如果您正在发展大型数据库,而突然遇到性能极限-是时候扩展了。 通过横向扩展,您可以清楚地看到:您添加了服务器,却不知所措。 随着规模的扩大,它并不是那么有趣。 根据标准的无胶粘架构,我们采用两个处理器,然后再向其中添加两个处理器...这样我们就可以达到八个。 英特尔不再预见它;请保存在新服务器上。

但是还有另一种选择-胶合架构。 其中,双处理器计算单元通过节点控制器互连。 在他们的帮助下,每台服务器的上限阈值上升到16个或更多处理器。 在本文中,我们将更多地讨论一般的胶合架构及其在服务器中的实现方式。
为了诚实起见,在进入胶合架构之前,我们先介绍一下无胶合的优缺点。
根据无胶粘剂架构制作的解决方案是典型的。 处理器无需额外的设备即可相互通信,而是通过标准QPI \ UPI总线进行通信。 结果比胶水便宜一点。 但是每8个处理器之后就不得不花费很多钱-安装新服务器。
 典型的无胶结构
典型的无胶结构就像我们已经说过的那样,在采用胶合架构的情况下,每个服务器的上限增加到16个或更多处理器。
Bull BCS2粘合架构如何工作
Bull BCS2体系结构的优势由两个组件提供-弹性外部节点控制器和处理器缓存。 支持与Intel Xeon E7-4800 / 8800 v4系列处理器兼容的团队。
 胶合架构Bull BCS2。 服务器中的所有连接均在此处可见。 每个BCS节点都有7个XQPI链接。
胶合架构Bull BCS2。 服务器中的所有连接均在此处可见。 每个BCS节点都有7个XQPI链接。多亏了缓存,减少了处理器之间的交互量-每个模块中的处理器都可以访问公共缓存。 因此,减少了RAM上的负载。 而Noda则充当流量交换机,解决了“狭窄的脖子”的问题-它将流量重定向到使用最少的路径。
结果,Bull BCS2架构仅消耗英特尔QPI总线带宽的5-10%,这是无胶粘架构的标准。 至于对本地内存的访问延迟,它们与4插槽无胶系统相当,比8插槽无胶系统少44%。 根据规范,BCS节点的总数据传输速度为230 GB / s-7个端口中的每个端口均获得25.6 GB / s。 最大带宽为300 GB / s。

在每台Bullion S服务器中,母板上都有一个这样的开关。 一个XQPI链接(16个套接字)在速度上相当于十个10 GigE端口。
 范围金条S
范围金条S在4个和8个处理器上的配置中,胶合和非胶合架构之间的差异可以忽略不计。 但是,当切换到16个处理器时,情况会发生变化。 我们记得在无胶状态下,您已经需要两个服务器。 在具有胶合架构的Bullion S服务器中,一切都将如下所示:
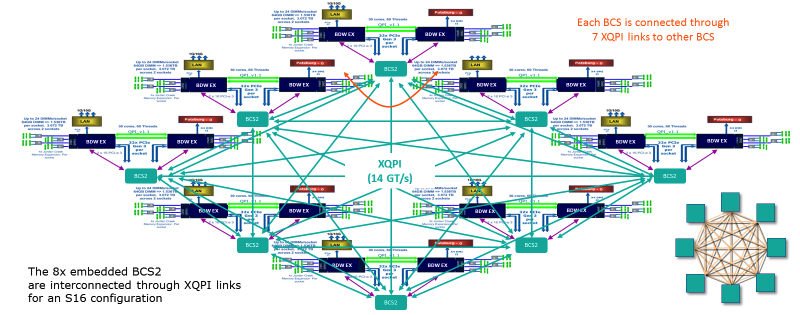 双处理器模块通过XQPI网络互连,吞吐量为14 GT / s(每秒数十亿次事务)
双处理器模块通过XQPI网络互连,吞吐量为14 GT / s(每秒数十亿次事务)这些插槽可容纳E7系列的任何处理器,但E7-8893除外,该插槽只能在双处理器配置中使用。 与访问本地内存相比,NUMA系统的延迟在模块内部达到大约x1.5,在模块之间达到大约x4。 主机控制器管理硬件分区,并允许您创建最多8个在Bullion S服务器上的操作系统上运行的独立分区。
因此,我们在一台服务器中最多可以托管384个处理器内核。 至于RAM,这里的上限是64 GB的384个DDR4模块。 总共,我们得到24 TB。
所描述的配置与我们的主力设备-Bullion S服务器相关,此外,我们还拥有BullSequana S系列,该系列可包含多达32个基于Intel Purley平台以及Skylake和Cascadelake架构的物理处理器(2019年第一季度)。
整合范例
Bullion S专为满足苛刻的任务而设计-SAP HANA,Oracle,MS SQL,Datalake(经过BullSequana S认证的Cloudera),基于VMware的虚拟化/ VDI以及基于VMware vSAN的超融合解决方案。 西门子部分在Bullion S服务器上创建了世界上最大的SAP HANA平台。 同样基于Bullion S,PWC为Hadoop和分析构建了一个庞大的解决方案。 全世界大约有300家公司使用Bull解决方案。
为了让您了解我们服务器的功能,我们将提出一个计划,在一个俄罗斯电信运营商的分支机构中将Oracle数据库从Power迁移到x86:

结论
多亏了处理器缓存,粘合架构允许处理器直接与节点中的其他处理器通信。 快速链接-与其他群集进行交互时,请不要放慢速度。 如今,一台Bullion S服务器最多可容纳16个处理器(384个内核)和24 TB RAM。 扩展步骤是两个处理器-这有助于在创建IT基础架构时分配财务负担。
在以后的材料中,我们计划更详细地解析服务器。 我们很乐意在评论中回答您的问题。