有多种方法可以处理编程语言中的错误:
- 许多语言(Java,Scala和其他JVM,Python和许多其他语言)的标准异常
- 状态码或标志(Go,bash)
- 各种代数数据结构,其值既可以是成功的结果,也可以是错误描述(Scala,haskell和其他功能语言)
异常的使用非常广泛,另一方面,异常通常被称为缓慢的。 但是,功能性方法的反对者通常会对性能产生吸引力。
最近,我一直在与Scala一起工作,在这里我可以同时使用异常和各种数据类型进行错误处理,因此我想知道哪种方法会更方便,更快捷。
我们将立即放弃使用代码和标志,因为JVM语言不接受这种方法,而且我认为这种方法太容易出错(对双关语很抱歉)。 因此,我们将比较异常和不同类型的ADT。 此外,ADT可被视为功能性样式中错误代码的使用。
更新 :没有堆栈跟踪的异常被添加到比较中
参赛者
有关代数数据类型的更多信息对于不太熟悉ADT( ADT )的人-代数类型由几个可能的值组成,每个值都可以是复合值(结构,记录)。
一个示例是类型Option[T] = Some(value: T) | None Option[T] = Some(value: T) | None ,它代替空值:使用此类型的值可以是Some(t)如果有值Some(t) ,也可以是None (无)。
另一个示例为“ Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) ,它描述可以成功完成或出现错误的计算结果。
所以我们的参赛者:
- 好老的例外
- 没有堆栈跟踪的异常,因为填充堆栈跟踪是非常缓慢的操作
Try[T] = Success(value: T) | Failure(exception: Throwable) Try[T] = Success(value: T) | Failure(exception: Throwable) -相同的异常,但在功能包装中Either[String, T] = Left(error: String) | Right(value: T) Either[String, T] = Left(error: String) | Right(value: T) -包含结果或错误说明的类型ValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) ValidatedNec[String, T] = Valid(value: T) | Invalid(errors: List[String]) - Cats库中的一种类型,如果发生错误,它可能包含有关不同错误的多条消息(此处并没有使用List ,但这没关系)
注意本质上,将异常与堆栈跟踪(不带和ADT)进行比较,但选择了几种类型,因为Scala没有单一的方法,比较几种有趣。
除异常外,字符串还用于描述错误,但在实际情况下成功使用相同的字符串时,将使用不同的类( Either[Failure, T] )。
问题
为了测试错误处理,我们考虑了解析和数据验证的问题:
case class Person(name: String, age: Int, isMale: Boolean) type Result[T] = Either[String, T] trait PersonParser { def parse(data: Map[String, String]): Result[Person] }
即 具有原始数据Map[String, String]您需要获取Person或一个错误(如果数据无效)。
投掷
使用异常解决额头的方法(以下我将仅提供person函数,您可以在github上查看完整的代码):
Throwparser.scala
def person(data: Map[String, String]): Person = { val name = string(data.getOrElse("name", null)) val age = integer(data.getOrElse("age", null)) val isMale = boolean(data.getOrElse("isMale", null)) require(name.nonEmpty, "name should not be empty") require(age > 0, "age should be positive") Person(name, age, isMale) }
在这里, string , integer和boolean验证简单类型的存在和格式并执行转换。
总的来说,它非常简单明了。
ThrowNST(无堆栈跟踪)
代码与前面的情况相同,但是在可能的情况下使用了没有堆栈跟踪的异常: ThrowNSTParser.scala
试一下
该解决方案可以更早地捕获异常,并允许通过for合并结果(不要与其他语言的循环混淆):
TryParser.scala
def person(data: Map[String, String]): Try[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
对于脆弱的眼睛来说有点不寻常,但是由于使用了for ,它与版本非常相似,但有例外,另外,对字段是否存在的验证和所需类型的解析是分别进行的( flatMap可以在此处and then阅读)
要么
由于错误类型是固定的,因此, Either类型都隐藏在Result别名后面:
解析器
def person(data: Map[String, String]): Result[Person] = for { name <- required(data.get("name")) age <- required(data.get("age")) flatMap integer isMale <- required(data.get("isMale")) flatMap boolean _ <- require(name.nonEmpty, "name should not be empty") _ <- require(age > 0, "age should be positive") } yield Person(name, age, isMale)
由于标准的Either如Try在Scala中形成了monad,因此代码完全相同,因此此处的区别在于,字符串在此处显示为错误,并且最少使用了异常(仅用于解析数字时处理错误)
已验证
在这里,使用Cats库的目的是为了尽可能多地获取未发生的第一件事(例如,如果几个字段无效,则结果将包含所有这些字段的解析错误)
ValidatedParser.scala
def person(data: Map[String, String]): Validated[Person] = { val name: Validated[String] = required(data.get("name")) .ensure(one("name should not be empty"))(_.nonEmpty) val age: Validated[Int] = required(data.get("age")) .andThen(integer) .ensure(one("age should be positive"))(_ > 0) val isMale: Validated[Boolean] = required(data.get("isMale")) .andThen(boolean) (name, age, isMale).mapN(Person) }
这段代码已经与原始版本稍有相似,但是有例外,但是对附加限制的验证并未脱离解析字段,我们仍然会遇到一些错误而不是一个错误,这是值得的!
测试中
为了进行测试,生成了具有不同百分比错误的数据集,并以每种方式对其进行了解析。
所有错误百分比的结果:

更详细地讲,错误率低(由于使用了更大的样本,因此时间有所不同):
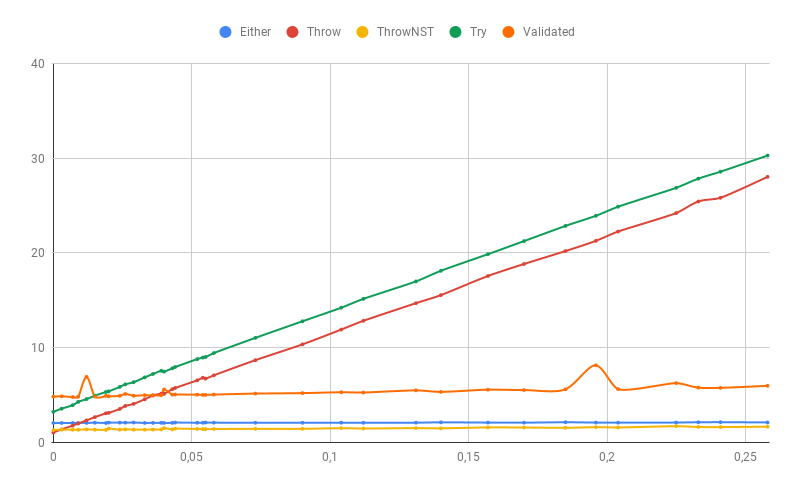
如果错误的某些部分仍然是堆栈跟踪的异常(在我们的情况下,解析数字的错误将是我们无法控制的异常),那么“快速”错误处理方法的性能当然会大大降低。 Validated尤其受到影响,因为它收集了所有错误,因此比其他错误接收到的异常缓慢:

结论
如实验所示,具有堆栈跟踪的异常确实非常慢(100%的错误是Throw和Either之间的差异超过50倍!),并且在几乎没有异常的情况下,使用ADT付出了代价。 但是,使用没有堆栈跟踪的异常的速度与ADT一样快(并且错误率较低),但是,如果此类异常超出了相同的验证范围,则跟踪其来源将不容易。
总体而言,如果发生异常的可能性大于1%,则没有堆栈跟踪的异常的工作速度最快, Validated或常规的Either几乎一样快。 出现大量错误时,仅由于快速失败的语义, Either都可能比Validated更快。
使用ADT进行错误处理比异常提供了另一个优点:错误的可能性被连接到类型本身中,并且更容易错过,例如使用Option而不是null时。