
在续写有关如何使Kubernetes的日常工作变得更轻松的实用文章时,我们讨论了操作世界中的两个故事:为特定任务分配单个节点以及为重负载配置php-fpm(或另一个应用程序服务器)。 和以前一样,此处描述的解决方案并不是理想的解决方案,但是可以作为您特定案例的起点和反思的基础。 欢迎提出问题和改进意见!
1.为特定任务分配单个节点
我们正在虚拟服务器,云或裸机服务器上建立一个Kubernetes集群。 如果将所有系统软件和客户端应用程序安装在同一节点上,则可能会出现问题:
- 尽管客户端应用程序的限制非常高,但它会突然开始从内存中“泄漏”。
- 对日志库,Prometheus或Ingress的复杂一次性请求导致OOM,导致客户端应用程序遭受苦难;
- 尽管组件可能未在逻辑上相互连接,但由于系统软件中的错误而导致的内存泄漏会杀死客户端应用程序。
*除其他事项外,它与Ingress的较旧版本有关,由于大量的WebSocket连接和nginx的不断重载,出现了“悬挂nginx进程”,总数达数千个,并消耗了大量资源。真正的案例是安装了具有大量指标的Prometheus,其中在查看“大量”仪表板时,该仪表板上显示了大量应用程序容器,并从每个图表中绘制了图表,内存消耗迅速增长到了约15 GB。 结果,OOM杀手可能会“出现”在主机系统上并开始杀死其他服务,从而导致“集群中应用程序的行为难以理解”。 而且由于客户端应用程序上的CPU负载很高,很容易获得不稳定的Ingress查询处理时间...
该解决方案很快提示自己:有必要为不同的任务分配单独的计算机。 我们确定了3种主要的任务组类型:
- Fronts ,我们仅放置Ingress,以确保没有其他服务可以影响请求的处理时间;
- 我们在其上部署VPN , loghouse , Prometheus ,Dashboard,CoreDNS等的系统节点 ;
- 应用程序的节点 -实际上是客户端应用程序推出的地方。 还可以为环境或功能分配它们:dev,prod,perf,...
解决方案
我们如何实现呢? 很简单:两种原生的Kubernetes机制。 第一个是
nodeSelector ,它根据每个节点上
安装的标签来选择应用程序应到达的所需节点。
假设我们有一个
kube-system-1节点。 我们为其添加一个附加标签:
$ kubectl label node kube-system-1 node-role/monitoring=
...,然后在应该
Deployment到该节点的
Deployment ,我们编写:
nodeSelector: node-role/monitoring: ""
第二种机制是
污点和宽容 。 在它的帮助下,我们明确指出在这些机器上,只能启动可以承受此异味的容器。
例如,有一台
kube-frontend-1机器,我们只会在其上滚动Ingress。 将异味添加到此节点:
$ kubectl taint node kube-frontend-1 node-role/frontend="":NoExecute
...在
Deployment我们创建容忍度:
tolerations: - effect: NoExecute key: node-role/frontend
对于kops,可以为相同的需求创建单个实例组:
$ kops create ig --name cluster_name IG_NAME
...,您会在kops中得到类似此实例组配置的内容:
apiVersion: kops/v1alpha2 kind: InstanceGroup metadata: creationTimestamp: 2017-12-07T09:24:49Z labels: dedicated: monitoring kops.k8s.io/cluster: k-dev.k8s name: monitoring spec: image: kope.io/k8s-1.8-debian-jessie-amd64-hvm-ebs-2018-01-14 machineType: m4.4xlarge maxSize: 2 minSize: 2 nodeLabels: dedicated: monitoring role: Node subnets: - eu-central-1c taints: - dedicated=monitoring:NoSchedule
因此,该实例组中的节点将自动添加其他标签和异味。
2.为重负载配置php-fpm
有许多用于运行Web应用程序的服务器:php-fpm,gunicorn等。 它们在Kubernetes中的使用意味着您应该始终考虑以下几点:
- 有必要大致了解我们愿意在每个容器的php-fpm中分配多少工人 。 例如,我们可以分配10个工人来处理传入的请求,为pod分配较少的资源,并使用pod的数量进行扩展-这是一个好习惯。 另一个例子是为每个吊舱分配500名工人,并在生产中拥有2-3个这样的吊舱...但这是一个非常糟糕的主意。
- 需要进行活动/就绪测试以验证每个Pod的正确操作,以及由于网络问题或数据库访问(可能有任何选择和原因)Pod被“卡住”的情况。 在这种情况下,您需要重新创建有问题的窗格。
- 重要的是,显式注册每个容器的请求并限制资源 ,以使应用程序不会“流动”并且不会开始损害此服务器上的所有服务。
解决方案
不幸的是,
没有灵丹妙药可以帮助您立即了解应用程序可能需要多少资源(CPU,RAM)。 一个可能的选择是观察资源消耗并每次选择最佳值。 为了避免不合理的OOM kill'ov和节流CPU,从而严重影响服务,可以提供:
- 添加正确的活动/就绪测试,以便我们可以肯定地说此容器工作正常。 很有可能是一个服务页面,该页面检查所有基础结构元素的可用性(应用程序在pod中工作所必需),并返回200 OK响应代码;
- 正确选择将处理请求并正确分发请求的工作人员数量。
例如,我们有10个Pod,由两个容器组成:nginx(用于向后端发送静态消息和代理请求)和php-fpm(实际上是后端,用于处理动态页面)。 php-fpm池配置为静态数量的工作程序(10)。 因此,在一个时间单位内,我们可以处理100个对后端的活动请求。 让每个请求在1秒内由PHP处理。
如果在一个特定的Pod中又有1个请求到达,现在正在积极处理10个请求,会发生什么情况? PHP将无法对其进行处理,并且如果它是GET请求,则Ingress会将其发送以重试到下一个pod。 如果有POST请求,它将返回一个错误。
并且如果考虑到在处理所有10个请求期间,我们将收到来自kubelet(活动性探针)的检查,它将以错误结尾,并且Kubernetes将开始认为此容器有问题并将其杀死。 在这种情况下,当前处理的所有请求都将以错误(!)结束,并且在重新启动容器时,它将失去平衡,这将导致对所有其他后端的请求增加。
明显地
假设我们有2个Pod,每个Pod配置了10个php-fpm worker。 这是一个在“停机时间”期间显示信息的图表,即 当唯一一个请求php-fpm的是php-fpm exporter时(我们每个都有一个工作线程):
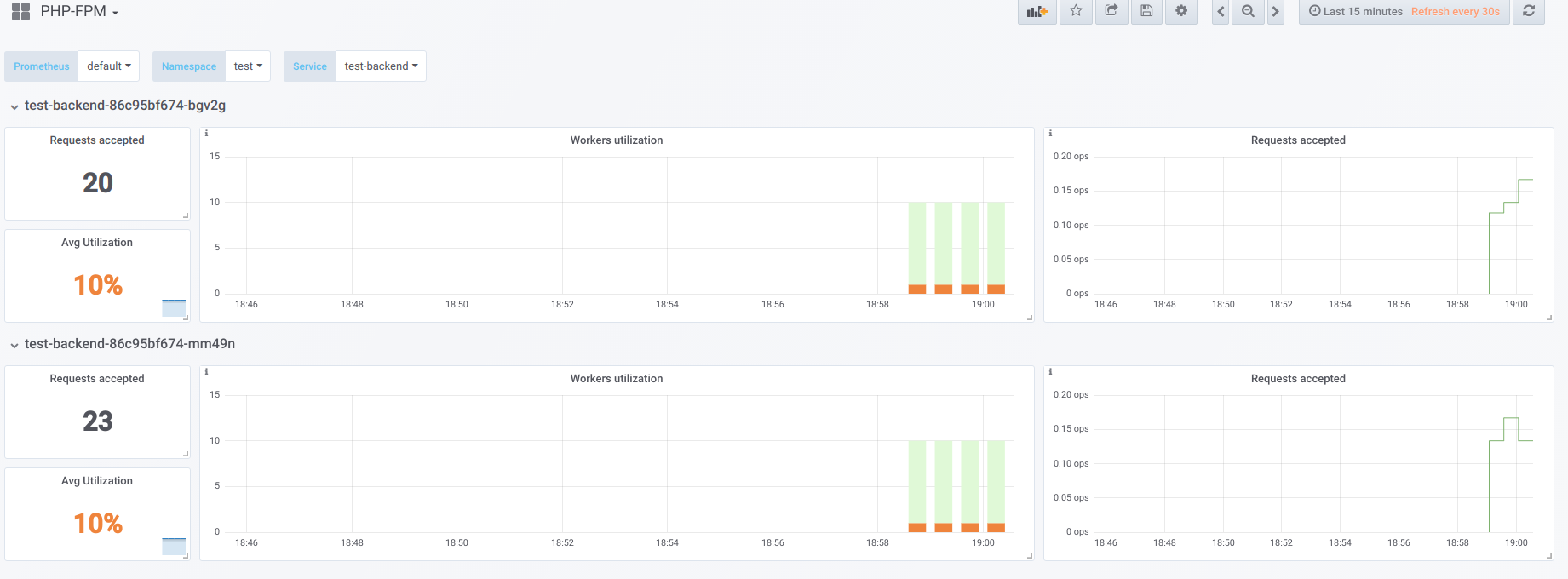
现在以并发19启动启动:
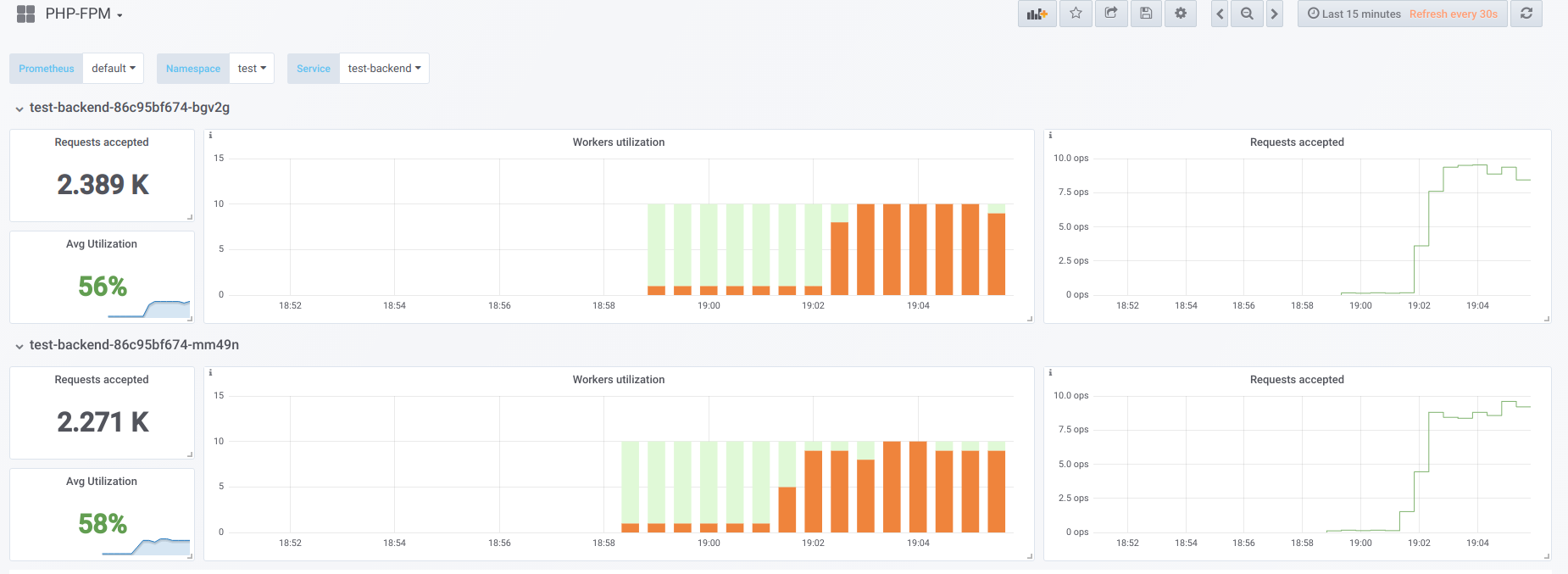
现在让我们尝试使并发性超过我们可以处理的(20)...假设23。然后所有php-fpm工作人员都在忙于处理客户端请求:

Vorkers不再足以处理活动样本,因此我们在Kubernetes仪表板(或
describe pod )中看到了这张图片:

现在,当其中一个Pod重新启动时,
会发生雪崩效应 :请求开始落在第二个Pod上,第二个Pod也无法对其进行处理,因此,我们从客户端收到了很多错误。 在所有容器的池都装满之后,提高服务水平是有问题的-只有通过大量增加吊舱或工人的数量才有可能。
第一选择
在使用PHP的容器中,您可以配置2个fpm池:一个用于处理客户端请求,另一个用于检查容器的“生存能力”。 然后在nginx容器上,您需要执行类似的配置:
upstream backend { server 127.0.0.1:9000 max_fails=0; } upstream backend-status { server 127.0.0.1:9001 max_fails=0; }
剩下的就是将活动性样本发送到上游,称为
backend-status进行处理。
现在,活动性探针已单独处理,在某些客户端中仍然会发生错误,但是至少没有重新启动Pod和断开其余客户端的连接的问题。 因此,即使我们的后端无法应付当前的负载,我们也会大大减少错误的数量。
当然,此选项总比没有好,但是它也很糟糕,因为主池可能会发生某些事情,使用活动性测试我们将不知道。
第二选择
您还可以使用不太流行的nginx模块,称为
nginx-limit-upstream 。 然后在PHP中,我们将指定11个worker,在具有nginx的容器中,我们将进行类似的配置:
limit_upstream_zone limit 32m; upstream backend { server 127.0.0.1:9000 max_fails=0; limit_upstream_conn limit=10 zone=limit backlog=10 timeout=5s; } upstream backend-status { server 127.0.0.1:9000 max_fails=0; }
在前端级别,nginx将限制将发送到后端的请求数(10)。 有趣的一点是,创建了一个特殊的积压:如果第11个对nginx的请求来自客户端,并且nginx看到php-fpm池正忙,则此请求将被放置在积压中5秒钟。 如果在此期间php-fpm尚未释放,则只有Ingress才会生效,这会将请求重试到另一个pod。 由于我们将始终有1个免费的PHP工人来处理活动样本,因此可以使图像变得平滑-我们可以避免雪崩效应。
其他想法
对于解决此问题的更多用途和美观选项,值得向
Envoy及其类似物的方向看。
通常,为了使Prometheus能够清楚地雇用工人,这反过来将有助于快速发现问题(并通知问题),我强烈建议让现成的
出口商将数据从软件转换为Prometheus格式。
聚苯乙烯
K8s提示和技巧周期中的其他内容:
另请参阅我们的博客: