Python中词典的内部结构不仅限于存储桶和私有哈希。 这是一个了不起的世界,它包含共享密钥,哈希缓存,DKIX_DUMMY和快速比较,它们甚至可以更快地完成(以大约2 ^ -64的错误概率付出)。
如果您不知道刚创建的字典中的元素数量,每个元素花费了多少内存,为什么现在(从CPython 3.6开始)将字典分为两个数组实现以及与保持插入顺序有何关系,或者您只是没有观看Raymond Hettinger的演示,“现代Python字典汇集了许多很棒的主意。” 然后欢迎。
但是,熟悉讲座的人还可以找到一些详细信息和新鲜信息,对于不熟悉存储桶和封闭式哈希的新手来说,本文也将很有趣。
CPython中的字典无处不在,类,全局变量,kwargs参数都基于它们,即使您自己没有在脚本中添加大括号,
解释器也会
创建成千上万的字典 。 但是,为了解决许多应用问题,还使用了字典,不足为奇的是它们的实现不断改进,并且越来越多地发展成不同的技巧。
字典的基本实现(通过Hashmap)
如果您熟悉标准Hashmap和私有哈希的工作,则可以继续下一章。
字典的基本概念很简单:如果我们有一个数组,其中存储了相同大小的对象,那么我们就可以在知道索引的情况下轻松访问所需的对象。
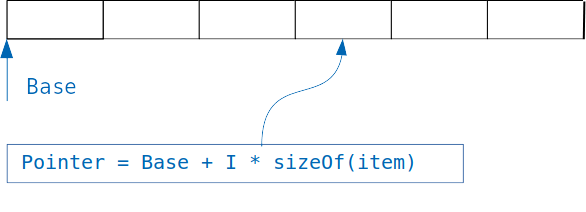
我们只需将索引乘以对象的大小乘以数组的偏移量,就可以得到所需对象的地址。
但是,如果我们不想按整数索引而是按另一种类型的变量来组织搜索,例如,要在其邮件地址处查找用户,该怎么办?
在简单数组的情况下,我们将不得不浏览数组中所有用户的邮件,并将它们与搜索进行比较,这种方法称为线性搜索,显然,它比按索引访问对象要慢得多。
如果我们限制您要搜索的区域的大小,则可以大大加快线性搜索的速度。 这通常是通过获取
哈希的其余部分来实现的。 搜索的字段是关键。
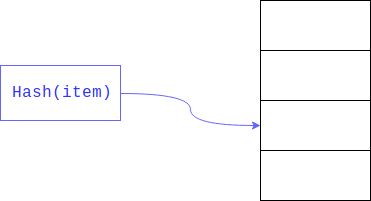
结果,不是对整个大型阵列进行线性搜索,而是沿其一部分进行线性搜索。
但是,如果那里已经有一个元素怎么办? 这很可能发生,因为没有人保证分割哈希的残差是唯一的(就像哈希本身一样)。 在这种情况下,对象将被放置在下一个索引处,如果繁忙,它将移动另一个索引,依此类推,直到找到空闲的索引为止。 检索项目时,将查看具有相同哈希值的所有键。
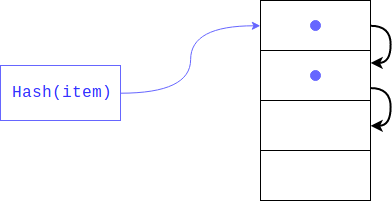
这种哈希称为私有。 如果字典中的空闲单元数很少,那么这样的搜索可能会退化为线性搜索,因此我们将失去为此字典创建的所有收益,为了避免这种情况,解释器会将数组填充为1/2-2/3。 如果没有足够的空闲单元,则会创建一个新数组,其大小是前一个数组的两倍,并将旧数组中的元素一次转移到新数组中。
如果该项目已删除该怎么办? 在这种情况下,数组中会形成一个空单元格,并且无法通过关键字区分搜索算法,该单元格为空是因为具有此类哈希的元素不在词典中,或者因为已将其删除。 为避免在删除过程中丢失数据,该单元带有特殊标志(DKIX_DUMMY)标记。 如果在元素搜索期间遇到此标志,则搜索将继续,该单元被视为繁忙,如果插入,则该单元将被覆盖。
Python的实现功能
字典的每个元素都必须包含指向目标对象和键的链接。 出于明显的原因,必须存储密钥以进行对象的碰撞处理。 由于键和对象都可以是任何类型和大小,因此我们不能将它们直接存储在结构中,它们位于动态内存中,并且指向它们的链接存储在列表项的结构中。 也就是说,一个元素的大小必须等于两个指针的最小大小(在64位系统上为16个字节)。 但是,解释器还会存储哈希,这样做是为了避免随着字典大小的每次增加而重新计算哈希。 解释器无需以新的方式计算每个键的哈希值,而是将剩余的除以存储桶数,而是读取已保存的值。 但是,如果更改了关键对象怎么办? 在这种情况下,必须重新计算哈希值,并且存储的值不正确? 这种情况是不可能的,因为可变类型不能是字典键。
字典元素的结构定义如下:
typedef struct { Py_hash_t me_hash;
字典的最小大小由PyDict_MINSIZE常量声明,该常量为8。开发人员认为这是最佳大小,以避免不必要的内存浪费,从而浪费了存储空值的时间和动态扩展数组的时间。 因此,在创建字典(版本3.6之前)时,字典中至少需要8个元素*结构中的24个字节= 192个字节(这没有考虑其余字段:字典变量本身的成本,元素数的计数器等)。
字典还用于实现自定义类字段。 Python允许您动态更改属性的数量,这种动态过程不需要额外的费用,因为添加/删除属性本质上等效于字典上的相应操作。 但是,少数程序使用此功能;大多数程序限于__init__中声明的字段。 但是,每个对象都必须存储自己的字典以及其键和哈希值,尽管它们与其他对象重合。 此处的逻辑改进是仅在一个位置存储共享密钥,这正是
PEP 412-密钥共享字典中实现的 。 动态更改字典的能力并未消失:如果更改了键的顺序或数量,则字典将从分割键转换为常规键。
为了避免冲突,字典的最大“负载”为数组当前大小的2/3。
#define USABLE_FRACTION(n) (((n) << 1)/3)
因此,当添加第6个元素时,将发生第一个扩展名。
事实证明,在编程操作期间,该阵列已完全放电,有一半至三分之一的单元保持为空,这导致内存消耗增加。 为了规避此限制,并在可能的情况下仅存储必需的数据,添加了新
级别的数组
抽象 。
例如,不要存储稀疏数组:
d = {'timmy': 'red', 'barry': 'green', 'guido': 'blue'}
从3.6版开始,字典的组织方式如下:
indices = [None, 1, None, None, None, 0, None, 2] entries = [[-9092791511155847987, 'timmy', 'red'], [-8522787127447073495, 'barry', 'green'], [-6480567542315338377, 'guido', 'blue']]
即 仅存储真正必要的那些记录,它们从哈希表中以单独的数组取出,并且只有相应记录的索引存储在哈希表中。 如果最初数组占用192个字节,那么现在只有80个(每个记录3 * 24个字节+索引8个字节)。 压缩率达到58%[2]
索引中元素的大小也会动态变化,最初等于一个字节,也就是说,整个数组可以放在一个寄存器中,当索引开始适合8位时,元素将扩展为16位,然后扩展为32位。 对于空项目和已删除项目,分别有特殊的常量DKIX_EMPTY和DKIX_DUMMY,当字典中的项目超过127个时,索引扩展为16个字节。
新对象将添加到条目中,也就是说,在扩展字典时,无需移动它们,您只需要增加索引的大小并用索引过度填充它即可。
在字典上进行迭代时,不需要索引数组,这些元素从条目开始按顺序返回,因为 每次将元素添加到条目末尾时,该词典都会自动保存元素的出现顺序。 因此,除了减少存储字典所需的内存外,我们还获得了更快的动态扩展和键顺序的保留。 减少内存本身是好的,但同时它可以提高性能,因为它允许更多记录进入处理器缓存。
CPython开发人员非常喜欢此实现,以至于现在字典需要按规范维护插入顺序。 如果较早地确定了字典的顺序,即 它是由哈希严格确定的,并且从开始到开始都没有变化,然后向其中添加了一些随机性,以便每次键都不同,现在字典键必须保持顺序。 目前尚不清楚这是多少,以及如果出现字典的更有效实现但不保留插入顺序时该怎么办。
但是,有人要求实现一种用于保留
类和
kwargs中的属性声明的机制,并且该实现允许您在没有特殊机制的情况下解决这些问题。
这是
CPython代码中的样子:
struct _dictkeysobject { Py_ssize_t dk_refcnt; Py_ssize_t dk_size; dict_lookup_func dk_lookup; Py_ssize_t dk_usable; Py_ssize_t dk_nentries; char dk_indices[]; };
但是迭代比您最初想象的要复杂,还有其他验证机制可确保字典在迭代过程中没有更改,其中一种是存储每个字典
的字典的64位
版本 。
最后,我们考虑解决冲突的机制。 问题是,在python中,哈希值很容易预测:
>>>[hash(i) for i in range(4)] [0, 1, 2, 3]
并且由于从这些哈希表创建字典时,将采用除法的其余部分,因此,实际上,它们确定记录将转到哪个存储区,因此仅键的最后几位(如果它是整数)。 您可以想象这样一种情况,我们有很多“想要”进入相邻存储桶的对象,在这种情况下,您将不得不在搜索时查看许多不适当的对象。 为了减少冲突次数并增加确定记录将进入哪个存储区的位数,实现了以下机制:
perturb是由哈希值初始化的整数变量。 应当注意,在发生大量冲突的情况下,将其重置为零,并通过以下公式计算以下索引:
j = (5 * j + 1) % n
从字典中提取元素时,将执行相同的搜索:计算元素应位于的插槽的索引,如果插槽为空,则会引发“找不到值”异常。 如果此插槽中有一个值,则需要检查其键是否与您要查找的键匹配,如果发生冲突,则可能无法实现。 但是,键几乎可以是任何对象,包括比较操作需要花费大量时间的对象。 为了避免冗长的比较操作,Python使用了一些技巧:
首先,比较指针,如果所需对象的键指针等于要搜索的对象的指针,即它们指向相同的存储区,则比较立即返回true。 但这还不是全部。 如您所知,相等的对象必须具有相等的哈希值,这意味着具有不同哈希值的对象是不相等的。 检查指针后,将检查哈希;如果它们不相等,则将返回false。 并且只有在哈希值相等的情况下,才需要进行诚实的比较。
这种结果的可能性是什么? 当然,大约2 ^ -64,由于哈希值的易预测性,您可以轻松地找到这样的示例,但实际上,这种验证并不经常出现,需要多少费用? 雷蒙德·海廷格(Raymond Hettinger)通过更改最后的比较操作(带有简单的return true)来组装解释器。 即 如果解释器的哈希值相等,则认为它们相等。 然后,他在该解释器上设置了许多受欢迎项目的自动化测试,并成功结束了。 考虑具有相等哈希值的对象相等,而不是另外检查其内容,并且仅完全依赖哈希,这似乎很奇怪,但是在使用git或torrent协议时,请定期执行此操作。 他们认为如果文件(文件块)的哈希值相等,则很可能会导致错误,但是他们的创建者(以及我们所有人)希望值得注意的是,发生碰撞的可能性非常小,这并非不合理。
现在,您应该终于了解了字典的结构,如下所示:
typedef struct { PyObject_HEAD Py_ssize_t ma_used; uint64_t ma_version_tag; PyDictKeysObject *ma_keys; PyObject **ma_values; } PyDictObject;
未来的变化
在上一章中,我们考虑了已经实施并可以在每个人的工作中使用的内容,但是改进之处当然不限于:3.8版的计划包括
对反向字典的支持 。 确实,没有什么能阻止而不是从元素数组的开头和从索引的结尾和递减的索引开始递增的迭代。
附加材料
为了更深入地了解该主题,建议您熟悉以下材料:
- 文章开头的报告记录
- 关于重新实施词典的提案
- CPython中的词典源代码