今天,在有关大数据的专题国外网站上,您可以找到针对Apache Hadoop等相对较新的Hadoop生态系统工具。 这是现代的开源ETL工具。 用于快速并行加载和数据处理的分布式体系结构,用于源和转换的大量插件,配置版本控制只是其优势的一部分。 NiFi具有所有功能,仍然相当易于使用。
Rostelecom的我们努力开发Hadoop,因此我们已经尝试并欣赏了Apache NiFi与其他解决方案相比的优势。 在本文中,我将告诉您该工具如何吸引我们以及我们如何使用它。
背景知识
不久前,我们面临选择从外部源将数据加载到Hadoop集群中的解决方案的选择。 长期以来,我们使用
Apache Flume解决了此类问题。 除了一些不适合我们的观点外,没有对整个Flume提出抱怨。
作为管理员,我们不喜欢
的第一件事是编写Flume配置文件以执行下一个琐碎的下载工作不会委托给没有沉迷于此工具复杂性的开发人员或分析师。 连接每个新资源都需要管理团队的强制干预。
第二点是容错和扩展。 例如,对于大量下载,例如通过syslog,有必要配置多个Flume代理并在它们前面设置一个均衡器。 一旦发生故障,所有这些都必须以某种方式进行监视和恢复。
第三 ,Flume不允许从各种DBMS下载数据以及开箱即用其他协议。 当然,在广阔的网络中,您可以找到使Flume与Oracle或SFTP协同工作的方法,但是支持这种自行车并不令人愉快。 要从同一个Oracle加载数据,我们必须使用另一个工具
-Apache Sqoop 。
坦白说,从我的天性来看,我是一个懒惰的人,我根本不想支持所有的解决方案。 我不希望所有这些工作都必须由我自己完成。
当然,在ETL工具市场中,有很多功能强大的解决方案可以与Hadoop一起使用。 其中包括Informatica,IBM Datastage,SAS和Pentaho Data Integration。 这些是研讨会上最常听到的同事,也是最先想到的。 顺便说一下,我们在数据仓库类的解决方案上使用IBM DataStage for ETL。 但是从历史上来看,我们的团队无法使用DataStage在Hadoop中进行下载。 同样,我们不需要此级别的解决方案的全部功能来执行相当简单的转换和数据下载。 我们需要的是一种具有良好开发动态的解决方案,能够与多种协议一起使用,并且具有便捷直观的界面,不仅了解其所有细微之处的管理员都能够处理,而且具有分析师的开发人员(通常适合我们)数据本身的客户。
从标题中可以看出,我们使用Apache NiFi解决了上述问题。
什么是Apache NiFi
NiFi名称来自“ Niagara文件”。 该项目是由美国国家安全局开发的,历时8年。2014年11月,该项目的源代码被开放,并作为
NSA技术转让计划的一部分移交给了Apache软件基金会。
NiFi是一种开放源代码的ETL / ELT工具,不仅可以与大数据和数据仓库类一起使用,而且可以与许多系统一起使用。 以下是其中一些:HDFS,Hive,HBase,Solr,Cassandra,MongoDB,ElastcSearch,Kafka,RabbitMQ,Syslog,HTTPS,SFTP。 您可以在官方
文档中看到完整列表。
通过添加适当的JDBC驱动程序来实现与特定DBMS的配合。 有一个API可将您的模块编写为其他接收器或数据转换器。 示例可以在
这里和
这里找到。
主要特点
NiFi使用Web界面创建DataFlow。 最近开始与Hadoop合作的一名分析师,一名开发人员和一个有胡子的管理员将对此进行应对。 最后两个不仅可以与“矩形和箭头”进行交互,还可以与用于收集统计信息,监视和管理DataFlow组件的
REST API进行交互。
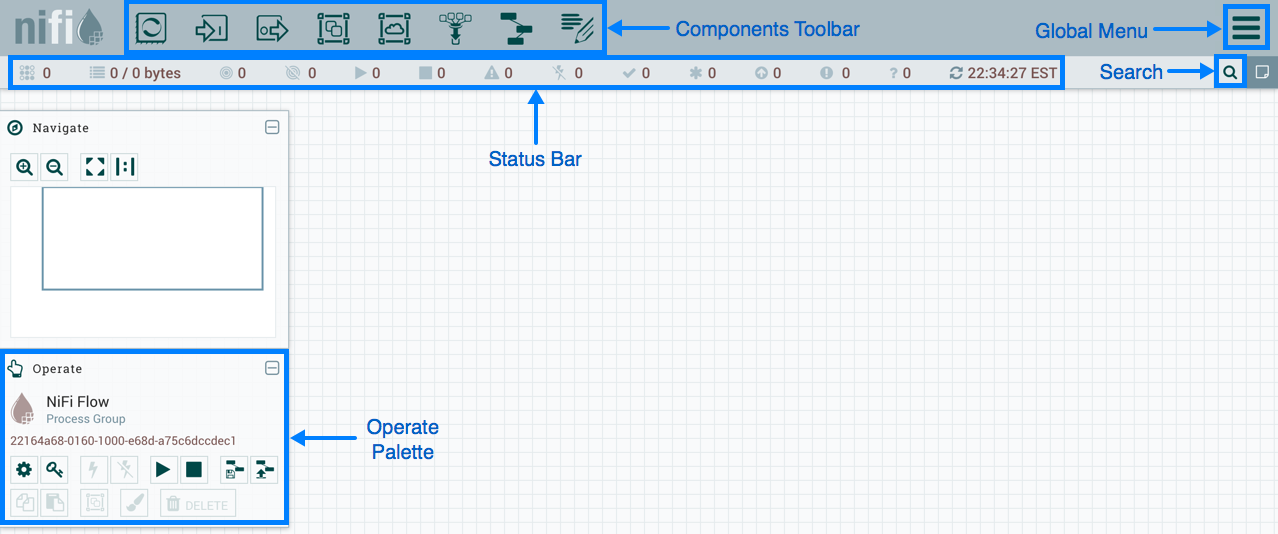 NiFi基于网络的管理
NiFi基于网络的管理下面,我将显示一些用于执行一些常见操作的DataFlow示例。
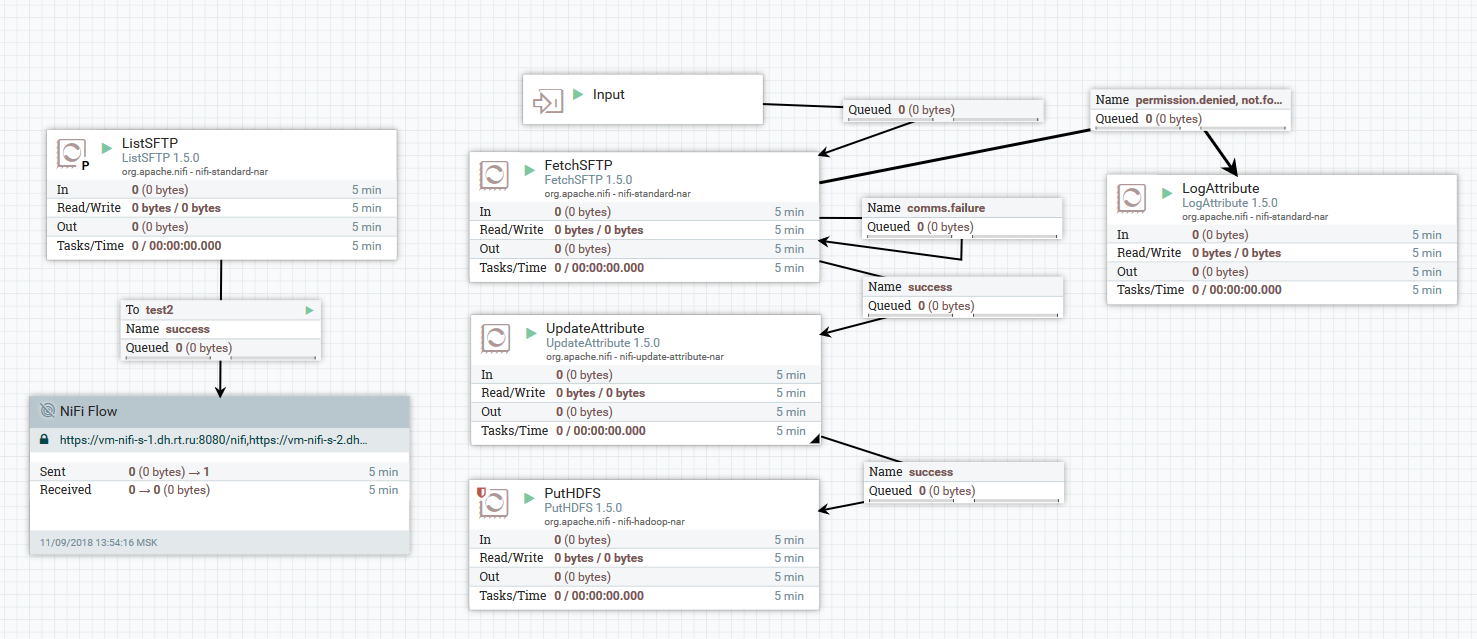 将文件从SFTP服务器下载到HDFS的示例
将文件从SFTP服务器下载到HDFS的示例在此示例中,ListSFTP处理器在远程服务器上执行文件列表。 此清单的结果由FetchSFTP处理器用于群集中所有节点的并行文件加载。 之后,将属性添加到每个文件中,这些文件是通过解析其名称获得的,然后在将文件写入最终目录时由PutHDFS处理器使用。
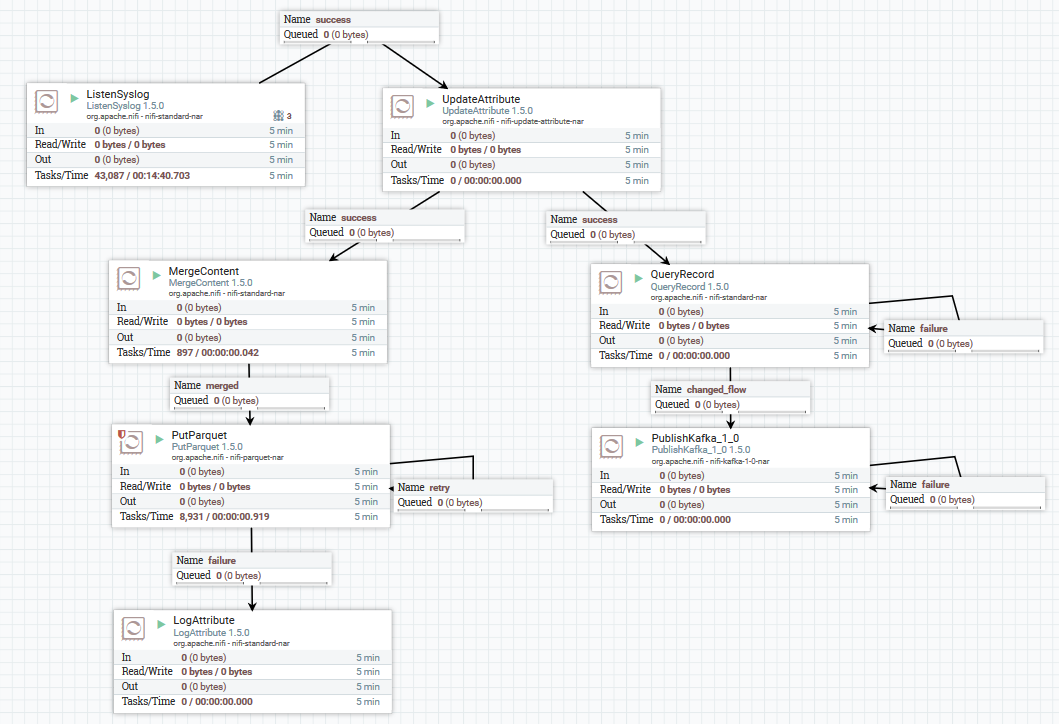 在Kafka和HDFS中下载系统日志数据的示例
在Kafka和HDFS中下载系统日志数据的示例在这里,使用ListenSyslog处理器,我们获得了输入消息流。 然后,将有关它们到达NiFi的时间和Avro Schema Registry中方案名称的属性添加到每个消息组。 接下来,将第一个分支发送到QueryRecord处理器的输入,该处理器根据指定的方案读取数据并使用SQL对其进行解析,然后将其发送到Kafka。 第二个分支发送到MergeContent处理器,该处理器将数据聚合10分钟,然后将其传递到下一个处理器,以转换为Parquet格式并记录到HDFS。
这是一个示例您如何可以其他方式设置DataFlow的示例:
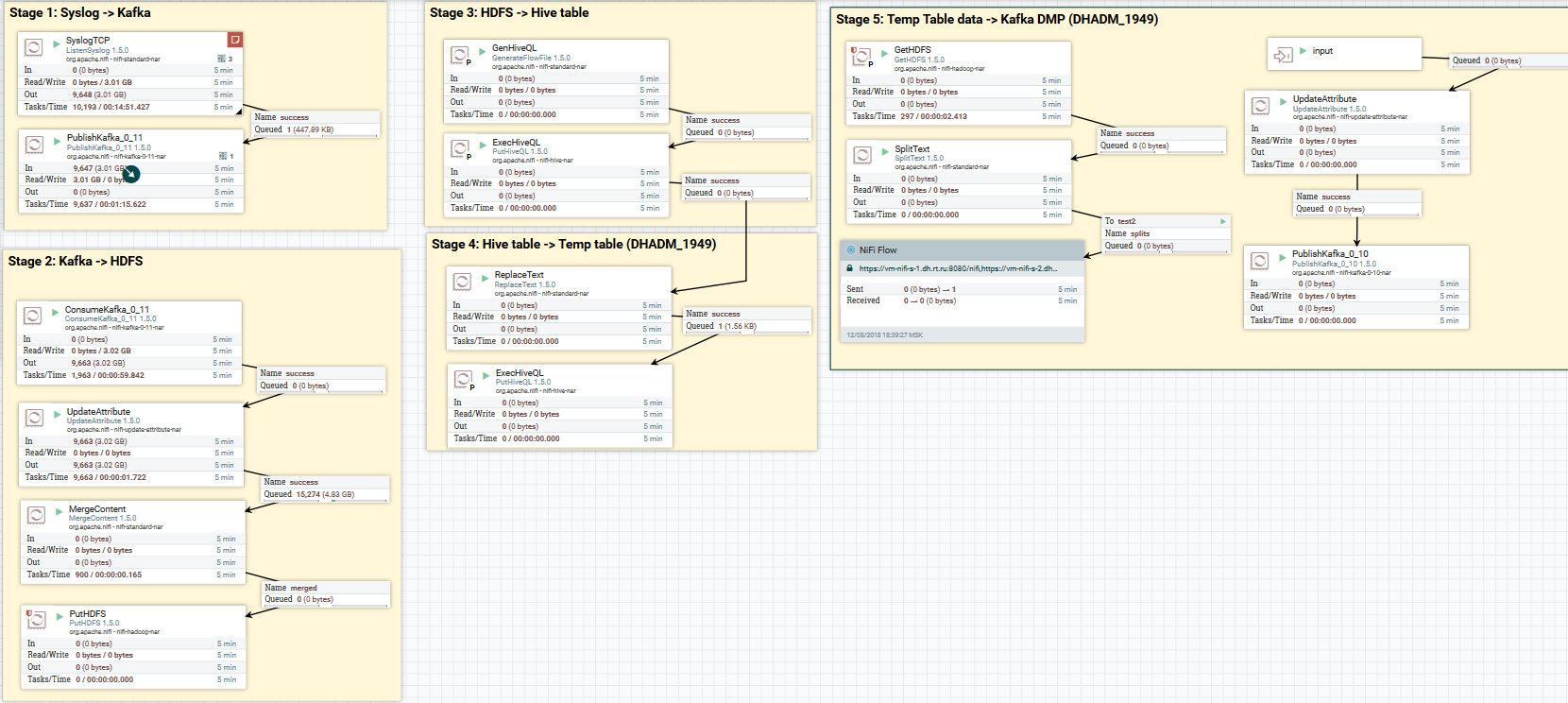 将系统日志数据下载到Kafka和HDFS。 清除Hive中的数据
将系统日志数据下载到Kafka和HDFS。 清除Hive中的数据现在介绍数据转换。 NiFi允许您使用常规数据解析数据,对其执行SQL,过滤和添加字段,以及将一种数据格式转换为另一种格式。 它还具有自己的表达语言,其中包含各种运算符和内置函数。 有了它,您可以向数据添加变量和属性,比较和计算值,稍后在形成各种参数时使用它们,例如在Hive中写入HDFS或SQL查询的路径。
在这里阅读更多。
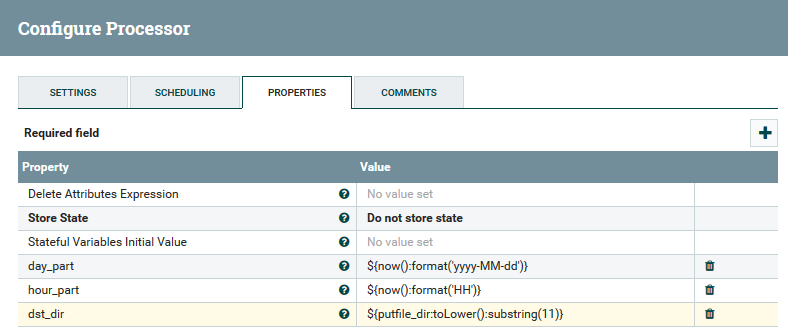 在UpdateAttribute处理器中使用变量和函数的示例
在UpdateAttribute处理器中使用变量和函数的示例用户可以跟踪数据的完整路径,观察其内容和属性的变化。
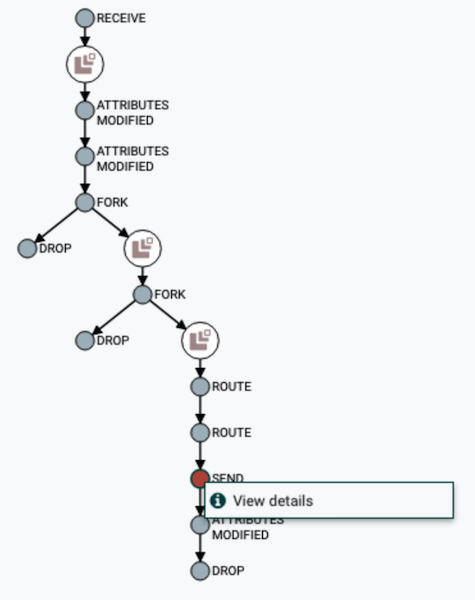 DataFlow链可视化
DataFlow链可视化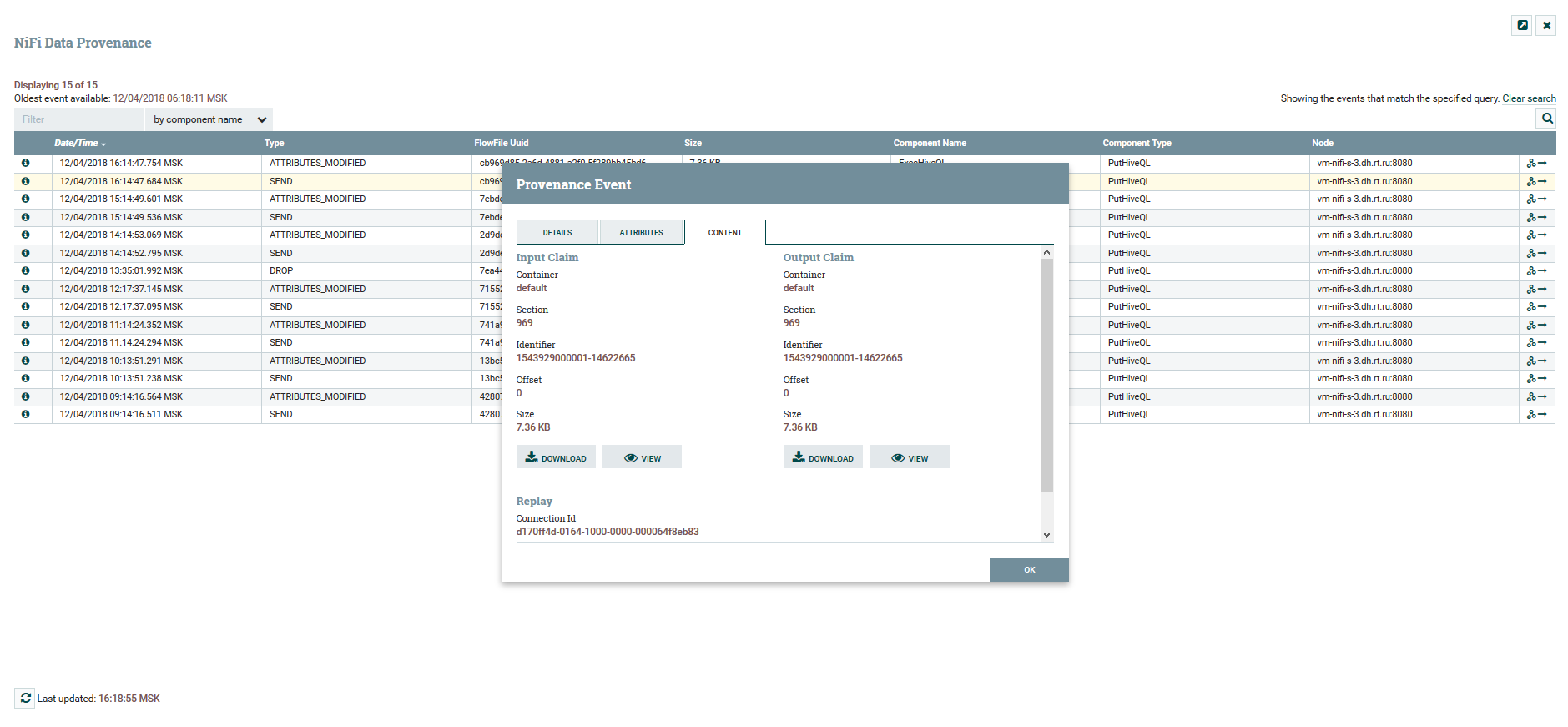 查看内容和数据属性
查看内容和数据属性要对DataFlow进行版本控制,有一个单独的
NiFi Registry服务。 通过设置,您可以管理更改。 您可以运行本地更改,回滚或下载任何以前的版本。
 版本控制菜单
版本控制菜单在NiFi中,您可以控制对Web界面的访问以及用户权限的分离。 当前支持以下身份验证机制:
不支持同时使用多种机制。 要授权系统中的用户,请使用FileUserGroupProvider和LdapUserGroupProvider。
在此处阅读有关此内容的更多信息。
如我所说,NiFi可以在群集模式下工作。 这提供了容错能力,并实现了水平负载缩放。 没有静态固定的主节点。 相反,
Apache Zookeeper选择一个节点作为协调器,并选择一个作为主要节点。 协调器从其他节点接收有关其状态的信息,并负责它们与集群的连接和断开连接。
主节点用于启动隔离的处理器,这些处理器不应同时在所有节点上运行。
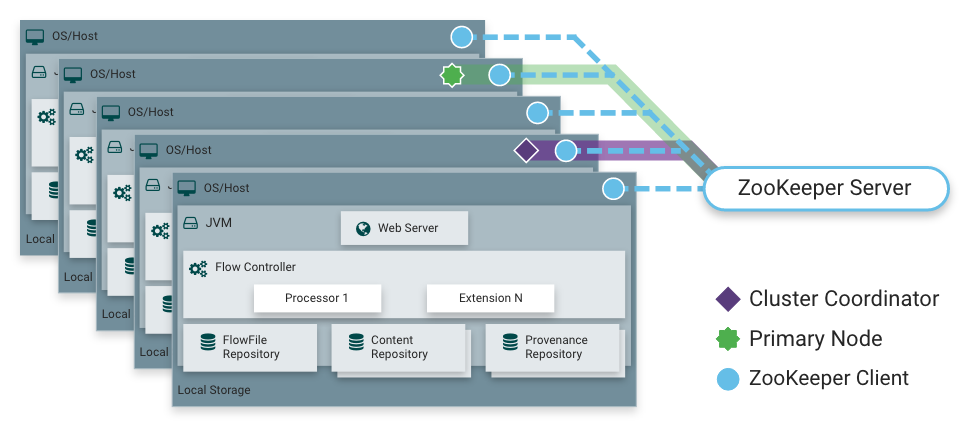 集群中的NiFi操作
集群中的NiFi操作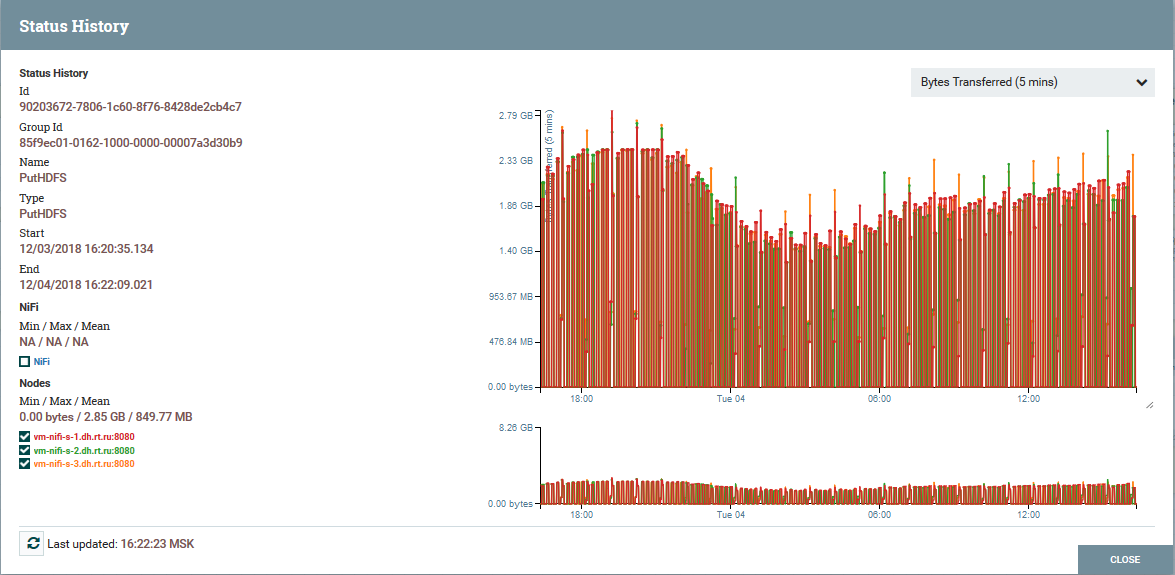 以PutHDFS处理器为例,集群节点的负载分配
以PutHDFS处理器为例,集群节点的负载分配NiFi架构和组件的简要说明
 NiFi实例架构
NiFi实例架构NiFi基于“基于流的编程”(
FBP )的概念。 以下是每个用户遇到的基本概念和组件:
FlowFile-代表对象的实体,该对象的内容从零个或多个字节开始,并包含其对应的属性。 这可以是数据本身(例如,Kafka消息流),也可以是处理器的结果(例如,PutSQL),它不包含数据本身,而仅包含查询结果生成的属性。 属性是FlowFile元数据。
FlowFile Processor正是在NiFi中完成基本工作的本质。 通常,处理器具有使用FlowFile的一项或多项功能:创建,读取/写入和更改内容,读取/写入/更改属性,路由。 例如,ListenSyslog处理器使用syslog协议接收数据,并使用syslog.version,syslog.hostname,syslog.sender等属性创建FlowFiles。 RouteOnAttribute处理器读取输入FlowFile的属性,并根据属性的值决定将其重定向到与另一个处理器的适当连接。
连接 -提供flowFile连接并在各种处理器和某些其他NiFi实体之间进行传输。 Connection将FlowFile放入队列中,然后将其沿链向下传递。 您可以配置如何从队列中选择FlowFiles,它们的生存期,队列中所有对象的最大数量和最大大小。
进程组 -一组处理器,它们的连接和其他DataFlow元素。 它是一种将许多组件组织成一个逻辑结构的机制。 帮助简化对DataFlow的理解。 输入/输出端口用于接收和发送来自过程组的数据。
在此处阅读有关其用法的更多信息。
NiFi可以在
FlowFile信息库中存储有关系统中每个现有FlowFile的所有已知信息。
内容存储库 -所有FlowFiles内容所在的存储库,即 传输的数据本身。
来源存储库 -包含有关每个FlowFile的故事。 每当FlowFile发生事件(创建,更改等)时,相应的信息都会输入到此存储库中。
Web服务器 -提供Web界面和REST API。
结论
借助NiFi,Rostelecom能够改善将数据传输到Hadoop上的Data Lake的机制。 通常,整个过程变得更加方便和可靠。 今天,我可以自信地说NiFi非常适合下载到Hadoop。 我们的运作没有问题。
顺便说一下,NiFi是Hortonworks Data Flow发行版的一部分,由Hortonworks本身积极开发。 他还有一个有趣的Apache MiNiFi子项目,可让您从各种设备收集数据并将其集成到NiFi中的DataFlow中。
关于NiFi的其他信息
也许就这些。 谢谢大家的关注。 如有疑问,请在评论中写。 我会很高兴地回答他们。