
DeepMind创建了真正令人惊叹的算法,该算法能够实现以前机器系统无法实现的功能。 特别是神经网络
AlphaGo能够击败世界上最好的球员。 根据专家的说法,现在该系统的功能已经发展得如此之快,以至于试图击败它甚至都没有道理-结果是预先确定的。
尽管如此,该公司并不止于此,而是继续工作。 由于对其员工的研究,诞生
了改进版本的AlphaGo,称为AlphaZero。 如标题所示,系统本身能够学习如何同时玩三个逻辑游戏-国际象棋,将棋和围棋。
新版本与以前的所有版本之间的区别在于,系统本身可以学习几乎所有内容。 她从零开始,很快学会了完美玩三局游戏。 没有人帮助过AlphaZero-该系统“独自完成了一切”。
象棋是包括在游戏中的,而是按照传统-教计算机如何下棋并不难,不是。 1950年代第一次将计算机系统引入游戏。 然后,已经在60年代,创建了
Mac Hack IV程序,该程序开始击败人类竞争对手。 随着时间的推移,国际象棋程序逐渐得到改善,1997年IBM开发了“象棋计算机”深蓝,成功击败了Grandmaster和世界冠军Garry Kasparov。
正如他本人指出的那样,目前智能手机上的许多应用程序比国际象棋深蓝更好地下棋。 在创建可以下棋的系统的过程中取得了完美的成就之后,开发人员开始创建新版本的人类计算机竞争对手-尤其是,他们设法教会了计算机玩棋游戏。 以前,这种具有一千多年历史的游戏被认为是计算机“理解”中最难获得的游戏之一。 但是时代变了。 如上所述,AlphaGo掌握了很高的围棋游戏技巧,因此没有人站在附近。
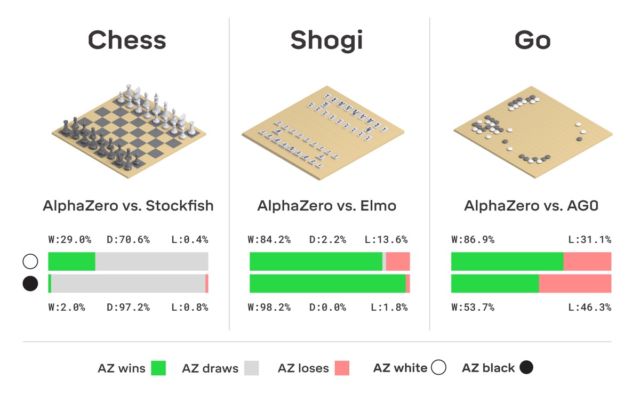
顺便说一下,今年AlphaGo收到了更新,借助该更新,神经网络现在可以在无需人工干预的情况下学习各种打球策略。 一次又一次地玩耍,AlphaGo不断进步。 AlphaGo的“后裔”使用的就是这种训练系统-AlphaZero神经网络。 在短短的三天内,她在Go方面达到了精通的水平,以100到0的分数击败了原始版本的AlphaGo。系统最初收到的唯一内容是游戏规则。
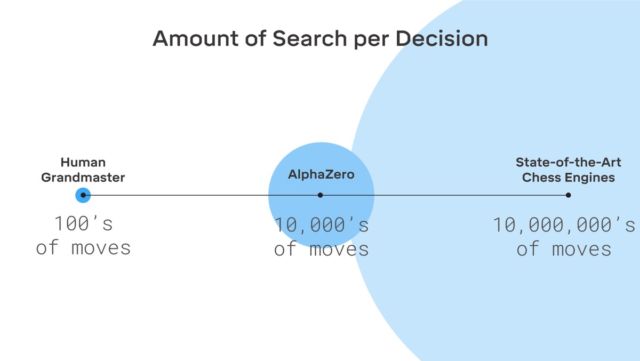
这里没有虚构,DeepMind使用了著名的强化机器学习系统。 计算机寻求获胜,因为每次获胜都会得到奖励(积分)。 此外,AlphaZero在学习过程中损失了数百万种组合。 AlphaZero仅花费0.4秒来错误计算下一步,并评估获胜的可能性。 至于原始版本的AlphaGo,神经网络由两个元素组成,两个神经网络-一个确定了下一个可能的动作,第二个计算了概率。
为了达到Go AlphaZero的大师级水平,您需要独自滚动“滚动”约450万个游戏。 但是AlphaGo需要3000万游戏。
值得注意的是,AlphaZero是专门为玩go而创建的。 该公司没有忘记这一点。 但是除此之外,该系统还能够学习上面提到的另外两个游戏。 使用的系统是相同的-具有增强功能的机器学习。 值得注意的是,AlphaZero仅适用于具有一定数量解决方案的任务。 该系统还需要一个环境模型(虚拟)。
有趣的是,卡斯帕罗夫本人相信一个人可以从像AlphaGo这样的系统中学到很多东西-您可以从中学到很多东西。
当前,开发人员面临着这样的任务:教导计算机比任何人都更好的玩扑克,还创建一种可以在公平竞争中击败任何电子竞技者的系统。 无论如何,很明显,神经网络和AI具有很多功能。