在X5,我们在ERP系统中处理大量数据。 相信没有其他人在俄罗斯的SAP ERP和SAP BW中处理我们。 但是还有一点-操作数量和该系统上的负载正在迅速增加。 三年来,我们一直在为ERP重量级产品的性能而“奋斗”,获得了很多优势,并告诉他们采用了哪些方法。

ERP X5
现在,X5经营着13,000多家商店。 他们每个人的大多数业务流程都通过一个ERP系统。 每个商店可以拥有3,000到30,000种产品,这会给系统的负载造成问题,因为 定期根据促销和立法要求重新计算价格的过程以及库存补充的计算。 所有这些都是至关重要的,如果没有及时计算明天应该将多少数量的商品送到商店或商品的价格应该是多少,买家将找不到他们在货架上想要的东西,或者将无法以当前促销的价格购买商品股票。 通常,除了会计处理财务交易外,ERP系统还负责每个商店的日常生活。
ERP系统的一些性能特征。 它的体系结构是经典的三层结构,具有面向服务的元素:在应用程序层中,我们拥有5,000多个胖客户和数TB的信息流,来自应用程序层-SAP ABAP具有10,000多个流程,最后,Oracle Database拥有超过10,000个流程100 TB的数据。 每个ABAP进程都是有条件的虚拟机,它使用自己的DBSL和SQL方言,缓存,内存管理,ORM等执行ABAP业务逻辑。 每天我们在数据库日志中获得超过15 Tb的更改。 负载级别是每秒500,000个请求。
此体系结构是异构环境。 每个组件都是跨平台的,我们可以将其移动到不同的平台,选择最佳的组件,等等。
一年365天,一天24小时每天都在加载ERP系统,这增加了火势。 可用性-全年99.9%的时间。 负载分为昼夜配置文件和空闲时间进行内务处理。
但这还不是全部。 该系统具有紧密的释放周期。 每年进行2,000多次批量更改。 这可能是一个新按钮,并且会严重改变业务应用程序的逻辑。

结果,这是一个庞大且高负载的系统,但同时又稳定,可预测且易于增长,可以容纳成千上万家商店。 但这并非总是如此。
2014.分叉点
要深入研究实用材料,您需要回到2014年。 然后是最困难的任务,以优化系统。 大约有5,000家商店。
当时的系统处于这样一种状态,即大多数关键流程无法扩展,并且不能充分响应不断增长的负载(即新商店和商品的出现)。 此外,两年前,购买了昂贵的Hi-End,而且一段时间以来,升级并不是我们计划的一部分。 此外,ERP中的流程已接近违反SLA的边缘。 供应商得出结论,系统上的负载不可扩展。 没有人知道她是否能承受至少+ 10%的负载增加。 并计划在三年内开设两倍的商店。
不能简单地用新铁为ERP系统供料,也无济于事。 因此,首先,我们决定在发布周期中包括一种软件优化技术,并遵循以下规则:线性负载增长与负载驱动器增长成比例是可预测性和可伸缩性的关键。
什么是优化技术? 这是一个循环过程,分为几个阶段:
- 监视(确定系统中的瓶颈并确定资源的主要使用者)
- 分析(消费者过程的概要分析,对负载有最大和非线性影响的结构的识别)
- 发展(减少结构对载荷的影响,实现线性载荷)
- 在质量评估环境中进行测试或在生产环境中进行实施
接下来,重复该循环。
在此过程中,我们意识到当前的监视工具无法使我们快速确定主要消费者,瓶颈和资源消耗过程。 因此,为了加快速度,我们尝试了弹性搜索和Grafana工具。 为此,他们独立开发了收集器,这些收集器从Oracle / SAP / AIX / Linux中的标准监视工具将指标转移到弹性搜索中,并允许对系统运行状况进行实时监视。 此外,他们还通过自定义指标(例如,特定SAP组件的响应时间和吞吐量或业务流程的负载配置文件布局)丰富了监视功能。
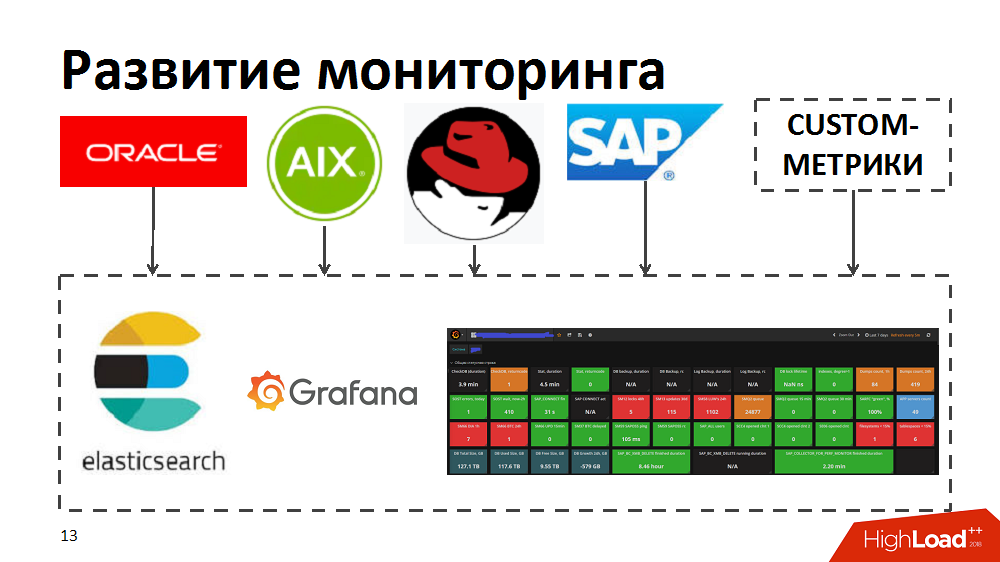
代码和流程优化
首先,为了减少瓶颈对速度的影响,它们确保了系统负载的平稳供应。
例如,我们ERP系统中的大多数业务流程(例如定期定价或库存补给计划)都是对大量数据(针对所有商品和所有商店)的顺序逐步处理。 为了在此类困难任务的框架中实现处理,我们一次开发了自己的批处理并行处理调度程序(以下称为负载调度程序)。 在这种情况下,以包装的形式呈现了针对单独的商店的单独执行的处理步骤。
最初,调度程序的逻辑是这样的:首先对所有存储执行第一处理阶段的软件包,然后对第二阶段的软件包等等。 也就是说,系统同时执行创建相同类型的负载并导致某些资源(输入/输出到数据库或应用程序服务器上的CPU等)的进程。
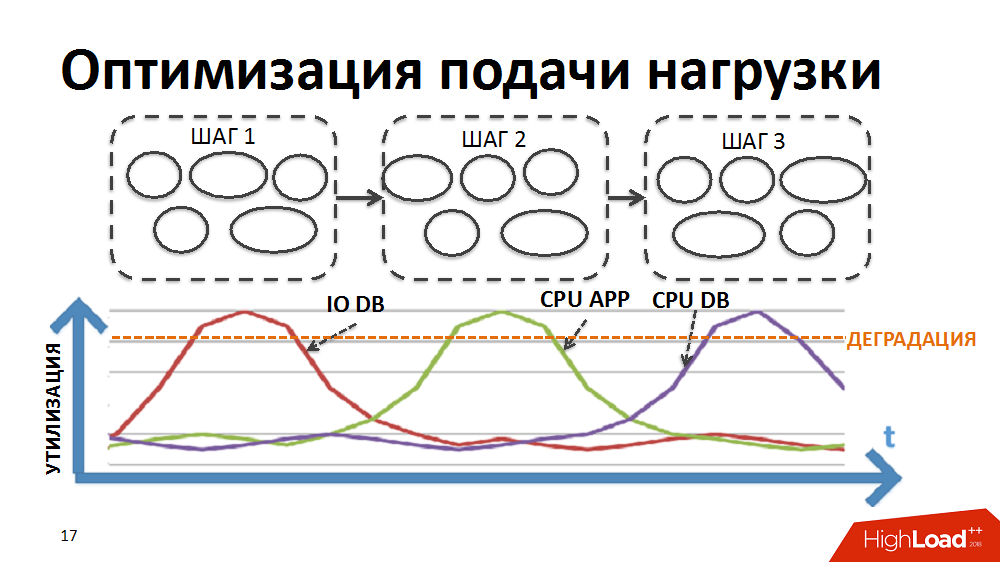
我们重写了调度程序的逻辑,以便为每个商店分别形成包裹链,并且启动新包裹的优先级不是按阶段而是按商店来构建。
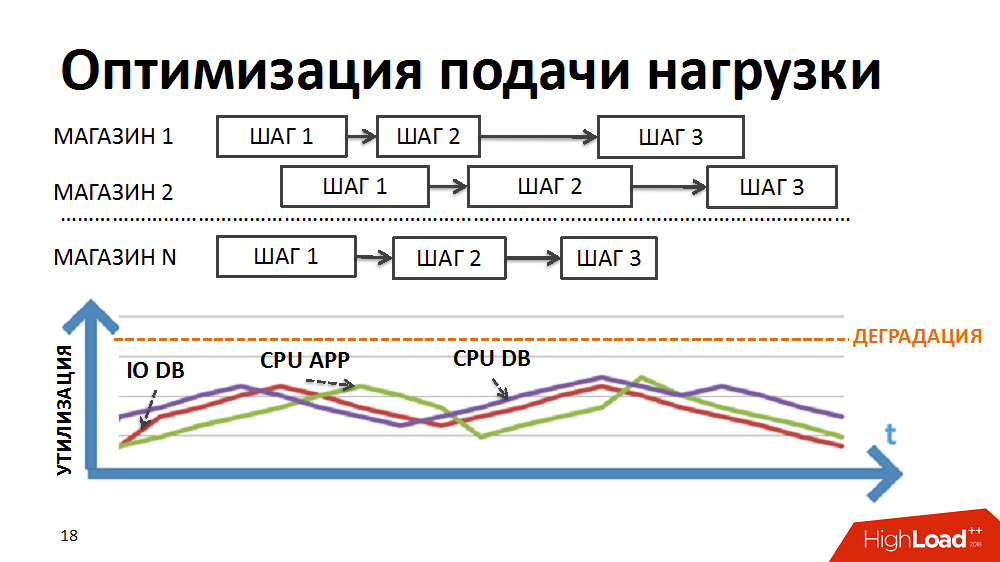
由于不同商店的软件包持续时间不同,并且在负载调度程序的任务框架内受控的大量同时执行的流程,我们实现了异类流程的同时执行,负载的平滑加载和消除了一些瓶颈。
然后他们开始优化单个设计。 对每个单独的包装进行审查,分析和组装非最佳设计,并采用优化它们的方法。 随后,这些方法已包含在开发人员的法规中,以防止在系统开发期间出现不希望的负载增长。 其中一些:
- 应用服务器CPU上的过多负载(通常由程序代码中的非线性算法生成,例如,循环中良好的老式线性搜索或用于查找无序元素集的交集的非线性算法等....通过替换线性算法来解决:用二进制替换循环中的线性搜索;要搜索集合的交集,我们使用线性算法,预排序元素等)
- 在相同的过程中以相同的条件对数据库进行相同的调用通常会导致数据库的CPU利用率过高(可通过将第一个样本的结果缓存在程序存储器中或应用程序服务器级别,并将缓存的数据用于后续样本来解决)
- 频繁的加入请求(当然最好在数据库级别执行它们,但是有时我们允许我们将它们分成简单的样本,并缓存其结果,然后将胶合逻辑传输到应用程序。在这种情况下,最好对应用程序服务器而非数据库进行热身。 )
- 大量的连接请求导致大量的I / O
关于后者的更多细节。 在这种情况下,数据模型被转换为不太普通的形式。 一个典型的例子是为各个商店选择特定日期的会计凭证。 许多员工都要求它。 主表(标题表)在位置表中存储文件的日期-商店和货物。 最常见的查询是在特定日期选择特定商店的所有文档。 有了此请求,标题表上的按日期筛选将给出50万条记录,按存储筛选-数量相同。 同时,在适当的日期粘贴到另一家商店后,我们有3000个学期。 无论我们从哪个表开始过滤和粘贴数据,我们总是会收到很多不需要的I / O。
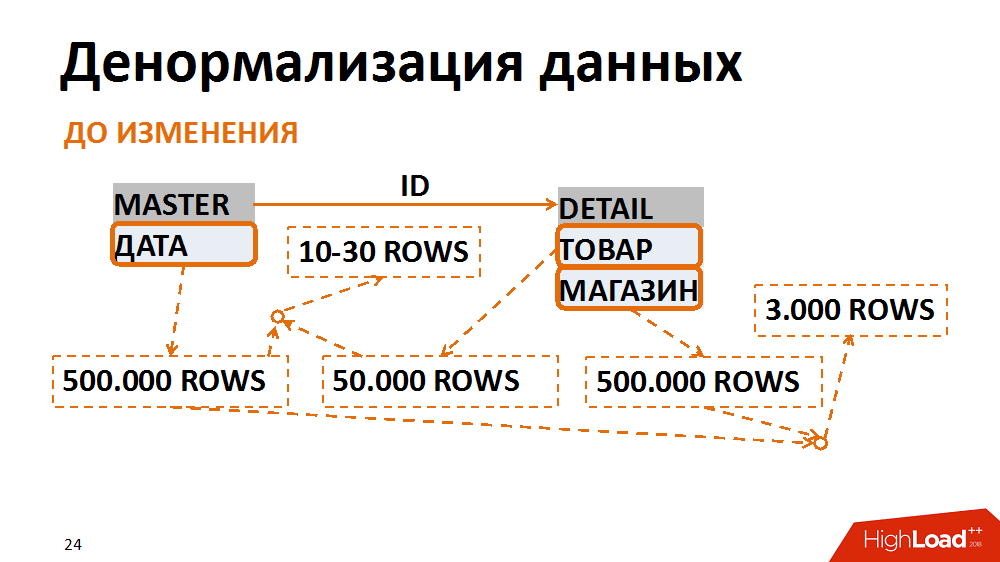
通过以不太普通的形式显示数据可以避免这种情况。 在一种情况下,日期字段在位置表中重复,在创建文档时将其填充,收集索引以进行快速搜索,并且已经根据位置表对其进行了过滤。 因此,在牺牲了微不足道的开销来存储新字段和索引之后,我们多次减少了有问题的查询所生成的输入/输出操作的数量。

2015.一站式服务的问题
一年半以来,我们在优化系统方面做得非常出色,它变得更加可预测。 尽管如此,将商店数量增加一倍的计划仍然具有现实意义,因此挑战仍然摆在我们面前。
在上升的过程中,我们遇到了各种瓶颈。 例如,在2015年底,他们意识到自己已经遇到了该平台一项核心服务的性能。 这是一个SAP ABAP逻辑锁定服务。 因此,系统显然无法承受负载的增长。 大笔钱的损失隐约可见。
为了明确起见,服务的任务是将逻辑事务性带到应用程序服务器级别。 在ABAP中,单个事务可以在不同的工作流程上经历多个步骤。 为了完成交易,提供了锁定服务和相关机制。 其中的锁定和解锁操作很快发生,但是它们是原子的,无法分开。 同步I / O存在问题。
在SAP开发人员发布特殊补丁后,该服务有所加速,我们将服务切换到另一种硬件并进行了系统设置,但这还不够。 护照服务的上限大约是每秒7千次操作,长期以来,我们已经需要1万次。
经过综合负载测试后,发现性能下降是非线性的,但是我们仍处于服务性能边界,在该性能边界之上,整个ERP系统的性能下降是不可接受的。 一再致电给开发人员,结果令人失望-服务正常运行,在当前解决方案体系结构中我们只需要太多。 即使我们立即着手重做该解决方案的整个体系结构,也要花几个月的时间来维持当前系统的可操作性。
尝试延长锁服务寿命的第一个选择是加速I / O并写入文件系统。 什么啊 试用AIX的替代方法。 在最强大的Power-machine上将服务转移到Linux,并赢得了很多响应时间。 启用了文件系统的服务的行为与禁用了Aix的服务相同。 然后,我们将此代码转移到x86_64刀片服务器之一,并获得了比以前更加奇妙的缓坡性能曲线。 看起来很有趣。
可以假设AIX和Linux上的开发人员在上次测试中做了一些不同的事情,但是处理器体系结构在这里也产生了影响。
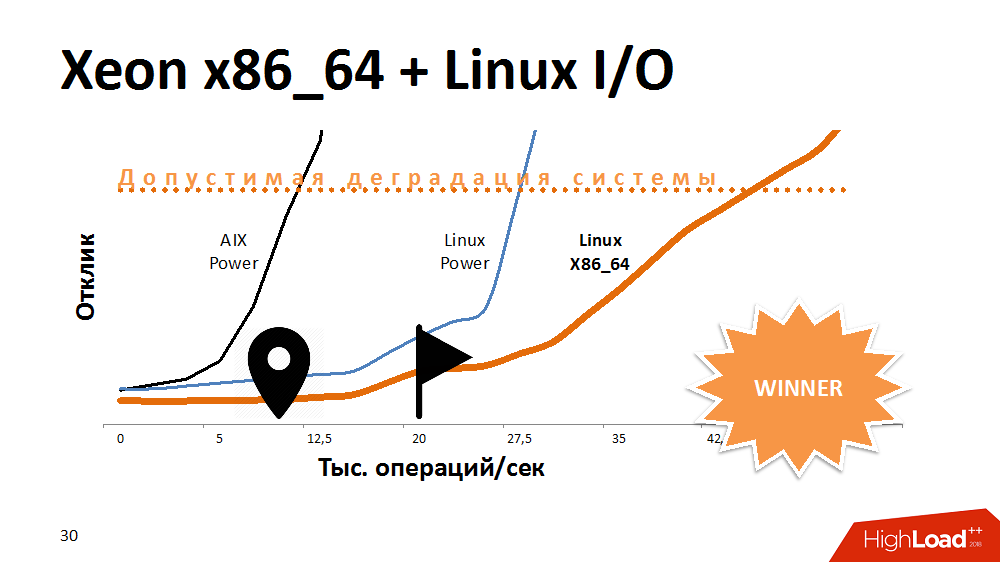
结论是什么? 某些平台非常适合多线程数据库,同时提供性能和容错能力,但是采用不同体系结构的处理器可以更好地应对特定任务。 如果开始构建放弃跨平台的解决方案,则将来可能会失去进行操作的空间。
但是,我们发现了这个问题,该服务开始运行的速度提高了3-4倍,这足以实现非常长的增长。
2016. DB CPU瓶颈
从字面上看,六个月后,数据库中的CPU开始出现异常问题。 显然,随着负载的增加,处理器资源的消耗也随之增加。 但是SysTime开始占用大部分时间,并且内核中显然存在问题。 他们开始理解并进行综合负载测试,并意识到我们的吞吐量为每秒30万次操作,即 每小时十亿个请求,然后降级。
结果,我们得出的结论是,完美的请求是不存在的。 我们用新方法扩展了优化技术,并对ERP系统进行了审核:例如,我们开始搜索效率低下的查询(10万个选择-作为100行或0的结果)以重做。 如果无法删除“空”请求,则在适当的情况下让它们进入“负缓存”。 如果对同一产品数据的许多请求被并行处理,则让它们折磨应用程序服务器而不是数据库,我们将其缓存。 我们还将在一个过程的框架内“扩大”对某个键的大量频繁的单个查询,用一部分键中更罕见的选择代替它。 或者,例如,为了在处理链中分配负载,可以在不同的应用程序服务器上执行不同的步骤。 这很好,但是在不同阶段,他们可以向基地提出相同的要求。 然后,在应用程序缓存部分请求之后,让第一步开始,并保留在那里以完成其余部分。

在这些技巧的帮助下,我们到处都赢了一点,但是最后我们认真地卸下了基地。 该系统栩栩如生。 同时,我们回到了Aix。
其他实验表明存在性能上限-已经提到的每秒300,000个数据库调用。 问题的根源在于网络接口的性能,它有一个上限-在一个方向上每秒约30万个数据包。 随着上限越来越近,系统调用的时间也越来越长。 后来证明,它也是AIX内核网络堆栈的遗留物。
总的来说,我们从来没有等待时间的问题,网络的核心是高效的,所有的电线都被组装到一个接口上的一个坚不可摧的大通道中。 我们采取了一种解决方法:将应用程序服务器和数据库之间的整个网络划分为不同接口上的组。 结果,每组应用服务器都通过其自己的单独接口与数据库进行通信。 每个接口的最大性能略有降低,但总的来说,我们在一个方向上将网络超频至每秒100万个数据包。
对于开发人员,Talmud中增加了“最好的请求就是不存在的请求”原则,因此在编写代码时要考虑到这一点。
2017.现场升级
好吧,我们系统恢复的最后阶段已于2017年结束。 剩下的就是要活到升级,并且有必要保留SLA。 代码已经过优化,但是我们发现数据库CPU的负载越高,进程的运行速度就越慢,尽管利用率为10-20%。 最初,估计100%是50%的两倍。 如果储备金为10-20%,则为10-20%。 实际上,在高于67-80%的负载下,任务的持续时间会非线性地增加,即 阿姆达尔的法律奏效。 该系统具有并行化限制,当超出并行化限制时,随着工作中越来越多的处理器的参与,每个处理器的性能都会下降。
当时,考虑到AIX级别的多线程,我们使用了125个物理处理器或500个逻辑处理器。 你有什么建议? 升级? 甚至在协调结束之前,有必要坚持几个月而不放弃SLA。
在某些时候,他们意识到传统的处理器利用率指标并不代表我们-它们没有显示降级的实际开始。 为了对系统的运行状况进行实际评估,我们开始使用集成度量标准-综合测试的结果作为数据库处理器性能的度量标准。 他们每分钟进行一次综合测试,测量其持续时间,并将此指标显示在我们的监视器上。 如果指标上升到宣布的临界点以上,他们就会做出反应。 我们将负载计划程序的负载保持了一点,使其保持在数据库的“最大扭矩”区域中。
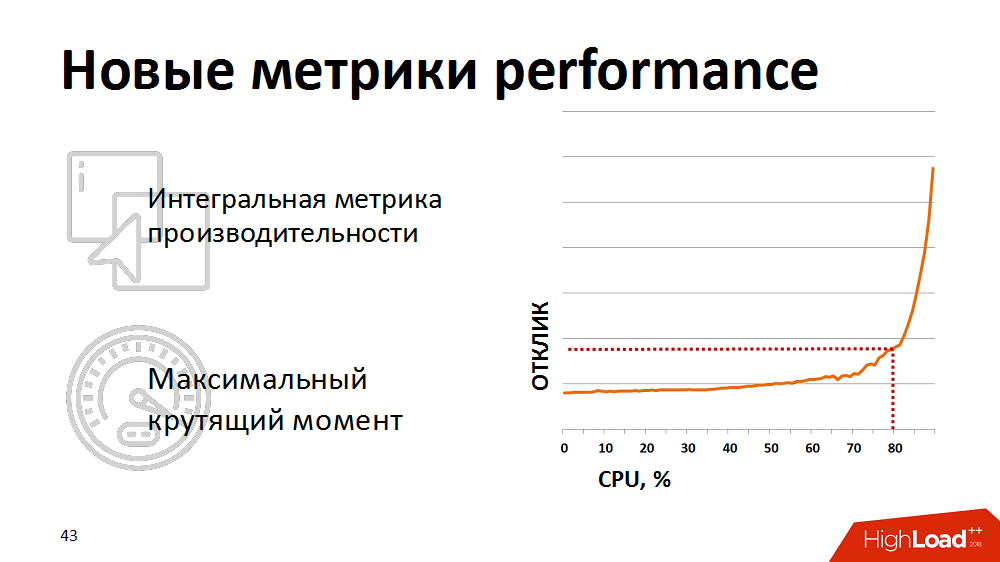
但是,手动控制效果不佳,让我们厌倦了晚上醒来。 然后,我们重写了负载计划程序,以便他获得有关当前性能指标的反馈。 如果指标超出黄色阈值(请参见图片),则低优先级软件包的计划将被冻结,只有关键业务流程才获得优先级。 因此,我们能够自动控制负载的强度,并有效地利用了资源。 最有趣的是,将系统保持在负载的80%以内,在最大扭矩的相同区域内,我们最终减少了执行业务流程的总时间,因为 每个线程开始更快地工作。
针对使用高负载ERP的人员的一些技巧
- 在项目开始时监视系统的性能非常重要,尤其是使用它们自己的指标时。
- 确保负载与负载驱动程序数量的增加成比例地线性增加(在我们的示例中,这些是商品和商店)。
- 消除代码中的非线性结构,使用缓存消除相同的数据库查询。
- 如果需要将负载从数据库CPU转移到应用程序服务器CPU,则可以将连接请求拆分为简单样本。
- 对于所有优化,请记住快速请求是好的,而快速频繁的请求有时是不好的。
- 尝试始终探索并利用异构解决方案环境。
- 与传统的性能指标一起,使用可以唯一识别性能下降的集成指标;使用此度量,确定系统的“最大扭矩”区域。
- 为负载计划工具提供监视当前性能指标和管理负载流率的机制,以有效利用系统资源
我们感谢Highload的组织者有机会在Habré上以及在高负载系统上最大的活动的舞台上分享这一经验。
#ITX5的SAP专家Dmitry Tsvetkov和Alexander Lishchuk,顺便说一句,#ITX5正在寻找 SAP顾问。