是否曾有人要求您根据上个月数据库中的数据来计算某物的数量,将结果按一些值分组,然后按天/小时将其细分?
如果是,那么您已经想象过必须写这样的东西,只会更糟
SELECT hour(datetime), somename, count(*), sum(somemetric) from table where datetime > :monthAgo group by 1, 2 order by 1 desc, 2
有时,各种各样的此类请求开始出现,如果您一次忍受并提供帮助,可惜,将来会发出上诉。
但是这样的请求是不好的,因为它们在运行时会大量消耗系统资源,并且可能有太多的数据,即使是此类请求的副本也很可惜(及其时间)。
但是,如果我说对了,就可以在PostgreSQL中创建一个视图,使其仅在直接类似的查询中仅考虑新传入的数据,如上所述呢?
所以-它可以扩展PipelineDB
PipelineDB以前是一个单独的项目,但现在可作为PG 10.1及更高版本的扩展。
尽管提供的机会在专门设计用于收集实时指标的其他产品中早已存在,但PipelineDB具有显着的优点:对于已经了解SQL的开发人员而言,入门门槛较低。
也许对于某些人来说不是必需的。 就我个人而言,我不太愿意尝试所有似乎适合解决特定问题的方法,但是我不会立即采取行动针对所有情况使用一种新的解决方案。 因此,在本文中,我不敦促删除所有内容并立即安装PipelineDB,这只是主要功能的概述,因为 这件事对我来说似乎很好奇。
因此,总的来说,他们有很好的文档,但是我想分享我的经验,以实践方式尝试这项业务并将结果带给Grafana。
为了不乱扔本地计算机,我将所有内容都部署在docker中。
使用的图像:
postgres:latest ,
grafana/grafana在Postgres上安装PipelineDB
在具有postgres的计算机上,按顺序执行:
apt updateapt install curlcurl -s http://download.pipelinedb.com/apt.sh | bashapt install pipelinedb-postgresql-11cd /var/lib/postgresql/data- 在任何编辑器中打开
postgresql.conf文件 - 查找
shared_preload_libraries键,取消注释并设置pipelinedb值 - 关键
max_worker_processes设置为128(推荐max_worker_processes ) - 重新启动服务器
在PipelineDB中创建流和视图
- 我们将在其中工作的数据库:
CREATE DATABASE testpipe; - 创建扩展:
CREATE EXTENSION pipelinedb; - 现在,最有趣的是创建流。 您需要在其中添加数据以进行进一步处理:
CREATE FOREIGN TABLE flow_stream ( dtmsk timestamp without time zone, action text, duration smallint ) SERVER pipelinedb;
实际上,这与创建普通表非常相似,您不能仅通过简单的select就可以从此流中获取数据-您需要一个视图 - 实际如何创建它:
CREATE VIEW viewflow WITH (ttl = '3 month', ttl_column = 'm') AS select minute(dtmsk) m, action, count(*), avg(duration)::smallint, min(duration), max(duration) from flow_stream group by 1, 2;
它们被称为“ 连续视图” ,默认为实现,即 保留国家。
WITH传递其他参数。
在我的情况下, ttl = '3 month'意味着您只需要存储最近3个月的数据,并从M列获取日期/时间M 后台reaper程序reaper过时的数据并将其删除。
对于那些不知道的人, minute功能返回没有秒的日期/时间。 因此,由于聚合,在一分钟内发生的所有事件将具有相同的时间。 - 这种视图几乎是一张表,因为如果存储了大量数据,则按日期进行索引的索引将非常有用
create index on viewflow (m desc, action);
使用PipelineDB
切记:将数据插入流中,并从订阅它的视图中读取
insert into flow_stream VALUES (now(), 'act1', 21); insert into flow_stream VALUES (now(), 'act2', 33); select * from viewflow order by m desc, action limit 4; select now()
首先,我看第46分钟的数据变化
第47号到来时,前一号将停止更新,而当前分钟将开始计时。
如果您注意查询计划,则可以看到带有数据的原始表
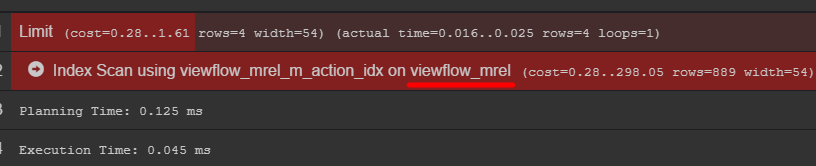
我建议您去了解一下如何真正存储您的数据
C#事件产生器 using Npgsql; using System; using System.Threading; namespace PipelineDbLogGenerator { class Program { private static Random _rnd = new Random(); private static string[] _actions = new string[] { "foo", "bar", "yep", "goal", "ano" }; static void Main(string[] args) { var connString = "Host=localhost;port=5432;Username=postgres;Database=testpipe"; using (var conn = new NpgsqlConnection(connString)) { conn.Open(); while (true) { var dt = DateTime.UtcNow; using (var cmd = new NpgsqlCommand()) { var act = GetAction(); cmd.Connection = conn; cmd.CommandText = "INSERT INTO flow_stream VALUES (@dtmsk, @action, @duration)"; cmd.Parameters.AddWithValue("dtmsk", dt); cmd.Parameters.AddWithValue("action", act); cmd.Parameters.AddWithValue("duration", GetDuration(act)); var res = cmd.ExecuteNonQuery(); Console.WriteLine($"{res} {dt}"); } Thread.Sleep(_rnd.Next(50, 230)); } } } private static int GetDuration(string act) { var c = 0; for (int i = 0; i < act.Length; i++) { c += act[i]; } return _rnd.Next(c); } private static string GetAction() { return _actions[_rnd.Next(_actions.Length)]; } } }
结论在格拉法纳
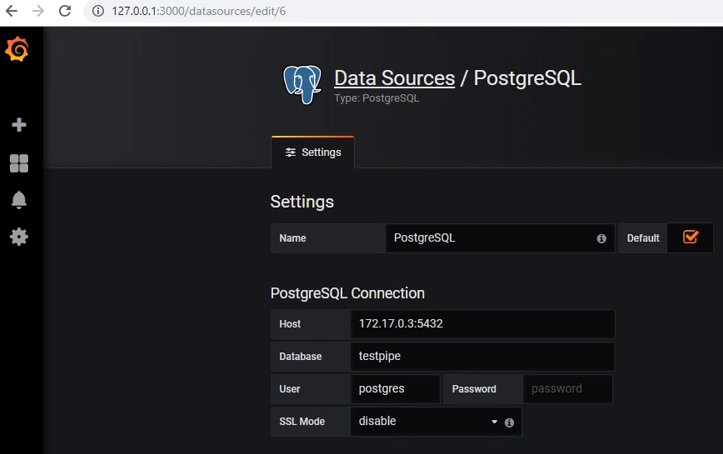
要从postgres获取数据,您需要添加适当的数据源:
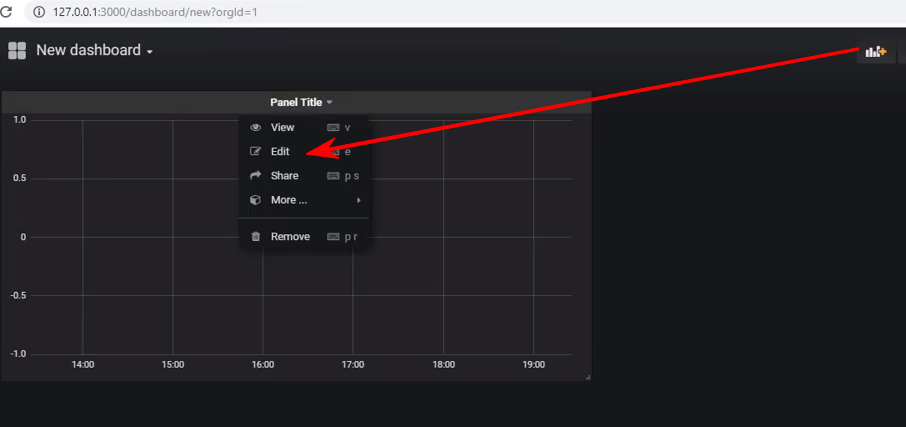
创建一个新的仪表板,并向其中添加一个Graph类型的面板,然后需要编辑该面板:
接下来-选择一个数据源,切换到sql-query写入模式并输入以下内容:
select m as time,
然后,如果您启动了事件生成器,那么您将获得正常的计划
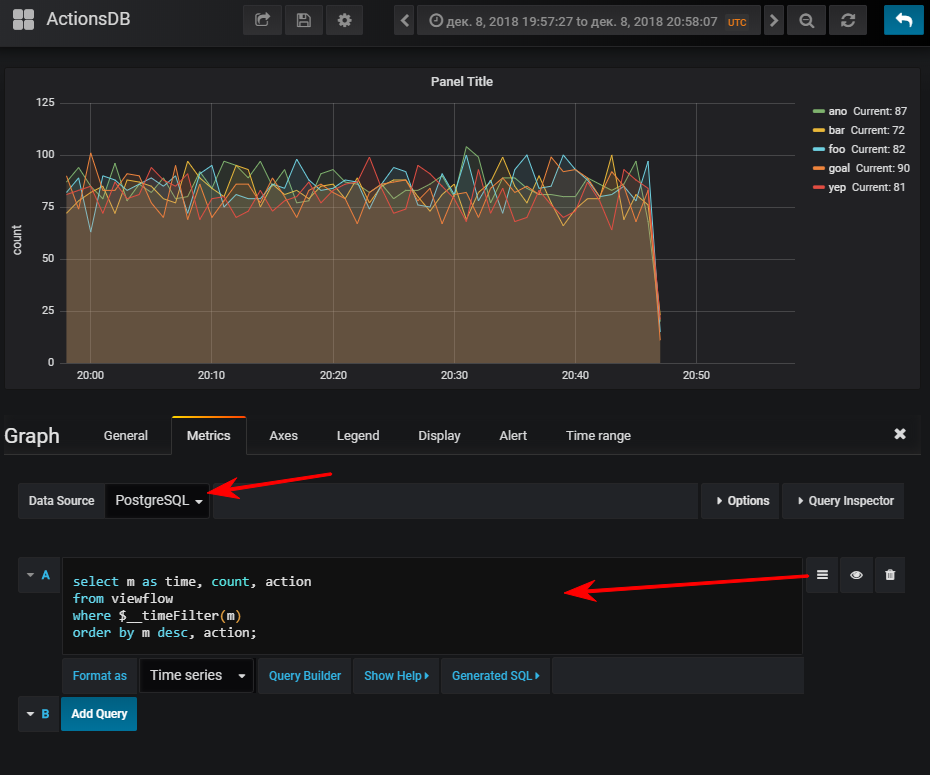
仅供参考:拥有索引可能非常重要。 尽管其用法取决于结果表的容量。 如果计划在少量时间内存储少量行,则很容易发现seq扫描会便宜一些,而索引只会增加额外的开销。 更新值时加载
可以将多个视图订阅到一个流。
假设我想查看百分位数执行多少个api方法
CREATE VIEW viewflow_per WITH (ttl = '3 d', ttl_column = 'm') AS select minute(dtmsk) m, action, percentile_cont(0.50) WITHIN GROUP (ORDER BY duration)::smallint p50, percentile_cont(0.95) WITHIN GROUP (ORDER BY duration)::smallint p95, percentile_cont(0.99) WITHIN GROUP (ORDER BY duration)::smallint p99 from flow_stream group by 1, 2; create index on viewflow_per (m desc);
合计
总的来说,它运行良好,运行良好,没有任何抱怨。 尽管在docker下,但将他们的演示数据库下载到存档(2.3 GB)中却有点长。
我想指出-我没有进行压力测试。
官方文件可能很有趣