我们想分享发生在我们的一个新年项目中的故事。 该项目的实质是使医疗机构中医生的工作自动化。 在患者就诊期间,医生将信息写入记录器,然后转录音频。 转录过程之后-即 将录音转换成文本-根据相关标准形成医疗文件,然后将其发送回诊所,录音来自何处,由发送医生接收,检查并批准。 通过强制性检查后,文档将发送给最终患者。
所有使用该产品的医疗机构都可以有条件地分为两大类:
- 托管在我们客户的数据中心中,该中心完全负责应用程序的功能,包括软件和硬件。 例如,如果磁盘空间用尽,或者CPU上的服务器性能不足;
- 自托管:他们将所有设备直接放在家里,并自行负责其性能。 我们的客户为他们提供应用程序及其支持。
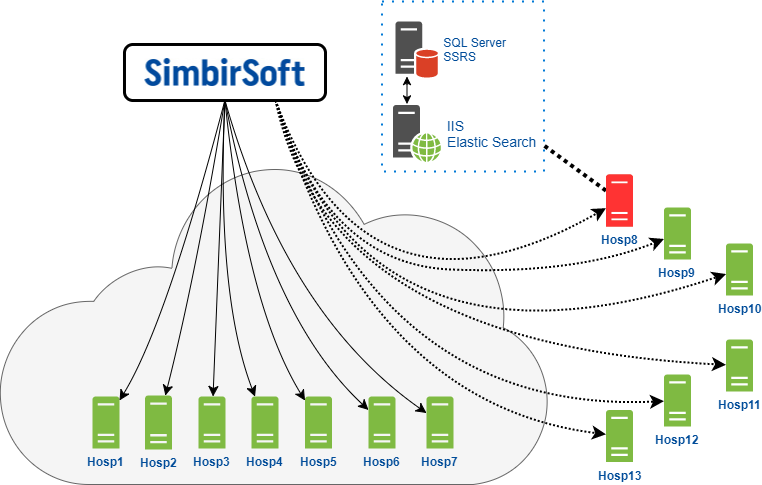
这就是我们的团队与直接托管在客户云中的最终服务器进行交互的方式。

我们可以访问这些服务器来执行所需的所有计划的工作和维护。
第二组-自托管客户端-对于他们来说,客户端云充当我们连接到这些服务器的网关。 在这种情况下,我们的权限有限,由于安全设置,我们经常无法执行任何操作。 我们通过Windows操作系统上的远程桌面协议RDP连接到服务器。 自然,所有这些都通过VPN起作用。
应该记住,图中表示的每个服务器实际上是应用程序服务器和数据库服务器的组合。 在数据库服务器上,分别安装了MS SQL Server DBMS和SSRS报告服务。 此外,MSSQL Server的版本在所有诊所中都不同:2008、2012、2014。除了版本本身之外,各处还安装了不同的Service Pack和补丁程序。 一般来说,一个完整的动物园。
在应用程序服务器上,我们已经安装了IIS和ElasticSearch Web服务器。 ElasticSearch是一个搜索引擎,还实现了全文搜索。
就我们的产品而言,主要要素是“工作”。 作品是一个抽象实体,将与特定患者的接收有关的所有信息链接在一起。 这些信息包括:
- 有关医生的数据;
- 患者资料;
- 有关访问的数据;
- 音频文件(医生的讲话);
- 文件(几个版本);
- 工作处理历史;
- 分支机构信息等
此图显示了简化的数据库架构,从中可以查看主表之间的关系。 这只是基础部分,实际上数据库有200多个表。

关于事件发生的诊所的一些信息:
- 每天1500-2000作品;
- 1000多名活跃用户(医生+秘书);
- 自托管。
DB:
- 大小:800+ Gb(750K +作品,2M +文件);
- DBMS:MS SQL Server 2008 R2;
- 恢复模型:简单。
在这里我想作一些解释。 SQL Server中有3种恢复模型:简单,批量记录和完整。 我现在不再谈论第三个,我将解释第一个和第二个。 主要区别在于,在简单模型中,我们不将事务历史记录存储在日志中-提交事务后,就会删除事务日志中的记录。 使用完全恢复模式时,数据更改的整个历史记录都存储在事务日志中。 这给了我们什么? 在某些不可预见的情况下,当我们需要从备份回滚数据库时,我们不仅可以返回到特定的备份,还可以返回到任何时间点,直到特定的事务,即我们已经存储了在备份中,不仅备份时数据库处于特定状态,而且还存在数据更改的历史记录。
我认为没有必要说明简单模式仅在开发中,在测试服务器上使用,并且不能在生产中使用的情况。 没办法
但是诊所显然对此有自己的想法;)
开始
新年过后的几天,每个人都在为假期做准备,购买礼物,装饰圣诞树,参加公司派对,都在等待一个漫长的周末。
12月22日(星期五)1天
14:31客户说他没有收到下一份每日报告。 该报告按计划每天两次发送到邮件中;需要控制该数据向外部集成系统的发送,这并不是很关键。
可能有几个原因:
- SMTP的问题是,信件根本无法传递(例如,他们更改了密码,并且没有告诉任何人);
- 报告服务器端的问题;
- 数据库发生了什么事。
16:03诊所有时会将密码更改为SMTP,而不会警告任何人,因此,在完成当前任务之后,我们通过在Web界面中启动报告来平静地手动检查报告-我们收到一条错误消息,指出数据库中存在问题。
我们在开始报告时收到的错误示例。
SQL Server detected a logical consistency-based I/O error: incorrect checksum (expected: 0x9876641f; actual: 0xa3255fbf). It occurred during a read of page (1:876) in database ID 7 at offset 0x000000006d8000 in file 'D:\Program Files\Microsoft SQL Server\MSSQL10_50.MSSQLSERVER\MSSQL\DATA\ServerLive.mdf'.
这表明数据库已损坏页面。 我们有轻微的焦虑感。
20:53为了评估损坏的程度,我们使用特殊的
DBCC CHECKDB命令运行数据库检查。 根据损坏的大小,测试命令可能会花费一些时间,因此我们在晚上运行该命令。 在这里,我们很幸运这发生在星期五的下午,也就是说,我们至少有所有的休息日来解决这个问题。
当时的情况如下:
12月23日(星期六)第二天
10:02早晨,我们发现用CHECKDB检查数据库是软盘的-这是由于缺少可用磁盘空间,因为 在验证过程中,会临时使用临时tempdb数据库,并且在某些时候,可用磁盘空间只是耗尽了。
因此,我们决定而不是检查整个数据库来立即启动表扫描。 为此,请使用
DBCC CHECKTABLE命令 。
10:46我们决定从JobHistory表开始,该表可能已损坏,因为它是用来生成报告的。 顾名思义,该表保留了所有作品的历史记录,即各个阶段之间的作品过渡。
运行
DBCC CHECKTABLE('dbo.JobHistory') 。
检查此表可发现数据库中的损坏表,这在原则上是可以预期的。
12:00目前,如果数据库使用了完整的恢复模型,我们可以从备份中还原损坏的页面,这样就可以了,但是我们的数据库处于简单模式。 因此,修复损坏的唯一选择仍然是使用特殊参数
REPAIR_ALLOW_DATA_LOSS来启动同一命令。 这可能会导致数据丢失。
我们开始。 检查再次以错误结束-我们收到一个错误,直到还原相关表后才能恢复该表。 历史表通过外键引用工作表(作业),因此,我们得出结论,主工作表(作业)中也存在损坏。
13:30下一步是同时检查Jobs表-我们希望损坏是在索引中,而不是数据中。 在这种情况下,对于我们而言,只需重建索引以进行数据恢复就足够了。
17:33一段时间后,我们发现我们的服务器无法通过RDP使用。 它可能已关闭,检查未完成,工作已暂停。 我们通知诊所服务器不可用,请举起它。
轻度焦虑症的表现形式非常特殊。
12月24日(星期日)第3天
14:31快到晚餐了,服务器升起了,我们重新运行Jobs表检查。
DBCC CHECKTABLE('dbo.Jobs')16:05验证未完成,服务器不可用。 再来一次
一段时间后,在我们设法完成检查表之前,服务器再次不可用。 此时,诊所的IT服务会执行一系列服务器检查。 我们正在等待工作的完成。
由于假期,我们与客户之间的交流很慢-我们希望问题能持续几个小时。
12月25日(星期一-圣诞节)第四天
第二天
16:00服务器抬起,客户端过圣诞节,我们再次开始检查表,但是这次我们从扫描中排除索引,只保留数据检查。 一段时间后,服务器再次不可用。
这是怎么回事?
此时此刻,人们开始浮想联翩,这不仅是巧合,而且还怀疑这可能是铁水平的损坏(硬盘掉落了)。 我们假设磁盘上有坏扇区,并且当扫描尝试从这些扇区读取数据时,系统崩溃。 我们通知客户有关我们的假设。
客户端在主机上运行磁盘检查。
17:19 Clinic IT服务报告虚拟机文件已损坏-这很糟糕!(
我们还不能工作,当他们解决问题时我们正在等待信号,我们可以继续我们的工作。
12月26日(星期二)第五天
14:05 IT诊所服务启动了另一个磁盘恢复过程。 有人告诉我们可以并行运行CHECKTABLE来检查表。 我们再次开始测试-虚拟机再次崩溃,我们通知客户端虚拟机文件仍然损坏。
这些天,由于假期,与客户的所有通信都非常缓慢,而且时间间隔很大。
12月27日(星期三)第6天
14:00我们使用Windows启动磁盘检查-虚拟机内部的
checkdisk-未检测到问题。
数据库处于“简单”模式,因此使用DBMS工具修复当前数据库的机会趋于零,因为 我们无法恢复个别损坏的页面。
我们开始考虑从备份回滚和还原数据库的选项。
我们检查了数据库备份,发现备份不是使用DBMS方式进行的,最后一次备份是在2014年,即 没有数据库的备份。 为什么他们不这样做是一个单独的问题,因此诊所有责任确保数据库的可操作性和安全性。
很有可能无法恢复当前数据库,我们开始考虑其他回滚选项。
让我们详细介绍一下诊所中的备份情况。
备份情况:
- 没有数据库备份(!!!)
- 没有虚拟机的快照(!?)
- 但是有磁盘备份(完整+公司)
数据库分别位于磁盘D上,它们每周执行一次完整备份,每天执行一次增量备份。
- 每个星期五的20:00完整备份
- 每天增量备份
- 15号和22号有完整的备份
- 每天都有备份,直到21日
即 原则上,我们可以回滚到问题发生之前的状态。
我们正在等待诊所进行更新,以从备份开始回滚数据库。
同时,诊所向标有“紧急”标志的铁(HP)供应商发出了要求。
12月28日(星期四)第7天
13:13诊所IT服务开始设置新的虚拟机,因为 无法修复旧虚拟机文件中的损坏。
19:09新的虚拟
机已安装SQL Server。
下一步是从磁盘备份还原数据库。 首先,我们决定回滚到第22天,如果问题仍然存在,则回滚到21、20等,直到我们进入工作状态。
那是院子里的第28天,我们参加了公司聚会,在这里他们告诉我们诊所在恢复备份方面存在问题,因为BACKUPS可以清空!
这是新闻!
从21号还原驱动器D的备份时,事实证明它像其他所有人一样是空的。 获得了直接碎纸机备份-它们似乎在那里,但同时却没有。 目前尚不清楚这是怎么发生的,但是据我们所知,关键是磁盘空间不足以存储磁盘备份。 他们分配了500 Gb的备份用于存储,但是在发生此事时,数据库已经达到800 Gb的重量,因此,从原则上讲,备份无法成功。 即 备份是按照计划定期进行的,但是由于空间不足,它们最终会出错,因此是空的,诊所的IT服务甚至没有想法检查它们是否一切正常。 不要那样做
12月29日(星期五)第8天
13:11讨论进一步的行动。 可能的选择:
- 尝试复制数据库文件(.ldf + .two文件)-成功的机会非常低;
- 再次尝试备份数据库的机会很小。
- 配置复制-可能有效。
在新服务器上分配了1 Tb驱动器,如果我们尝试从中进行备份和还原,显然这是不够的,因为 在最坏的情况下,如果不进行压缩,备份将占用原始数据库所需的空间,即 800 Gb。
请在新服务器上添加位置,然后继续复制数据库文件。
在新服务器上创建了一个数据库,并还原了数据库架构-这将至少允许处理新工作。 诊所将至少能够使用这种系统接受新患者。
14:36因此,尽管我们期望不会有太大的成功,但我们还是选择了第一方案。
停止SQL Server,开始复制数据文件(mdf)和日志(ldf)。
16:13一半日志文件后,已成功复制(48 Gb),并且已经复制了50 GB数据文件(剩余846 GB的795)。 以这种速度,大约需要12个小时才能完成复印。
16:30在复制文件时,旧的数据库服务器已关闭,这是很正常的。
17:09因此,我们进入下一个选项-设置复制,同时我们可以指定要复制的数据,即,我们可以首先排除故意损坏的表,然后首先复制未损坏的数据,然后再将有问题的表进行部分转移。 但是不幸的是,该选项也不起作用,因为由于数据库损坏,我们甚至无法使用某些表创建发布。
我们也在考虑数据传输选项。
20:01结果,我们开始通过按优先级顺序导入和导出,简单地将数据从旧服务器传输到新服务器。
21:35首先,是最关键的数据,然后是归档数据,而不太关键的数据(约300 GB)。 在第一次出口浪潮中,仅剩下不到300 GB的数据。 文件表(300GB)也被排除在外。 我们在晚上开始复制过程。
12月30日(星期六)第9天
15:00我们继续传输数据。 Jobs表根本不可用。 到此时,大多数表已被复制。
但是如果没有
乔布斯,那一切都将毫无用处,因为它是所有数据之间的主要链接,并从业务角度赋予它们意义和价值。 没有它,我们将只有一个无法使用的完全不同的数据集。
另外,此时,数据库架构恢复已完成。
事件的后果:在这一点上,我们已经丢失了大量实时数据。
即 正式地,我们在数据库中有一些数据,但是,实际上,没有使用或连接它们的方法,因此我们可以谈论数据的完全丢失。
超过750,000名患者入院的数据丢失。
真是可悲!
- 这对我们客户的声誉是一个巨大的打击,这对于他们在签订新合同和寻找新客户时的业务而言可能是个大问题。
- 诊所丢失大量数据可能会导致严重的问题和罚款,因为 这是包含医疗机密性的机密数据,从字面上看,这取决于人们的生活。
我们开始考虑在这种情况下可以做什么。 他们开始通过骨头对系统进行分类以寻找线索。
15:16通过分析系统的各个方面,我们了解可以尝试从ElasticSearch索引中提取丢失的数据。 事实是,由于ElasticSearch索引的配置不正确,它不仅存储执行全文搜索的字段,而且还存储了所有内容,也就是说,实际上所有数据都有完整的副本,并且我们可以从理论上从中提取数据关于作品,并将它们放回我们的数据库。 希望数据仍然能够恢复。
您可以在上面放置纪念碑的错误!
 18:00
18:00快速编写了一个实用程序来提取数据,几个小时后,我们确保该方法有效并且可以恢复数据。
20:00已开始借助书面实用程序从ElasticSearch恢复工作。 该方法行之有效,我们可以恢复工作上的数据。 同时,我们开始为每项工作提取文档的最新版本。
12月31日(星期日-新年)第10天
14:09晚上,修复了188811件作品。
20:13看到我们的成功,诊所决定推迟将服务器转移到HP服务,以便给我们时间从旧服务器中提取最大数据。
有了这样的消息,我们庆祝了新年))
1月1日(星期一)11日
11:23事件发生后准备启动系统:
- 在应用服务器上重新配置IIS;
- 重新配置了与新数据库服务器一起使用的所有必要服务;
- 触发器,存储过程,功能已恢复。
14:28然后他们开始复制文档表,由于初始传输过程中尺寸太大,该表被跳过了。
-旧的数据库服务器再次关闭。 显然,Documents表也已损坏,所有患者信息都随它存储。 幸运的是,它还没有完全损坏,我们可以向它提出请求,并且当我们收到一个请求返回损坏的记录时,此时服务器将崩溃并关闭。 我们可以提取一些数据。
因此,我们向客户发出信号,他们提高服务器,与此同时,我们继续为启动系统准备新的数据库。
18:01在传输数据的主要部分之后恢复所有完整性约束。
22:02恢复限制。 我们只是将原始数据传输到最大。 完整性约束的存在将使我们的任务大大复杂化。
1月2日(星期二)第12天
05:52在复制文档时
,旧的DB服务器再次关闭。 他很快被抚养长大,以便我们可以继续工作。
09:00可以批量恢复大约200,000个文档(大约20%)
我们开始使用不同的恢复方法:按不同的列排序以从表的末尾或开始处获取数据,直到偶然发现表的某些损坏部分为止。
13:42开始在表中复制档案作品-幸运的是,它没有损坏。
17:08恢复了所有存档工作(491 380件)。
该系统已准备好启动:用户可以创建和处理新工作。
不幸的是,由于文档表的部分损坏,您不能像其他表一样仅从其中传输所有数据,因为 桌子部分损坏。 因此,当尝试检索所有数据时,尝试读取损坏的页面时请求会崩溃。 因此,我们使用不同的排序和样本大小逐点提取数据:
- 按不同字段排序(ID,DateTime);
- 升序,降序;
- 处理少量的线路(1000、100);
- 按ID提取作业。
1月3日(星期三)第13天
08:58继续了恢复文件的过程。 仅出于活动,不完整的工作而还原了文档。 此时,有1000幅作品(处于活动状态)没有文档。
11:38迁移了所有SQL作业
13:17 5没有文档,没有231,但是有一个音频文件,您需要重新同步。
1月4日(星期四)第14天
手动恢复和验证剩余工作已经开始。
该系统可以工作,在线监视和修复错误。
1月5日(星期五)第15天
报告迁移到SSRS的计划。
无法转移到新服务器,因为 诊所安装了旧版本的SQL Server,因此无法从旧服务器传输数据库。
选项:
- 将SQL Server从2008升级到2008 R2;
- 从头开始配置所有内容。
已决定等待SQL Server更新。
09:21已经开始完成已完成工作的文档的后台恢复-这个过程很长,需要几天的时间。
13:28部门更改文件恢复的优先级。
18:18诊所允许访问SMTP,邮件设置
结果:
- 几乎所有数据都已还原(仅丢失了5个作业);
- 发布了有关数据库维护的建议以防止这种情况;
- 数据库备份是使用SQL Server配置的。
- 我们还对备份进行了额外的监视,如果发生故障则发出警报。