
我们提请您注意“
PIFR:姿势不变3D人脸重建 ”一文的翻译。
在许多实际应用中,包括面部检测和识别,3D表情符号和贴纸的生成,都需要从平面图像恢复面部几何形状。 但是,此任务仍然很困难,尤其是在有关面部的大多数信息无法得知时。
江南大学(中国)的Jiang和Wu以及萨里大学(英国)的Kittler提供了一种
新的3D人脸重建算法-PIFR ,即使在困难的姿势下,该
算法也可以显着提高重建的准确性。
但是,让我们首先简要回顾一下先前在3D蒙版和脸部重构方面的工作。
最新研究
作者提到了四种使3D蒙版变形的常用方法:
本文使用最受欢迎的BML模型。
有多种方法可以从平面图像重建3D模型,包括:
建议方法-PIFR
Jiang,Wu和Kitler的文章提出了一种新的基于3DMM方法的姿态不变3D人脸重建(PIFR)。
首先,作者建议生成正面图像,对一个输入的面部图像进行标准化。 此步骤允许您还原此人的其他身份信息。
下一步是使用两个图像的3D特征的加权和:正面和源。 这不仅允许保留原始图像的姿势,而且可以扩展识别信息。
拟议方法方案:
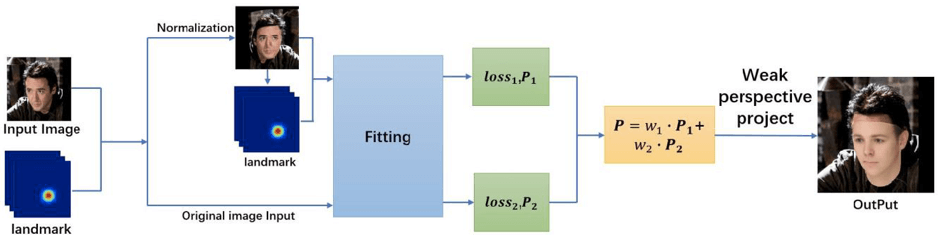
实验表明,与以前的方法相比,PIVL算法显着提高了3D面部重建性能,尤其是在复杂的姿势中。
更详细地考虑建议的模型。
方法说明
PIVL方法在很大程度上依赖于3DMM拟合过程,这可以表示为将计算关键点的3D投影坐标时的误差最小化。 但是,由3D模型创建的面大约有50,000个顶点,因此迭代计算会导致收敛缓慢且效率低下。
为了克服这个问题,研究人员建议在装配面罩过程中使用关键点(例如,眼中心,嘴角和鼻尖)作为主要事实。 特别是,使用加权参考3DMM拟合。
 第一行:原始图像和地标。 下排:3D人脸模型及其在2D图像上的对齐
第一行:原始图像和地标。 下排:3D人脸模型及其在2D图像上的对齐下一个任务是特写创建3D面罩。 为了解决此问题,研究人员使用了
姿势和表情的高精度归一化(VNPV)方法 ,但仅对姿势而不是面部表情进行了归一化。 此外,
泊松编辑用于恢复由于视角而封闭的脸部区域。
与其他方法的性能比较
评估了PIVL方法的有效性,以重现脸部:
- 中小姿势;
- 特写;
- 复杂的姿势(偏差角±90)。
为此,研究人员使用了
三个公共数据集 :
- 使用Flickr图像创建的AFW数据集包含205个图像,其中包含468个标记的脸部,复杂的背景和脸部姿势。
- LFPW数据集,包含测试集中的224张面部图像和训练集中的811张面部图像; 每个图像标记有68个特征点; 从这两组中选择了900张图像进行本研究的测试。
- AFLW数据集是一个大规模的人脸数据库,其中包含约2.5亿个手动标记的图像,并且每个图像都标记有21个特征点。 在这项研究中,仅将来自该数据集的复杂面部位置的图像用于定性分析。
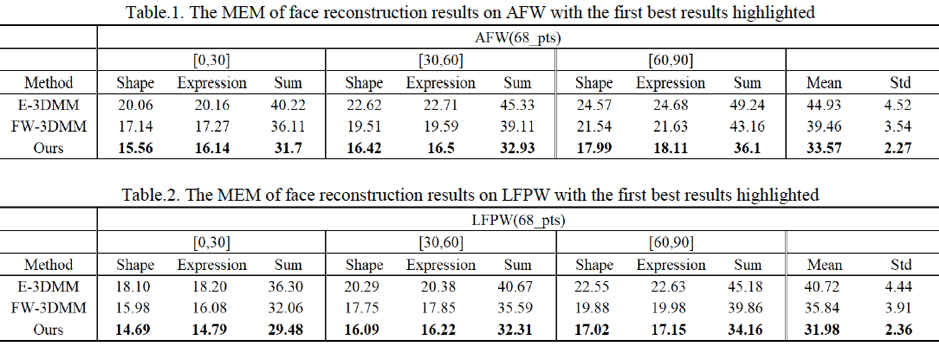
定量分析
使用欧几里得平均指标(CEM),该研究在AFW和lfpw数据集中比较了PIFR方法与E-3DMM和FW-3DMM的性能。 累积误差分布(RNO)曲线如下:
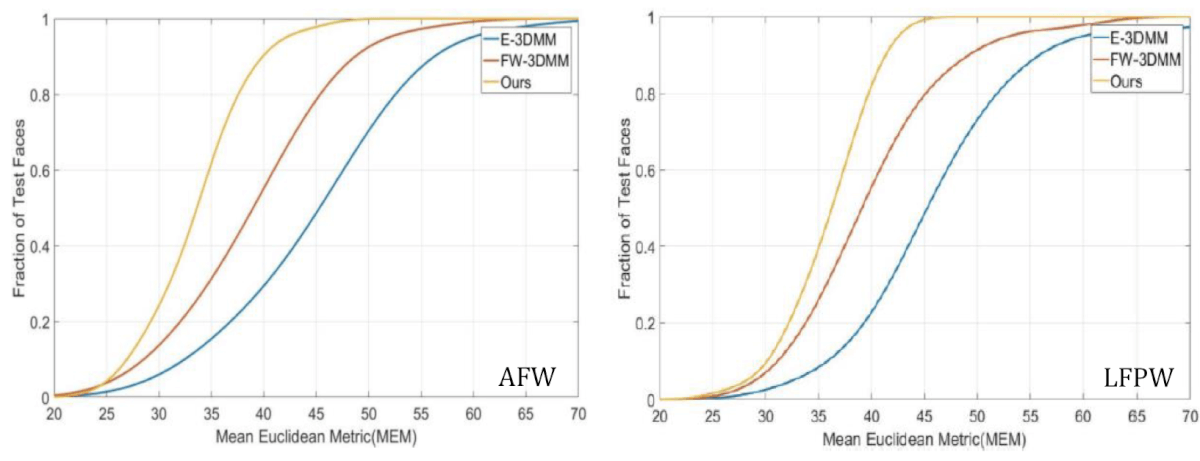 AFW和LFPW数据集中的累积误差分布(RNO)曲线比较
AFW和LFPW数据集中的累积误差分布(RNO)曲线比较从下面的图表可以看出,PIVL方法比其他两种方法具有更高的效率。 休闲娱乐近摄效果特别好。
定性分析
该方法还基于AFLW数据集中不同位置的面部照片进行了定性评估。 结果如下图所示。
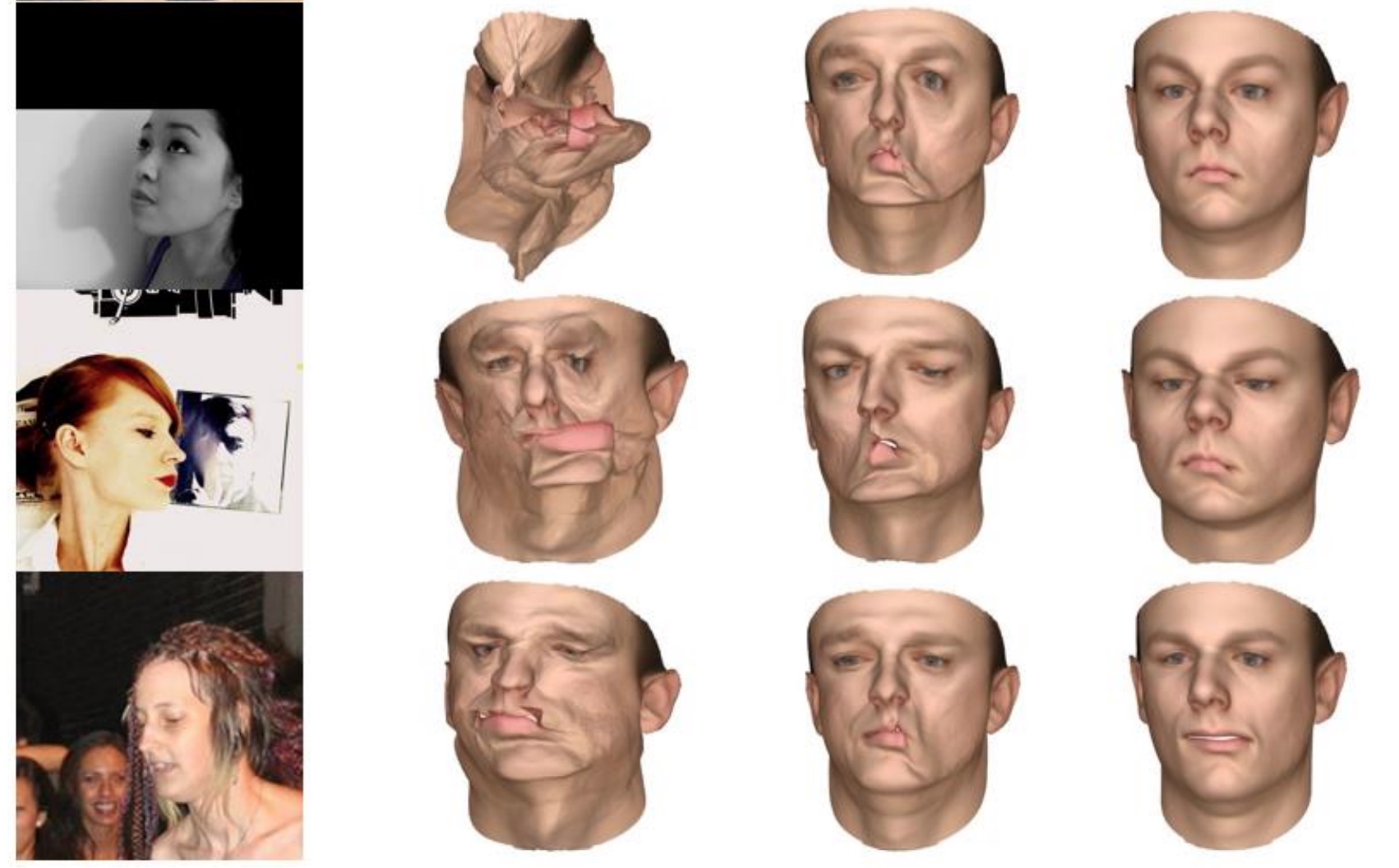 3D人脸重建的比较:(a)原始图像; (b)FW-3DMM; (c)E-3DMM; (d)建议的方法
3D人脸重建的比较:(a)原始图像; (b)FW-3DMM; (c)E-3DMM; (d)建议的方法即使由于平凡的姿势而看不到一半地标,这会导致较大的错误和其他方法的失败,但PIFR方法仍然可以正常工作。
以下是基于AFW数据集中图像的PIVL方法有效性的其他示例。

第一行:2D图像输入。 中排:3D蒙版。 最底行:遮罩对齐
总结
新的PIVL人脸重建算法即使在复杂的姿势下也能提供良好的重建结果。 该方法同时接受源图像和正面图像进行加权合并,使您可以还原有关面部的足够信息以重新创建3D蒙版。
将来,研究人员计划恢复更多有关面部的信息,以提高面罩重建的准确性。
原来的翻译-Farid Gasratov