昨天我收到了西伯利亚一位十年级学生的来信,他想成为一名微处理器开发人员。 她已经在该领域取得了一些成果-她将乘法指令添加到了最简单的schoolMIPS处理器中,并针对英特尔FPGA MAX10 FPGA进行了合成,确定了简单程序的最大频率并提高了生产率。 她首先在新西伯利亚州的Burmistrovo村做所有这一切,然后在托木斯克的一次会议上做。
现在,达莎·克里沃鲁奇科(那是十年级学生的名字)搬到莫斯科寄宿学校住,问我她还应该设计什么。 我认为,在她职业生涯的这个阶段,她应该为基于矩阵矩阵的脉动数组设计神经网络的硬件加速器。 使用Verilog硬件描述语言和Intel FPGA FPGA,但不要便宜的MAX10,但是要容纳大型脉动阵列,价格会更高一些。
然后,将硬件解决方案的性能与在schoolMIPS处理器上运行的程序以及在台式计算机上运行的Python程序进行比较。 作为测试用例,请使用小矩阵中的数字识别。

实际上,此练习的所有部分都是由不同的人开发的,但重点是将其放入一个单独的,有文档记录的练习中,然后可以用作在线课程和实际比赛的基础:
1)RUSNANO的教育部门eNano,过去曾为学生组织过有关现代电子设计(RTL到GDSII路线)的Charles Danchek研讨会,目前正致力于此类在线课程(在寄存器传输+神经网络的水平上设计硬件)感兴趣面向高级学生的精简课程。 查尔斯和我在这里在他们的办公室:

2)奥运会的举办地可能对
NTI奥运会感兴趣,几个星期前我在莫斯科提出了这个问题。 对于这样的示例,奥林匹克运动会的参与者可以添加用于不同激活功能的硬件。 以下是NTI奥运会的同事:

因此,如果Dasha对此进行开发,她可以从理论上在RUSNANO和NTI奥林匹克运动会中介绍她的加速器。 我认为这对她学校的管理将是有益的-可以将其显示在电视上或发送给一般的Intel FPGA竞赛。 以下是
在加利福尼亚州圣克拉拉举行的英特尔FPGA竞赛决赛中,来自圣彼得堡的一
对俄罗斯人 :

现在让我们谈谈项目的技术方面。 收缩质量加速器的想法在Khabra Vyacheslav Golovanov
SLY_G的编辑翻译的一篇文章中进行了描述。
为什么 TPU 如此适合深度学习?易于识别的数据流神经网络图如下所示:

执行乘法和加法的原始计算元素:

这种元素的强大流水线结构,用于矩阵乘法的脉动数组为:

在Internet上,在Verilog和VHDL上有一堆代码是通过脉动数组实现的,例如,该代码
在此博客文章下 :

module top(clk,reset,a1,a2,a3,b1,b2,b3,c1,c2,c3,c4,c5,c6,c7,c8,c9); parameter data_size=8; input wire clk,reset; input wire [data_size-1:0] a1,a2,a3,b1,b2,b3; output wire [2*data_size:0] c1,c2,c3,c4,c5,c6,c7,c8,c9; wire [data_size-1:0] a12,a23,a45,a56,a78,a89,b14,b25,b36,b47,b58,b69; pe pe1 (.clk(clk), .reset(reset), .in_a(a1), .in_b(b1), .out_a(a12), .out_b(b14), .out_c(c1)); pe pe2 (.clk(clk), .reset(reset), .in_a(a12), .in_b(b2), .out_a(a23), .out_b(b25), .out_c(c2)); pe pe3 (.clk(clk), .reset(reset), .in_a(a23), .in_b(b3), .out_a(), .out_b(b36), .out_c(c3)); pe pe4 (.clk(clk), .reset(reset), .in_a(a2), .in_b(b14), .out_a(a45), .out_b(b47), .out_c(c4)); pe pe5 (.clk(clk), .reset(reset), .in_a(a45), .in_b(b25), .out_a(a56), .out_b(b58), .out_c(c5)); pe pe6 (.clk(clk), .reset(reset), .in_a(a56), .in_b(b36), .out_a(), .out_b(b69), .out_c(c6)); pe pe7 (.clk(clk), .reset(reset), .in_a(a3), .in_b(b47), .out_a(a78), .out_b(), .out_c(c7)); pe pe8 (.clk(clk), .reset(reset), .in_a(a78), .in_b(b58), .out_a(a89), .out_b(), .out_c(c8)); pe pe9 (.clk(clk), .reset(reset), .in_a(a89), .in_b(b69), .out_a(), .out_b(), .out_c(c9)); endmodule module pe(clk,reset,in_a,in_b,out_a,out_b,out_c); parameter data_size=8; input wire reset,clk; input wire [data_size-1:0] in_a,in_b; output reg [2*data_size:0] out_c; output reg [data_size-1:0] out_a,out_b; always @(posedge clk)begin if(reset) begin out_a<=0; out_b<=0; out_c<=0; end else begin out_c<=out_c+in_a*in_b; out_a<=in_a; out_b<=in_b; end end endmodule
我注意到这段代码并未经过优化,而且通常很笨拙(甚至是不专业地编写-帖子中的源代码使用@(posege clk)中的块分配-我已将其修复)。 例如,Dasha可以使用Verilog生成构造来获得更优雅的代码。
除了神经网络的两个极端实现(在处理器和脉动阵列上)外,Dasha还可以考虑比处理器更快的其他选项,但不像脉动阵列那样乘法运算那么繁琐。 没错,这更可能不是针对学童,而是针对学生。
一种选择是具有大量并行运行的功能块的执行设备,例如在无序处理器中:

另一个选择是所谓的粗粒度可重配置阵列-准处理器元素的矩阵,每个元素都有一个小程序。 这些处理器元件在理想情况下类似于FPGA / FPGA单元,但不使用单个信号进行操作,而是在总线和寄存器上使用成组的位/数字-请参阅
硬件AI主要参与者诞生时的
实时报告,这可以加速TensorFlow并与NVidia竞争。 。
现在,大沙的原始信件是:
美好的一天,尤里。
2017年,我在您的LSHUP所在学校的您的车间里学习,2017年10月,我参加了同年10月在托木斯克举行的一次会议,致力于将乘法单元嵌入SchooolMIPS处理器中。
我现在想继续这项工作。 此刻,我设法在学校获得了将该主题作为小课程的权限。 您是否有机会帮助我继续这项工作?
PS由于工作是以特定格式完成的,因此需要撰写有关该主题的简介和文献综述。 如果您有这样的资源,请告知来源,您可以从中获取有关该主题发展历史,建筑哲学等方面的信息。
另外,目前我住在莫斯科的一所寄宿学校,可能会更容易互动。
问候
达里亚(Daria Krivoruchko)。
Dasha在我的帮助下以及
David Harris和Sarah Harris所著的
《数字电路与计算机体系结构》一书中教了Verilog和寄存器级设计。 但是,如果您是一名男生/女生,并且想非常简单地理解基本概念,那么出版社DMK-Press就为您发布了
2013年日本漫画的
俄语翻译,其中涉及了天野英治和目黑浩二创作的
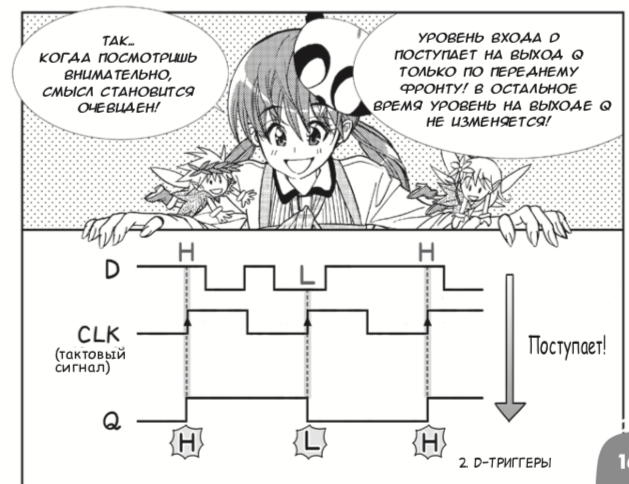
数字电路 。 尽管表现形式轻描淡写,但本书正确地介绍了逻辑元素和D触发器,
然后将其绑定到FPGA :
这是新西伯利亚地区
青年程序员暑期学校的样子,Dasha在这里学习了Verilog,FPGA,一种寄存器转移开发方法(寄存器转移级别-RTL):


这是达莎(Dasha)在托木斯克(Tomsk)会议上的讲话,以及另一位十年级生Arseniy Chegodaev:
在Dasha与我和Stanislav Zhelnio
sparf (在FPGA上实现的schoolMIPS教学处理器核心的主要创建者)进行了交谈之后:

schoolMIPS项目的文档位于
https://github.com/MIPSfpga/schoolMIPS 。 在此培训处理器内核的最简单配置中,Verilog上只有300条线,而在中产阶级的工业嵌入式内核中大约有30万条线。 尽管如此,Dasha仍能感觉到业界设计师的工作情况,当他们向处理器添加新指令时,他们以相同的方式更改解码器和执行设备:
最后,我们展示了萨马拉大学(Samara University)院长Ilya Kudryavtsev的照片,他对创建暑期学校和使用FPGA处理器的奥林匹克竞赛感兴趣,供未来的申请者使用:

还有Zelenograd MIET的员工的照片,他们已经在计划明年这样的暑期学校:

RUSNANO的材料以及NTI奥林匹克运动会的可能材料,以及过去几年在HSE MIEM,莫斯科国立大学和
喀山Innopolis计划中在FPGA和微体系结构的实现方面取得的成就,都应该在一个地方和另一个地方进行得很好。