
每天有一百五十万人在奥松搜索各种各样的产品,对于每种产品,服务应选择类似的产品(如果吸尘器仍需要更强大的吸尘器)或相关的产品(如果唱歌的恐龙需要电池)。 当产品类型过多时,Word2Vec模型有助于解决该问题。 我们了解其工作原理以及如何为任意对象创建矢量表示。
动机
为了构建和训练模型,我们使用嵌入技术(机器学习的标准),当每个对象变成固定长度的向量,并且接近向量对应于接近对象时。 几乎所有已知的模型都要求输入数据的长度是固定的,而向量集是将其转换为这种形式的简便方法。
word2vec是最早的嵌入方法之一。 我们根据任务调整了此方法,我们使用产品作为单词,使用用户会话作为句子。 如果一切都清楚了,请随意浏览结果。
接下来,我将讨论模型的体系结构及其工作原理。 由于我们正在处理商品,因此我们需要学习如何构建对商品的描述,一方面包含足够的信息,另一方面对于机器学习算法可以理解。
在网站上,每个产品都有一张卡。 它由标题,文字说明,规格和照片组成。 我们还可以使用有关用户与产品交互的数据:视图,添加到购物篮或收藏夹中的数据都存储在日志中。
构造产品的矢量描述有两种根本不同的方法:
-使用内容-卷积神经网络从照片,循环网络或一袋单词中提取特征以分析文本描述;
-有关用户与产品互动的数据的使用:哪些产品以及产品看起来/与数据一起添加到购物篮的频率。
我们将专注于第二种方法。
Prod2Vec模型的数据
首先,让我们弄清楚我们使用什么数据。 我们可以使用网站上所有用户的点击次数,将它们划分为用户会话-一系列点击,相邻点击之间的间隔不超过30分钟。 为了训练模型,我们使用了大约1亿个用户会话的数据,在每个会话中,我们仅对查看产品并将其添加到购物篮感兴趣。
真实用户会话的示例:

会话中的每个产品都与其上下文相对应-用户在此会话中添加到购物篮中的所有产品,以及与此一起查看的产品。 prod2vec模型基于类似产品最经常具有相似上下文的假设。
例如:

因此,如果假设是正确的,则例如,相同手机型号的案例将具有相似的上下文(同一手机)。 我们将通过构建乘积向量来检验该假设。
型号Prod2Vec
当我们介绍产品的概念及其上下文时,我们描述了模型本身。 这是具有两个完全连接的层的神经网络。 第一层的输入数量等于我们要为其构建向量的乘积数量。 入口处的每个乘积将由带有一个单位的零向量进行编码-该乘积在字典中的位置。
第一层输出的神经元数量等于我们要获取的向量的维数,例如64。在最后一层的输出中,神经元的数量再次等于商品的数量。

我们将训练模型以预测上下文,并了解产品。 这种体系结构称为Skip-gram(替代方案是CBOW,我们根据上下文来预测产品)。 在训练过程中,货物被运送到入口,货物将从其上下文中输出(零向量,在相应位置有一个单位)。
从本质上讲,这是一个多类分类,并且可以使用交叉熵损失来训练模型。 对于上下文中的一个单词-单词对,其编写如下:
在哪里 -根据上下文对产品进行网络预测, -货物总数 -产品的网络预测 。
训练模型后,我们可以舍弃第二层-不需要它来获取向量。 第一层的权重矩阵(商品数量的大小x 64)是商品向量的字典。 每个乘积对应于长度为64的矩阵的一行-这是与乘积相对应的向量,可以在其他算法中使用。
但是此过程不适用于大量产品。 回想一下,我们有一百五十万。
为什么Prod2Vec不起作用
-损失函数包含许多获取指数的操作-这是一个长期且不稳定的计算。
-结果,考虑了所有网络权重的梯度-可能有数千万。
为了解决这些问题,采用负采样方法是合适的,我们不仅可以使用该方法教网络预测产品的上下文,还可以教示不预测上下文中不完全相同的产品。 为此,我们需要生成负面示例-对于每种产品,选择不需要对其进行预测的示例。 在这里,大量商品的可用性对我们有帮助。 当为产品选择随机对时,从上下文来看,它成为产品的可能性很小。
结果,对于上下文中的每个产品,我们随机生成5-10个未包含在上下文中的产品。 而且,货物不是按均匀分布抽样的,而是按其出现的频率成比例的。
损失函数现在类似于二进制分类中使用的函数。 对于上下文中的一个单词-单词对,它看起来像这样:
在这些符号中 表示第二层权重矩阵的一列,对应于上下文中的乘积; -对于随机选择的产品, -第一层权重矩阵的行与主要乘积相对应(这正是我们为其构建的向量)。 功能介绍 。
与先前版本的不同之处在于,我们不需要在每次迭代时更新所有网络权重,我们只需要更新与少量产品相对应的权重即可(第一个产品是我们预测的产品,其余产品是根据其上下文或随机选择的产品) 同时,我们在每次迭代中都摆脱了大量的指数捕获。
可以提高结果模型质量的另一种技术是二次采样。 在这种情况下,我们有意将不经常发现的商品用于培训,以便获得稀有商品的最佳结果。
结果
相关产品
因此,我们学习了如何获取商品的向量,现在我们需要检查模型的充分性和适用性。
下图显示了该产品及其最接近的邻居(以余弦度量)。
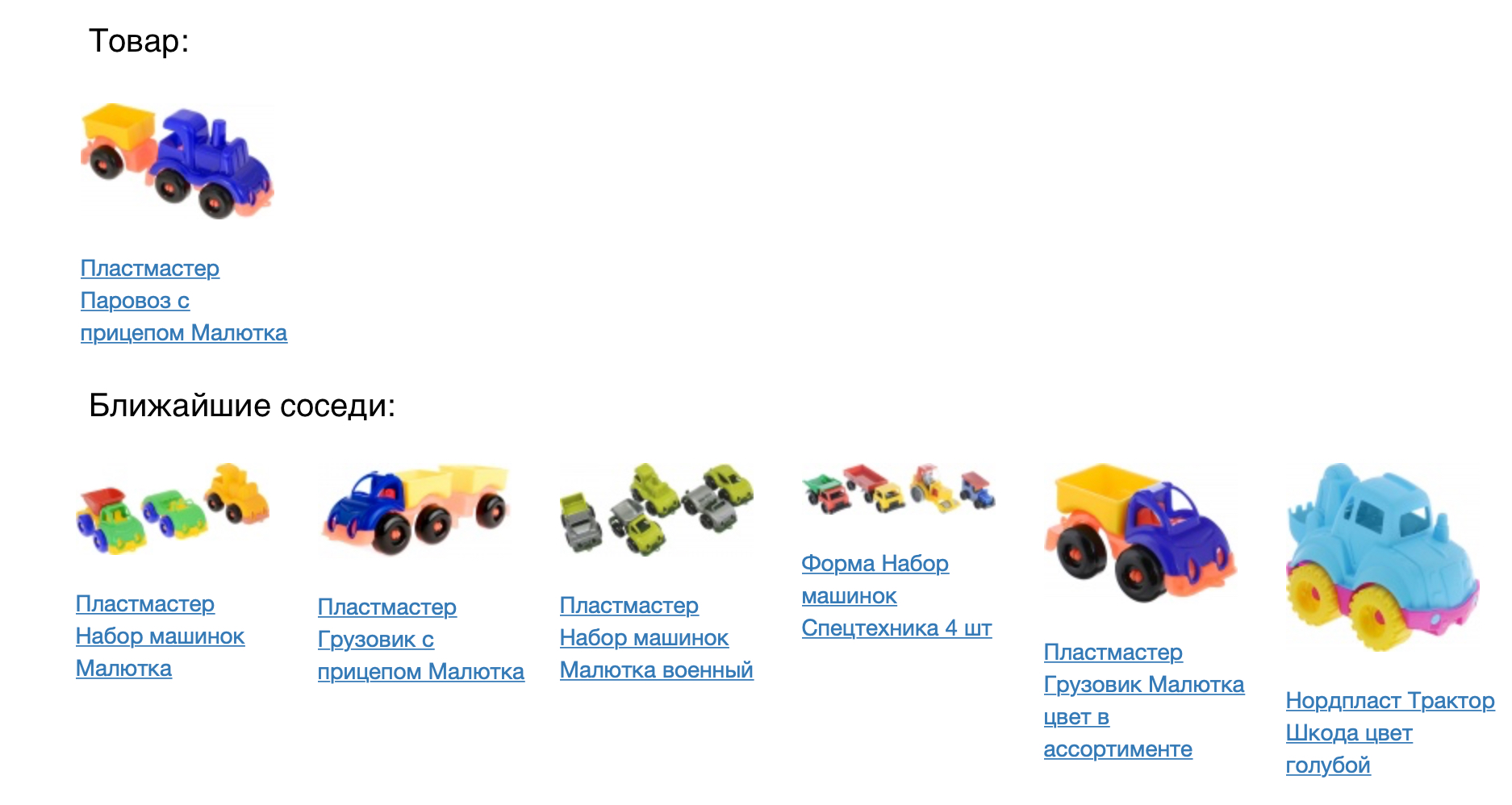
结果看起来不错,但是您需要从数字上检查我们的模型有多好。 为此,我们将其应用于产品推荐任务。 对于每种产品,我们建议进入构造的向量空间。 我们根据联合视图的统计数据和向购物篮中添加商品的方式,将prod2vec模型与一个简单得多的模型进行了比较。 对于会议中的每种产品,列出了7条建议。 会议中所有推荐产品的组合与一个人实际添加到购物篮中的组合进行了比较。 使用prod2vec,在超过40%的会话中,我们推荐了至少一种产品,然后将其添加到购物篮中。 为了进行比较,较简单的算法显示出34%的质量。
产生的向量描述使我们不仅可以搜索最接近的向量(可以通过更简单的模型来完成,尽管质量较差)。 我们可以考虑使用我们的模型可以显示出哪些有趣的副作用。
向量算术
为了说明矢量具有商品的真实含义,我们可以尝试对它们使用矢量算法。 就像在word2vec上的教科书示例中(国王-男人+女人=女王)一样,我们可以问自己例如哪个产品与打印机的距离与吸尘器中的集尘袋大致相同。 常识表明它应该是某种消耗品,即墨盒。 我们的模型能够捕获以下模式:

产品空间可视化
为了更好地理解结果,我们可以可视化平面上货物的向量空间,将维数减小为2(在此示例中,我们使用t-SNE)。

可以清楚地看到相关产品形成集群。 例如,在卧室内可以看到带有纺织品的簇,男女服装,鞋子。 再一次,我们注意到该模型仅基于用户与商品互动的历史记录建立;我们在训练时没有使用图像或文本描述的相似性。
从该空间的插图中,您还可以看到如何使用模型选择商品的附件。 为此,您需要从最近的集群中取货,例如,建议将体育用品用于T恤,为帽子推荐用于保暖的毛衣。
计划
我们现在在生产中引入prod2vec模型以计算产品推荐。 而且,获得的向量可用作我们团队从事的其他机器学习算法的功能(预测产品需求,在搜索和目录中排名,个人推荐)。
将来,我们计划实时实施在站点上收到的嵌入。 对于所有已查看的商品,下一批将在会话中,这将立即反映在个性化交付中。 我们还计划根据矢量描述将图像分析和相似性分析集成到我们的模型中,这将大大提高生成矢量的质量。
如果您知道如何最好地做到这一点(或翻拍),请前来参观(甚至做得更好)。
参考文献:
- Mikolov,Tomas等。 “单词和短语的分布式表示及其组成。” 神经信息处理系统的进步。 2013。
- Grbovic,Mihajlo等。 “收件箱中的电子商务:大规模推荐产品。” 第21届ACM SIGKDD国际知识发现和数据挖掘会议论文集。 ACM,2015年。
- Grbovic,Mihajlo和Haibin Cheng。 “使用嵌入对Airbnb进行搜索排名的实时个性化。” 第24届ACM SIGKDD国际知识发现和数据挖掘会议论文集。 ACM,2018年。