在Rostelecom,我们使用Hadoop来存储和处理使用Java应用程序从多个来源下载的数据。 现在,我们已迁移到具有Kerberos身份验证的hadoop的新版本。 移动时,我遇到了许多问题,包括使用YARN API。 Hadoop与Kerberos身份验证的合作值得一提,但在本文中,我们将讨论调试Hadoop MapReduce。

在集群中执行任务时,由于不知道哪个节点将处理输入数据的这一部分或那一部分,因此启动调试器非常复杂,而且我们无法提前配置调试器。
您可以使用经过时间考验的
System.out.println("message") 。 但是,如何分析分散在这些节点上的
System.out.println("message")的输出呢?
我们可以将消息输出到标准错误流。 用stdout或stderr编写的所有内容,
发送到适当的日志文件,该文件可在扩展任务信息网页或日志文件中找到。
我们还可以在代码中包含调试工具,更新任务状态消息,并使用自定义计数器来帮助我们了解灾难的规模。
可以在Hadoop工作的所有三种模式下调试Hadoop MapReduce应用程序:
我们将更详细地介绍前两个。
伪分布式模式
伪分布式模式用于模拟实际群集。 它可以用于尽可能接近生产环境的测试。 在这种模式下,所有Hadoop守护程序都将在一个节点上运行!
如果您有开发服务器或其他沙箱(例如,具有自定义开发环境的虚拟机,例如带有HDP的Hortonworks Sanbox),则可以使用远程调试工具调试控制程序。
要开始调试,您需要设置环境变量的值:
YARN_OPTS 。 以下是一个示例。 为方便起见,您可以创建startWordCount.sh文件并向其中添加必要的参数以启动应用程序。
现在,运行脚本
`./startWordCount.sh` ,我们将看到一条消息
Listening for transport dt_socket at address: 6000
仍然需要配置IDE进行远程调试。 我正在使用intellij IDEA。 转到菜单运行->编辑配置...添加新的
Remote配置。
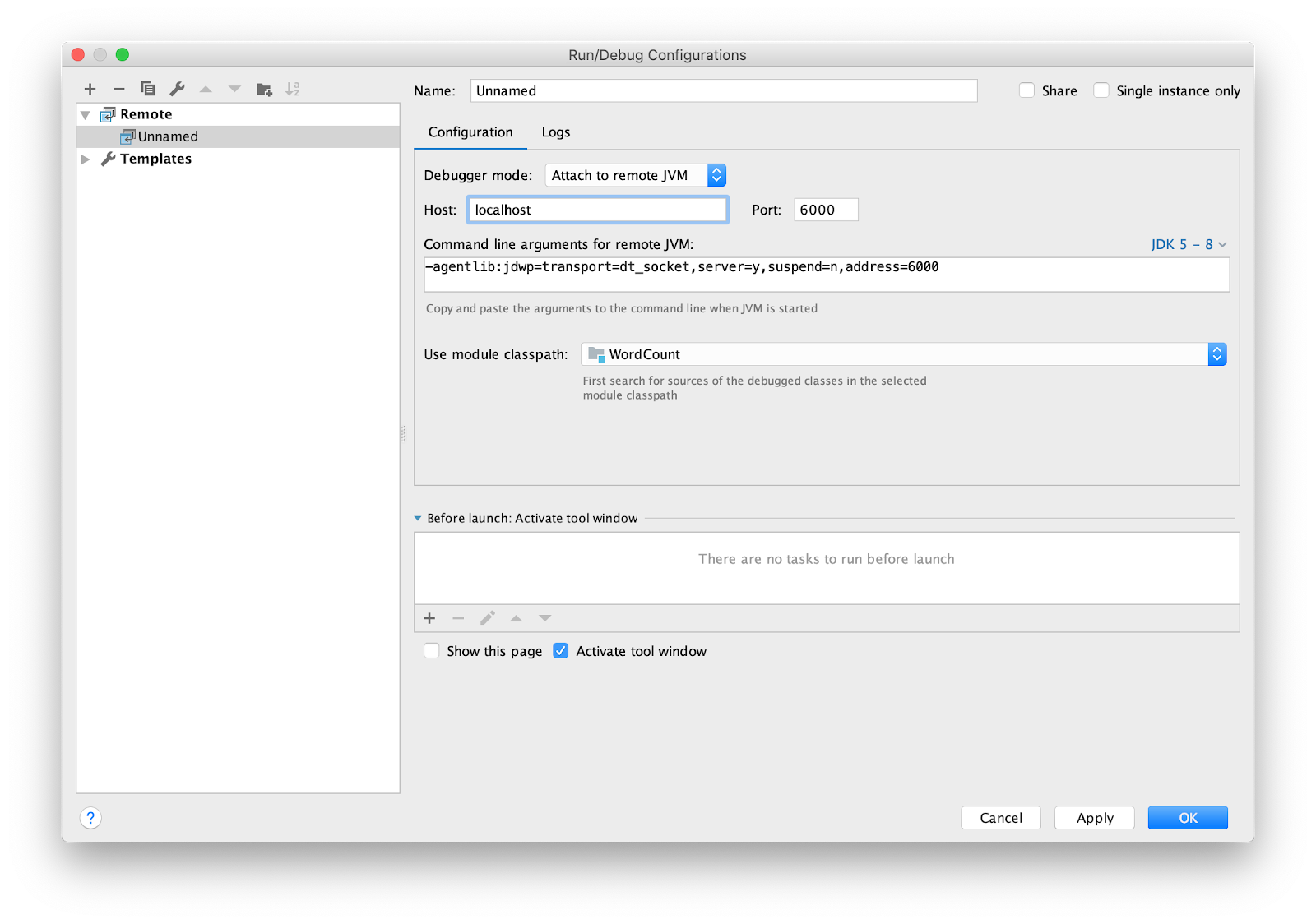
将断点设置为main并运行。
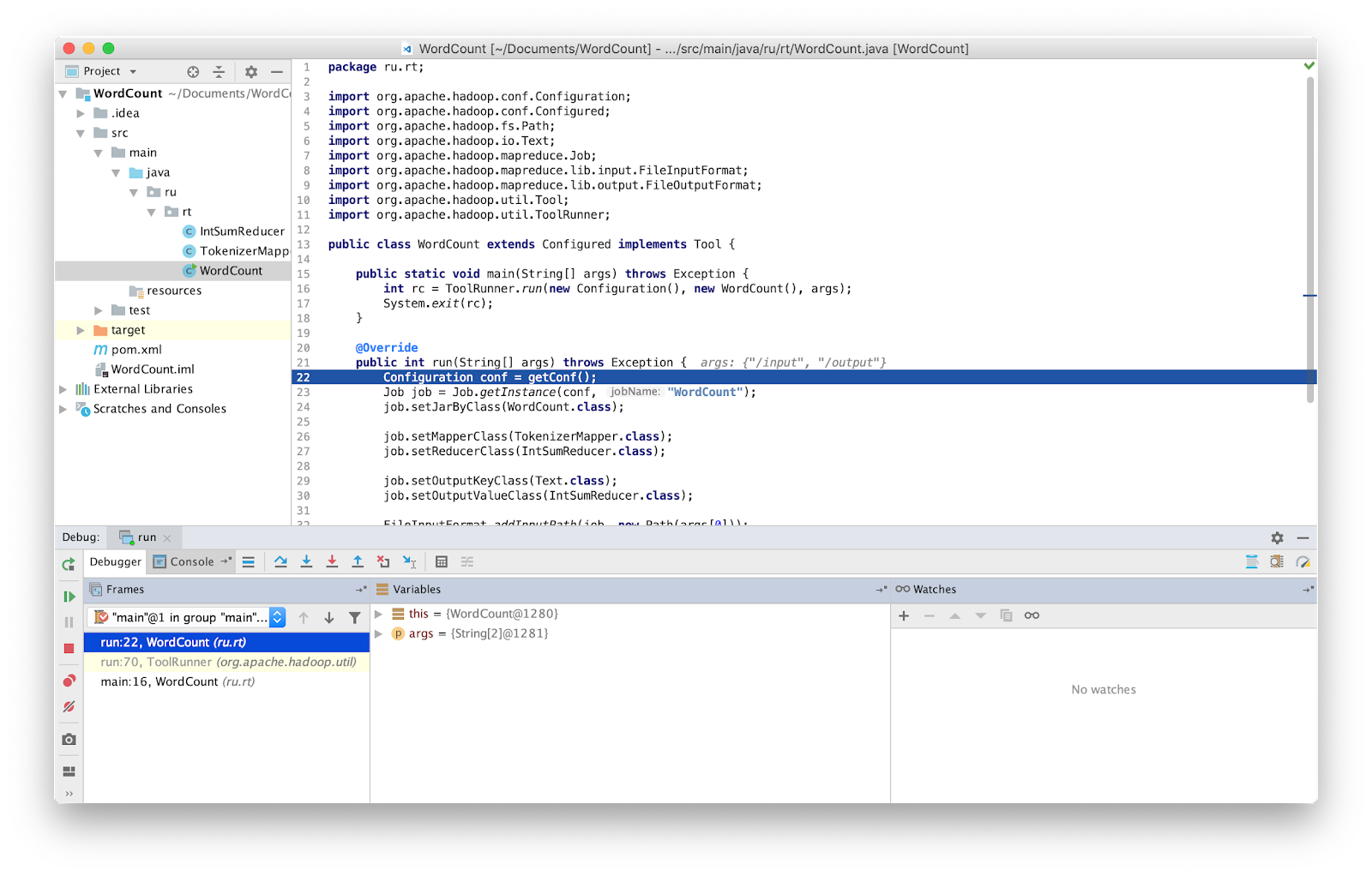
就是这样,现在我们可以照常调试程序了。
注意事项 您必须确保使用的是最新版本的源代码。 如果不是,则调试器停止的行可能有所不同。
在Hadoop的早期版本中,提供了一个特殊的类,它使您可以重新启动失败的任务-IsolationRunner。 导致故障的数据已保存到Hadoop环境变量mapred.local.dir中指定的地址的磁盘上。 不幸的是,在最新版本的Hadoop中,不再提供此类。
独立(本地启动)
独立是Hadoop工作的标准模式。 它适用于不使用HDFS的调试。 通过这种调试,您可以通过本地文件系统使用输入和输出。 独立模式通常是最快的Hadoop模式,因为它将本地文件系统用于所有输入和输出数据。
如前所述,您可以将调试工具插入代码中,例如计数器。 计数器由Java
枚举定义。 枚举名称定义组的名称,而枚举字段确定计数器的名称。 计数器对于评估问题很有用,
并且可以用作调试输出的补充。
柜台的声明和使用:
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class Map extends Mapper<LongWritable, Text, Text, IntWritable> { private Text word = new Text(); enum Word { TOTAL_WORD_COUNT, } @Override public void map(LongWritable key, Text value, Context context) { String[] stringArr = value.toString().split("\\s+"); for (String str : stringArr) { word.set(str); context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); } } } }
要递增计数器,请使用
increment(1)方法。
... context.getCounter(Word.TOTAL_WORD_COUNT).increment(1); ...
MapReduce成功完成后,任务将在最后显示计数器。
Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 ru.rt.example.Map$Word TOTAL_WORD_COUNT=655
可以使用
MultipleOutputs类将错误的数据输出到stderr或stdout,或将输出写到hdfs进行进一步分析。 接收到的数据可以以独立模式或编写单元测试时传输到应用程序的输入。
Hadoop具有MRUnit库,该库可与测试框架(例如JUnit)结合使用。 在编写单元测试时,我们验证函数是否在输出中产生了预期的结果。 我们使用MRUnit包中的MapDriver类,在其属性中设置了测试的类。 为此,请使用
withMapper()方法,输入值
withInputValue()和预期结果
withOutput()或
withMultiOutput()如果使用了多个输出)。
这是我们的测试。
package ru.rt.example; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mrunit.mapreduce.MapDriver; import org.apache.hadoop.mrunit.types.Pair; import org.junit.Before; import org.junit.Test; import java.io.IOException; public class TestWordCount { private MapDriver<Object, Text, Text, IntWritable> mapDriver; @Before public void setUp() { Map mapper = new Map(); mapDriver.setMapper(mapper) } @Test public void mapperTest() throws IOException { mapDriver.withInput(new LongWritable(0), new Text("msg1")); mapDriver.withOutput(new Pair<Text, IntWritable>(new Text("msg1"), new IntWritable(1))); mapDriver.runTest(); } }
全分布式模式
顾名思义,这是一种使用Hadoop所有功能的模式。 启动的MapReduce程序可以在1000台服务器上运行。 调试MapReduce程序总是很困难,因为您有在不同输入数据的不同机器上运行的Mappers。
结论
事实证明,测试MapReduce并不像乍看起来那样容易。
为了节省在MapReduce中查找错误的时间,我使用了上面列出的所有方法,并建议所有人也都使用它们。 这对于大型安装(例如在Rostelecom中运行的安装)尤其有用。