'y下降了。
让我们尝试弄清楚那里到底发生了什么。 令我们感兴趣的第一件事是在图表的开始部分就进行了下探。
OSD故障
考虑一个具有三个机架的集群示例,每个机架有多个节点。 如果左侧机架发生故障,则所有OSD守护程序(不是主机!)都将在一定间隔内通过Ceph消息对自己进行ping通。 如果丢失了几条消息,则会向监视器发送一条消息:“ I,某某OSD,无法到达某某OSD”。

在这种情况下,消息通常按主机分组,即,如果来自不同OSD的两条消息到达同一主机,则它们将合并为一条消息。 因此,如果OSD 11和OSD 12报告无法到达OSD 1,则将其解释为主机11抱怨OSD1。报告OSD 21和OSD 22时,将其解释为主机21对OSD 1不满意。之后,监视器认为OSD 1处于关闭状态并通知集群的所有成员(通过更改OSD映射),工作将以降级模式继续进行。
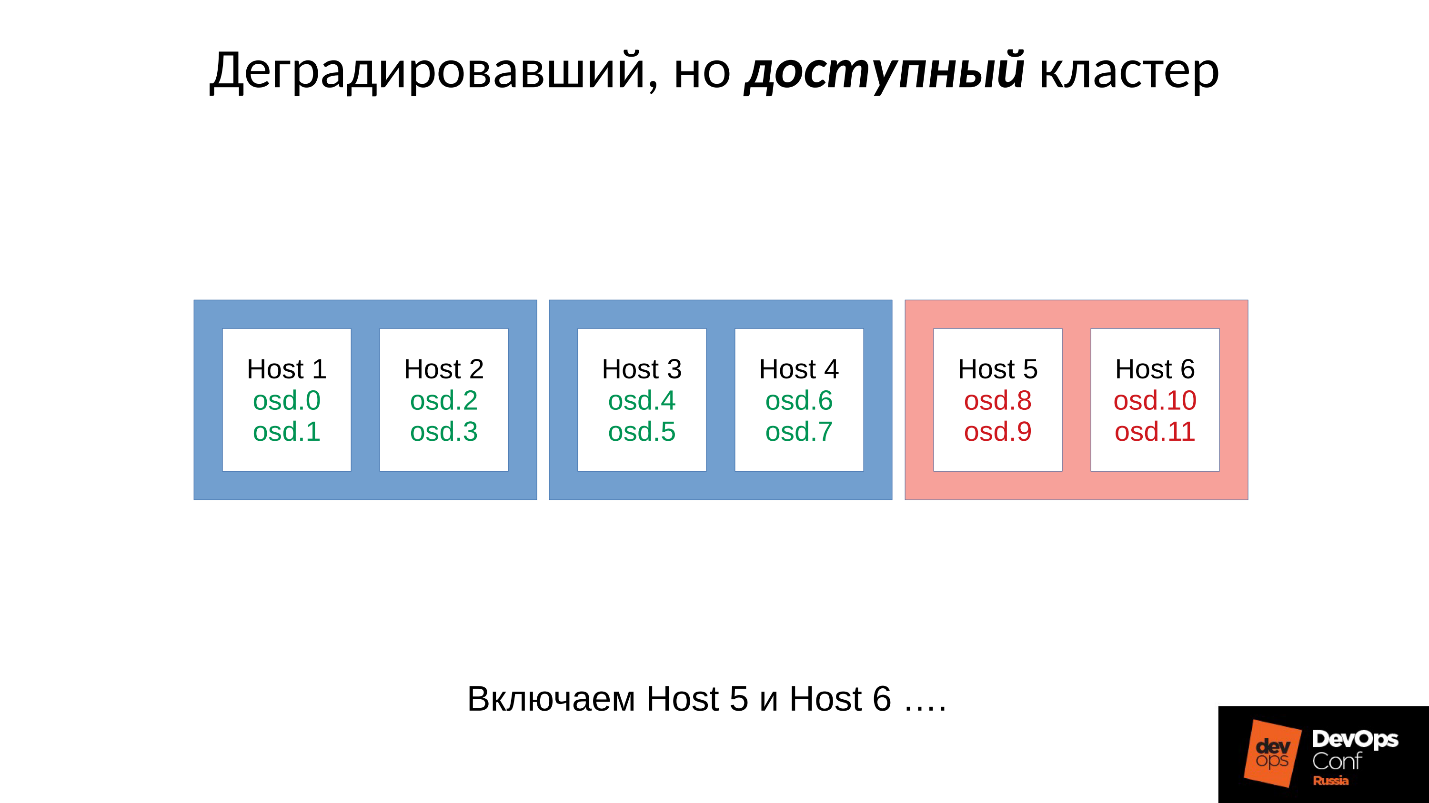
因此,这是我们的群集和故障机架(主机5和主机6)。 随着电源的出现,我们打开主机5和主机6,然后...
Ceph的内部行为
现在最有趣的部分是我们开始
初始数据同步 。 由于存在许多副本,因此它们必须是同步的并且具有相同的版本。 在启动OSD的过程中,请启动:
- OSD读取可用的版本,可用的历史记录(pg_log-确定对象的当前版本)。
- 之后,它确定降级对象的最新版本(missing_loc)在哪个OSD上以及后面的哪个版本。
- 在存储向后版本的地方,必须进行同步,并且可以将新版本用作读取和写入数据的参考。
使用从所有OSD收集的故事,这个故事可能很多。 确定集群中对应版本所在的对象集的实际位置。 群集中有多少个对象,获得了多少记录,如果群集长时间处于降级模式,则故事很长。
为了进行比较:使用RBD图像时,对象
的典型大小为4 MB。 当我们进行擦除编码时-1MB。 如果我们有一个10 TB的磁盘,则在磁盘上将获得一百万兆字节的对象。 如果服务器中有10个磁盘,则已经有1000万个对象,如果有32个磁盘(我们正在构建一个有效的集群,我们有一个紧密的分配),则必须在内存中保留3200万个对象。 此外,实际上,有关每个对象的信息存储在多个副本中,因为每个副本都表明它在此版本中以及在此版本中。
结果发现大量数据位于RAM中:
- 对象越多,missing_loc的历史记录就越大;
- PG越多-pg_log和OSD映射越多;
另外:
- 磁盘大小越大;
- 密度(每个服务器中的磁盘数量)越高;
- 集群上的负载越高,集群越快;
- OSD关闭的时间越长(处于“脱机”状态);
换句话说,
我们构建的集群越陡峭,并且集群部分没有响应的时间越长,启动时就需要更多的RAM 。
极端的优化是万恶之源
“ ...黑色的OOM在晚上降临到坏男孩和女孩身上,杀死了所有左右过程”
城市系统管理员传奇
因此,RAM需要大量资源,内存消耗正在增长(我们立即在群集的三分之一中启动),并且如果您创建了该系统,理论上该系统可以进入SWAP。 我认为很多人认为SWAP不好,他们没有创造出来:“为什么? 我们有很多记忆!” 但这是错误的方法。
如果尚未预先创建SWAP文件,因为已经确定Linux将更有效地工作,那么它迟早会在内存杀手(OOM-killer)之外发生,而不是杀死所有占用内存的人,而不是事实。第一个不幸的人。 我们知道一个乐观的位置-我们要求记忆,他们向我们承诺,我们说:“现在给我们一个”,以回应:“但不!” -和内存不足的杀手.。
除非在虚拟内存区域中配置,否则这是常规的Linux作业。
该过程脱离了内存杀手,并迅速而残酷地退出。 而且,他死去的其他过程都不是不知道的。 他没有时间通知任何人,他们只是终止了他。
然后,该过程当然会重新启动-我们已经进行了systemd,如果需要的话,它还会启动已经崩溃的OSD。 掉落的OSD开始,并且...连锁反应开始。
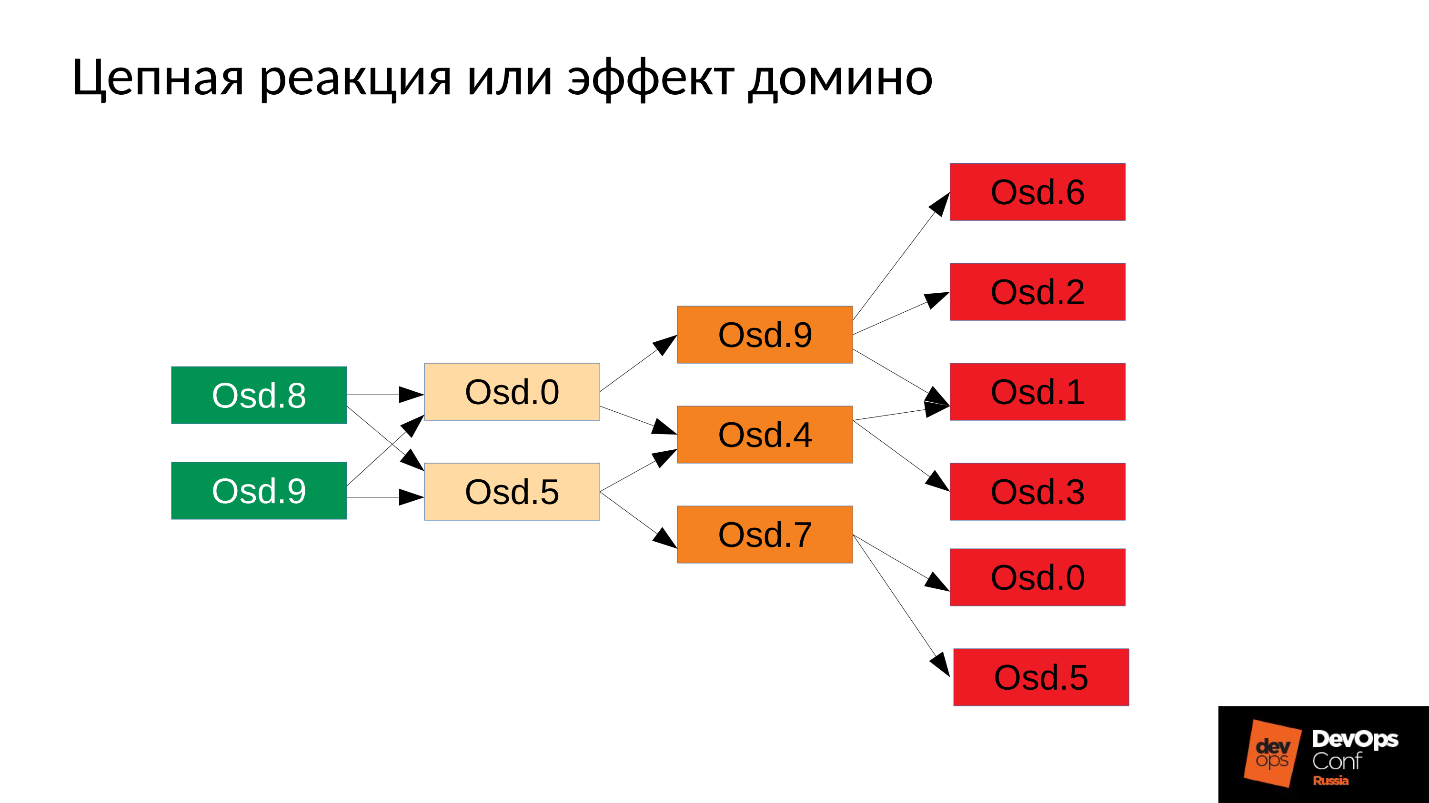
在我们的案例中,我们启动了OSD 8和OSD 9,它们开始粉碎所有内容,但是运气不佳的OSD 0和OSD 5没有运气。 他们重新启动-他们读取数据,开始同步并粉碎其余数据。 另外三个倒霉(OSD 9,OSD 4和OSD 7)。 这三个重新启动,开始对整个集群施加压力,下一个包很不幸。
星团开始在我们眼前消失 。 退化发生得非常快,这种“非常快”的表达通常以分钟为单位,最长为数十分钟。 如果您有30个节点(每个机架10个节点),并且由于电源故障而切断了机架-6分钟后,群集的一半将处于闲置状态。
因此,我们得到如下内容。
在几乎每台服务器上,我们的OSD均发生故障。 而且,如果在每台服务器上,即在发生故障的OSD的每个故障域中,那么
我们的大多数数据都是不可访问的 。 任何请求都被阻止-写入,读取-没什么区别。 仅此而已! 我们起床了。
在这种情况下该怎么办? 更确切地说,
必须做什么?
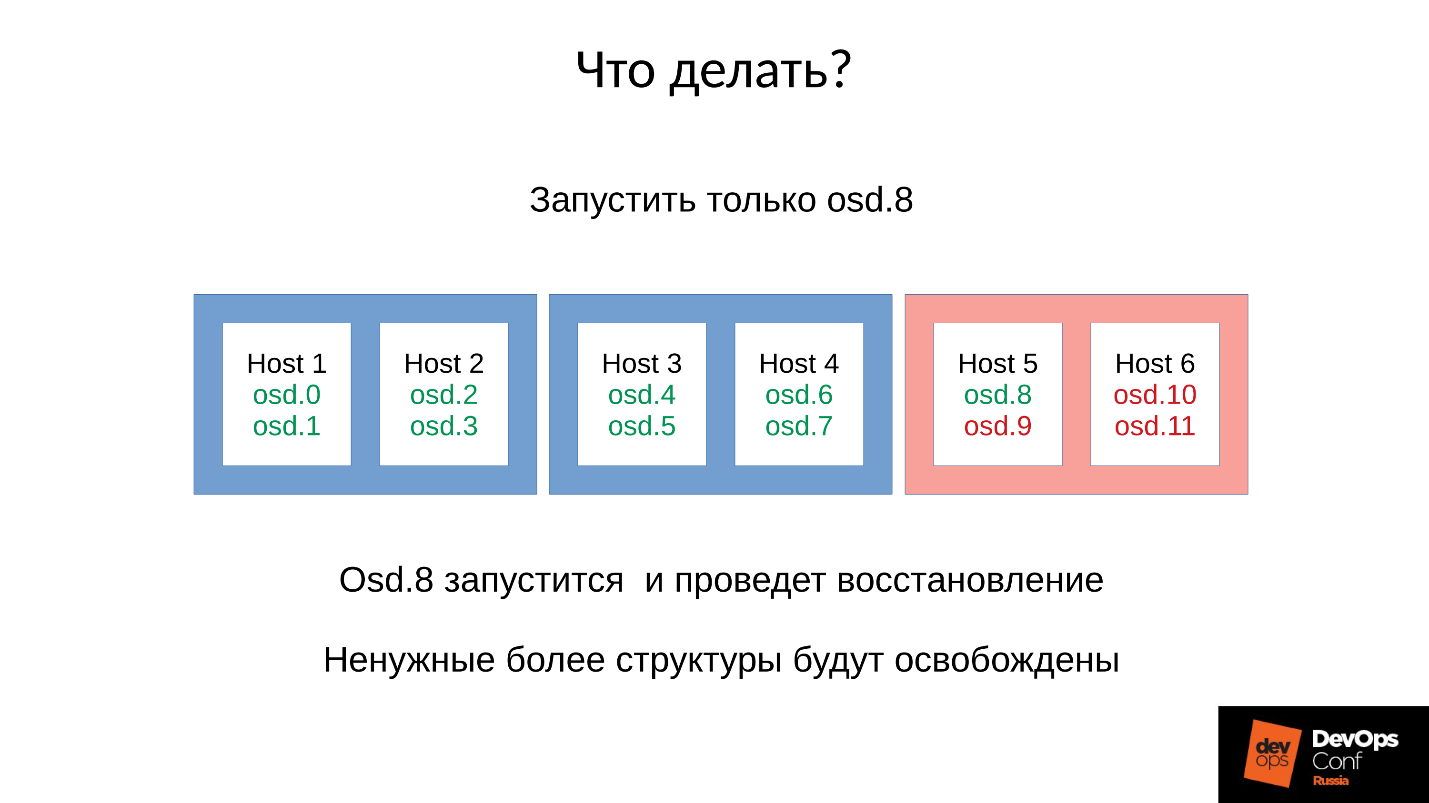
答:不要立即启动集群,即整个机架,但要小心地每个举起一个恶魔。
但是我们不知道。 我们马上开始,得到了我们得到的。 在这种情况下,我们启动了四个守护进程之一(8、9、10、11),内存消耗将增加约20%。 通常,我们是这样飞跃的。 然后,内存消耗开始减少,这是因为用于保存有关群集如何退化的信息的某些结构将离开。 也就是说,部分放置组已恢复到其正常状态,并且维护了降级状态所需的所有内容都已释放-
从理论上讲,它已被释放 。
让我们来看一个例子。 左右的C代码几乎相同,不同之处仅在于常量。

这两个示例要求系统提供不同的内存量:
- 左-2048个,每个1 MB;
- 右-2097152个1 KB的块。
然后,这两个示例都等待着我们将它们放在最上面。 然后按Enter键,他们释放了内存-除了最后一块以外的所有东西。 这非常重要-最后一块仍然存在。 他们又在等我们照相。
以下是实际发生的情况。

- 首先,两个进程都启动并占用了内存。 听起来像是事实-2 GB RSS。
- 按ENTER键并感到惊讶。 第一个大块突出的程序返回了内存。 但是第二个程序没有返回。
导致这种情况发生的答案在于Linux malloc。
如果我们请求大块内存,则使用匿名mmap机制发出该内存,该机制被提供给处理器的地址空间,然后从那里将内存切割给我们。 当我们执行free()时,将释放内存,并将页面返回到页面缓存(系统)。
如果我们将内存分配成小块,则执行sbrk()。 sbrk()将指针移到堆的尾部;理论上,如果不使用内存,则可以通过将内存页面返回给系统来将移回的尾部返回。
现在看一下插图。 我们在降级对象位置的历史记录中有很多记录,然后出现了用户会话-一个长期存在的对象。 我们进行了同步,所有额外的结构都消失了,但是寿命长的对象仍然存在,并且我们无法将sbrk()移回。

如果有了SWAP,我们仍有大量未使用的空间可以释放。 但是我们很聪明-我们禁用了SWAP。
当然,那么将使用堆开始处的部分内存,但这只是一部分,非常重要的剩余部分将被占用。
在这种情况下该怎么办? 答案如下。
受控发射
- 我们启动一个OSD守护程序。
- 我们等待同步,我们检查内存预算。
- 如果我们知道我们将在下一个恶魔的开始中生存下来,那么我们将开始下一个恶魔。
- 如果不是,请快速重新启动占用最多内存的守护程序。 他能够在很短的时间内停机,他没有太多的历史记录,缺少位置信息和其他东西,因此他将减少内存消耗,内存预算将略有增加。
- 我们围绕集群运行,对其进行控制,然后逐步提高一切。
- 我们检查是否可以继续执行下一个OSD,然后转到该菜单。
DigitalOcean实际上做到了这一点:
“我们的数据中心团队执行内存扩充,而另一个团队则继续缓慢地启动节点,同时手动管理每个主机的内存预算。”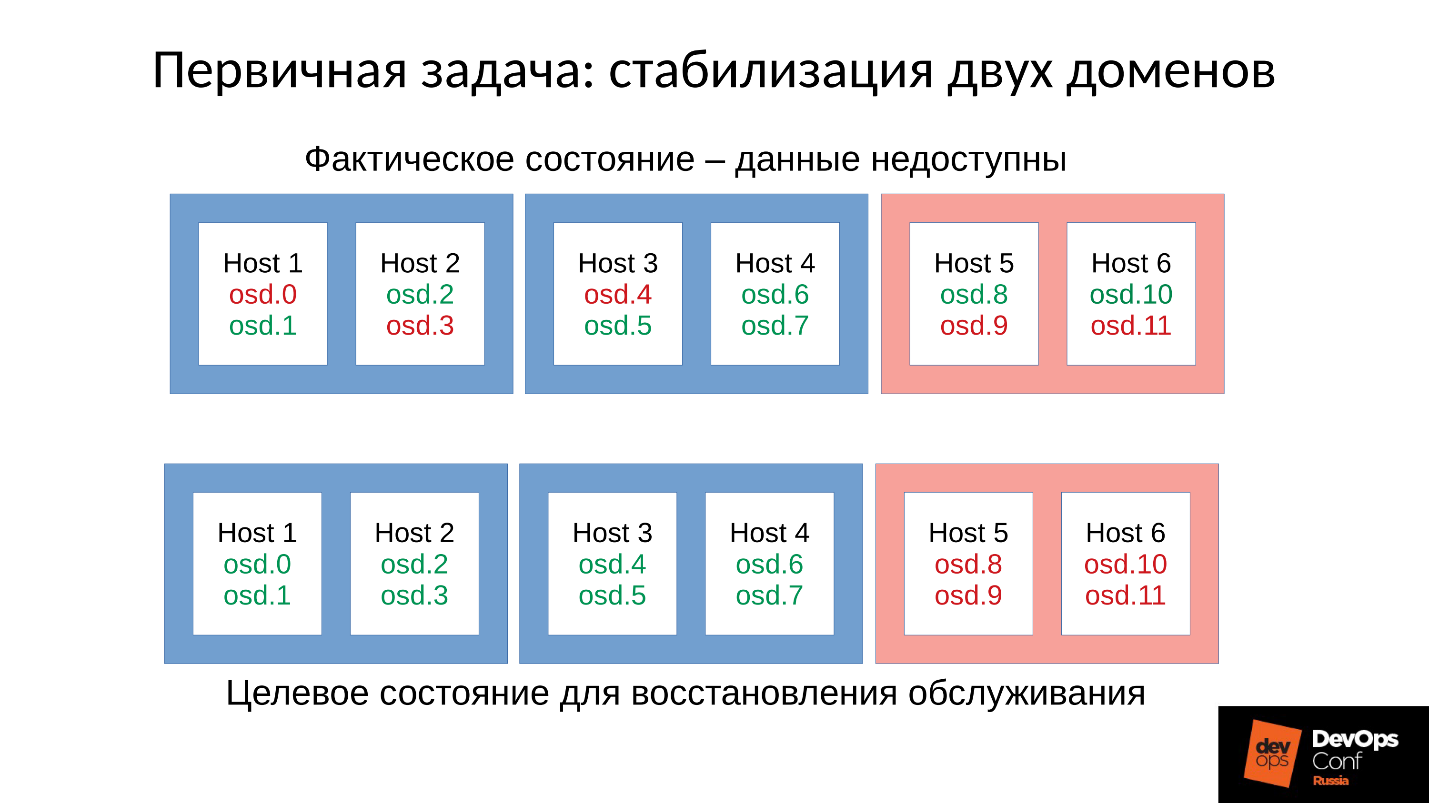
让我们回到我们的配置和当前情况。 现在,由于内存不足杀手的连锁反应,我们有了一个崩溃的集群。 我们禁止在红色域中自动重启OSD,并且我们一一从蓝色域中启动节点。 因为
我们的首要任务始终是恢复服务 ,而不了解为什么会这样。 稍后我们将在恢复服务时了解。 在操作中,总是这样。
我们将群集置于目标状态以恢复服务,然后根据我们的方法开始一个接一个地运行OSD。 我们查看第一个,如果有必要,请重新启动其他的以调整内存预算,下一个-9、10、11-群集似乎已同步并准备开始维护。
问题是如何
在Ceph中执行
写维护 。
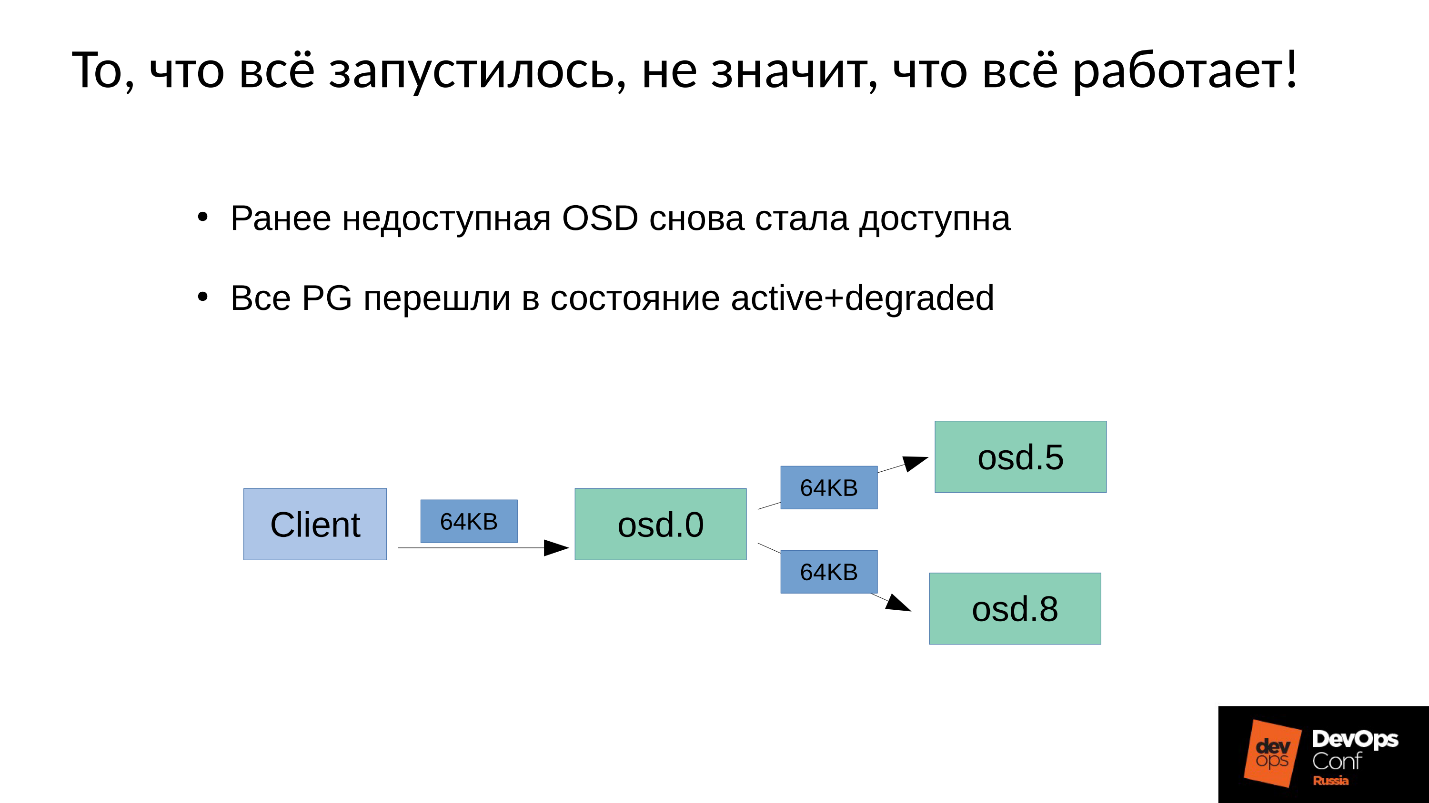
我们有3个副本:一个主OSD和两个从OSD。 我们将说明每个展示位置组中的主/从设备都有自己的主/从设备,但是每个都有一个主设备和两个从设备。
写入或读取操作属于主机。 阅读时,如果master具有正确的版本,则他会将其提供给客户端。 录制有点复杂,必须在所有副本上重复录制。 因此,当客户端在OSD 0中写入64 KB时,在我们的示例中,相同的64 KB进入OSD 5和OSD 8。
但事实是,由于我们重新启动了许多进程,因此OSD 8的性能大大下降。

由于在Ceph中,任何更改都是从一个版本到另一个版本的过渡,因此在OSD 0和OSD 5上,我们将在OSD 8上有一个新版本-旧版本。 , , ( 64 ) OSD 8 — 4 ( ). 4 OSD 0, OSD 8, , . , 64 .
— .

:
- 4 1 , 1000 / 1 .
- 4 ( ) 22 , 45 /.
, , , , .
— .

4 22 , 22 , 1 4 . 45 SSD, 1 —
45 .
, .
- , — (45+1) / 2 = 23 .
- 75% , (45 * 3 + 1) / 4 = 34 .
- 90% —(45 * 9 + 1) / 10 = 41 — 40 , .
Ceph, . , , , .
Ceph .

- — : , , , , .
- — latency. latency , . 100% ( , ). Latency 60 , .

, . 10 , 1 200 /, 300 , , . 10 SSD — 300 , — , - 300 .
, .
, . 900 / ( SSD). 2 500 128 ( , ESXi HyperV 128 ). degraded, 225 . file store, object store, ( ), 110 , - .
SSD 110 — !
?1: —
.

: ; PG;
.
:
- , 45 — .
- ( . ), 14 .
- , 8 ( 10% PG).
, , , , , .
2: —
(order, objectsize) .
, , , 4 2 1 . , , . :
:
(32 ) — !
3: —
Ceph .
, -,
Ceph . , , . .
, — Latency. — , — . Latency 30% , , .
Community , preproduction . , . , .
- , . , Ceph - , , .
●
- .
, . ,
. . , , production. , , , DigitalOcean , . , , , .
, , . , : « ! ?!» , , . , : , , down time.
●
(OSD)., , — , , - , .
OSD — — . , .
●
.OSD .
, . , , , .
●
RAM OSD.●
SWAP.SWAP Ceph' , Linux' . .
●
.100%, 10%. , , , .
●
RBD Rados Getway., .
SWAP — . , SWAP — , , , , .
— DevOpsConf Russia. . , youtube , DevOps-.