
Ozon在线商店几乎拥有所有东西:冰箱,婴儿食品,可容纳100,000人的笔记本电脑等。 这意味着所有这些也都在公司的仓库中-货物在那里存放的时间越长,公司的价格就越高。 为了了解人们想要订购多少商品以及需要购买多少臭氧,我们使用了机器学习技术。
销售预测:挑战
在研究问题陈述之前,我们先从一个例子开始。 这是一段时间以来真正的Ozon销售时间表。 问题:他下一步将去哪里?
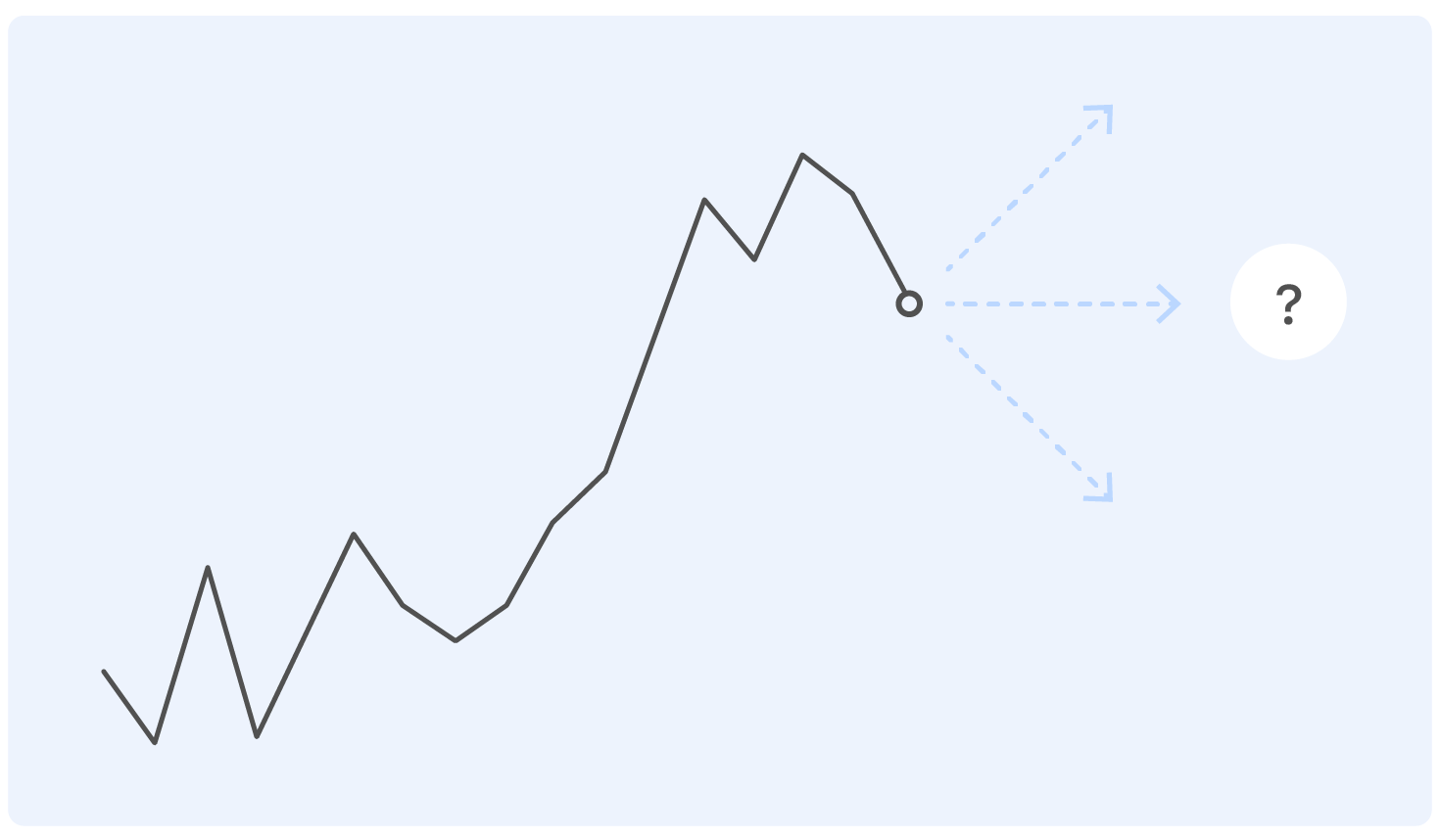
接受过这样的问题近似技术培训的人会提出以下问题:坐标轴在哪里? 什么样的产品呢? 什么单位? 您从哪所学院毕业的? -以及出于道德原因未包含在本文中的许多其他内容。
实际上,没有人可以在这样的陈述中正确回答问题,如果有人可以,那么很可能会弄错他。
在此图表中添加更多信息:Ozon网站(蓝色)和竞争对手网站(橙色)上的坐标轴和价格变化。
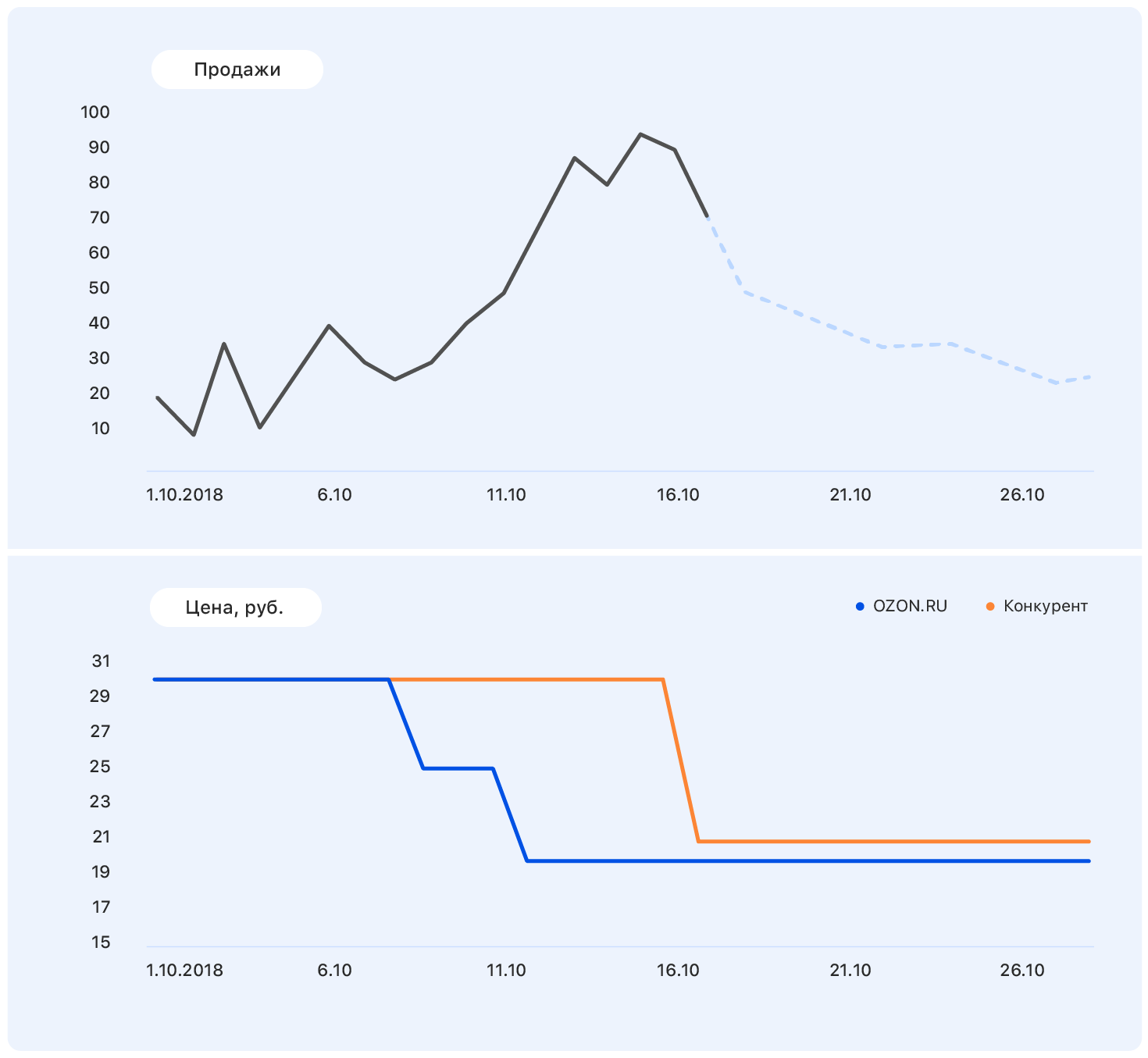
我们的价格在某个时候下降了,但是竞争仍然是一样的-Ozon的销量上升了。 我们知道定价计划:我们的价格将保持在同一水平,但是竞争对手紧随Ozon之后将价格降低到几乎我们的价格。
此数据足以做出有意义的假设-例如,销售将恢复到先前的水平。 而且,如果您查看图表,事实就是如此。
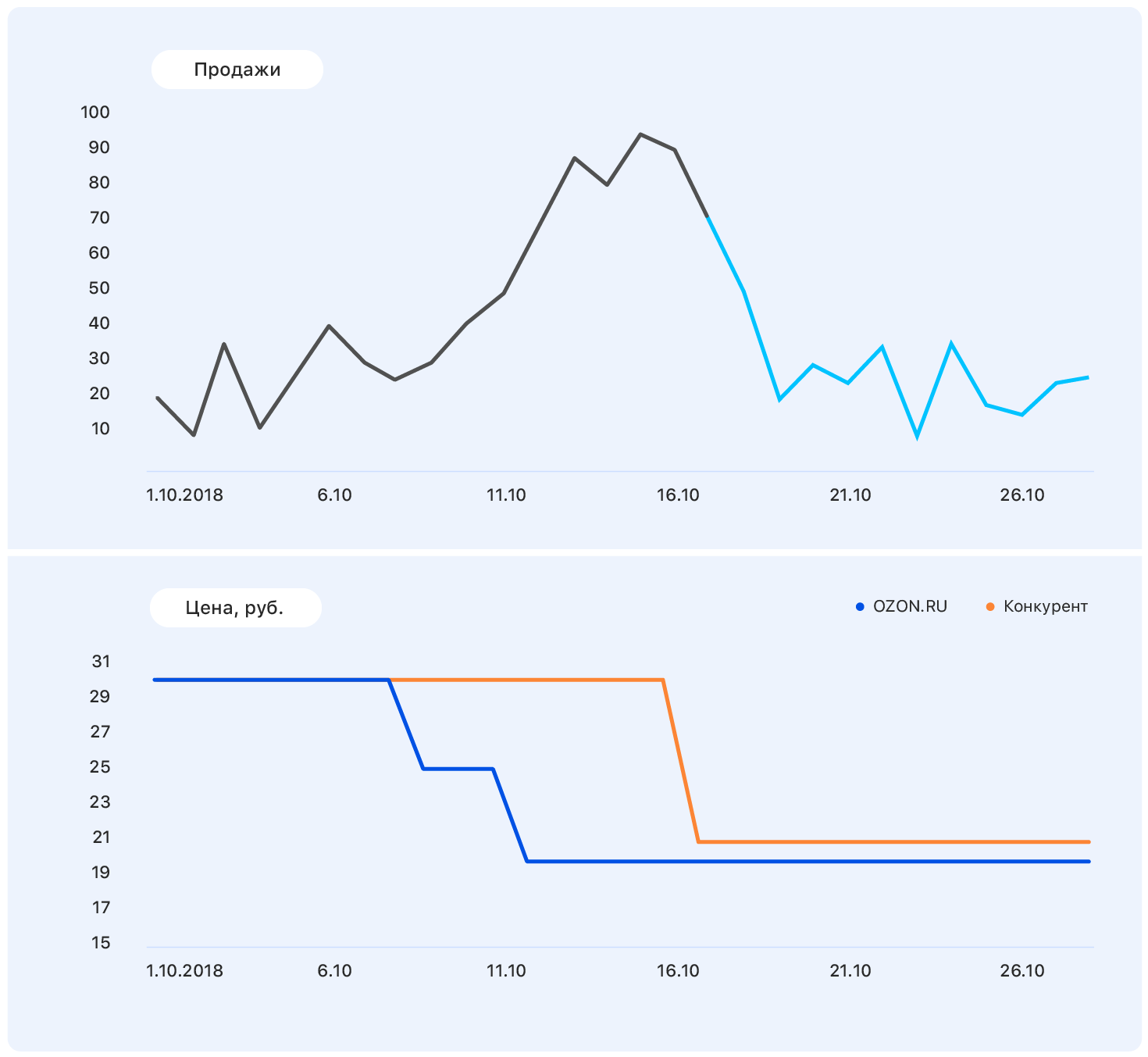
问题在于,实际上,对该产品的需求并没有受价格的太大影响,而销售增长主要是由于我们商店中缺少该产品的大多数竞争对手而引起的。 我们仍然没有考虑许多因素:电视上刊登的商品是否在广告中? 还是甜食,3月8日不久?
有一件事很清楚:“下跪”预测是行不通的。 我们遵循
耙子和拐杖的标准路径
来构建任何ML算法。 就是这样。
指标选择
如果您之外的其他人至少会使用您的预测,那么选择度量是起点。
考虑一个例子:我们有三个预测选项。 哪个更好?
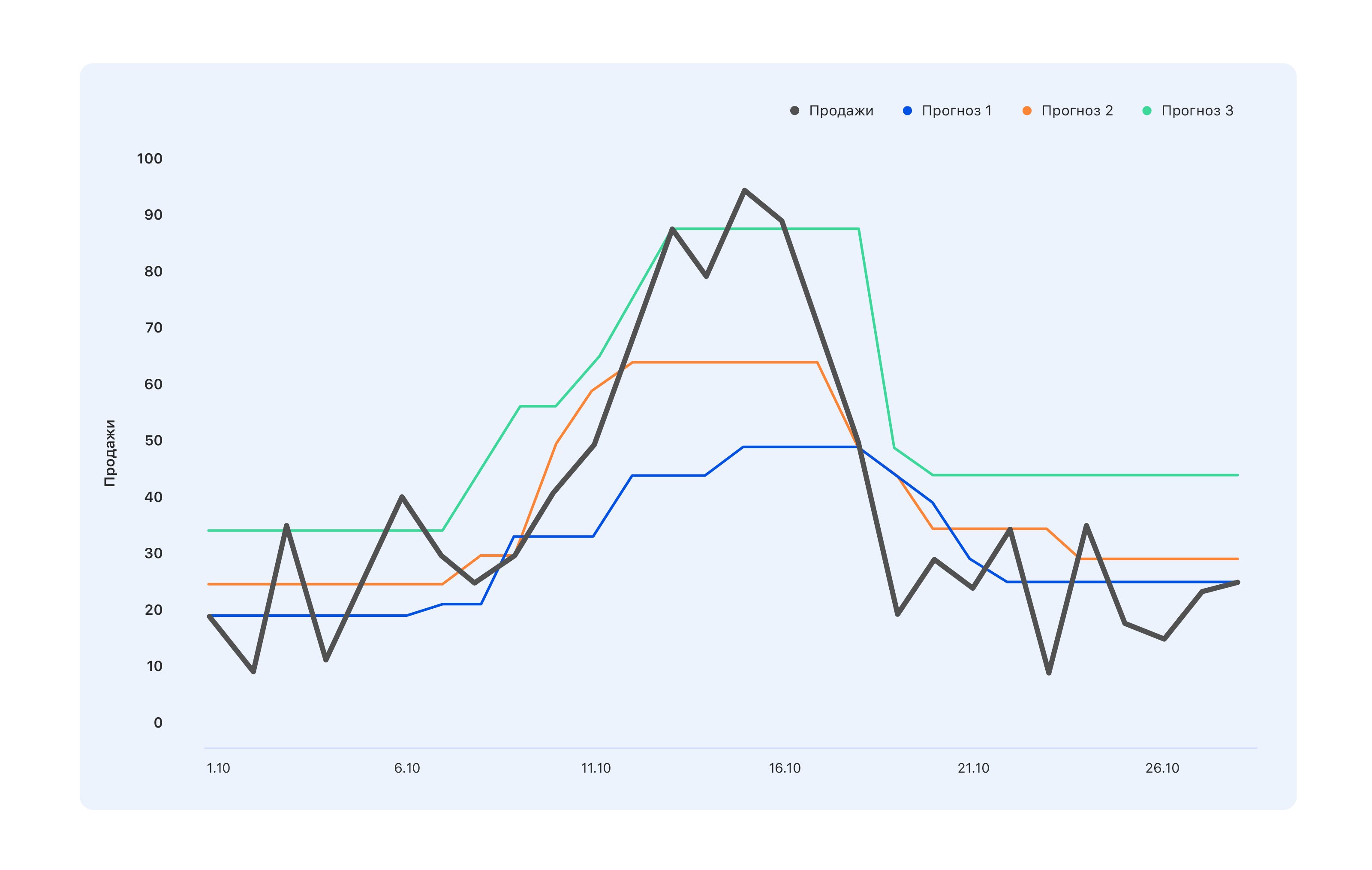
从仓库专家的角度来看,我们需要一个蓝色的预测-我们将少买些东西,让我们错过10月中旬的顶峰,但是仓库中什么都不会剩下。 将关键绩效指标与销售挂钩的专家持相反的看法:即使是绿松石的预测也不是很正确,需求的所有跃升也没有得到反映-请对其进行修改。 但是从一个人的角度来看,从外部来看,通常需要更好的东西-这样每个人都会感觉良好,反之亦然。
因此,在做出预测之前,有必要确定谁将使用它以及为什么使用它。 也就是说,选择一个指标并了解基于该指标建立的预测的预期结果。 然后等待。
我们选择MAE-平均绝对误差。 此指标适用于我们高度不平衡的训练样本。 由于种类繁多(150万种),因此特定区域中的每种产品都少量销售。 如果我们总共出售数百件绿色连衣裙,那么一件带有猫的绿色连衣裙每天的售价为2-3。 结果,样本向较小的值偏移。 另一方面,还有iPhone,微调器,奥尔加·布佐娃(Olga Buzova)的新书(一个玩笑)等。 -它们在任何城市都大量销售。 MAE允许您在有条件的iPhone上不受巨额罚款,并且通常在大部分商品上都能正常工作。
第一步
我们从构建最愚蠢的预测开始,该预测可能是:下周将出售0到1000之间的随机数,并获得指标MAE =496。可能会更糟,但这已经非常糟糕了。 因此,我们有了一个指导方针:如果获得这样的度量标准值,那么显然我们做错了什么。
然后,我们开始玩耍那些知道如何在没有机器学习的情况下进行预测的人,并尝试预测下周的商品销售额等于过去几周的平均销售额,得出的指标MAE = 1.45-更好。
继续推理,我们认为上周的销售与预测下周的销售将不再相关。 对于这样的预测,MAE为1.26。 在下一轮的预后思考中,我们决定考虑这两个因素并预测下周的销售额,即平均销售额的50%和过去一周的销售额的50%的总和-MAE = 1.23。
但这对我们来说似乎太简单了,我们决定使事情复杂化。 我们收集了一个小的培训样本,其中的迹象是过去的销售量和平均销售量,目标是下周的销售量,我们对其进行了简单的线性回归培训。 平均和最后几周的权重分别为0.46和0.55,测试样本的MAE等于1.2。
结论:我们的数据具有预测潜力。
特征工程
决定基于两个理由建立预测不是我们的目标,因此我们坐下来生成新的复杂功能。 这是有关过去销售的信息-1、2、3、4周前,一年前的一周等。 以及过去几周的观看次数,添加到购物篮中的视图,按订单将视图和添加到购物篮中的视图转换-以及所有在不同时期的操作。
我们需要提供一个知识模型,以了解产品整体的销售方式,最近销售的动态如何变化,人们对产品的兴趣如何演变,其销售如何取决于价格以及我们认为有用的其他因素。
当我们的想法用完后,我们去了销售部门的专家。 例如,在那儿,我们了解到明年是猪年,因此,至少与猪类似的商品将非常受欢迎。 或者,例如,“非冻结”的我们的人民没有提前购买,而是恰好在初霜之日购买-因此,请考虑天气预报。 总的来说,每个人都很满意。 我们-因为有了很多我们从未想到过的新主意,以及我们的商人-很快将有可能做比销售预测更有趣的事情。
但这仍然太简单-我们添加了综合症状:
- 从视图到销售的转换-情况如何,如何变化;
- 过去4周的销售量与过去一周的销售量之比(如果此数字与4相差很大,目前此产品的需求可能会受到“动荡”的影响);
- 产品销售与整个类别中销售的比率-如果该数字接近一个,则该产品是“垄断者”。
在此阶段,您需要尽可能多地提出建议-在培训阶段扔掉非信息性标志。
结果,我们得到了170个标志。 展望未来,最大的功能重要性在于
- 过去一周的销售量(两个,三个和四个)。
- 上周产品可用性是产品出现在网站上的时间百分比。
- 最近7天商品销售计划的角度系数。
- 过去价格与未来价格的比率-享有巨大的折扣,因此可以更积极地开始购买商品。
- 我们网站内直接竞争对手的数量。 例如,如果这支笔是同类产品中唯一的一支,那么销售将非常平稳。
- 产品尺寸-事实证明,长度和宽度会严重影响销售的可预测性。 由于某种原因,对于长而狭窄的物体(例如,遮阳伞或钓鱼竿),日程安排更加不稳定。 我们尚不知道如何解释这一点。
- 一年中的天数-显示新年是否临近,3月8日,季节性销售开始增加等。
取样方式
训练样本是痛苦。 我们收集了大约4周的时间,其中有2个是去找了不同的数据保管人,并要求他们了解一下。 每当您长时间需要数据时,都会发生这种情况。 即使在很长一段时间的理想数据收集系统中,也会出现“本来就是这样的想法,但后来我们开始不同地思考并将数据写在同一列中”的精神。 大约在一两年前,服务器崩溃了,但是没有人准确记录下什么时候-零不再意味着没有销售。
结果,我们获得了有关人们在该站点上所做的工作,数量以及数量的信息,这些人被添加到收藏夹和购物篮中并进行购买。 我们收集了大约1500万个样本,每个样本包含170个功能,目标是下周的销售数量。
我们在Spark上编写了2000行代码。 它工作缓慢,但允许咀嚼大量数据。 似乎计算直线的斜率很简单。 并从多个销售点撤出销售时执行10kk次-任务不是胆小。
再过一周,我们从事数据清理工作,以使该模型不会因排放量和本地采样特征而分散注意力,而是仅提取了Ozon销售中固有的真实依赖性。 这里有3个sigma和更多狡猾的异常搜索方法。 最困难的情况是在缺货期间恢复销售。 最简单的解决方案是在“目标”星期内淘汰产品投放市场的那几周。
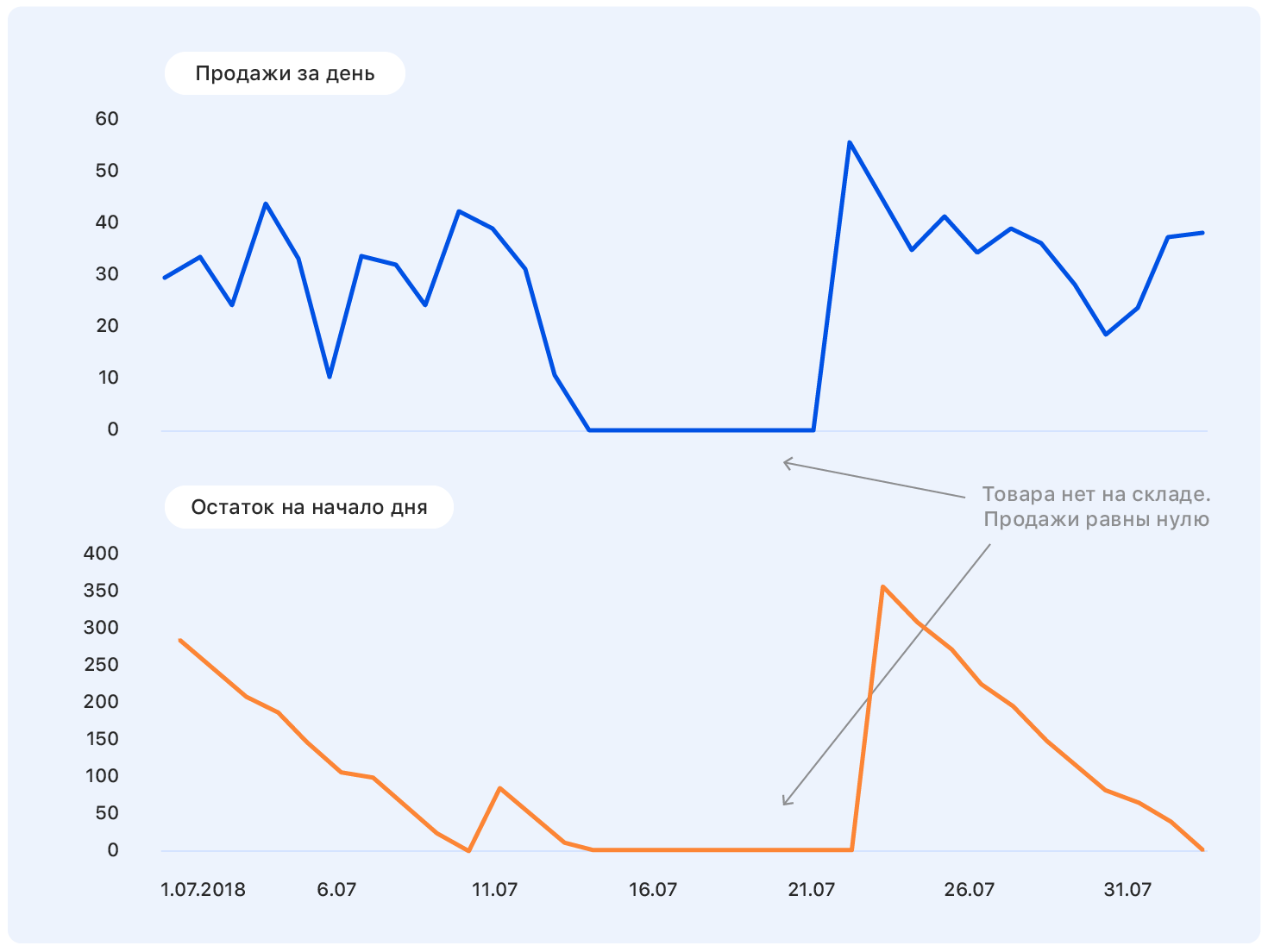
结果,在1500万个样本中,有1000万个仍然存在。重要的是不要被带走,也不要失去样本的完整性(实际上,仓库中的货物不足是其对公司重要性的间接特征;从样本中删除此类货物与扔掉随机样本并不相同。 )
ML时间
在干净的样品上,开始训练模型。 自然地,我们从线性回归开始,得到MAE = 1.15。 看来,这只是很小的增长,但是当您有1000万个样本,其中平均值为5-10时,即使指标值发生很小的变化,也都将带来无与伦比的预测视觉质量。 而且由于您最终将不得不向商业客户展示该解决方案,因此提高客户的满意度是一个重要因素。
接下来是sklearn.ensemble.RandomForestRegressor,在短暂选择超参数后,其显示MAE = 1.10。 接下来,我们尝试了XGBoost(没有它的地方)-一切都很好,MAE = 1.03-只是很长时间。 不幸的是,我们无法使用GPU来训练XGBoost,并且在一个处理器上训练了一个模型很长时间。 我们试图更快地找到一些东西,并选择了LightGBM-它训练了两倍的速度,并且显示MAE甚至更低-1.01。
我们将所有产品划分为13个类别,如网站上的目录:桌子,笔记本电脑,瓶子,并且针对每种类别,我们训练了具有5至16天不同预测深度的模型。
培训耗时约五天,为此,我们提出了庞大的计算集群。 我们开发了这样的管道:随机搜索工作了很长时间,给出了前10组超参数,然后科学家手动与他们合作-建立了额外的质量指标(我们针对不同目标范围计算了MAE),建立了学习曲线(例如,我们排除了部分训练样本并再次训练,检查是否有新数据减少了测试样本和其他图表上的损失。
对一组超参数之一进行详细分析的示例:
详细的质量指标火车设置:
| 测试集:
|
| 对于目标= 0,MAE = 0.142222484602 | 对于0 MAE = 0.141900737761 |
| 对于目标> 0,MAPE = 45.168530676 | 对于> 0 MAPE = 45.5771812826 |
| 错误大于0-67.931341691% | 错误大于0-51.6405939896% |
| 错误大于1-19.0346986379% | 错误大于1-12.1977096603% |
| 错误大于2-8.94313926245% | 错误大于2-5.16977226441% |
| 错误大于3-5.42406856507% | 错误大于3-3.12760834969% |
错误大于4-3.67938161595%
| 错误大于4-2.10263125679% |
错误大于5-2.67322988948%
| 错误大于5-1.56473158807%
|
错误大于6-2.0618556701%
| 错误大于6-1.19599209102%
|
| 错误大于7-1.65887701209% | 错误大于7-0.949300173983%
|
错误大于8-1.36821095777%
| 错误大于8-0.78310772461% |
| 错误大于9-1.15368611519% | 错误大于9-0.659205318158%
|
| 错误大于10-0.99199395014% | 错误大于10-0.554593106723% |
| 错误大于11-0.863969667827% | 错误大于11-0.490045146476%
|
错误大于12-0.764347266082%
| 错误大于12-0.428835873827%
|
| 错误大于13-0.68086818247% | 错误大于13-0.386545830907%
|
| 错误大于14-0.613446089087% | 错误大于14-0.343884822697%
|
错误大于15-0.556297016335%
| 错误大于15-0.316433391328%
|
对于目标= 0,MAE = 0.142222484602
| 对于目标= 0,MAE = 0.141900737761
|
对于目标= 1,MAE = 0.63978556493
| 对于目标= 1,MAE = 0.660823509405 |
| 对于目标= 2,MAE = 1.01528075312 | 对于目标= 2,MAE = 1.01098070566 |
| 对于目标= 3,MAE = 1.43762342295 | 对于目标= 3,MAE = 1.44836233499 |
对于目标= 4,MAE = 1.82790678437
| 对于目标= 4,MAE = 1.86539223382
|
对于目标= 5,MAE = 2.15369976552
| 对于目标= 5,MAE = 2.16017884573 |
对于目标= 6,MAE = 2.51629758129
| 对于目标= 6,MAE = 2.51987403661
|
对于目标= 7,MAE = 2.80225497415
| 对于目标= 7,MAE = 2.97580015564
|
对于目标= 8,MAE = 3.09405048248
| 对于目标= 8,MAE = 3.21914648525
|
对于目标= 9,MAE = 3.39256765159
| 对于目标= 9,MAE = 3.54572928241
|
| 对于目标= 10,MAE = 3.6640339953 | 对于目标= 10,MAE = 3.84409605282
|
对于目标= 11,MAE = 4.02797747118
| 对于目标= 11,MAE = 4.21828735273
|
对于目标= 12,MAE = 4.17163467899
| 对于目标= 12,MAE = 3.92536509115
|
对于目标= 14,MAE = 4.78590364522
| 对于目标= 14,MAE = 5.11290428675 |
对于目标= 15,MAE = 4.89409916994
| 对于目标= 15,MAE = 5.20892023117
|
火车损失= 0.535842111392
测试损失= 0.895529959873
如果不匹配,请再次随机搜索。 这就是我们以工业节奏训练模型5到5天的方式。 我们正在值班,有人在晚上,有人在早晨醒来,查看了前10个参数,重新启动或保存了模型,然后上床睡觉了。 在这种模式下,我们工作了一周,训练了130种模型-13种商品和10种预测深度,每种模型都有170个特征。 5倍时间序列cv的平均MAE等于1。
似乎这不是很酷-确实如此,除非您在单位选择中占很大比例。 根据对结果的分析,可以预测所有产品中最差的一个-每周购买一次产品这一事实并不能说明是否有需求。 一旦任何东西都可以出售-会有人以牙医的形式购买瓷器,而这并没有说明未来的销售或过去的销售。 总的来说,我们对此并不感到很沮丧。
技巧与窍门
出了什么问题,如何避免呢?
第一个问题是参数的选择。 我们开始使用RandomizedSearchCV-一种来自sklearn的知名工具,用于对超参数进行排序。 这是我们第一个惊喜的地方。
像这样from sklearn.model_selection import ParameterSampler
from sklearn.model_selection import RandomizedSearchCV
estimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=72)
param_grid = {'boosting_type': boosting_type, 'num_leaves': num_leaves, 'max_depth': max_depth, 'learning_rate':learning_rate, 'n_estimators': n_estimators, 'subsample_for_bin': subsample_for_bin, 'min_child_samples': min_child_samples, 'colsample_bytree': colsample_bytree, 'reg_alpha': reg_alpha, 'max_bin': max_bin}
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=1, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
计算只是停顿了(重要的是,它不会下降,但是会继续起作用,但是在越来越少的内核上,并且有时它会停止)。
由于RandomizedSearchCV,我不得不并行处理estimator = lightgbm.LGBMRegressor(application='regression_l1', is_training_metric = True, objective = 'regression_l1', num_threads=1)
rscv = RandomizedSearchCV(estimator, param_grid, refit=False, n_iter=100, scoring='neg_mean_absolute_error', n_jobs=72, cv=10, verbose=3, pre_dispatch='1*n_jobs', error_score=-1, return_train_score='warn')
rscv .fit(X_train.values, y_train['target'].values)
print('Best parameters found by grid search are:', rscv.best_params_)
但是,RandomizedSearchCV几乎为每个“职位”获取了整个数据集。 因此,有必要大大扩展RAM的数量,可能会牺牲内核的数量。
谁能告诉我们有关hyperopt之类的奇妙事物呢! 既然我们学会了,我们只会使用它。
在项目接近尾声时,我们想到的另一个技巧是选择具有colsample_bytree参数(这是LightGBM参数,该参数表示要赋予每个角色的特征百分比)的模型在0.2-0.3范围内,因为它可以在生产中使用,可能没有任何表格,并且可能无法正确计算单个功能。 通过这种正则化,您可以确保这些未说明的功能至少不会影响模型中的所有提示。
从经验上,我们得出的结论是,我们需要做更多的估计,并且更难地扭曲正则化。 这不是LightGBM的工作规则,但这种方案对我们有用。
好吧,当然还有Spark。 例如,Spark本身就有一个错误:如果您从一个表中获取几列并创建一个新列,然后从同一表中获取其他列并创建一个新列,然后对收到的表进行调优,那么一切都会中断,尽管它不会这样做。 只有摆脱所有懒惰的计算,您才能被保存。 我们甚至编写了一个特殊功能bumb_df,它将数据帧转换为RDD,然后又转换为数据帧。 也就是说,它将重置所有惰性计算。 这样可以保护自己免受大多数Spark问题的困扰。
bumb_dfdef bump_df(df):
# to avoid problem: AnalysisException: resolved attribute(s)
df_rdd = df.rdd
if df_rdd.isEmpty():
df = df_rdd.toDF(schema=df.schema)
return df
else:
return df_rdd.toDF(schema=df.schema)
预测已准备就绪:我们将订购多少?
预测销售额是纯粹的数学任务,如果零均值误差的正态分布是数学家的胜利,那么对于帐目上有卢布的商人来说,这是不可接受的。
如果在仓库中再买一部iPhone或一件时髦的衣服不是问题,而是保险库存,那么在仓库中缺少同一部iPhone至少会损失利润,最大程度地损失图像,这是不允许的。
为了教该算法根据需要购买更多商品,我们必须计算每种产品的再购买和购买不足的成本,并训练一个简单的模型,以最大程度地减少可能的金钱损失。
该模型在输入时接收销售预测,并向其添加随机的,正态分布的噪声(我们模拟供应商的缺陷),并学会为每种特定产品准确地将预测增加多少,以最大程度地减少金钱损失。
因此,订单是预测+安全存货,可保证覆盖预测错误和外界的不完美之处。
如产品
Ozon拥有自己的大型计算集群,每天晚上都会在该集群上启动来自15个以上工作的管道(我们使用气流)。 看起来像这样:

每天晚上,该算法都会启动,将来自各种来源的大约20 GB数据提取到本地hdfs中,为每种产品选择一个供应商,为每种产品收集功能,做出销售预测并根据交货计划生成订单。 到凌晨6点至7点,我们将负责与供应商合作的现成桌子交给工作人员,这些工作人员只需单击供应商按钮即可飞走。
没有一个预测
经过训练的模型可以知道预测对任何功能的依赖关系,因此,如果冻结N-1个符号并开始更改一个符号,则可以观察到它如何影响预测。 当然,最有趣的是销售如何取决于价格。
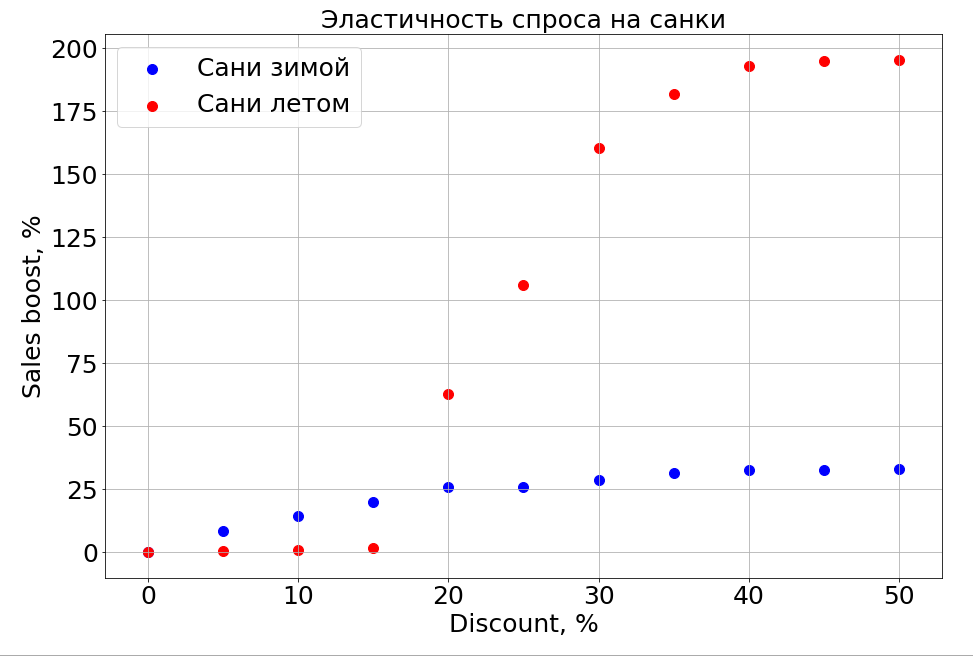
重要的是要注意,需求不仅取决于价格。 例如,如果您在夏天对雪橇打折,则仍无济于事。 我们正在提供更多折扣,并且出现了“在夏天准备雪橇”的人。 但是,除非有一定程度的折扣,否则我们仍然无法到达负责计划的大脑部分。 在冬季,它适用于所有产品-您可以打折,并且销售更快。
计划
现在,我们正在积极研究时间序列的聚类,以便根据描述其销售的曲线的性质在聚类之间分配商品。 例如,季节性,传统上在夏季流行,或者相反,在冬季流行。 当我们学习如何分离具有悠久销售历史的产品时,我们计划重点介绍基于项目的功能,这些功能将告诉您新的刚刚出现的产品的销售模式是什么-目前,这是我们的主要任务。
神经网络和时间序列的参数模型,以及所有这些,肯定会更进一步。
特别是,由于采用了新的预测系统,当我们从一种供应向另一种供应购买而不存储库存余额时,Ozon从购买有库存商品转变为周期性交货。
现在,我们必须决定如何教授该算法来预测新产品和整个类别的销售额。 明年,该公司计划在类别中增加x10销售额,在实现方面增加x2.5。 我们需要告诉模型这些旧数据是相关的,但是对于不同的过去存储。 当我们正在考虑如何做时。
我们必须学会预测的天生第二不理性的事物是时尚。 一个人怎么能预测纺纱厂会这样卖呢? 如果Dan Brown的一本书售罄而另一本书没有售罄,该如何预测Dan Brown的新书销量? 当我们正在努力的时候。
如果您知道如何做得更好,或者您在评论中有关于在战斗中使用机器学习的故事,我们将进行讨论。