我们的广告网站不起眼但重要的功能
之一就是保存并显示其观看次数。 我们的网站一直在观看广告浏览量超过10年。 在此期间,该功能的技术实现设法多次更改,现在它已成为Go上的(微)服务,使用Redis作为缓存和任务队列,并使用MongoDB作为持久性存储。 几年前,他不仅学会了如何处理广告观看次数的总和,还学会了每天的统计数据。 但是他最近才学会了迅速而可靠地完成所有这些工作。

总共,该服务每分钟处理约30万个读取请求和约9000个写入请求,其中99%的执行时间长达5毫秒。 当然,这些并不是天文指标,也不是火星上的火箭发射-但这也不是琐碎的任务,因为看起来似乎简单地存储数字。 事实证明,完成所有这些操作(确保无损数据存储并读取一致的相关值)需要付出一些努力,我们将在下面进行讨论。
项目任务和概述
尽管视图计数器对业务的重要性不如处理付款或
贷款请求那样重要,但它们首先对我们的用户很重要。 人们着迷于跟踪广告的受欢迎程度:有些人甚至在看到不正确的观看信息时致电支持人员(这是以前的一种服务实现方式)。 此外,我们还会在用户的个人帐户中存储和显示详细的统计信息(例如,评估使用付费服务的有效性)。 所有这些使我们能够保存每个观看事件并显示最相关的值。
通常,项目的功能和原理如下所示:
- 网页或应用程序屏幕在广告视图计数器后面发出一个请求(该请求通常是异步的,以优先输出基本信息)。 而且,如果显示广告本身的页面,则客户会要求增加并返回更新后的观看次数。
- 通过处理读取请求,该服务尝试从Redis缓存中获取信息,并通过完成对MongoDB的请求来补充未知信息。
- 写请求被发送到萝卜中的2个结构:增量更新队列(在后台异步处理)和视图总数的缓存。
- 同一服务中的后台进程从队列中读取元素,将其累积在本地缓冲区中,然后定期将其写入MongoDB。
记录查看计数器:陷阱
尽管上述步骤看起来很简单,但是这里的问题是数据库和微服务实例之间的交互的组织,因此数据不会丢失,不会重复且不会滞后。
仅使用一个存储库(例如,仅使用MongoDB)将解决其中的一些问题。 实际上,该服务以前一直可以使用,直到我们遇到了扩展,稳定性和速度问题。
在存储之间移动数据的幼稚实现可能导致例如以下异常情况:
- 竞争性写入高速缓存期间数据丢失:
- 进程A增加了Redis缓存中的视图计数,但是发现该实体仍然没有数据(它可以是从缓存中挤出的新声明或旧声明),因此进程必须首先从MongoDB获取此值。
- 进程A从MongoDB获取视图计数-例如,数字5; 然后向其添加1并将写入Redis 6 。
- 流程B (例如,由也输入了相同广告的网站的另一个用户发起)同时执行相同的操作。
- 进程A将值6写入Redis。
- 进程B将值6写入Redis。
- 结果,在记录数据时由于竞赛而丢失了一个视图。
这种情况不太可能发生:例如,我们有一项付费服务,可以在网站主页上放置广告。 对于新的公告,此类事件可能会因为突然涌入而立即导致失去许多视图。
- 另一种情况的示例是将视图从Redis移至MongoDb时的数据丢失:
- 该过程从Redis中获取一个待处理的值,并将其存储在内存中,以供以后写入MongoDB。
- 写入请求失败(或进程在执行之前崩溃)。
- 数据再次丢失,下一次将缓存的值推出并替换为数据库中的值时,数据将变得很明显。
可能会发生其他错误,其原因也取决于数据库之间操作的非原子性,例如,在删除和增加同一实体的视图时发生冲突。
记录观看次数:解决方案
我们在该项目中存储和处理数据的方法是基于这样的期望:在任何时间点,MongoDB可能比Redis更有可能失败。 当然,这并不是绝对的
规则 -至少不是每个项目都适用-但是在我们的环境中,我们确实习惯于观察磁盘操作性能导致的MongoDB查询的定期超时,这以前是丢失某些事件的原因之一。
为避免上述许多问题,我们将任务队列用于延迟保存和lua脚本,这使得可以一次原子地更改多个萝卜结构中的数据成为可能。 考虑到这一点,保存视图的细节如下:
- 当写入请求落入微服务时,它将运行lua脚本IncrementIfExists以仅在高速缓存中已存在计数器时才增加计数器。 如果萝卜中没有正在查看的实体的数据,脚本将立即返回-1;否则,脚本将立即返回-1 。 否则,它会通过HINCRBY增加缓存中视图的值,通过LPUSH将事件添加到队列中以供随后存储在MongoDB中(我们称为挂起队列 ),并返回更新的视图数。
- 如果IncrementIfExists返回正数,则此值返回给客户端,并且请求结束。
否则,微服务会从MongoDb中获取视图计数器,并将其递增1并将其发送到萝卜。
- 通过另一个lua脚本Upsert来执行对萝卜的写入操作,如果脚本仍然为空,则将其总数保存到缓存中;如果其他人在步骤1和步骤3之间设法填充了缓存,则将视图总数增加1。
- Upsert还将查看事件添加到挂起的队列中,并返回更新的数量,然后将其发送到客户端。
由于lua脚本
是原子执行的 ,因此我们避免了竞争性写入可能导致的许多潜在问题。
另一个重要的细节是确保将更新从未决队列安全转移到MongoDB。 为此,我们使用了
Redis文档中描述的“可靠队列”模板,该模板通过在单独的另一个队列中创建已处理项目的副本,直到最终将它们存储在持久性存储中,从而大大降低了数据丢失的机会。
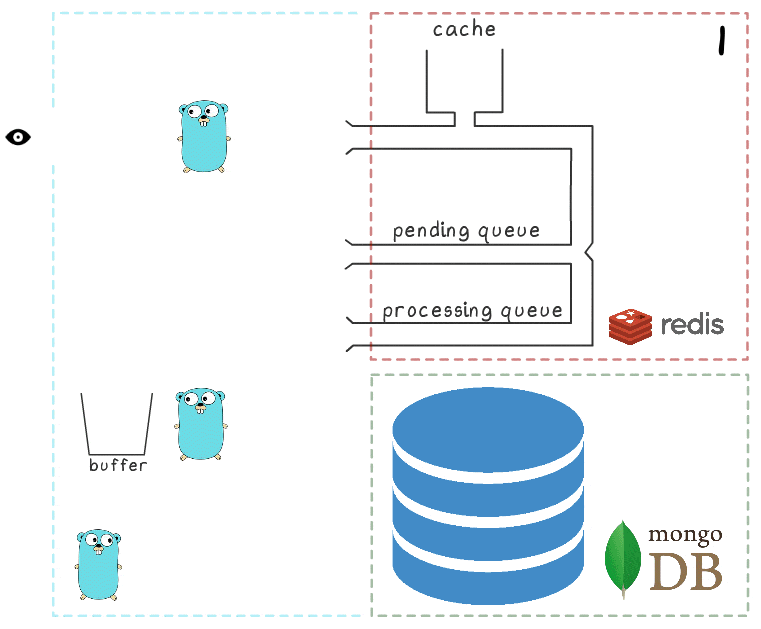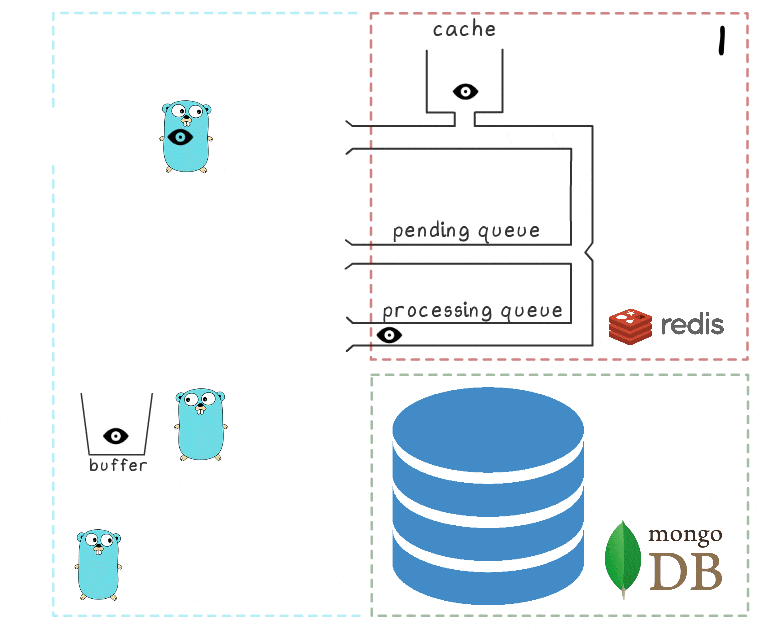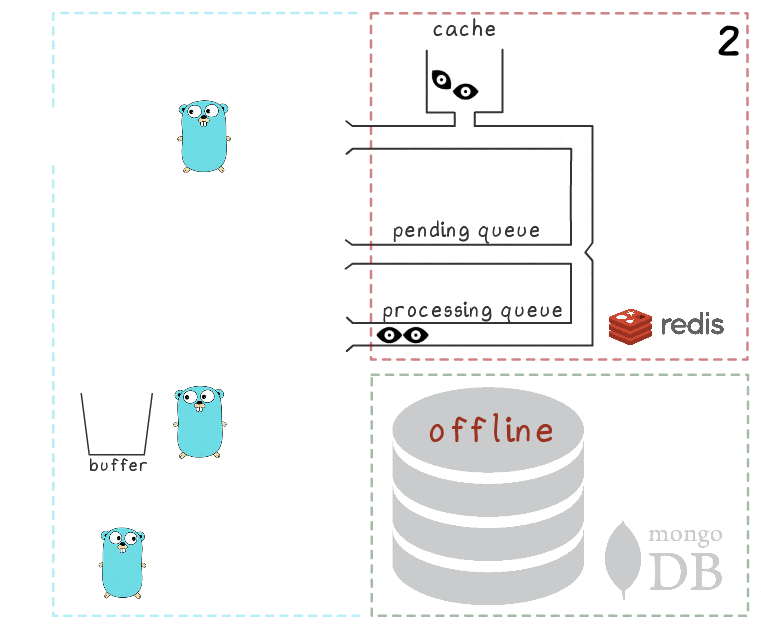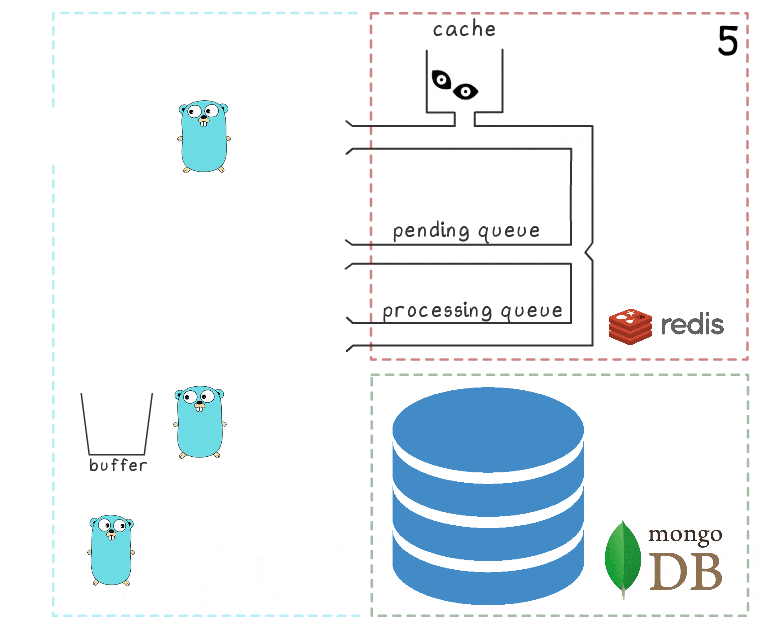
为了更好地理解整个过程步骤,我们准备了一个小的可视化文件。 首先,让我们看一个正常的成功场景(这些步骤在右上角编号,下面将对其进行详细描述):
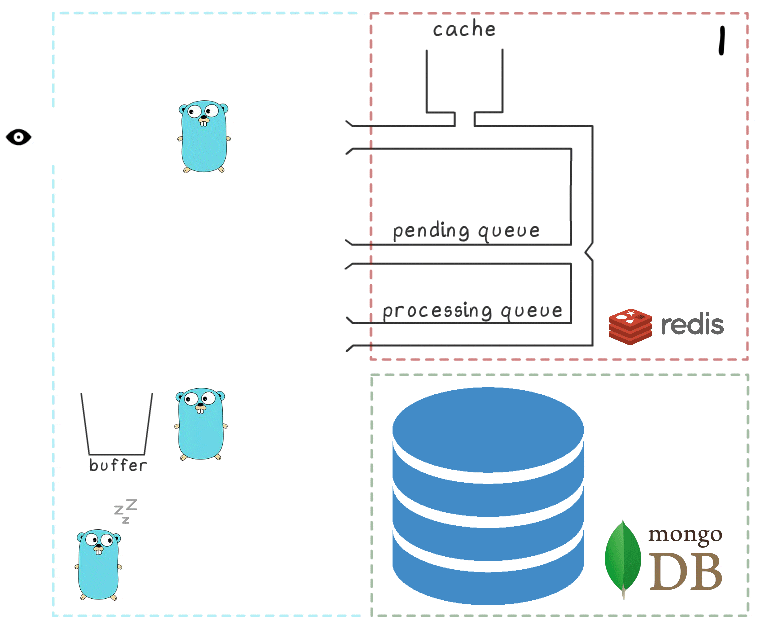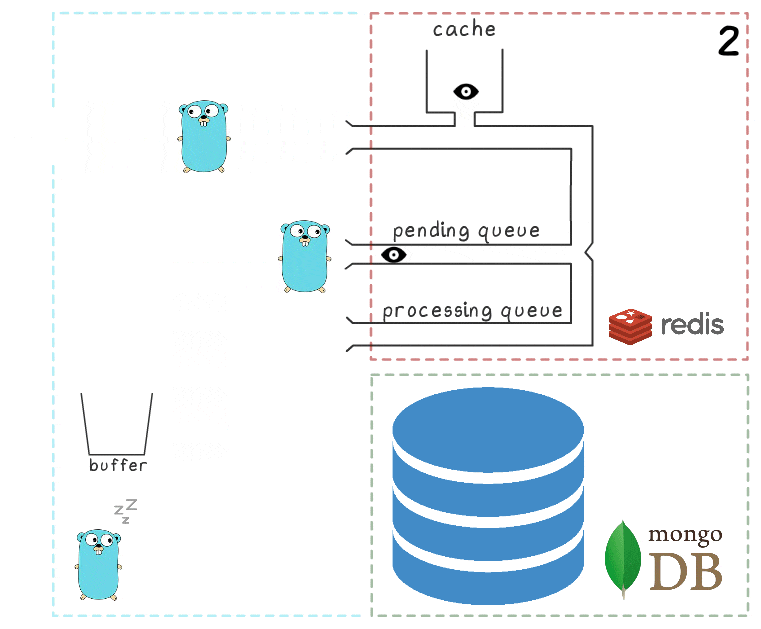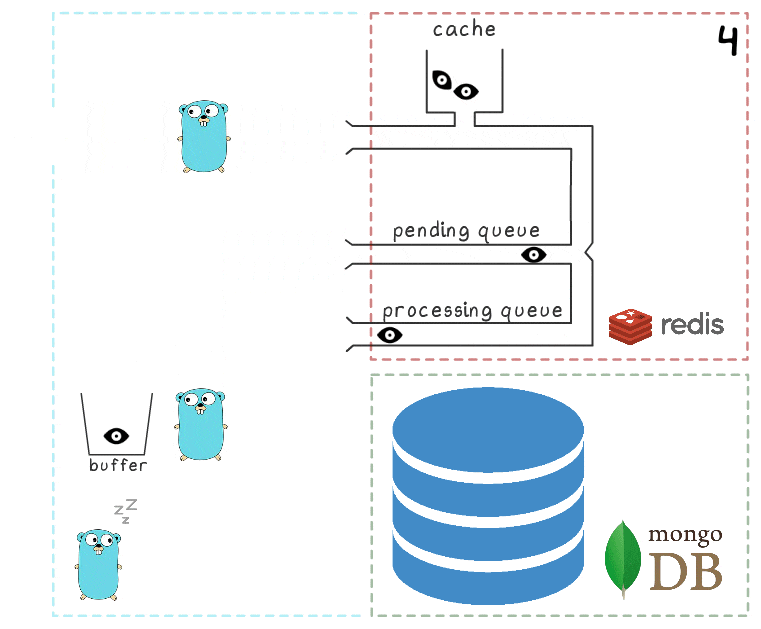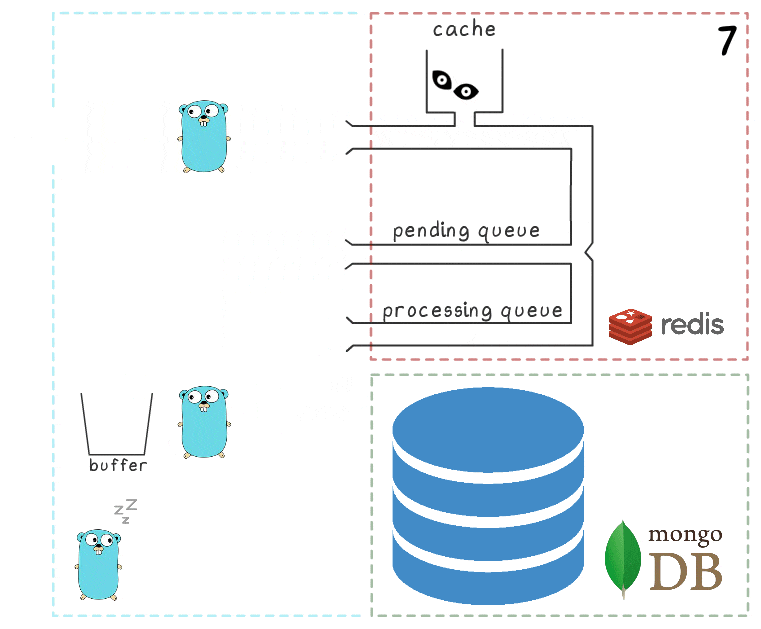
- 微服务收到写入请求
- 请求处理程序将其传递给lua脚本,该脚本将查找内容写入缓存(立即使其可读)并写入队列以进行进一步处理。
- 后台goroutine(定期)执行BRPopLPush操作,该操作将一个元素从一个队列原子地移动到另一个队列(我们称其为“处理队列”-具有当前已处理元素的队列)。 然后,将相同的元素存储在过程存储器的缓冲区中。
- 另一个写入请求到达并正在处理,这使我们在缓冲区中有2个元素,在处理队列中有2个元素。
- 超时后,后台进程决定刷新MongoDB中的缓冲区。 从缓冲区写入多个值是由单个请求执行的,这会对吞吐量产生积极影响。 另外,在录制之前,该过程会尝试将多个视图合并为一个视图,以汇总相同广告的值。
在我们的每个项目中,使用3个微服务实例,每个实例都有自己的缓冲区,每2秒将其保存到数据库中。 在这段时间内,大约100个元素累积在一个缓冲区中。
- 成功写入后,该进程将从处理队列中删除项目,表示处理已成功完成。
当所有子系统都井井有条时,其中一些步骤可能显得多余。 细心的读者可能还对睡觉在左下角的地鼠有什么疑问。
在考虑MongoDB不可用时的情况时,将解释所有内容:
- 第一步与先前场景中的事件相同:该服务接收2个记录视图的请求并对其进行处理。
- 进程失去与MongoDB的连接(进程本身当然还不知道这一点)。
和以前一样,Gorutin处理程序正在尝试将其缓冲区刷新到数据库中-但这一次没有成功。 她返回以等待下一次迭代。
- 另一个后台goroutine唤醒并检查处理队列。 她发现这些元素是很久以前添加的。 她断定他们的处理失败,因此将他们移回了挂起的队列。
- 一段时间后,将恢复与MongoDB的连接。
- 第一个后台goroutine再次尝试执行写操作-这次成功-最终从处理队列中永久删除项目。
在此方案中,通过测试和常识得出了一些重要的超时和启发式方法:例如,在闲置15分钟后,元素从处理队列移回到挂起队列。 另外,负责此任务的goroutine在执行之前执行
锁定 ,因此微服务的多个实例不会尝试同时还原“冻结”视图。
严格来说,即使是这些措施也不能提供理论上有力的保证(例如,我们忽略了过程冻结15分钟之类的情况),但实际上它确实可靠。
此外,在此方案中,我们至少还知道2个要注意的漏洞:
- 如果微服务成功保存到MongoDb之后但在清除处理队列列表之前立即崩溃,则该数据将被视为未保存-15分钟后将再次保存。
为了减少发生这种情况的可能性,我们多次尝试在出现错误的情况下从处理队列中删除。 实际上,我们尚未在生产中观察到此类情况。
- 重新启动后,由于萝卜配置为每隔几分钟定期保存RDB快照 ,因此萝卜不仅会丢失缓存,还会丢失队列中一些未保存的视图。
尽管从理论上讲这可能是一个严重的问题(特别是如果项目处理的是非常关键的数据),但实际上很少重启节点。 同时,根据监视,元素在队列中花费的时间少于3秒,也就是说,可能的损失量非常有限。
似乎有更多的问题比我们想要的要多。 但是,实际上,事实证明,我们最初为之辩护的场景-MongoDB的失败确实是一个更为现实的威胁,并且新的数据处理方案成功地确保了服务的可用性并防止了损失。
一个生动的例子是,其中一个项目的MongoDB实例一整夜都无法使用。 一直以来,视图计数都是以萝卜的形式累积并从一个队列轮换到另一个队列,直到解决事件后最终将其保存在数据库中; 大多数用户甚至都没有注意到失败。
读取观看次数
读取请求比写入请求简单得多:微服务首先检查萝卜中的缓存;然后,检查萝卜中的缓存。 缓存中未找到的所有内容都将填充来自MongoDb的数据,并返回给客户端。
在读取操作期间,不会对缓存进行端到端写入,从而避免了防止竞争性写入的开销。 高速缓存的命中率保持良好,通常,由于其他写入请求,它已被预热。
可以从MongoDB直接读取每日视图统计信息,因为它的请求频率要低得多,而缓存起来则更加困难。 这也意味着当数据库不可用时,读取统计信息将停止工作。 但它仅影响一小部分用户。
MongoDB数据存储方案
该项目的MongoDB收集方案基于
数据库开发人员自身的以下建议 ,如下所示:
- 视图被保存在2个集合中:一个集合中有视图的总量,另一个集合中是按天统计。
- 统计信息收集中的数据是根据每个广告每月一个文档的形式组织的。 对于新公告,将当月插入31个零填充的文档; 根据上面提到的文章,这使您可以立即为磁盘上的文档分配足够的空间,以便数据库在添加数据时不必移动它。
该项目使读取统计信息的过程有点尴尬(请求必须由微服务端每月生成),但总体而言,该方案仍然相当直观。
- upsert操作用于记录,以便在同一请求中为所需实体更新并根据需要创建文档。
我们不使用MongoDb的事务处理功能来同时更新多个集合,这意味着我们冒着只能将数据写入一个集合的风险。 暂时,我们只记录这种情况; 它们很少,并且到目前为止,这还没有像其他方案一样带来同样的重大问题。
测试中
我不会相信我所讲的话,如果测试未涵盖所描述的场景,它们确实会起作用。
由于大多数项目代码与萝卜和MongoDb紧密协作,因此其中的大多数测试都是集成测试。 通过docker-compose支持测试环境,这意味着它可以快速部署,通过在每次启动时重置和还原状态来提供可重现性,并且可以进行实验而不会影响其他人的数据库。
在这个项目中,有3个主要的测试领域:
- 在典型场景中验证业务逻辑,即所谓的 幸福的道路。 这些测试回答了问题-当所有子系统都井井有条时,服务是否按照功能要求工作?
- 检查预期服务将继续工作的负面情况。 例如,当MongoDb崩溃时,该服务真的不会丢失数据吗?
我们确定信息与定期超时,冻结和竞争性录制操作保持一致吗? - 检查我们不希望服务继续运行的负面情况,但仍应提供最低级别的功能。 例如,当萝卜和mongo都不可用时,该服务将没有机会继续保存并提供数据-但是我们要确保在这种情况下它不会崩溃,但是希望系统恢复后再恢复工作。
为了检查不成功的方案,服务业务逻辑代码与数据库客户端接口配合使用,在必要的测试中,该服务将替换为返回错误和/或模拟网络延迟的实现。 我们还使用“
环境对象 ”模式来模拟几个服务实例的并行操作。 这是众所周知的“控制反转”方法的一种变体,在该方法中,函数本身不访问依赖项,而是通过参数中传递的环境对象接收依赖项。 除其他优点外,该方法还允许您在一个测试中模拟服务的多个独立副本,每个副本都有其自己的数据库连接池,或多或少有效地再现了生产环境。 一些测试会并行运行每个此类实例,并确保它们都看到相同的数据,并且没有竞争条件。
我们还根据以下内容进行了基本但仍然非常有用的压力测试:
siege ,这有助于大致估算服务的允许负载和响应速度。
关于性能
对于90%的请求,处理时间非常短,最重要的是-稳定; 这是几天中一个项目的测量示例:
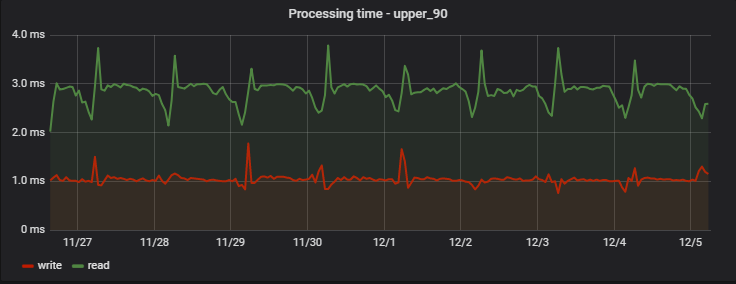
有趣的是,一条记录(实际上是写+读操作,因为它返回更新的值)比读取快一点(但仅从不观察实际延迟记录的客户端的角度来看)。
每天早上定期增加延误是我们分析团队工作的一个副作用,该团队每天根据服务数据收集自己的统计信息,从而给我们带来了“人为负担”。
最大处理时间相对较长:在最慢的请求中,新的和不受欢迎的广告会展示自己(如果未查看广告并且仅在列表中显示-其数据不会进入缓存并从MongoDB中读取),则将多个广告一次组合请求(它们的成本另行安排),以及可能的网络延迟: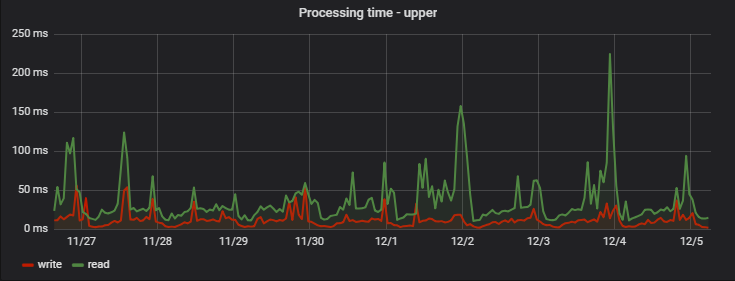
结论
实践在某种程度上与直觉相反,表明使用Redis作为查看服务的主要存储库,可以提高整体稳定性并提高整体速度。服务的主要负载是读取请求,读取请求中有95%是从缓存中返回的,因此工作非常迅速。记录请求被延迟,尽管从最终用户的角度来看,它们也可以快速工作并立即对所有客户端可见。通常,几乎所有客户都在不到5毫秒内收到响应。结果,基于Go,Redis和MongoDB的微服务的当前版本可以在负载下成功工作,并且能够承受其中一个数据存储的周期性不可用。根据我们过去在基础结构问题方面的经验,我们确定了主要的错误情况并成功地针对这些错误情况进行了防御,因此大多数用户不会感到不便。反过来,我们在日志中收到的投诉,警报和消息也要少得多,并且我们准备进一步增加出勤率。