
这一切开始变得很糟糕-一年来,我的公司一直每月支付一项服务,该服务知道如何在照片中找到带有牌照的区域。 此功能用于自动为某些客户端绘制数字。
晴天,乌克兰内政部开放
了车辆登记册 。 现在,使用车牌就可以检查有关汽车的一些信息(品牌,型号,制造年份,颜色等)! 在执行新任务之前,无聊的线性编程例程已经消失了-读取整个照片库中的数字并使用用户指定的数据验证该数据。 您自己知道它是如何发生的,“让您大开眼界”-呼叫被接受,所有其他任务变得无聊又单调……我们开始工作并取得了良好的结果,实际上,我们决定与社区分享。
供参考:每天向网站AUTO.RIA.com添加100,000张照片。
数据专家已经知道并能够解决此类问题,因此,
我和
dimabendera专门为程序员撰写了本文。 如果您不惧怕“卷积网络”这个短语,并且知道如何用python编写“ Hello World”,那么在目录下,欢迎您...
还有谁认识
一年前,我研究了这个市场,结果发现并没有多少服务和软件可以使用exUSSR国家/地区号码。 以下是我们合作的公司列表:
- 有一个开源和商业版本。 开源版本显示出非常低的识别率,此外,它的组装和操作都需要特定的依赖关系(我们并不特别喜欢它)。 商业版本,或者说商业服务,效果很好。 能够使用俄罗斯和乌克兰数字。 价格适中-每月49 $ / 50K识别。 OpenALPR在线演示
- 我们已经使用这项服务大约一年了。 质量很好。 他发现该地区的人数非常好。 该服务不知道如何处理乌克兰和欧洲号码。 值得注意的是,对于低质量的图像(在雪中,低分辨率的照片等中),它的出色工作。 服务的价格也是可以接受的,但是他们不愿意小批量购买。
有许多带有封闭软件的商业系统,但是我们没有找到一个好的开源实现。 实际上,这很奇怪,因为长期以来一直存在作为解决此问题的基础的开源工具。
需要哪些工具来识别数字
在图像或视频流中查找对象是计算机视觉领域的一项任务,可以通过不同的方法来解决,但通常是借助所谓的卷积神经网络来解决。 我们不仅需要找到照片中找到所需对象的区域,还需要将其所有点与其他对象或背景分开。 这种任务称为“实例细分”。 下图显示了不同类型的计算机视觉任务。
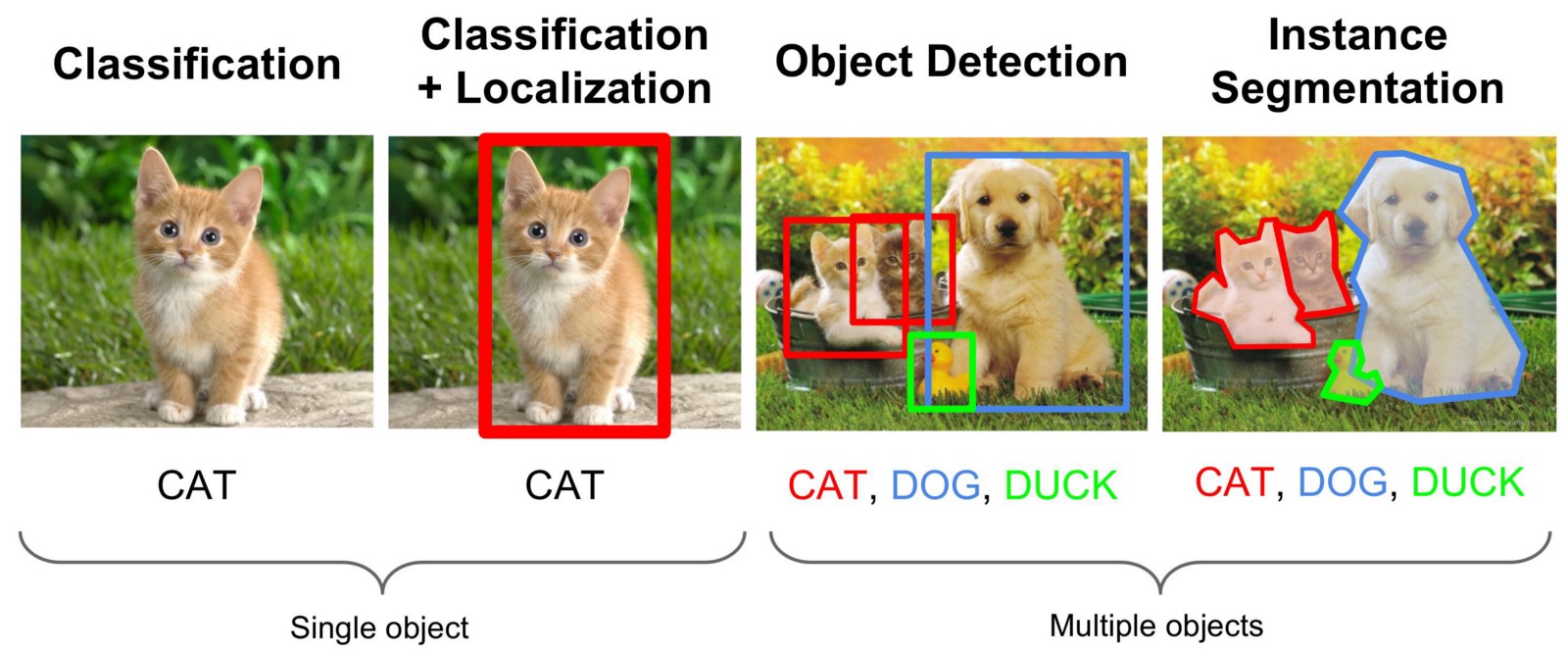
我不会写很多关于卷积网络如何工作的理论,这些信息在网络上已经足够,在YouTube上也有报道。
从用于卷积任务的卷积数组的现代体系结构中,它们经常使用:
U-Net或
Mask R-CNN 。 我们选择了Mask R-CNN。
我们需要的第二个工具是文本识别库,该库可以使用不同的语言,并且可以轻松地针对要识别的文本的特定内容进行自定义。 这里的选择不是那么好,最高级的是来自Google的
tesseract 。
还有许多较少的“全局”工具,我们将需要使用这些工具来对车牌区域进行标准化(以能够进行文本识别的方式进行运输)。 通常,opencv用于此类转换。
同样,可以尝试确定车牌号码所属的国家和类型,以便在后处理中,我们应用特定于该国家和该号码类型的优化模板。 例如,从2015年开始以蓝色和黄色装饰的乌克兰车牌由“两个字母四个数字两个字母”模板组成。

此外,通过统计字母或数字的特定组合在车牌中“开会”的频率,可以提高“有争议”情况下的后处理质量。 ”
诺默罗夫网
从文章的标题可以明显看出,我们所有人都已实施并命名了项目
Nomeroff Net 。 现在,此项目的部分代码已在
AUTO.RIA.com上
投入生产。 当然,它离商业类似物还很远;一切都只适用于乌克兰数字。 此外,只有在GPU模块tensorflow的支持下才能达到可接受的速度! 没有GPU,您也可以尝试,但不能在Raspberry Pi上尝试:)。
我们项目的所有材料: 标记的数据集和经过训练的模型 ,我们已根据Creative Commons CC BY 4.0许可在RIA.com的许可下公开发布
我们需要什么
我和Dmitry都在Fedora 28上运行,我确信它都可以安装在任何其他Linux发行版上。 我不想将这篇文章变成安装和配置tensorflow的说明,如果您想尝试但仍无法解决问题-在评论中提问,我会回答并告诉您。
为了加快安装速度,我们计划创建一个dockerfile-在项目的下一次更新中期望。
Nomeroff Net“ Hello world”
让我们尝试识别一些东西。 我们正在
使用github中的代码克隆
存储库 。 我们将下载
经过训练的模型搜索到Models文件夹中,以进行数字搜索和分类,然后我们将根据文件夹的位置略微调整变量。
UPD:不推荐使用此代码,它仅
在0.1.0分支中有效 ,
请参见此处的最新示例 :
一切都可以识别:
import os import sys import json import matplotlib.image as mpimg
在线演示
他们为那些不想安装和运行所有这些程序的人绘制了一个
简单的演示 :)。 对脚本的速度要宽容和耐心。
如果需要乌克兰数字示例(用于检查校正算法的操作),请
从此文件夹中获取示例
。接下来是什么
我知道这个话题非常小众,不太可能引起广泛的程序员的兴趣,此外,代码和模型在识别质量,速度,内存消耗等方面仍然很“原始”。但是仍然希望有爱好者谁会对他们的需求,他们的国家/地区的培训模型感兴趣,谁会帮助您并告诉您哪里有问题,并且与我们一起使该项目不会比商业同行更糟糕。
已知问题
- 该项目没有文档,只有基本的代码示例。
- 作为识别模块,选择了通用OCR tesseract,它可以读取很多内容,但是会犯很多错误。 在识别乌克兰数字的情况下,会在此处编写一个专门的校正系统,该系统到目前为止可以弥补一些错误,但是直觉上可以在此处完成更多工作。
- “正方形”数字(比例为1:2的车牌)非常少见,我们刚刚开始处理它们,因此它们会有更多错误。
- 有时,我们的模型会代替牌照来查找带有村庄名称的路标,机舱内的仪表板以及其他人工制品。
- 数字质量差或分辨率低时,无法完全确定4点的区域
公告公告
如果对某人感兴趣,那么在第二部分中,我们将讨论如何以及如何标记数据集,以及如何训练适合您的内容(您所在的国家/地区,您的照片尺寸)的模型。 我们还将讨论如何创建自己的分类器,例如,这将有助于确定数字是否在照片上绘制。
Jupyter Notebook中的一些示例:
有用的链接