您是否注意到任何流行的利基市场如何在恐惧中吸引信息安全交易的营销人员? 他们说服您,如果发生网络攻击,该公司将无法应对任何响应事件的任务。 当然,在这里会出现一个友好的向导-服务提供商,愿意为客户节省一定数量的费用,以免他们麻烦和决策的需要。 我们解释了为什么这种方法不仅对钱包有危险,而且对公司的安全水平也有危险,服务提供商的参与可以带来什么实际利益,以及应该始终留在客户责任范围内的决定是什么?

首先,我们将处理术语。 在事件管理方面,通常会听到SOC和CSIRT这两个缩写,为了避免行销操纵,必须理解它们的重要性。
SOC(安全运营中心)-专门负责信息安全运营任务的部门。 通常,在谈论SOC的功能时,人们意味着监视和识别事件。 但是,通常SOC的职责包括与信息安全流程有关的所有任务,包括响应和消除事件的后果,改进IT基础架构并提高公司安全级别的方法学活动。 同时,SOC通常是一个独立的员工部门,包括各种职位的专家。
CSIRT(网络安全事件响应团队)-负责响应新出现的事件的组/临时组或部门。 CSIRT通常具有永久性的骨干网,由信息安全专业人员,SZI的管理员和一组取证人员组成。 但是,在每种情况下,团队的最终组成都是由威胁向量确定的,并且可以由IT服务,业务系统所有者乃至公司的管理人员通过PR服务进行补充(以消除媒体的负面背景)。
尽管CSIRT在其活动中通常受NIST标准(包括完整的事件管理周期)指导,但目前在营销领域的重点更多地放在响应活动上,拒绝SOC使用此功能并将这两个术语进行对比。
相对于CSIRT,SOC的概念是否更广泛? 我认为是的。 在其活动中,SOC不仅限于事件,它可以依靠网络情报数据,对组织安全级别的预测和分析,并包括更广泛的安全任务。
但是回到NIST标准,它是描述事件管理的过程和阶段的最受欢迎的方法之一。 NIST SP 800-61标准的一般步骤如下:
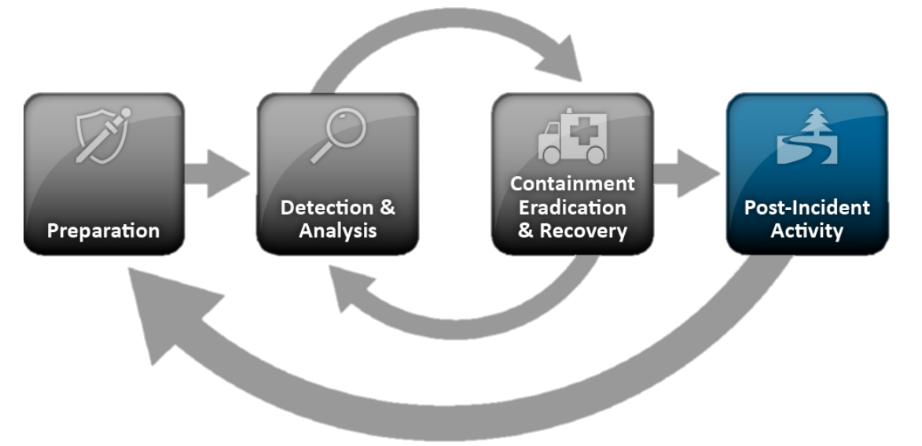
- 准备:
- 识别和分析事件:
- 本地化,中和和恢复:
- 有条不紊的活动:
尽管NIST标准专用于事件响应,但响应的很大一部分仍由“事件的检测和分析”部分占据,该部分实际上描述了监视和处理事件的经典任务。 他们为什么受到如此关注? 为了回答这个问题,让我们仔细看一下每个块。
准备工作
识别事件的任务始于根据识别事件的规则创建和“着陆”威胁模型和入侵者模型。 您可以通过分析来自各种信息保护工具,IT基础架构的组件,应用程序系统,技术系统(ACS)的元素和其他信息资源的信息安全事件(日志)来检测事件。 当然,您可以使用脚本,报告来手动执行此操作,但是为了有效地实时检测信息安全事件,仍需要专门的解决方案。
SIEM系统可以在这里进行救援,但是它们的操作绝不亚于分析“原始”日志,并且在每个阶段(从连接源到创建事件规则)都应运而生。 困难与以下事实有关:来自不同来源的事件必须具有统一的外观,并且事件的关键参数必须映射到SIEM中的相同事件字段中,而与系统或硬件的类/制造商无关。
检测事件的规则,危害指标列表,网络威胁趋势构成了SIEM的所谓“内容”。 它应该执行以下任务:收集网络和用户活动配置文件,收集有关各种类型事件的统计信息以及识别典型的信息安全事件。 触发检测事件规则的逻辑应考虑到特定公司的特定基础结构和业务流程。
由于没有公司的标准基础架构和业务流程在其中进行,因此SIEM系统可能没有统一的内容。 因此,应在安全设备的设置和调整以及SIEM中及时反映公司IT基础架构中的所有更改。 如果仅在提供服务之初对系统进行一次配置,或者每年进行一次更新,则这将减少检测军事事件并成功过滤误报几次的机会。
因此,设置安全功能,将源连接到SIEM系统以及调整SIEM内容是响应事件的首要任务,没有这些基础,就不可能继续前进。 毕竟,如果未及时记录该事件并且没有经历识别和分析阶段,那么我们就不再谈论任何响应,我们只能处理其后果。
检测和分析事件
监视服务应全天候和每周7天以实时模式处理事件。 就像安全基础一样,这条规则也是鲜血写成的:大约一半的严重网络攻击在晚上开始,而通常在星期五开始(例如,WannaCry勒索软件病毒就是这种情况)。 如果您在第一个小时内没有采取保护措施,那么可能已经太迟了。 在这种情况下,只需将所有记录的事件转移到NIST标准中描述的下一步,即 到本地化阶段,这是不切实际的,原因如下:
- 在分析阶段,要获得有关正在发生的事件的其他信息或滤除误报,比对事件进行定位要容易和正确得多。 这样,您可以最大程度地减少事件响应过程的下一阶段中涉及的事件数量,在这些事件中,应该由更高级别的专家来考虑-事件管理经理,响应团队,IT系统和SIS管理员。 以不将每个小问题(包括误报)升级到CISO级别的方式来构建流程,这更合乎逻辑。
- 事件的响应和“抑制”始终会带来业务风险。 对事件做出响应可能包括阻止可疑访问,隔离主机并升级为领导层的工作。 在误报的情况下,每个步骤都将直接影响基础架构元素的可用性,并迫使事件管理团队长时间使用多页报告和备忘录来“消除”自己的升级。
通常,第一线工程师在监视服务24/7中工作,他们直接参与SIEM系统记录的潜在事件的处理。 此类事件的数量每天可能达到数千起(再次-本地化阶段是否还要这样?),但是幸运的是,大多数事件都符合众所周知的模式。 因此,为了提高处理速度,可以使用脚本和说明逐步描述必要的操作。
这是一种行之有效的做法,可以减少分析师的第2行和第3行的工作量-仅将那些不适合任何现有脚本的事件转移给他们。 否则,在第二和第三条监视线上的事件升级将达到80%,或者在第一条监视上,将需要安排具有高专业知识和较长培训时间的昂贵专家。
因此,除了一线员工之外,还需要分析师和架构师来创建脚本和指令,培训一线专家,在SIEM中创建内容,连接源,维护可操作性并将SIEM与类系统IRP,CMDB等集成。
一项重要的监视任务是在SIEM系统中搜索,处理和实施各种信誉数据库,APT报告,新闻通讯和订阅,这些最终最终变成危害指标(IoC)。 正是它们使识别攻击者对基础结构的秘密攻击,反病毒供应商未检测到的恶意软件等成为可能。 但是,就像将事件源连接到SIEM系统一样,添加有关威胁的所有这些信息首先需要解决许多任务:
- 自动添加指标
- 评估其适用性和相关性
- 信息陈旧和优先级排序
- 最重要的是-了解保护手段,您可以获取信息以验证这些指标。 如果对于网络设备而言,一切都很简单-检查防火墙和代理,然后对主机进行检查,则比较困难-比较哈希值,如何在所有主机上检查正在运行的进程,注册表分支和写入硬盘的文件?
上面,我仅谈到了监视和分析事件过程的一部分,而任何构建事件响应过程的公司都必须面对这些事件。 我认为,这是整个过程中最重要的任务,但是让我们继续进行到已经记录和分析了信息安全事件的工作单元。
本地化,中和和恢复
根据某些信息安全专家的说法,此障碍是监视团队与事件响应团队之间差异的确定因素。 让我们仔细看看NIST的内容。
事件本地化
根据NIST,事件本地化过程中的主要任务是制定策略,即确定措施以防止事件在公司基础架构中传播。 这些措施的复杂性可能包括各种措施-在网络级别隔离事件中涉及的主机,切换信息保护工具的操作模式,甚至停止公司的业务流程以最大程度地减少事件造成的损害。 实际上,该策略是一本剧本,由取决于事件类型的一系列行动组成。
这些措施的实施可能涉及IT技术支持,系统(包括业务系统),第三方承包商公司和信息安全服务的所有者和管理员的转移责任领域。 动作可以由EDR组件手动执行,甚至可以由命令使用自行编写的脚本执行。
由于在此阶段做出的决定会直接影响公司的业务流程,因此在绝大多数情况下采用特定策略的决定仍然是内部信息安全经理的任务(通常涉及业务系统所有者),并且
不能将此任务外包公司 。 信息安全服务提供商在事件本地化中的作用被简化为客户选择的策略的运营应用。
收集,存储和记录事故征候
一旦采取了行动措施以定位事件的地点,则必须进行彻底的调查,收集所有信息以评估程度。 该任务分为两个子任务:
- 将更多的信息传递给监视团队,将事件中涉及的信息安全事件的其他来源连接到事件收集和分析系统。
- 连接取证小组以分析硬盘映像,分析内存泄漏,恶意软件样本以及网络犯罪分子在此事件中使用的工具。
还应任命一个人来协调事件调查框架内所有部门的活动。 该专家应具有参与调查的所有人员的权限和联系。 承包商员工可以执行此角色吗? 否定可能性更大。 将这个角色委托给专家或客户信息安全服务负责人是更合乎逻辑的。
减灾
协调员收到了各个部门对事件的全面了解之后,便制定了消除事件后果的措施。 此过程可能包括:
- 删除已确定的危害指标和恶意软件/入侵者存在的痕迹。
- “重新加载”受感染的主机并更改用户密码。
- 安装最新更新并制定补偿措施,以消除攻击中使用的严重漏洞。
- 更改GIS的安全性配置文件。
- 控制相关单位执行的动作的完整性,以及入侵者不对系统进行重新妥协的控制。
在制定措施时,我们建议协调员与负责特定系统的专门部门,信息安全系统的管理员,取证小组以及IS事件监视服务进行协商。 但是,再次,事件分析小组的协调员将决定采取某些措施。
事件后恢复
在本节中,NIST实际上讨论了IT部门和业务系统运营服务的任务。 所有工作都减少到恢复和验证公司IT系统和业务流程的性能上。 停留在这一点上是没有意义的,因为大多数公司都面临着这些问题的解决方案,即使不是由于信息安全事件造成的,也至少在定期发生故障之后,即使在最稳定和容错的系统安装中也是如此。
有条不紊的活动
事件响应方法论的第四部分致力于解决错误和改进公司的安全技术。
通常,为了准备事件报告,填充知识库和TI,取证团队将与监视服务一起负责。 如果在此事件发生时尚未制定本地化策略,则此块中将包括其编写内容。
好吧,很明显,处理错误的一个重要点是制定一种策略,以防止将来发生类似事件:
- 改变IT基础架构和现有GIS的体系结构。
- 引入新的信息安全工具。
- 介绍补丁程序管理和信息安全事件监视(如果不存在)的过程。
- 纠正公司的业务流程。
- 信息安全部门的其他人员。
- 更改信息安全员工的权限。
服务提供商角色
因此,可以以矩阵的形式表示服务提供商可能参与事件响应的各个阶段:
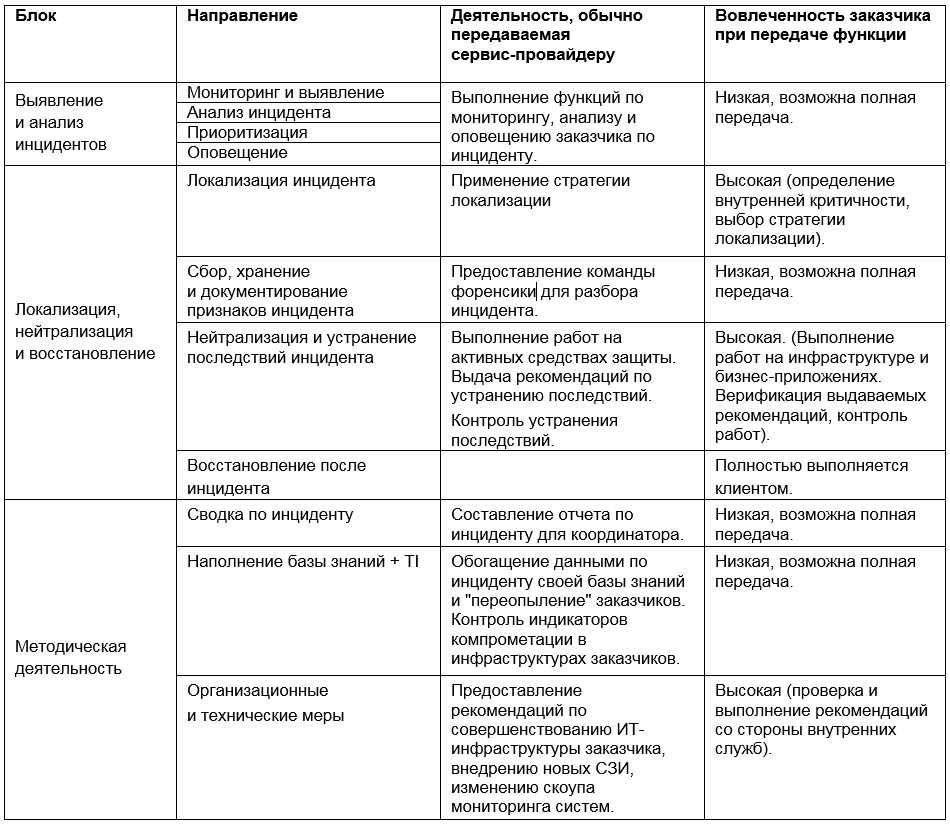
事件管理工具和方法的选择是信息安全最困难的任务之一。 相信服务提供商的承诺并赋予其所有功能的诱惑可能很大,但我们建议对情况进行合理评估,并在内部和外部资源使用之间取得平衡,以实现经济和流程效率的双重利益。