
每天在Badoo发生170亿个事件,6000万个用户会话和大量虚拟日期。 每个事件都被整齐地存储在关系数据库中,以便随后在SQL中进行分析。
具有数十兆字节数据的现代分布式事务数据库-工程学的真正奇迹。 但是,作为关系代数在大多数标准实现中的体现,SQL尚未允许我们根据有序元组来制定查询。
在有关虚拟 机的系列的最后一篇文章中,我将讨论寻找有趣会话的另一种方法-正则表达式引擎( Pig Match ),它是为事件序列定义的。
虚拟机,字节码和编译器是免费提供的!
第一部分,简介
第二部分,优化
第三部分,适用(当前)
关于活动和会议
假设我们已经有一个数据仓库,它使您可以快速顺序地查看每个用户会话的事件。
我们希望通过请求来查找会话,例如“对有事件的指定子事件的所有会话进行计数”,“查找给定模式描述的会话部分”,“返回在给定模式之后发生的会话部分”或“计数达到特定部分的会话数”模板”。 这对于多种类型的分析很有用:搜索可疑会话,漏斗分析等。
必须以某种方式描述所需的子序列。 在最简单的形式中,此任务类似于在文本中查找子字符串。 我们希望有一个更强大的工具-正则表达式。 正则表达式引擎的现代实现最经常使用(您猜对了!)虚拟机。
下面将讨论用于匹配具有正则表达式的会话的小型虚拟机的创建。 但首先,我们将澄清定义。
事件由事件类型,时间,上下文和特定于每种类型的一组属性组成。
每个事件的类型和上下文都是预定义列表中的整数。 如果所有事件类型都清楚,则上下文是例如发生给定事件的屏幕编号。
事件属性是一个任意整数,其含义取决于事件的类型。 一个事件可能没有属性,或者可能有多个。
会话是按时间排序的一系列事件。
但是,让我们最后开始做生意。 正如他们所说,嗡嗡声消退了,我走上了舞台。
在一张纸上比较
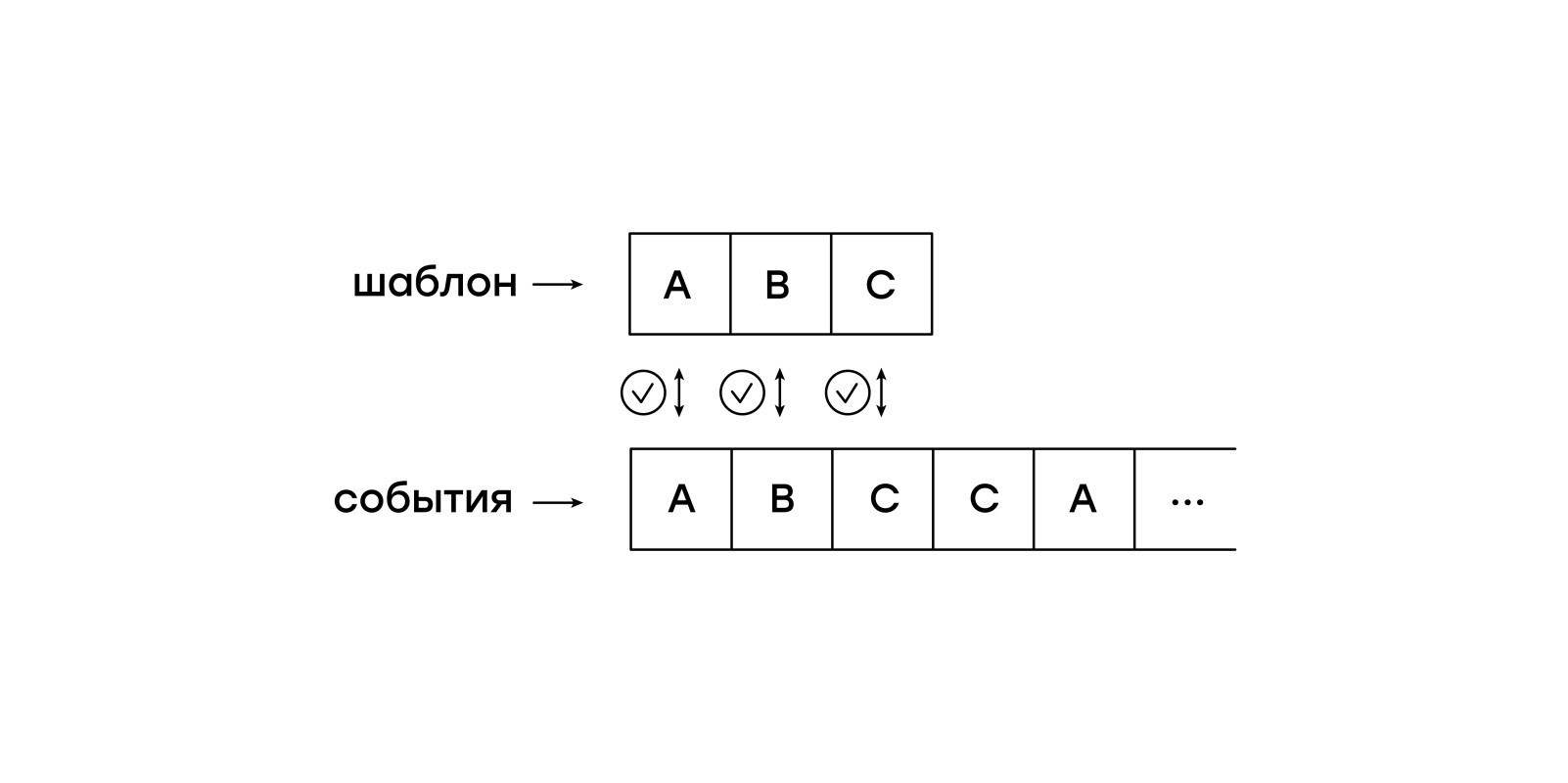
该虚拟机的一个特征是相对于输入事件的被动性。 我们不想将整个会话保留在内存中,而是希望虚拟机独立地从事件切换到事件。 取而代之的是,我们将会话中的事件一一提交到虚拟机中。
让我们定义接口函数:
matcher *matcher_create(uint8_t *bytecode); match_result matcher_accept(matcher *m, uint32_t event); void matcher_destroy(matcher *matcher);
如果使用matcher_create和matcher_destroy函数清除了所有内容,那么matcher_accept值得一提。 matcher_accept函数接收虚拟机的实例和下一个事件(32位,其中事件类型为16位,上下文为16位),并返回解释用户代码下一步应执行的代码:
typedef enum match_result {
虚拟机操作码:
typedef enum matcher_opcode {
虚拟机的主循环:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP() \ (*m->ip++) #define NEXT_ARG() \ ((void)(m->ip += 2), (m->ip[-2] << 8) + m->ip[-1]) for (;;) { uint8_t instruction = NEXT_OP(); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(); if (event_name(next_event) != name) return MATCH_FAIL; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(); if (event_screen(next_event) != screen) return MATCH_FAIL; break; } case OP_NEXT:{ return MATCH_NEXT; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } #undef NEXT_OP #undef NEXT_ARG }
在此简单版本中,我们的虚拟机将字节码描述的模式与传入事件顺序匹配。 因此,这根本不是两个行的前缀(所需的模板和输入行)的非常简洁的比较。
前缀是前缀,但是我们不仅要在开始时而且要在会话中的任意位置找到所需的模式。 天真的解决方案是从每个会话事件重新开始匹配。 但这意味着对每个事件和饮食有算法的婴儿进行多次查看。
实际上, 该系列第一篇文章中的 示例模拟了使用回滚(英语回溯)重新开始比赛的过程。 该示例中的代码当然比此处给出的代码更苗条,但是问题并没有消失:每个事件都必须被检查很多次。
你不能那样生活。
我,我又是我

让我们再次概述问题:我们需要将模板与传入事件进行匹配,从每个事件开始进行新的比较。 那我们为什么不这样做呢? 让虚拟机在多个线程中处理传入事件!
为此,我们需要获取一个新实体-流。 每个线程存储一个指针-指向当前指令:
typedef struct matcher_thread { uint8_t *ip; } matcher_thread;
自然,现在在虚拟机本身中,我们将不再存储显式指针。 它将由两个线程列表代替(下面更多有关它们的信息):
typedef struct matcher { uint8_t *bytecode; matcher_thread current_threads[MAX_THREAD_NUM]; uint8_t current_thread_num; matcher_thread next_threads[MAX_THREAD_NUM]; uint8_t next_thread_num; } matcher;
这是更新的主循环:
match_result matcher_accept(matcher *m, uint32_t next_event) { #define NEXT_OP(thread) \ (*(thread).ip++) #define NEXT_ARG(thread) \ ((void)((thread).ip += 2), ((thread).ip[-2] << 8) + (thread).ip[-1]) /* - */ add_current_thread(m, initial_thread(m)); // for (size_t thread_i = 0; thread_i < m->current_thread_num; thread_i++ ) { matcher_thread current_thread = m->current_threads[thread_i]; bool thread_done = false; while (!thread_done) { uint8_t instruction = NEXT_OP(current_thread); switch (instruction) { case OP_ABORT:{ return MATCH_ERROR; } case OP_NAME:{ uint16_t name = NEXT_ARG(current_thread); // , , // next_threads, if (event_name(next_event) != name) thread_done = true; break; } case OP_SCREEN:{ uint16_t screen = NEXT_ARG(current_thread); if (event_screen(next_event) != screen) thread_done = true; break; } case OP_NEXT:{ // , .. // next_threads add_next_thread(m, current_thread); thread_done = true; break; } case OP_MATCH:{ return MATCH_OK; } default:{ return MATCH_ERROR; } } } } /* , */ swap_current_and_next(m); return MATCH_NEXT; #undef NEXT_OP #undef NEXT_ARG }
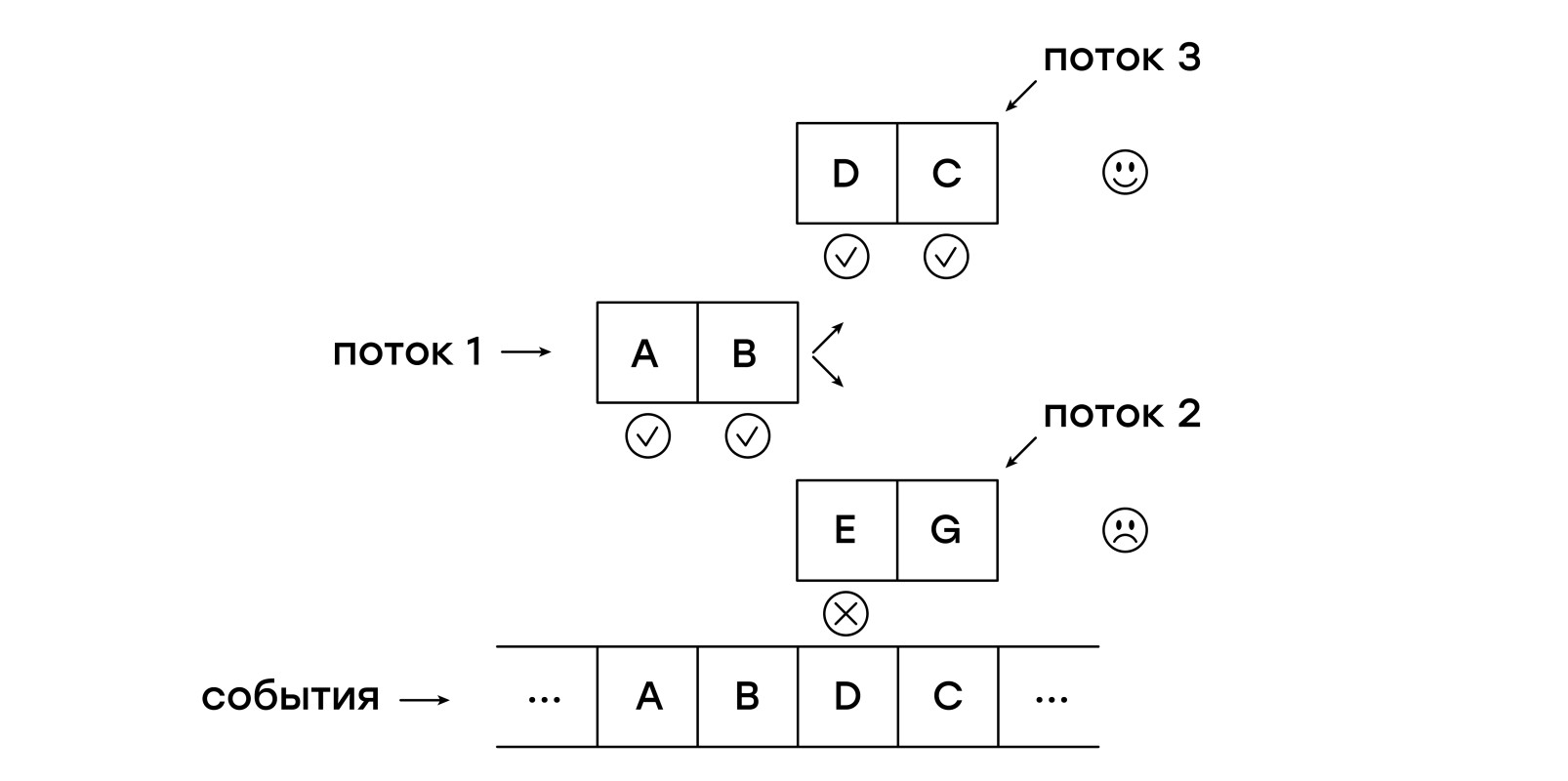
在收到的每个事件中,我们首先将一个新线程添加到current_threads列表中,从头开始检查模板,此后,我们按照说明在每个指针之后开始遍历current_threads列表。
如果遇到NEXT指令,则将该线程放置在next_threads列表中,也就是说,它等待接收下一个事件。
如果线程模式与接收到的事件不匹配,那么就不会将此类线程添加到next_threads列表中。
MATCH指令立即退出该函数,并报告该模式与会话匹配的返回码。
流列表的爬网完成后,将交换当前列表和下一个列表。
实际上,仅此而已。 可以说我们实际上是在做我们想要做的事情:同时我们在检查几个模板,为每个会话事件启动一个新的匹配过程。
模板中的多个身份和分支
搜索描述线性事件序列的模板当然是有用的,但是我们需要完整的正则表达式。 我们在上一阶段创建的流程在这里也很有用。
假设我们想找到一个我们感兴趣的两个或三个事件的序列,就像是行上的正则表达式:“ a?Bc”。 在此序列中,符号“ a”是可选的。 如何用字节码表示? 容易!
我们可以启动两个线程,每种情况一个线程:带符号“ a”,不带符号。 为此,我们引入了一条附加指令(SPLIT类型为addr1,addr2),该指令从指定的地址开始两个线程。 除了SPLIT之外,JUMP对我们也很有用,它仅使用direct参数中指定的指令继续执行:
typedef enum matcher_opcode { OP_ABORT, OP_NAME, OP_SCREEN, OP_NEXT,
循环本身和其余指令不会改变-我们仅介绍两个新的处理程序:
请注意,这些指令将线程添加到当前列表中,也就是说,它们在当前事件的上下文中继续工作。 发生分支的线程不会进入以下线程的列表。
这个正则表达式虚拟机中最令人惊讶的事情是,我们的线程和这对指令足以表达匹配字符串时通常接受的几乎所有构造。
事件的正则表达式
现在,我们已经有了合适的虚拟机和工具,我们实际上可以处理正则表达式的语法。
手动记录操作码,以便执行更严格的程序,很快就累了。 上次我没有做完整的解析器,但是真正的 用户 以PigletC迷你语言为例展示了raddsl库的功能。 代码的简洁性给我留下了深刻的印象,以至于在raddsl的帮助下,我用Python用一两百个小小的字符串正则表达式编译器进行了编写。 编译器及其使用说明在GitHub上。 读取两个文件(用于虚拟机的程序和用于验证的会话事件列表)的实用程序可以理解汇编语言以编译器的结果。
首先,我们将自己局限于事件的类型和上下文。 事件的类型用单个数字表示; 如果需要指定上下文,请通过冒号指定。 最简单的例子:
> python regexp/regexp.py "13" # , 13 NEXT NAME 13 MATCH
现在是一个带有上下文的示例:
python regexp/regexp.py "13:12" # 13, 12 NEXT NAME 13 SCREEN 12 MATCH
连续事件必须以某种方式分开(例如,用空格隔开):
> python regexp/regexp.py "13 11 10:9" 08:40:52 NEXT NAME 13 NEXT NAME 11 NEXT NAME 10 SCREEN 9 MATCH
模板更有趣:
> python regexp/regexp.py "12|13" SPLIT L0 L1 L0: NEXT NAME 12 JUMP L2 L1: NEXT NAME 13 L2: MATCH
注意以冒号结尾的行。 这些是标签。 SPLIT指令创建两个从标签L0和L1继续执行的线程,并且在执行的第一个分支的末尾的JUMP仅行进到该分支的末尾。
您可以通过将括号中的子序列分组来更准确地在表达式链之间选择:
> python regexp/regexp.py "(1 2 3)|4" SPLIT L0 L1 L0: NEXT NAME 1 NEXT NAME 2 NEXT NAME 3 JUMP L2 L1: NEXT NAME 4 L2: MATCH
任意事件用点表示:
> python regexp/regexp.py ". 1" NEXT NEXT NAME 1 MATCH
如果我们想表明子序列是可选的,则在其后添加问号:
> python regexp/regexp.py "1 2 3? 4" NEXT NAME 1 NEXT NAME 2 SPLIT L0 L1 L0: NEXT NAME 3 L1: NEXT NAME 4 MATCH
当然,在正则表达式中,多个正则重复(加号或星号)也很常见:
> python regexp/regexp.py "1+ 2" L0: NEXT NAME 1 SPLIT L0 L1 L1: NEXT NAME 2 MATCH
在这里,我们只需多次执行SPLIT指令,就可以在每个周期中启动新线程。
同样带有星号:
> python regexp/regexp.py "1* 2" L0: SPLIT L1 L2 L1: NEXT NAME 1 JUMP L0 L2: NEXT NAME 2 MATCH

透视图
所描述的虚拟机的其他扩展可能会派上用场。
例如,可以通过检查事件属性轻松地对其进行扩展。 对于实际系统,我假设使用类似“ 1:2 {3:4,5:> 3}”的语法,这意味着:上下文2中的事件1具有属性3的值4和属性值5大于3。您只需将其以数组形式传递给matcher_accept函数。
如果您还将事件之间的时间间隔传递给matcher_accept,则可以向模板语言添加语法,该语法允许您跳过事件之间的时间:“ 1 mindelta(120)2”,这表示:事件1,然后是至少120秒,事件2与保留子序列结合使用,这使您可以收集有关两个事件子序列之间的用户行为的信息。
相对容易添加的其他有用的东西是:保留正则表达式的子序列,将贪婪和普通星号以及加号运算符分隔开,等等。 就自动机理论而言,我们的虚拟机是不确定的有限自动机,对其实施不难做到。
结论
我们的系统是为快速用户界面开发的,因此会话存储引擎是自编写的,并针对通过所有会话进行了专门优化。 在单个服务器上,仅需几秒钟的时间,就可以检查会话中分解的数十亿个事件。
如果速度对您来说不是那么关键,那么可以将类似的系统设计为某些标准数据存储系统的扩展,例如传统的关系数据库或分布式文件系统。
顺便说一下,在最新版本的SQL标准中,已经出现了与本文所述类似的功能,并且单个数据库( Oracle和Vertica )已经实现了该功能。 Yandex ClickHouse继而实现了自己的类似于SQL的语言,但它也具有类似的功能 。
从事件和正则表达式分散注意力,我想重复一遍,虚拟机的适用性比乍看起来似乎要广泛得多。 当需要清楚地区分系统引擎可以理解的原语和“前端”子系统(例如某些DSL或编程语言)时,此技术适用于所有情况,并且广泛使用。
总结了一系列有关字节码解释器和虚拟机的各种用法的文章。 我希望Habr的读者喜欢该系列,当然,我将很乐意回答有关该主题的任何问题。
用于编程语言的字节码解释器是一个特定的主题,关于它们的文献很少。 就个人而言,我喜欢Ian Craig 的书《虚拟机》,尽管它并没有将解释程序的实现描述为抽象机,而是将各种编程语言作为基础的数学模型。
从广义上讲,另一本书专门针对虚拟机- “虚拟机:用于系统和过程的灵活平台” (“虚拟机:用于系统和过程的多功能平台”)。 这是对虚拟化的各种应用程序的介绍,涵盖了语言,流程和计算机体系结构的虚拟化。
在流行的编译器文献中很少讨论开发正则表达式引擎的实际方面。 Pig Match和第一篇文章中的示例均基于Russ Cox(Google RE2引擎的开发者之一) 一系列惊人的文章中的思想。
正则表达式的理论在所有有关编译器的学术教科书中都有介绍。 通常会参考著名的“龙书” ,但我建议您从上面的链接开始。
在撰写本文时,我首先使用了一个有趣的系统来快速开发Python raddsl的编译器,该系统属于用户true-grue的写照 (谢谢Peter!)。 如果您面临着对一种语言进行原型设计或快速开发某种DSL的任务,则应注意它。