储罐采样(英文简称“水库采样”)是一种简单有效的算法,可以预先从现有的大尺寸和/或未知尺寸的矢量中随机采样一定数量的元素。 我在Habré上未找到有关此算法的任何文章,因此决定自己编写。
所以,我们在说什么。 从向量中选择一个随机元素是一项基本任务:
“从大小为N的向量返回K个随机元素”的任务已经很棘手。 在这里,您可能已经犯了一个错误-例如,采用K个第一个元素(这违反了随机性的要求)或采用概率K / N采取每个元素(这违反了精确采用K个元素的要求)。 另外,可以实施形式上正确但极其无效的解决方案“将所有元素随机混合并先取K”。 如果我们添加以下条件:N是一个非常大的数字(我们没有足够的内存来保存所有N个元素),并且/或者事先未知,那么一切都会变得更加有趣。 例如,假设我们有某种外部服务可以一次向我们发送元素。 我们不知道其中有多少个元素,也无法全部保存,但是我们希望从任何时候收到的元素中随机选择K个元素。
储层采样算法使我们能够在O(N)步和O(K)内存中解决此问题。 在这种情况下,不需要预先知道N,并且将清楚地观察到精确地对K个元素进行随机采样的条件。
让我们从一个简化的任务开始。
令K = 1,即 我们只需要从所有传入元素中选择一个元素-但是每个传入元素都具有相同的被选择概率。 该算法建议自己:
步骤1 :将内存分配到一个元素。 我们将第一个到达的元素保存在其中。

到目前为止,一切都很好-只有一个元素出现了,现在应该选择100%的可能性-可以。
步骤2 :将第二个输入元素以1/2的概率重写为所选元素。

在这里,一切都很好:到目前为止,我们只有两个要素。 第一个仍以1/2的概率被选中,第二个以1/2的概率被重写。
步骤3 :将第三个概率为1/3的传入元素重写为所选元素。
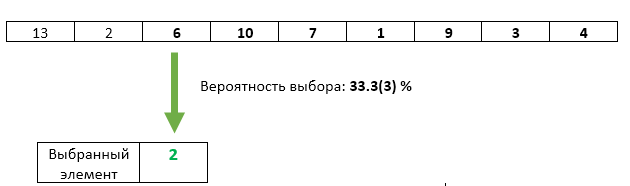
第三个元素一切都很好-选择它的机会恰好是1/3。 但是,我们是否以任何方式违反了先前因素的平等机会? 不行 在此步骤中所选项目不会被覆盖的概率为1-1/3 = 2/3。 并且由于在第2步中我们保证要选择的每个元素的机会均等,因此在第3步之后可以选择每个元素的机会为2/3 * 1/2 = 1/3。 与第三个元素完全一样的机会。
步骤N :以1 / N的概率,将元素编号N重写为所选择的元素编号。 之前到达的每个物品都有相同的1 / N机会被选中。
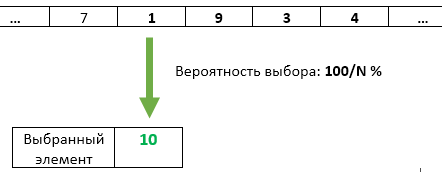
但这是一个简化的任务,K = 1。
对于K> 1,算法将如何变化?
步骤1 :我们在K个元素上分配内存。 我们在其中写下第一个K元素到达。

从K个到达的元素中提取K个元素的唯一方法是将它们全部都带走:)
步骤N :(对于每个N> K):生成一个从1到N的随机数X。如果X> K,则我们丢弃该元素并继续进行下一个操作。 如果X <= K,则用数字X重写元素。由于X的值将在1到N的范围内均匀随机,因此在X <= K的条件下,X的值将在1到K的范围内均匀随机。因此,我们确保了均匀性选择可擦写项目。

如您所见,每个下一个出现的元素被选择的机会越来越少。 尽管如此,它始终将精确地为K / N(对于之前到达的每个元素)。
该算法的优点是我们可以随时停止,向用户显示当前向量K-它将是从到达的元素序列中诚实选择的随机元素的向量。 也许这将适合用户,或者他可能希望继续处理输入值-我们可以随时执行此操作。 如开头所述,在这种情况下,我们使用的内存永远不会超过O(K)。
哦,是的,我完全忘记了,
std :: sample函数完全完成了上面描述的工作,最终包含在标准C ++ 17库中。 该标准不要求它仅使用储层采样,而是要按O(N)个步骤工作-很好,标准库中其实现的开发人员不太可能会选择使用比O(K)内存更多的算法(而且失败的也更少) -结果需要存储在某处)。
相关资料