在20世纪90年代末的棋盘游戏真正繁荣之后,这个家庭留下了数个装有游戏的盒子。 其中之一是原始德语版本的“野兔与刺猬”游戏。 一种适合多名玩家的游戏,其中随机性的元素被最小化,其敏锐的计算能力和几步之遥的“向前看”能力将获胜。
我在游戏中屡屡失利,导致我编写计算机“情报”以选择最佳举动。 智力,理想情况下可以与野兔和刺猬的宗师作战(并且,茶,而不是国际象棋,游戏会更容易)。 本文的其余部分描述了开发过程,AI逻辑以及到源的链接。
游戏规则野兔和刺猬
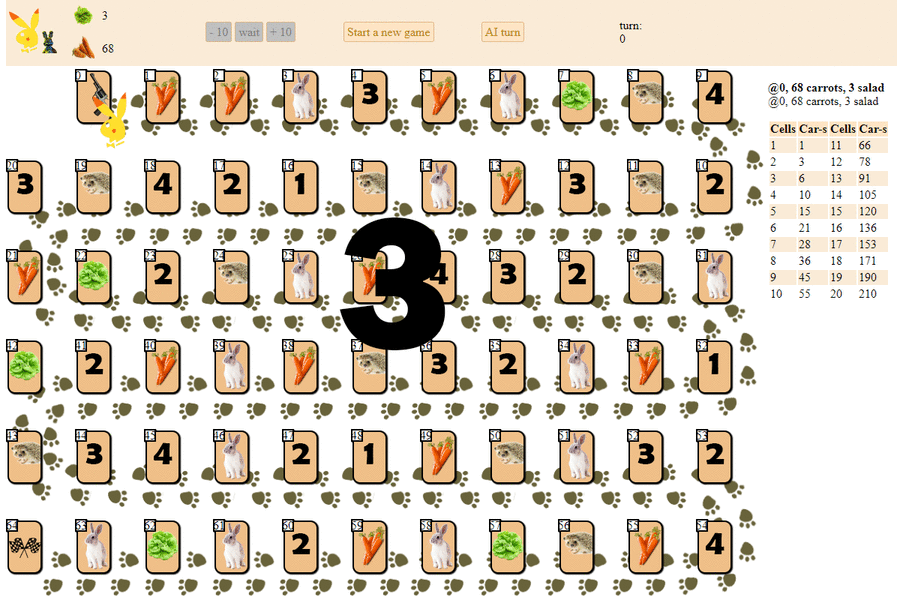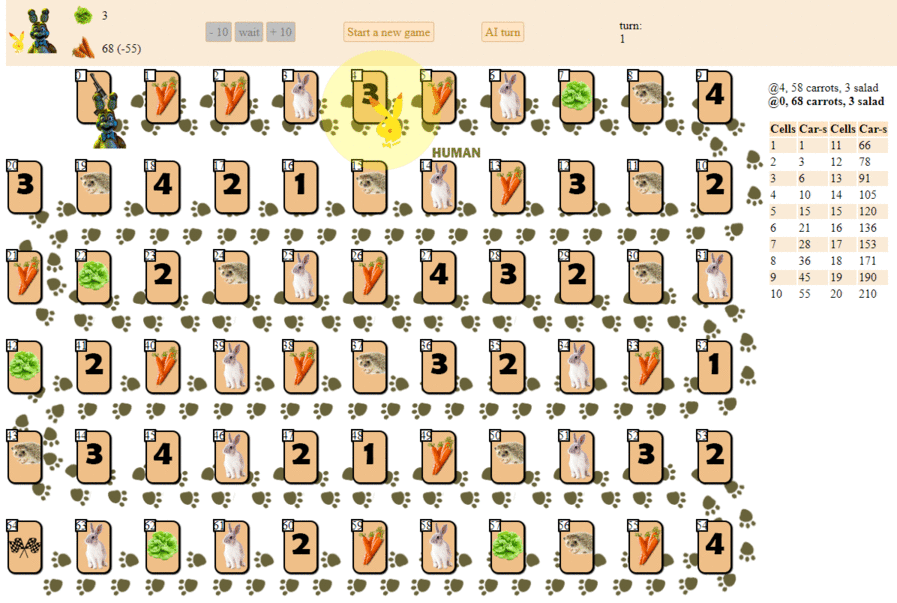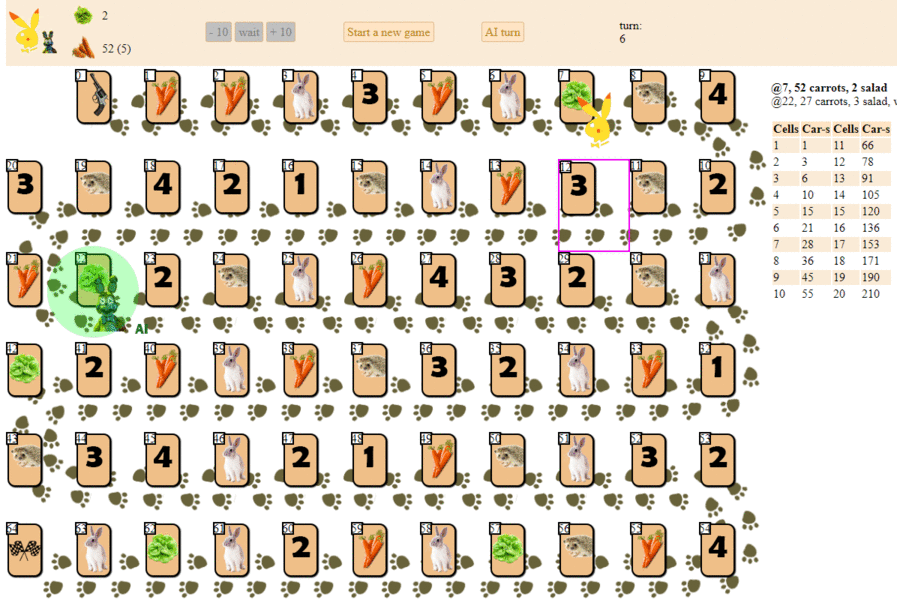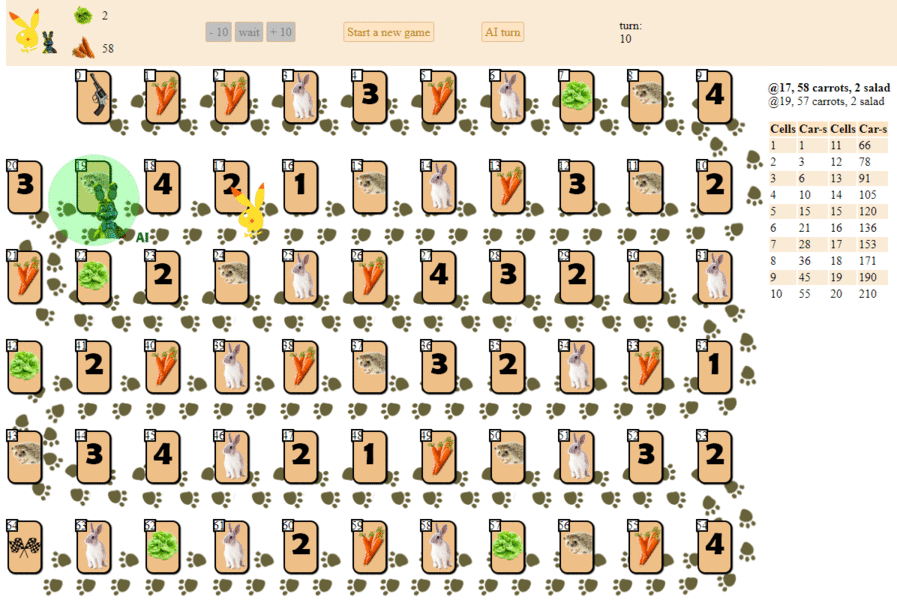
在65个单元的比赛场上,有几位玩家筹码,从2到6位参与者(我的绘画,非规范,外观,当然是这样):
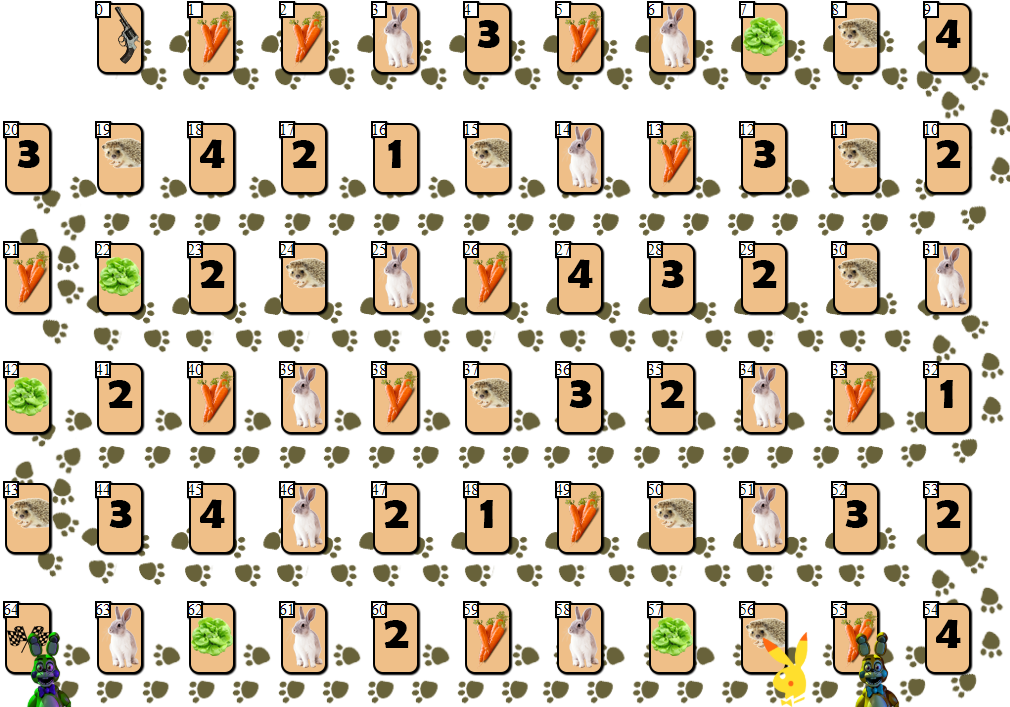
除了索引为0(开始)和64(结束)的单元外,每个单元中只能放置一个玩家。 每个玩家的目标是领先竞争对手进入终点站。
前进的“燃料”是胡萝卜-游戏的“
货币” 。 开始时,每个玩家都会收到68根胡萝卜,他在移动时会给予(有时还会收到)。
除了胡萝卜,玩家一开始会收到3张色卡。 沙拉是特殊的“神器”,玩家必须在完成比赛之前将其
清除 。 摆脱生菜(这只能在特殊的生菜笼中完成,如下所示:

),包括在内的玩家将获得额外的胡萝卜。 在此之前,跳过您的举动。 沙拉旁离开牌的玩家越多,该玩家获得的胡萝卜就越多:10 x(该玩家在场上相对于其他玩家的位置)。 也就是说,第二名的选手将获得20根胡萝卜,离开沙拉笼。
如果将玩家的位置与该单元格上的数字相匹配(1-4,则数字1的单元格也适合该字段的第四和第六位置),则编号为1-4的单元格可以带出几十个胡萝卜。
玩家可以跳过移动,留下带有胡萝卜图像的笼子,并为此动作接收或给予10个胡萝卜。 玩家为什么要给“加油”? 事实是,玩家在最后一步之后只能完成10根胡萝卜(如果获得第二,则获得20根胡萝卜,如果获得第三,则获得30根胡萝卜,依此类推)。
最后,玩家可以通过在
最近的免费刺猬上踩N步来获得10 x N的胡萝卜(如果最近的刺猬很忙,那么这样的举动是不可能的)。
根据公式(向上取整),向前移动的成本与移动的数量不成比例地计算:
fracN+N22 ,
其中N是前进的步数。
因此,要向前移动一个单元格,玩家会给1个胡萝卜,3个2个单元格的胡萝卜,6个3个单元格的胡萝卜,10个4个单元格...,210个向前移动20个单元格的胡萝卜。
最后一个单元-具有野兔图像的单元-将随机性元素引入游戏。 站在野兔的笼子上,玩家从堆子中抽出一张特殊的纸牌,然后执行一些操作。 根据卡牌和游戏情况的不同,玩家可能会损失一些胡萝卜,获得额外的胡萝卜或跳过一圈。 值得注意的是,在具有“效果”的牌中,对玩家来说还有更多的负面场景,这鼓励了游戏的谨慎性和计算性。
没有AI的实施
在最初的实现中,这将成为开发“智力”游戏的基础,我将自己限制在每个玩家(一个人)采取行动的选项上。
我决定将游戏作为客户端实施-一个静态的单页网站,其所有“逻辑”都在JS和服务器上实现-WEB API应用程序。 该服务器使用.NET Core 2.1编写,并生成一个程序集工件-dll文件,该文件可以在Windows / Linux / Mac OS下运行。
客户端部分的“逻辑”被最小化(与UX一样,因为GUI完全是功利主义的)。 例如,Web客户端本身不会执行检查以查看播放器请求的规则是否可接受。 此检查在服务器上执行。 服务器告诉客户端玩家可以从当前游戏位置做出什么动作。
该服务器是经典的
Moore机器 。 服务器逻辑缺少“连接的客户端”,“游戏会话”等概念。
服务器所做的只是处理收到的(HTTP POST)命令。
“命令”模式在服务器上实现。 客户端可以请求执行以下命令之一:
- 开始一个新游戏,即 将指定数量的玩家筹码“放置”在“干净”板上
- 进行命令中指示的移动
对于第二个团队,客户端向服务器发送当前游戏位置(Disposition类的对象),即以下形式的描述:
- 位置,每种野兔的胡萝卜和生菜的数量,以及一个附加的布尔字段,指示野兔缺少轮到
- 移动的野兔的索引。
服务器不需要发送其他信息-例如,有关运动场的信息。 就像记录国际象棋素描一样,不必在板上绘出黑白单元的排列,该信息被视为常数。
作为响应,服务器指示命令是否成功完成。 从技术上讲,客户可能会例如请求无效举动。 或者尝试为单个参与者创建一个新游戏,这显然没有意义。
如果团队成功,则响应将包含一个新的游戏
位置 ,以及队列中下一位玩家可以做出的动作列表(新位置的当前动作)。
除此之外,服务器响应还包含一些服务字段。 例如,玩家在相应笼子上的台阶上“拔出”野兔牌的文本。
玩家回合
玩家的回合编码为整数:
- 0,如果播放器被迫停留在当前单元格中,
1,2,... N代表1,... N前进, - -1,-2,... -M将1 ... M个细胞移回最近的自由刺猬,
- 1001、1002-决定停留在胡萝卜单元上并接收(1001)或给予(1002)10根胡萝卜的玩家的特殊代码。
软件实施
服务器接收请求的命令的JSON,将其解析为相应的请求类之一,然后执行请求的操作。
如果客户(球员)要求从转移到团队的位置(POS)使用CMD代码进行移动,则服务器将执行以下操作:
- 检查这样的举动是否可能
- 从当前位置创建一个新位置,对其进行相应的修改,
获得一个新职位的许多可能动作。 让我提醒您,进行位置移动的玩家的索引已经包含在描述位置的对象中, - 向客户返回新位置的答案,可能的举动或成功标志等于false以及错误说明。
检查所请求举动(CMD)的可接受性并构造新位置的逻辑比我们想要的紧密得多。 按照这种逻辑,找到可接受的动作的方法有一些共同点。 所有这些功能都由TurnChecker类实现。
在输入check / execute方法时,TurnChecker会收到一个游戏位置类别的对象(处置)。 Disposition对象包含一个播放器数据数组(Haze []雾度),该播放器的索引进行移动+在TurnChecker对象操作期间填写的一些服务信息。
运动场描述FieldMap类,该类实现为
singleton 。 该类包含一个单元格数组和一些用于简化/加速后续计算的开销信息。
性能考量在TurnChecker类的实现中,我尝试尽可能避免循环。 事实是,在准最佳移动的搜索过程中,随后将获取用于获得一组允许移动/执行某个移动的方法的次数称为数千次(成千上万次)。
因此,举例来说,我使用以下公式计算出玩家可以用N个胡萝卜前进多少格:
return ((int)Math.Pow(8 * N + 1, 0.5) - 1) / 2;
检查单元格i是否被其中一个玩家占用,我没有浏览玩家列表(因为此动作可能必须执行多次),但我要
查看预先填写的
[cell_index,busy_cell_ flag]形式的字典。
在检查指定的刺猬细胞是否最接近(当前)玩家所占据的当前细胞时,我还将请求的位置与
[cell_index,最近的back_de_dezh] _index] -静态信息形式的字典中的值进行比较。
用AI实施
一个命令被添加到服务器处理的命令列表中:执行程序选择的准最佳移动。 该团队是对“玩家的移动”命令的小修改,实际上,该命令已从其中删除了移动字段(
CMD )。
想到的第一个决定是使用试探法选择“最佳可能”的举动。 与国际象棋类似,我们可以通过为该位置设置某种等级来评估通过此举获得的每个游戏位置。
启发式位置评估
例如,在国际象棋中,进行评估(不爬到开口的荒野中)非常简单:至少,您可以通过将3个棋子的骑士/主教值,5个典当的车子价值,9的皇后数和9的国王价值来计算零件的总“成本”。
.MaxValue典当。 可以很容易地改进估计值,例如将其添加(带有校正因子-因子/指数或其他函数):
- 从当前位置可能移动的次数,
- 威胁与敌人人物的比率/来自敌人的威胁。
对垫子的位置进行了特殊评估:
int.MaxValue ,如果将
死者放置了计算机,
则为 int.MinValue ,如果将
死者放置了计算机。
如果您命令象棋处理器选择下一个动作,仅在这种评估的指导下,处理器可能不会选择最差的动作。 特别是:
- 千万不要错过机会选一个更大的棋子或将棋子,
- 最有可能的是,它不会推动数字增长,
- 鉴于评估中的威胁数量,它不会再次使该数字受到攻击。
当然,计算机的这种移动不会给他留下与对手进行成功的机会,而对手在丝毫意义上做出了移动。 计算机将忽略任何插头。 此外,他甚至可能会毫不犹豫地将女王换成典当。
但是,用于启发式评估国际象棋当前下注位置的算法(无需声明冠军程序的桂冠)是相当透明的。 您不能说游戏野兔和刺猬。
在一般情况下,在野兔和刺猬的游戏中,一个相当模糊的格言起作用了:“
最好多吃些胡萝卜,少些生菜,以更好的表现 ”。 但是,并非一切都那么简单。 假设,如果玩家在游戏中途有一张沙拉卡,则此选项可能会很好。 但是拿着沙拉卡站在终点线上的玩家显然将处于失败状态。 除了评估算法之外,我还希望能够进一步“窥视”一步,就像可以通过对棋局的启发式评估来计算对棋子的威胁一样。 例如,值得考虑的是,离开生菜室/位置室(1 ... 4)的玩家收到的胡萝卜的奖金,要考虑到前面的玩家数量。
我推断出最终成绩是一个函数:
E = Ks * S + Kc * C + Kp * P,
其中S,C,P是使用玩家手中的色卡(S)和胡萝卜©计算出的等级,P是给予玩家的行进距离的等级。
Ks,Kc,Kp是相应的校正因子(稍后将进行讨论)。
最简单的方法是我确定
行进路线的标记:
P = i * 3,其中i是播放器所在的单元格的索引。
对C(胡萝卜)进行分级已经更加困难。
为了获得特定的C值,我选择了以下三个函数之一
C0,C1,C2 从一个论点(手上胡萝卜的数量)开始。 函数C的索引([0,1,2])由玩家在运动场上的相对位置确定:
- [0]如果玩家完成的比赛场地不足一半,
- [2]如果玩家有足够(胡萝卜,甚至丰富)的胡萝卜来完成,
- [1]在其他情况下。
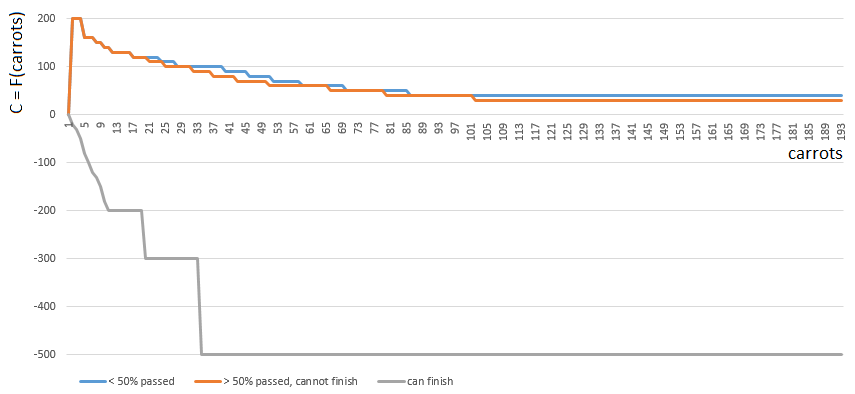
功能0和1相似:玩家手中每个胡萝卜的“值”随着手中胡萝卜数量的增加而逐渐减小。 游戏很少鼓励Plyushkins。 在第一种情况(通过的字段的一半)中,胡萝卜的值下降得更快。
相反,功能2(玩家可以完成)对玩家手中的每根胡萝卜都施加了较大的罚款(负系数值)-胡萝卜越多,惩罚系数越大。 由于过量的胡萝卜,比赛规则禁止涂饰。
在计算玩家手上的胡萝卜量之前,要先考虑生菜单元格/单元格编号1 ... 4中每步移动的胡萝卜。
以类似的方式得出“
生菜 ”等级S。 根据玩家手上的沙拉量(0 ... 3),选择一个功能
S0,S1,S2 或
S3 。 函数参数
S0−S3 。 -再次,玩家的“相对”路径。 即,前面剩下色拉的单元格数量(相对于玩家所占据的单元格):
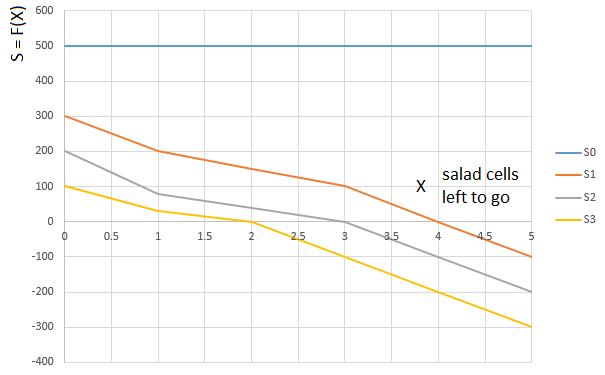
曲线
S0 -对于手头有0张生菜卡的玩家,评估播放器前面的生菜盒数(0 ... 5)的评估功能(S),
曲线
S1 -手上拿着一张沙拉卡等的玩家具有相同的功能。
因此,最终成绩(E = Ks * S + Kc * C + Kp * P)考虑到:
- 玩家在自己移动之前会立即收到的额外胡萝卜,
- 玩家的路径
- 非线性影响分数的胡萝卜和生菜的量。
这是计算机的播放方式,选择具有最大启发式得分的下一步:
原则上,首次亮相还不错。 但是,不应期望这样的AI会带来出色的游戏:在游戏过程中,绿色的“机器人”开始重复移动,最后,它进行了多次重复移动-向后刺入刺猬,直到最终完成。 部分由于偶然的缘故,他将落后于玩家-一个人十二步之遥。
实施说明评估的计算由一个特殊的类-EstimationCalculator管理。 用于评估相对于胡萝卜的位置的功能-色拉卡被加载到计算器类的静态构造函数中的数组中。 位置估算方法从“角度”接收位置对象本身和玩家的索引,并通过算法对其位置进行评估。 就是说,根据考虑虚拟点的玩家,同一游戏位置可以收到几个不同的评分。
决策树和Minimax算法
我们在对抗性Minimax游戏中使用决策算法。 在我看来,非常好,
此帖子(翻译)中介绍了
该算法。
我们教导程序“看”一些前进的步伐。 假设从当前位置开始(背景对算法并不重要-我们记得,该程序的功能就像
一台Moore机器 ),编号为1,该程序可以执行两次移动。 我们得到两个可能的位置,2和3。接下来是玩家的回合-人(通常是敌人)。 从第二位置开始,对手有3个动作,从第三位置开始-仅有两个动作。 接下来,再次进行移动的步骤由程序决定,该程序总共可以从5个可能的位置进行10次移动:
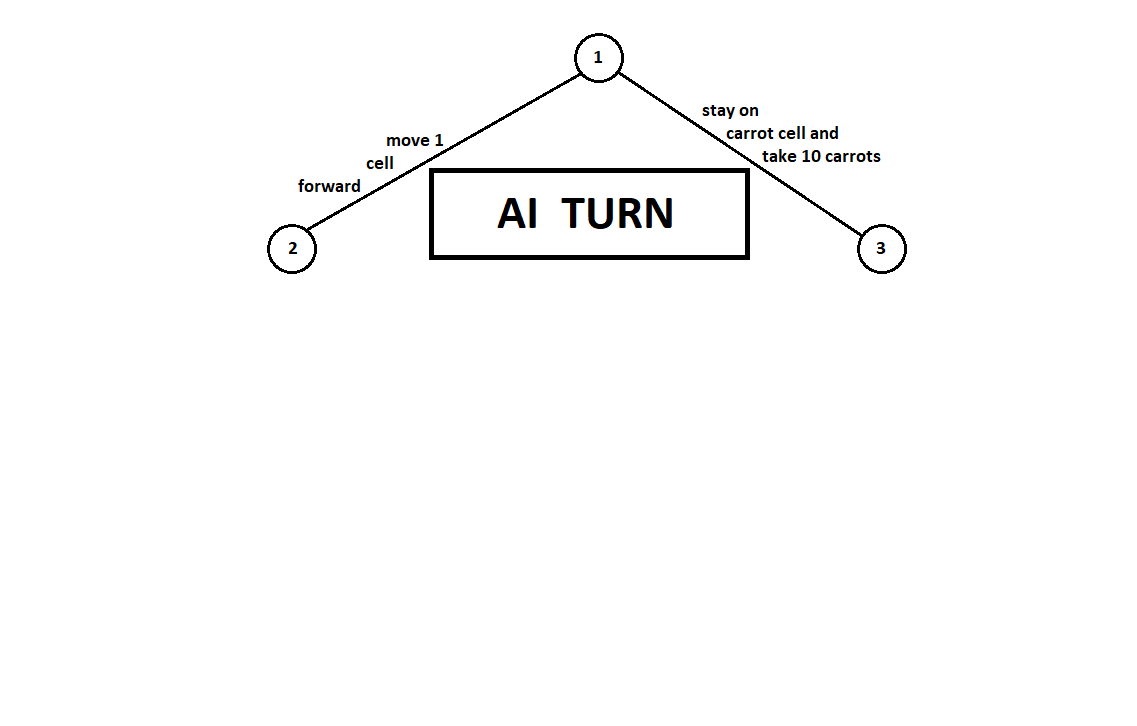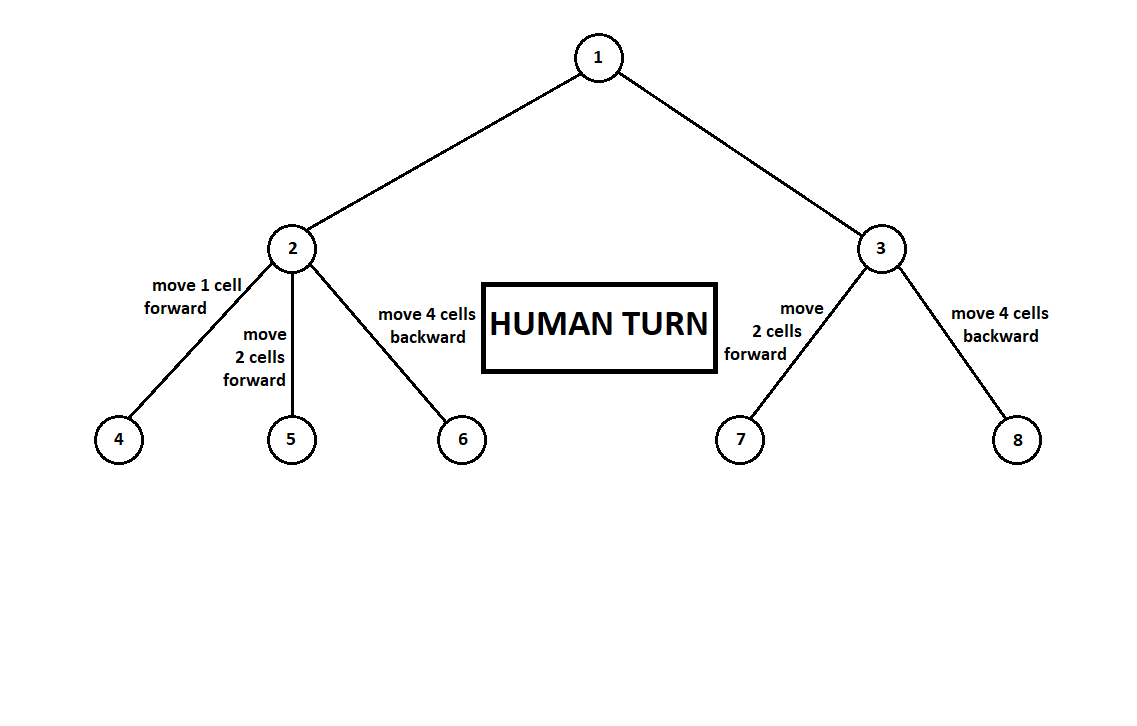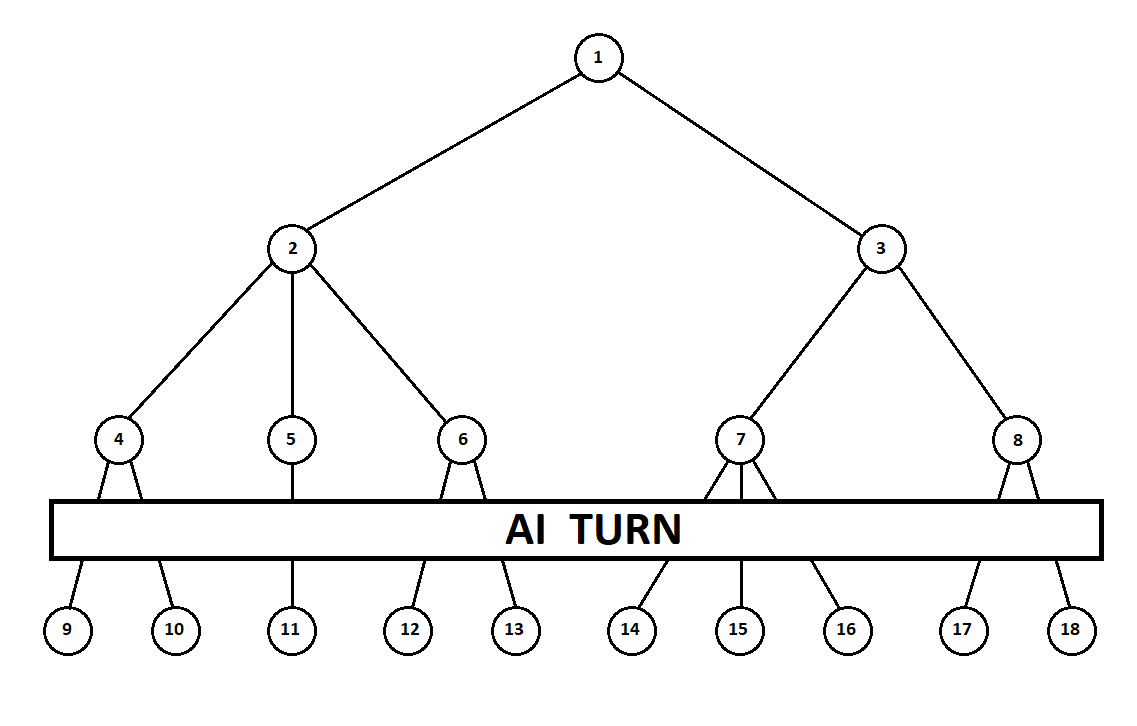
假设在计算机第二次移动之后,游戏结束,并且从第一和第二玩家的角度评估每个接收到的位置。 并且我们已经实现了评估算法。 让我们以向量的形式评估每个最终位置(树9 ... 18的叶子)
[v0,v1] ,
在哪里
v0 -为第一个玩家计算的分数,
v1 -第二名玩家的得分:
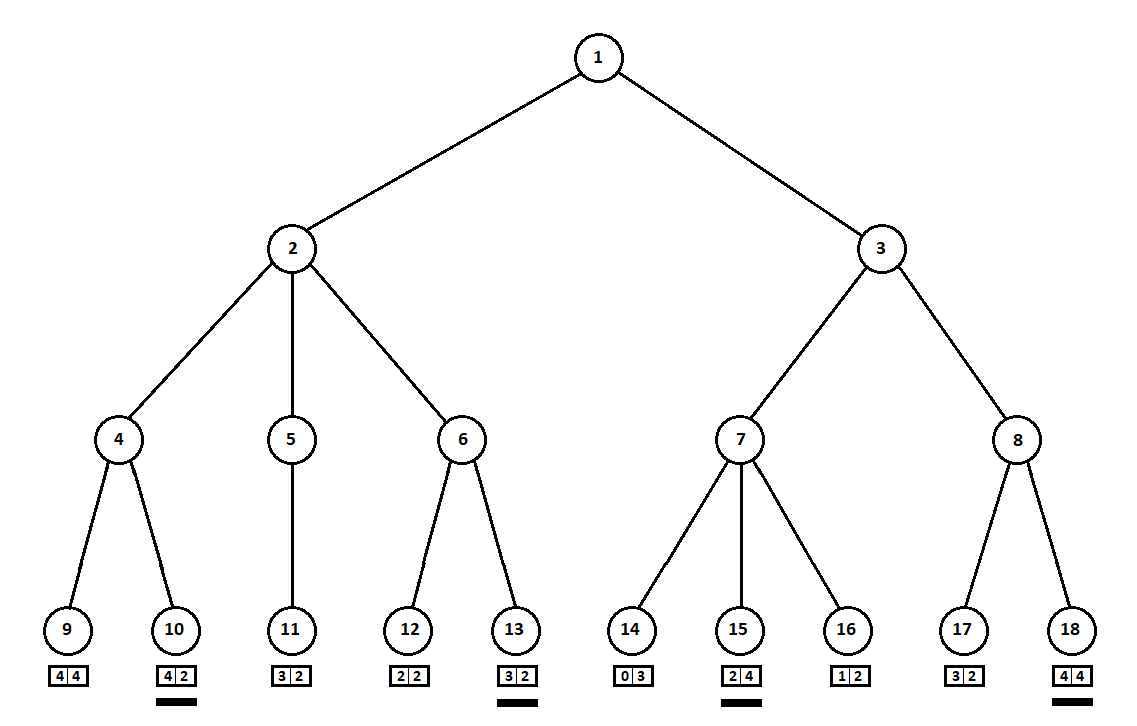
由于计算机采取了最后一步,因此显然它将选择每个子树中的选项([9、10],[11],[12、13],[14、15、16],[17、18])这给了他更好的评价。 问题立即浮出水面:应根据什么原则选择“最佳”职位?
例如,有两个动作,之后我们得到了具有评级的位置[5; 5]和[2; 1]。 评估第一个玩家。 显然有两种选择:
- 第i个玩家的第i个得分的最大绝对值的位置选择。 换句话说,高贵的赛车手莱斯利(Leslie)渴望获得胜利,而不顾竞争对手。 在这种情况下,位置估计为[5; 5]。
- 狡猾的教授费斯(Faith)是选择狡猾的教授费斯(Faith) 来选择相对于竞争对手的估计最高评价的职位,他不会错过对敌人施加肮脏手段的机会。 例如,故意落后于计划从第二位置开始的玩家。 评分为[2; 1]。
在我的软件实现中,我将等级选择算法(将等级向量映射到第i个播放器的标量值的函数)作为自定义参数。 令我惊讶的是,进一步的测试表明,第一种策略的优越性-通过最大绝对值选择仓位
vi 。
软件实施功能如果在AI的设置(TurnMaker类)中指定了选择最佳成绩的第一个选项,则相应方法的代码将采用以下形式:
int ContractEstimateByAbsMax(int[] estimationVector, int playerIndex) { return estimationVector[playerIndex]; }
第二种方法-相对于竞争对手的位置的最大值-实现起来稍微复杂一些:
int ContractEstimateByRelativeNumber(int[]eVector, int player) { int? min = null; var pVal = eVector[player]; for (var i = 0; i < eVector.Length; i++) { if (i == player) continue; var val = pVal - eVector[i]; if (!min.HasValue || min.Value > val) min = val; } return min.Value; }
选定的估计值(图中带下划线的部分)将转移到更高的水平。 现在,敌人必须选择一个位置,知道算法将选择哪个后续位置:
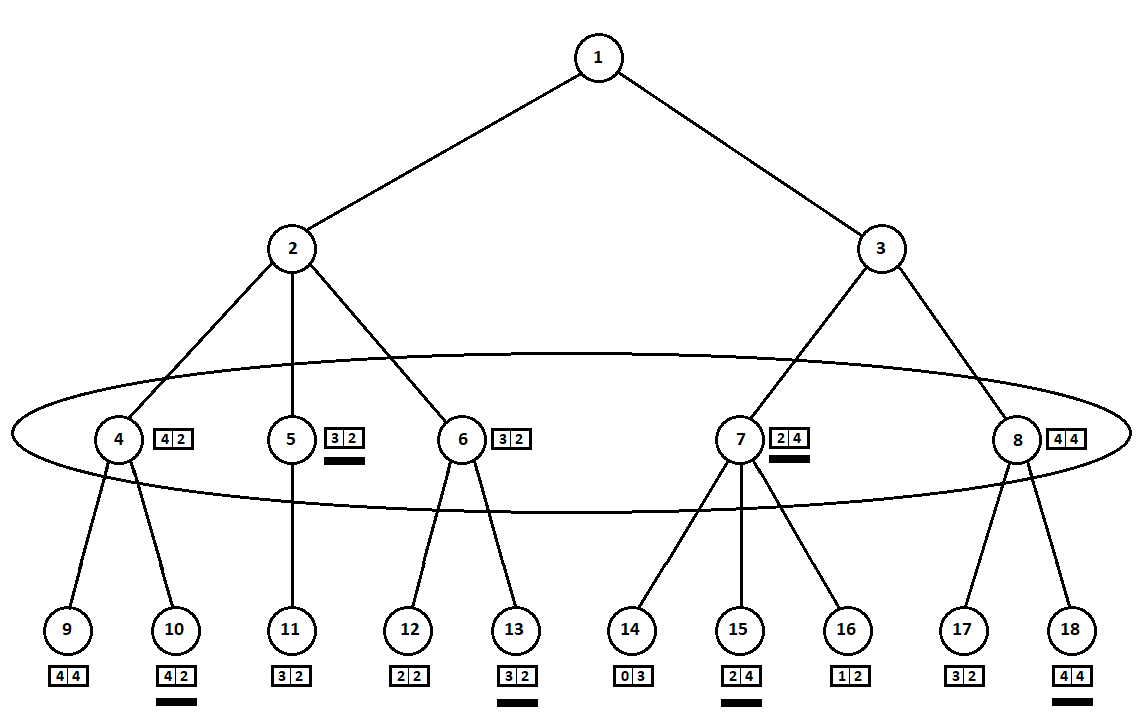
显然,对手会选择对自己评分最高的位置(向量
第二个坐标取最大值的位置)。 这些估计在图中再次强调。
最后,我们回到第一步。 计算机进行选择,并且他更喜欢使用向量的第一坐标最大的移动:
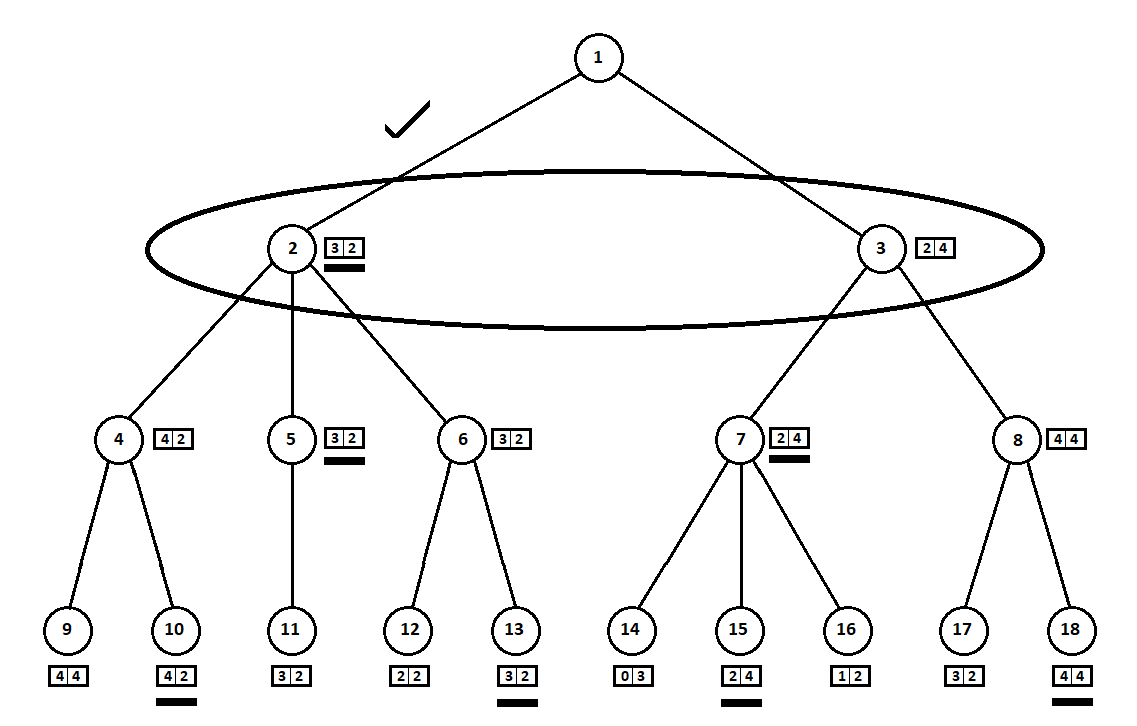
因此,解决了该问题-找到了一个最佳运动。 假设树上叶子位置的启发式得分为100%,则表示未来的获胜者。 然后,我们的算法将明确选择最佳移动方式。
但是,仅当评估游戏的
最终位置时,启发式分数才是100%准确的-一个(或几个)玩家已经完成,才确定获胜者。 因此,有机会展望N个动作-赢得同等实力的对手所需的一切,您可以选择最佳动作。
但是典型的2人游戏平均持续30-40步(三人-60步,依此类推)。 从每个位置,玩家通常可以进行约8步。 因此,完整的30步可能位置树将由大约
830 = 1237940039285380274899124224峰!
实际上,在我的PC上构建和“解析”约100,000个位置的树大约需要300毫秒。 如果我们希望计算机的响应时间不超过一秒钟,则可以将树的深度限制为7-8级(移动)。
软件实施功能显然,需要一种递归方法来建立位置树并找到最佳移动。 在该方法的输入处-当前位置(我们记得,玩家已经在其中移动)和当前树级别(移动编号)。 一旦我们下降到算法设置允许的最大水平,该函数就会从每个玩家的“观点”返回启发式位置估计向量。
重要的补充 :当当前玩家结束比赛时,还必须停止在树下的下降。 否则(如果选择了用于选择相对于其他玩家的位置的最佳位置的算法),则程序可以长时间在终点“踩”,“模拟”对手。 另外,通过这种方式,我们将在最终游戏中稍微减小树的大小。
如果我们还没有达到最终的递归级别,则选择可能的移动,为每个移动创建一个新位置,并将其传递给当前方法的递归调用。
为什么是Minimax?在最初的解释中,球员总是两个。 该程序仅根据第一个玩家的位置计算分数。 因此,当选择“最佳”位置时,索引为0的玩家搜索评分最高的位置,索引为1的玩家搜索最小值。
在我们的例子中,评分应该是一个矢量,以便当评分上升到树上时,N个参与者中的每一个都可以从其“角度”对其进行评估。
调整AI
我与计算机对战的实践表明,该算法虽然还不错,但仍然不如人类。 我决定通过两种方式改善AI:
Minimax算法优化
在上面的示例中,我们可以拒绝考虑位置8并“保存”树的2-3个顶点:
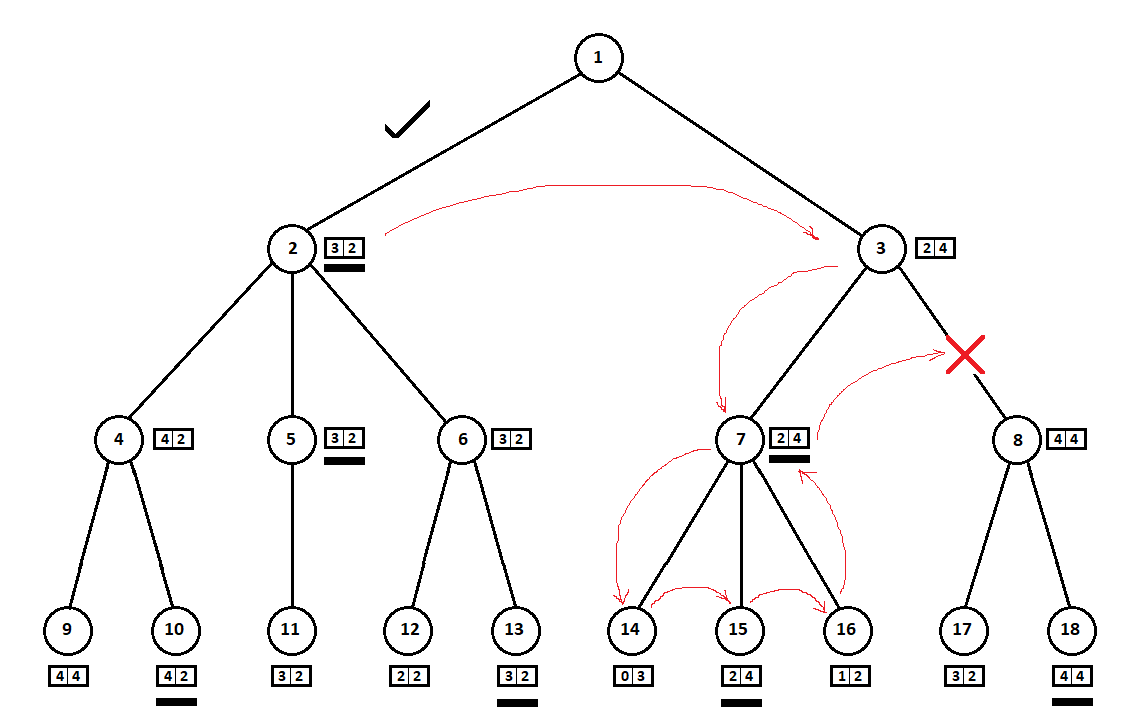
我们从上到下,从左到右,绕着树走。 绕过从位置2开始的子树,我们得出了移动1-> 2的最佳估计:[3,2]。 绕过根在位置7的子树,我们确定了当前(最佳移动3-> 7)等级:[2,4]。 从计算机(第一玩家)的角度来看,分数[2,4]比分数[3,2]差。 并且由于计算机的对手从位置3选择移动,所以无论位置8的得分如何,位置3的最终得分都将比第三位置的得分先验地差。 因此,不能建立和评估根在位置8的子树。
Minimax算法的优化版本允许您截断多余的子树,称为
alpha-beta裁剪算法 。 实现此算法将需要对源代码进行少量修改。
软件实施功能另外,将两个整数参数传递给TurnMaker类的CalcEstimate方法-alpha(初始等于int.MinValue和beta,等于int.MaxValue)。 此外,在接收到正在考虑的当前移动的估计值之后,将执行以下形式的伪代码:
e = _[0]
软件实施的重要特征根据定义,alpha-beta裁剪方法可产生与“纯净” Minimax算法相同的解决方案。 为了检查决策的逻辑是否发生了变化(或者说结果是移动),我编写了一个单元测试,其中机器人为2个对手中的每一个做出8步动作(总共16步动作),并保存了得到的一系列动作- 禁用剪辑选项。
然后,在同一测试中,在打开裁剪选项的情况下重复该过程。 之后,比较了移动顺序。 动作中的差异表示在执行alpha-beta裁剪算法时发生了错误(测试失败)。
较小的alpha-beta裁剪优化
在AI设置中启用了裁剪选项后,位置树中的顶点数平均减少了3倍。 该结果可以有所改善。
在上面的示例中:
如此成功地“巧合”,以至于在顶点位于位置3的子树之前,我们检查了顶点在位置2的子树。如果顺序不同,我们可以从“最差”子树开始,而不能得出结论,没有必要考虑下一个位置。
通常,修剪一棵树变得更加“经济”,在同一个级别(即,从i位置开始的所有可能移动)的后代顶点已经按当前(而不是深入研究)位置估计进行了排序。 换句话说,我们假设最好的方法(从启发式的角度来看)更有可能获得更好的最终成绩。 因此,我们很有可能对树进行排序,以便在“最差”子树之前考虑“最佳”子树,这将使我们减少更多选择。
评估当前职位是一个昂贵的过程。 如果以前只需要我们评估末端位置(叶)就足够了,那么现在就对树的所有顶点进行评估。 但是,如测试所示,在没有对可能的动作进行初步排序的情况下,所做的估计总数仍略少于变体。
软件实施功能alpha-beta裁剪算法返回与原始Minimax算法相同的动作。 这将检查我们编写的单元测试,比较两个移动序列(对于带有剪切和不带有剪切的算法)。 在一般情况下, 按排序进行的 Alpha-Beta裁剪可能表示与准最佳操作不同的操作 。
要测试修改后算法的正确操作,您需要进行新测试。 尽管进行了修改,但已排序的算法应产生与未排序的算法和原始Minimax算法完全相同的最终估计向量 (在本示例中为[3,2])。
在测试中,我创建了一系列测试位置,并根据“最佳”举动从每个位置中进行选择,打开和关闭排序选项。 然后,他比较了通过两种方式获得的评估向量。
此外,由于通过启发式评估对树的当前顶点中每个可能移动的位置进行了排序,因此请您立即丢弃一些最差的选择。 例如,国际象棋棋手可能会考虑用棋子代替典当机的举动。 但是,通过向前,向后移动3、4 ...个深度来展开情况,例如,当对手将其女王的主教袭击时,他将立即注意到这些选择。
在AI设置中,我设置了“削除最差的选项”向量。 例如,格式为[0,0,8,8,4]的向量表示:
- 向前看[0]和两个[0]步骤,程序将考虑所有可能的移动,因为 0 ,
- [8] [8] , 8 “” , , ,
- 展望未来五个或更多步骤[4],程序将评估不超过4个“最佳”动作。
启用了alpha-beta裁剪算法的排序功能并在裁剪设置中使用了类似的向量后,程序开始花费大约300毫秒来选择准最佳移动,“进一步”前进了8个步骤。启发式优化
尽管在树上遍历了大量的顶点位置并且“深”向前看以寻找准最佳移动,但AI仍然存在一些缺点。我将其中一个定义为“ 兔子陷阱 ”。野兔陷阱. ( 8 — 10 15), . “” ( !):
. :
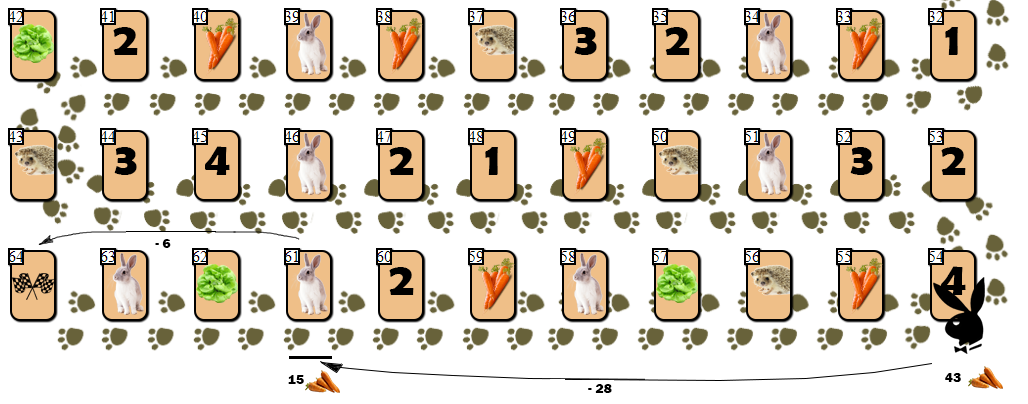
54 (43), — 10 55 . AI, , (61), 28 . , 6 9 ( 10 ).
, ( ), , 4 — 6 . , , , AI ?
,
, . AI . , , . “ ” :
65 — “” , , . , , , () .
校正因素
之前,我引用了用于评估当前位置的启发式公式E = Ks * S + Kc * C + Kp * P,但我并未提及校正因子。事实是公式本身和函数集C 0。。C 2,S 0。。S 5,是我根据所谓的 “常识。” 至少,我想选择这样的系数Ks,Kc和Kp,以便估算值尽可能地合适。如何评估评估的“充分性”?评估是一个无量纲的数量,只能与另一个评估进行比较。我能够提出修正校正系数的唯一方法:我在程序中放入了一系列“研究”,这些研究存储在CSV文件中,格式为 45;26;2;f;29;19;0;f;2 ...
该行的字面意思是:- 第一个玩家在第45方块上,他手中有26张胡萝卜卡和2张沙拉卡,该玩家不会错过任何招(f =假)。迁徙权始终是第一位。
- 第二个单元格上有19张胡萝卜并且没有沙拉卡的第二名玩家不会错过任何移动。
- 图二的意思是,“决定”研究,我假设第二名选手处于获胜状态。
将20个草图放入程序后,我将它们“下载”到游戏网络客户端中,然后对每个草图进行排序。在分析草图时,我轮流为每个玩家做出了动作,直到我确定“获胜者”为止。完成评估后,我将一个特别小组将其发送到服务器。在评估了20个练习曲之后(当然,值得分析更多练习曲),我通过程序对每个练习曲进行了评估。在评估中,每个校正因子的值从0.5到2,以0.1为增量-合计16 3 = 4096个系数三元组的变体。如果发现第一个玩家的分数高于第二个玩家的分数,并且在练习曲记录的行中存储了类似的指令(该行的最后值为1),则对“命中”计数。对于镜像情况也是如此。否则,计算为单据。结果,我选择了那些“命中”百分比最大的三元组(20个中的16个)。在4096个向量中大约有250个出来了,我再次选择了“最佳”,“肉眼”,并将其安装在AI设置中。总结
结果,我得到了一个可以正常运行的程序,该程序通常在与计算机的一对一版本中击败我。尚未积累有关该程序当前版本的重大胜利和失败的统计数据。随后进行的简单AI调整可能会使我无法取得胜利。或几乎不可能,因为野兔细胞因子仍然存在。例如,按照选择评分的逻辑(绝对最高或相对于其他玩家的最高金额),我肯定会尝试一种中间选择。至少,如果第i个玩家的得分的绝对值相等,则选择一个举动来获得得分的相对值更高的位置是合理的(高贵的莱斯利和奸诈的费思混合而成)。该程序对于具有3个播放器的版本是完全可用的。但是,有人怀疑与3个玩家玩游戏时AI动作的“质量”低于2个玩家玩游戏时的质量。但是,在最后一次测试中,我输给了计算机-可能是由于过失,随便评估了我手上的胡萝卜量,并以过量的“燃料”到达终点。到目前为止,人工智能的进一步发展由于缺少人-“测试者”(即计算机“天才”的活着的对手)而受到阻碍。我本人在野兔和刺猬身上玩了很多恶心,因此在现阶段不得不中断比赛。→链接到带有源的资源库