
在本周初,Kubernetes
的下一个发行版本被称为“天使”
1.13 。 该名称与编号113相关联,
被认为是 “天使”,据Kubernetes开发人员称,它表示“新章节的开始,转换和结尾,然后再打开新章节”。 根据已经为我们的博客建立的传统,无需进一步分析正在发生的事情的象征意义,我们将第七次谈论新版本的Kubernetes的主要变化,这些变化旨在使使用此产品的DevOps // SRE工程师满意。
作为信息来源,我们使用了来自
Kubernetes增强跟踪 ,
CHANGELOG-1.13表和相关问题,拉取请求,Kubernetes增强提案(KEP)的数据。
适用于kubeadm的GA
Kubernetes 1.13发行版的主要事件之一是宣布
kubeadm控制台实用程序处于稳定状态(通用可用性,GA)。 K8s博客甚至
为此专门
撰写了
单独的出版物 。 众所周知,kubeadm是根据项目的最佳实践及其最小支持来创建Kubernetes集群的工具。 开发人员的一个独特功能是努力使它保持紧凑并独立于提供者/基础架构,不包括诸如供应基础架构,第三方网络解决方案,附加组件(监视,日志记录等),与云的特定集成等问题的解决方案提供者。
GA地位标志着kubeadm在以下领域的成熟:
- 遵循Kubernetes淘汰策略的稳定控制台界面:GA版本中显示的命令和标志在弃用后必须至少支持一年;
- 由于集群是由在不久的将来不会改变的方法创建的事实,因此“在幕后”实现了稳定的实现:控制平面启动了许多静态Pod, bootstrap令牌用于
kubeadm join ,而ComponentConfig用于配置kubelet; - 具有新API(v1beta1)的配置方案,该API可以声明性地描述几乎所有集群组件(使用kubeadm创建的集群可以使用GitOps)-计划升级至v1,而无需进行任何更改或进行最少的更改;
- kubeadm中的所谓阶段 (或工具箱界面)(
kubeadm init phase ),允许您选择要执行的初始化过程; kubeadm upgrade团队保证在版本1.10.x,1.11.x,1.12.x和1.13.x(更新etcd,API Server,Controller Manager和Scheduler)之间进行集群更新;- 默认情况下安全地安装etcd(它在所有地方都使用TLS),并可以在必要时扩展到HA群集。
还应该指出,kubeadm现在可以正确识别Docker 18.09.0及其更高版本。 最后,开发人员要求kubeadm用户进行小型
在线调查 ,他们可以在其中表达他们对项目的使用和开发的意愿。
默认情况下为CoreDNS
在
Kubernetes 1.11版本中获得稳定状态的
CoreDNS进一步发展,并
成为 K8s中
的默认DNS服务器(而不是到目前为止使用的kube-dns)。 计划最早在1.12发生这种情况,但是开发人员面临着对可伸缩性和内存消耗进行其他优化的需求,这些优化仅在当前版本中才能完成。

对kube-dns的支持将“至少在下一个版本中继续”,但是开发人员正在谈论现在需要
开始迁移到最新解决方案的需求 。
在Kubernetes 1.13中与CoreDNS主题相关的更改中,还
可以注意到 NodeLocal DNS Cache插件可以提高DNS性能。 通过在群集节点上为DNS缓存运行代理可以实现改进,该代理的Pod将直接访问该代理。 默认情况下,该功能处于禁用状态,要激活该功能,必须设置
KUBE_ENABLE_NODELOCAL_DNS=true 。
仓储设施
在Kubernetes的最新版本中,很多注意力都集中在使用
容器存储接口 (CSI)上,该
容器存储在
K8s 1.9中以CSI的Alpha版本开始,以
1.10的Beta版本继续...但是,我们已经
不止一次地对此进行了介绍。 K8s 1.13达到了一个重要的新里程碑:
CSI支持被宣布为稳定 (GA)。
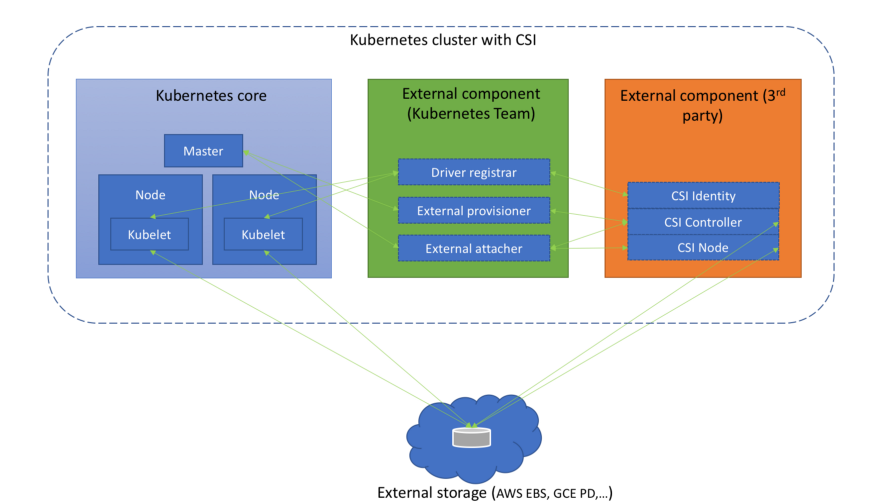 (图来自“ 了解容器存储接口 ”一文)
(图来自“ 了解容器存储接口 ”一文)同时,出现了对CSI规范v1.0.0的支持,并且不支持该标准的较早版本(0.3和更早版本)。 这意味着较旧的CSI驱动程序将需要升级到CSI 1.0(并移至新的Kubelet插件注册目录),才能在Kubernetes 1.15和更早版本中工作。 顺便说一句,从驱动程序本身来看,值得注意的是用于管理AWS EBS卷(弹性块存储)生命周期的CSI接口
的 alpha版本。
如果激活了以下两个功能门中的至少一个:
CSIDriverRegistry和
CSINodeInfo ,则附加组件管理器的新功能现在会自动从CSI安装CRI。 它具有alpha版本的状态,但实际上,它只是该问题的临时解决方案,详细描述为
CRD安装机制 。
在
Kubernetes 1.10版本的上下文中讨论的基于拓扑的卷计划(
Topology Aware Volume Scheduling )已
变得稳定 。 简而言之,调度程序在其工作中考虑了pod的拓扑结构的局限性(例如,其区域和节点)。
Kubernetes 1.9中引入的将永久性卷用作
块原始设备 (而非网络)的
机会 已转换为beta,并且现在默认启用。
我们以
声明对GCERegionalPersistentDisk的支持稳定的事实结束了存储主题。
集群节点
引入了
对第三方设备监视插件的alpha版本
支持 。 该计划背后的想法是从Kubelet
的树中挖掘
出特定于设备的知识。 集群管理员将在容器级别接收由设备插件报告的指标,制造商将能够创建这些指标,而无需更改Kubernetes核心。 可以在提案中找到实现的详细信息,该提案称为
Kubelet Metadata API 。
声明为稳定的
Kubelet插件观察程序 (也称为Kubelet设备插件注册) ,它允许节点级插件(设备插件,CSI和CNI)与Kubelet进行自身通信。
处于alpha状态的新功能是
NodeLease 。 如果之前节点的“心跳”是由NodeStatus决定的,则具有新功能,每个节点都有一个与其关联的
Lease对象(在
kube-node-lease名称空间中),该节点将定期更新该对象。 现在,“脉冲”由两个参数设置:旧的NodeStatus(仅在发生更改或固定超时(默认为每分钟一次)时才报告给主服务器)和新对象(频繁更新)。 由于此对象非常小,因此将大大提高可伸缩性和性能。 作者着手在测试大小超过2000个节点的集群之后开始创建一个新的“脉冲”,这在他们的工作中可能会超出etcd的限制,有关更多详细信息,请参阅
KEP-0009 。
type Lease struct { metav1.TypeMeta `json:",inline"` // Standard object's metadata. // More info: https://git.k8s.io/community/contributors/devel/api-conventions.md#metadata // +optional ObjectMeta metav1.ObjectMeta `json:"metadata,omitempty"` // Specification of the Lease. // More info: https://git.k8s.io/community/contributors/devel/api-conventions.md#spec-and-status // +optional Spec LeaseSpec `json:"spec,omitempty"` } type LeaseSpec struct { HolderIdentity string `json:"holderIdentity"` LeaseDurationSeconds int32 `json:"leaseDurationSeconds"` AcquireTime metav1.MicroTime `json:"acquireTime"` RenewTime metav1.MicroTime `json:"renewTime"` LeaseTransitions int32 `json:"leaseTransitions"` }
(用于表示节点“脉冲”的新对象的紧凑规范LeaderElectionRecord与LeaderElectionRecord相同)安全性
动态审核控制的Alpha版本遵循动态准入控制的思想,并提供高级审核功能的动态配置-为此,您现在可以(动态)注册将接收事件流的Webhook。 Kubernetes审核提供了非常强大的功能,但它们很难配置,并且每次配置更改仍需要重新启动apiserver,这一事实解释了对该功能的需求。
etcd中的数据加密 (请参阅官方文档 )已从实验状态转换为Beta。
kind: EncryptionConfiguration apiVersion: apiserver.config.k8s.io/v1 resources: - resources: - secrets providers: - identity: {} - aesgcm: keys: - name: key1 secret: c2VjcmV0IGlzIHNlY3VyZQ== - name: key2 secret: dGhpcyBpcyBwYXNzd29yZA== - aescbc: keys: - name: key1 secret: c2VjcmV0IGlzIHNlY3VyZQ== - name: key2 secret: dGhpcyBpcyBwYXNzd29yZA== - secretbox: keys: - name: key1 secret: YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXoxMjM0NTY=
(带有加密数据的示例配置来自文档 。)在该类别中次重要的创新中:
- 现在, 可以将 apiserver 配置为拒绝无法进入审核日志的请求。
- 添加了
PodSecurityPolicy对象PodSecurityPolicy 并支持fsGroup和supplementalGroups选项的MayRunAs规则,该规则允许为pod /容器定义允许的组标识符(GID)的范围,而无需强制使用默认GID。 此外,借助PodSecurityPolicy ,现在可以在pod的规范中使用RunAsGroup策略,即 您可以控制容器的主GID。 - 对于kube-scheduler,我们用新的安全端口(10259) 替换了以前的不安全端口(10251),并默认将其打开。 如果未指定其他标志,则在加载时会在内存中为其创建自签名证书。
命令行界面
显示本地配置和工作对象的当前描述(对于带有配置的目录有效且递归)之间
的区别的
kubectl diff 处于 beta状态。
实际上,
diff “预测”了将使用
kubectl apply进行的更改,并且使用了另一个新功能
-APIServer DryRun 。 它的本质-空闲启动-应该从名称中清除,并且
Kubernetes文档中提供了更详细的描述。 顺便说一下,在1.13版中,DryRun功能也已“升级”到Beta版本,并且默认情况下处于打开状态。
Kubernetes控制台世界中beta版的另一项进步影响了
新的插件机制 。 在此过程中,他们
更正了插件输出
的顺序(
kubectl plugin list ),从那里删除了其他排序。
另外,将使用过的
临时存储资源的输出
添加到
kubectl describe node ,并将
投影类型的卷
添加到
kubectl describe pod 。
其他变化
基于污染的逐出调度程序功能已转换为beta状态,经过
长时间的开发后默认情况下已启用。 其目的是在出现某些情况时(例如,node.kubernetes.io/not-ready)自动将
污点添加到节点(通过NodeController或kubelet),该条件对应于
Ready=False的
NodeCondition值。
不推荐用于群集操作的关键Pod的注释-Critical
critical-pod 。 相反,建议使用
优先级 (在Kubernetes 1.11的beta中) 。
对于AWS首次(作为alpha版本的一部分),以下功能可用:
SIG Azure实施了对Azure磁盘(超SSD,标准SSD和Premium Azure文件)的额外支持,并将
Cross资源组节点提升为beta。 此外,用于Windows的CNI插件现在可以在容器中配置DNS。
相容性
- etcd版本为3.2.24(自Kubernetes 1.12起未更改)。
- Docker的验证版本-1.11.1、1.12.1、1.13.1、17.03、17.06、17.09、18.06(也未更改)。
- Go版本-1.11.2,与支持的最低版本一致。
- CNI版本是0.6.0。
- CSI版本为1.0.0。
- CoreDNS版本是1.2.6。
聚苯乙烯
另请参阅我们的博客: