
去年12月,关于AlphaZero人工智能公司DeepMind使用新型国际象棋引擎的强大功能
的新闻热潮不断。 今天,他们发布了该引擎更新版本的惊人结果。
结果再次毫无疑问,AlphaZero是世界上最强大的国际象棋引擎之一。
更新的AlphaZero在一场新比赛中以1000场比赛击败了Stockfish 8,结果是:155胜6负,平局839。
AlphaZero在一系列具有不平等时间控制的游戏中也击败了Stockfish,即使让分了10次,也击败了传统引擎。
根据DeepMind的说法,在其他比赛中,新的AlphaZero在2018年1月13日超越了Stockfish的“最新开发版本”,显示出几乎与对Stockfish 8比赛相同的结果。
根据DeepMind的说法,他们的机器学习引擎还赢得了与“ Stockfish变体”的所有比赛,“ Stockfish变体使用了很强的首本书”。 增加一本首发书似乎对斯托克菲什有帮助,当阿尔法·泽罗(AlphaZero)打黑时,斯托克菲什最终赢得了大量比赛,但不足以赢得比赛。
结果发表
在科学杂志上
的一篇文章中,由选定的
国际象棋媒体提供 。
1000场比赛于2018年初举行。 在比赛中,每场比赛给AlphaZero和Stockfish 3小时,每回合增加15秒。 这种时间控制可能会成为反对去年比赛结果的最大争议之一,即2017年,每转一分钟的时间控制对AlphaZero来说是一个强大的优势。
用3个小时加上15秒的增加,这种说法就没有意义了,因为对于任何国际象棋引擎来说,这都是一个巨大的比赛时间。 在时间不相等的游戏中,即使时间比为10比1,AlphaZero仍占主导地位。 鳕鱼只以30:1的比例开始获胜。
AlphaZero在不平等时间的游戏中的结果表明,它不仅比任何传统的国际象棋引擎都要强大,而且使用了效率更高的移动搜索。 根据DeepMind的说法,AlphaZero使用Monte Carlo树搜索并每秒研究约60,000个位置,而Stockfish则为每秒6000万个位置。
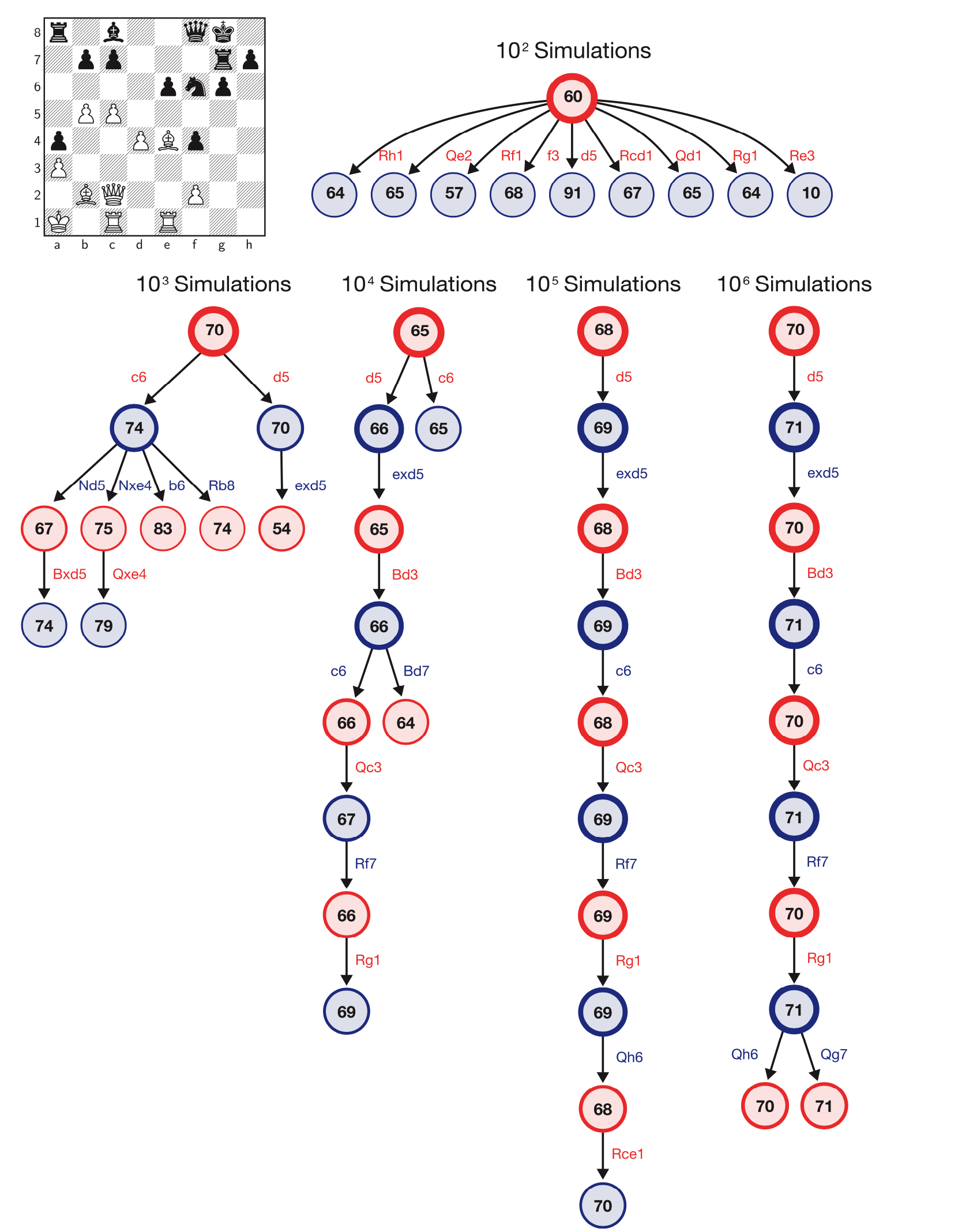 AlphaZero移动搜索算法图。 DeepMind的图片,来自《科学》杂志上的一篇文章。
AlphaZero移动搜索算法图。 DeepMind的图片,来自《科学》杂志上的一篇文章。根据文章,在三个复杂的游戏中,更新的AlphaZero算法是相同的:国际象棋,将棋和围棋。 经过数小时的自我训练,此版本的AlphaZero能够击败所有三款游戏中最好的计算机引擎,从简单的游戏规则开始。
DeepMind已从这场比赛中发布了210场比赛,您可以
在这里下载。
从游戏规则开始,新的AlphaZero版本已经学会了自己下棋,使用机器学习方法不断更新其神经网络。 根据DeepMind的说法,使用了5,000个TPU(Google张量处理器,用于AI的专用集成电路)来生成第一套独立游戏,然后使用16个TPU训练神经网络。
国际象棋的总训练时间从头开始花费了9个小时。 根据DeepMind的说法,新的AlphaZero仅需四个小时的培训就能超越Stockfish。 在九个小时内,他远远领先于世界象棋冠军。
对于游戏本身,Stockfish使用44个处理器,而AlphaZero使用一台具有四个TPU和44个处理器核心的机器。
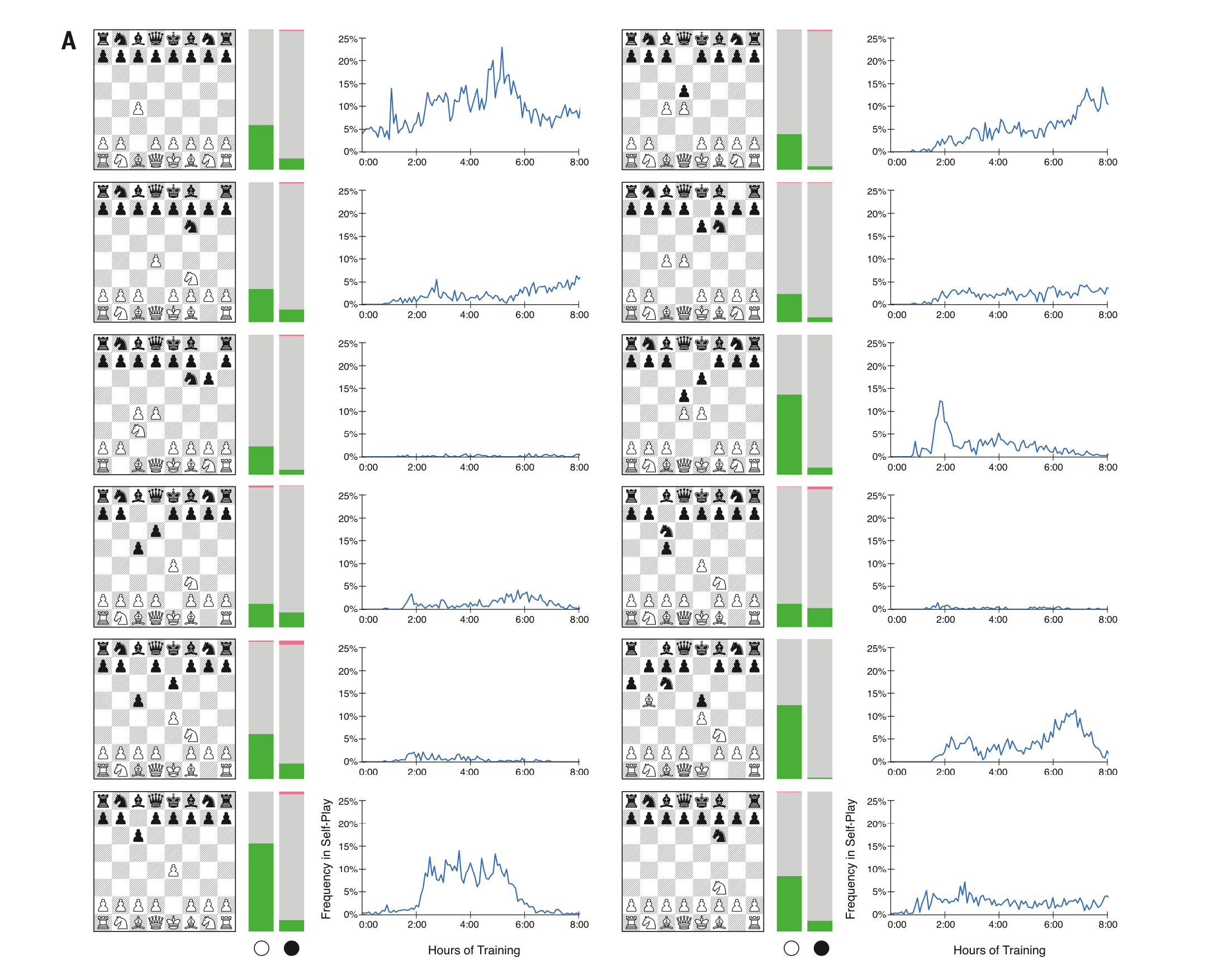 AlphaZero vs. Stockfish是最受欢迎的处女作。 在左侧,AlphaZero播放白色; 在右边-黑色。
AlphaZero vs. Stockfish是最受欢迎的处女作。 在左侧,AlphaZero播放白色; 在右边-黑色。DeepMind自己在文章中指出了其程序的独特播放风格:
DeepMind研究人员说:“在几场比赛中,AlphaZero为了长期的战略优势而牺牲了棋子,这表明它比以前的象棋程序中使用的基于规则的等级具有更高的上下文位置等级。”
AI还强调了在三种不同的游戏中使用相同版本的AlphaZero的重要性,并称其为整体游戏智能的突破:
DeepMind研究人员说:“这些结果使我们更加接近实现人工智能的长期目标:可以学习掌握任何游戏的通用游戏系统。”