挑战赛
用于存储和分析购买的应用程序的主要任务之一是在数据库中搜索相同或非常接近的产品,该数据库包含从收据中获得的各种且难以理解的产品名称。 有两种类型的输入请求:
- 带缩写的特定名称,只有本地超市的收银员或狂热的买家才能理解。
- 用户在搜索字符串中输入的自然语言查询。
通常,当用户需要寻找更便宜的产品时,第一类要求来自支票本身的产品。 我们的任务是从附近其他商店的支票中选择最相似的产品类似物。 选择最合适的产品品牌,如果可能的话,数量也很重要。
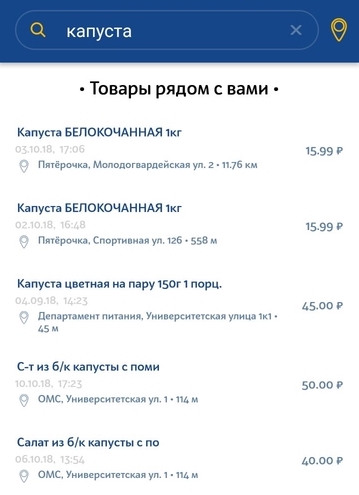
第二类请求是一个简单的用户请求,用于在最近的商店中搜索特定产品。 该请求可以是产品的非常笼统的,非唯一的描述。 可能与要求略有差异。 例如,如果用户搜索3.2%的牛奶,而在我们的数据库中仅搜索2.5%的牛奶,那么我们仍然希望至少显示此结果。
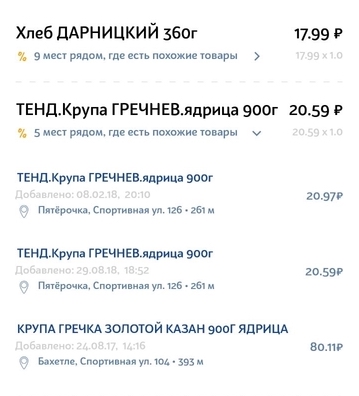
要素数据集-要解决的问题
产品收据中的信息远非理想。 它有很多不总是很清楚的缩写,语法错误,错字,各种翻译,西里尔字母中间的拉丁字母和字符集,这些字符仅对特定商店的内部组织有意义。
例如,可以很容易地在支票上写上一个带有干酪的婴儿苹果香蕉泥:

关于技术
Elasticsearch是一种相当流行且价格合理的技术,用于实现搜索。 这是一个使用Lucene并以Java编写的JSON REST API搜索引擎。 Elastic的主要优点是速度,可伸缩性和容错能力。 类似的引擎用于在文档数据库中进行复杂的搜索。 例如,考虑语言形态的搜索或按地理坐标搜索。
实验和改进的方向
要了解如何改进搜索,您需要将搜索系统解析为其组件自定义组件。 对于我们的情况,系统的结构如下所示。
- 用于搜索的输入字符串通过分析器,该分析器以某种方式将字符串分成令牌-搜索单元在也存储为令牌的数据中进行搜索。
- 然后直接在现有数据库中为每个文档搜索这些标记。 在某个文档中找到令牌(该令牌也作为令牌集在数据库中显示)后,根据所选的相似性模型(我们将其称为相关性模型)计算其相关性。 这可以是简单的TF / IDF (术语频率-反向文档频率),也可以是其他更复杂或特定的模型。
- 在下一个阶段,将以某种方式汇总每个单独令牌所获得的分数。 聚合参数由查询语义设置。 此类聚合的示例可以是某些令牌的附加权重(附加值),令牌强制存在的条件等。 该阶段的结果是评分-对数据库中特定文档相对于初始请求的相关性的最终评估。

可以从搜索设备中区分出三个可单独配置的组件,您可以在每个组件中突出显示自己的改进方式和方法。
- 分析仪
- 相似模型
- 查询时间改进
接下来,我们将分别考虑每个组件,并分析特定的参数设置,这些参数设置有助于改进产品名称的搜索。
查询时间改进
为了了解我们可以在请求中进行哪些改进,我们以初始请求为例。
{ "query": { "multi_match": { "query": " 105", "type": "most_fields", "fields": ["name"], "minimum_should_match": "70%" } }, “size”: 100, “min_score”: 15 }
因为我们预见到“产品名称”字段需要使用多个分析器的组合,所以我们使用most_fields查询类型。 这种类型的查询使您可以组合搜索结果,以不同方式分析包含相同文本的对象的不同属性。 此方法的替代方法是使用best_fields或cross_fields查询,但它们不适合我们的情况,因为搜索是在对象的各种属性(例如名称和描述)之间进行计算的。 我们面临着一项任务,即要考虑一个属性的各个方面-产品名称。
可以配置什么:
- 不同分析仪的加权组合。
最初,所有搜索元素都具有相同的权重-因此具有相同的重要性。 可以通过添加带有数值的参数“ boost”来更改此设置。 如果参数大于1,则搜索元素对结果的影响分别小于1-小于1。 - 将分析器分为“应该”和“必须”。
即,某些分析器必须重合,而某些是可选的,即不足。 在我们的案例中,数字分析器可以是这种分离的好处的一个例子。 如果仅数字与请求中的产品名称与数据库中的产品名称匹配,则这不是等效的充分条件。 我们不想看到这样的产品。 同时,如果要求“奶油10%”,那么我们希望所有脂肪含量10%的奶油都比脂肪含量20%的奶油具有更大的优势。 - minimum_should_match参数。 请求和数据库中的文档中必须匹配多少个令牌? 此参数与请求的类型(most_fields)一起使用,并检查每个字段(在本例中是每个分析器)的最小匹配令牌数。
- Min_score参数。 阈值筛选文件的分数不足。 问题是没有已知的最大速度。 结果分数取决于特定的请求和特定的文档数据库。 有时可以是150,有时是2,但是这两个值都意味着数据库中的对象与请求有关。 我们无法比较不同查询结果的分数。
- 不变的
充分监视不同查询的速度的最终值后,您可以确定一个近似边界,此后对于大多数查询,结果将变得不合适。 这是最简单但也是最愚蠢的决定,从而导致搜索质量低下。 - 在以最小或零的min_score执行搜索后,尝试分析针对特定请求获得的分数。
这个想法是,经过一会儿,您可以观察到速度下降方向的急剧跳跃。 剩下的只是确定该跳跃以便及时停止。 这种方法在类似的查询上会很好地工作:
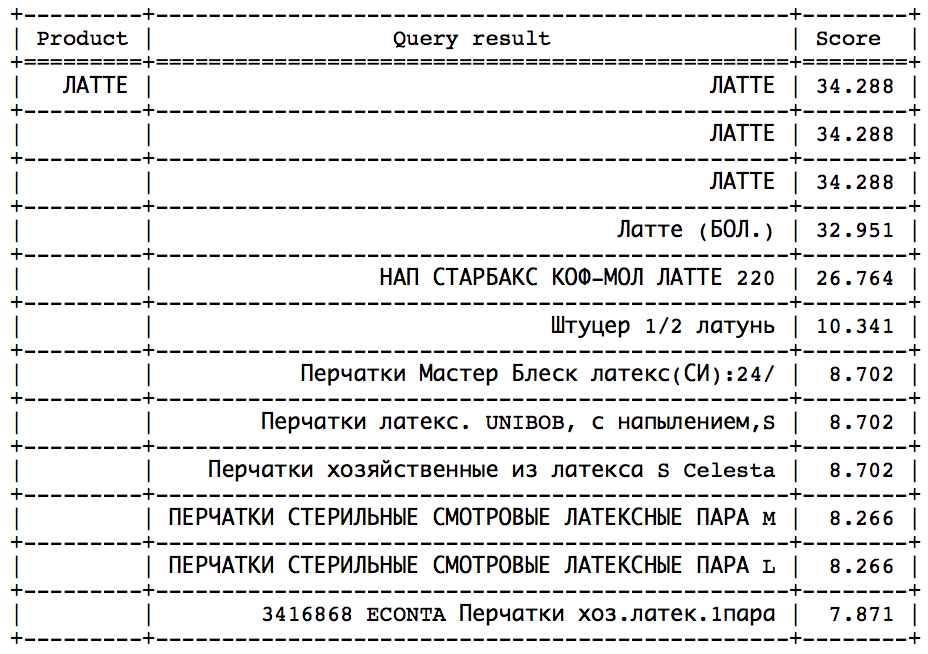
可以通过统计方法找到跳跃。 但是,不幸的是,并非所有请求都存在此跳转,并且很容易识别。 - 计算理想速度,并将min_score设置为理想速度的一部分,这可以通过两种方式完成:
- 根据Elastic自己在设置explain:true参数时提供的计算的详细描述。 这是一项艰巨的任务,需要彻底了解Elastic所使用的查询体系结构和计算算法。
- 通过一点技巧。 我们收到一个请求,将一个具有相同名称的新产品添加到我们的数据库中,进行搜索并获得最快的速度。 由于名称中将有100%匹配,因此结果值将是理想的。 我们尚未在系统中使用此方法,因为尚未确认此操作相对于时间的高成本。
- 更改负责最终相关性值的评分算法。 这可能是在考虑到商店的距离(对靠近的产品给予更多的积分),产品价格(对价格最可能的产品给予更多的积分)等。
分析仪
分析器分三个阶段分析输入字符串,并在输出-搜索单元中输出令牌:

首先,更改发生在字符串的字符级别。 可以替换,删除字符或将字符添加到字符串。 然后,分词器开始工作,该分词器用于将字符串拆分为令牌。 标准令牌生成器根据标点符号将字符串拆分为令牌。 在最后一步,对接收到的令牌进行过滤和处理。
考虑在我们的案例中哪些步骤的变体变得有用。
字符过滤器
- 根据俄语的具体情况,处理诸如th和e之类的字符并将它们分别替换为and和e会很有用。
- 执行音译-将一个书写字符转换为另一个书写字符。 在我们的案例中,这是对用拉丁字母书写或与两个字母混合的名称的处理。 可以使用插件( ICU Analysis Plugin )作为令牌过滤器来实现音译(也就是说,它不处理原始字符串,而是处理最终令牌)。 我们决定编写音译,因为我们对插件中的算法不太满意。 这个想法是首先替换出现的四个字符集(例如“ SHCH => u”),然后替换出现的三个字符,依此类推。使用符号过滤器的顺序很重要,因为结果将取决于顺序。
- 用俄语p替换被西里尔字母包围的拉丁字母c。 在分析了数据库中的名称之后,确定了对此的需要-西里尔语中的很多名称都包括拉丁文c,这意味着西里尔文c。 如果名称完全是拉丁文,则拉丁文C表示西里尔字母k或c。 因此,在音译之前,必须替换字符c。
- 从名称中删除太大的数字。 有时在产品名称中会有一个内部标识号(例如3387522 K.Ts. Maslo podsoln.raf。0.9l),在一般情况下没有任何意义。
- 用句点代替逗号。 为什么需要这个? 因此,数字(例如牛奶3.2和3.2的脂肪含量)是等效的
分词器
- 标准令牌生成器-根据空格和标点符号分隔行(例如,“ twix extra 2”->“ twix”,“ extra”,“ 2”)
- EdgeNGram标记器-将每个单词分成给定长度(通常是数字范围)的标记,从第一个字符开始(例如,对于N = [3,6]:“额外增加2个数字”->“ twee”,“ tweak”, “ Twix”,“ ex”,“ ext”,“ ext”,“ extra”)
- 数字标记器-通过搜索正则表达式从字符串中仅选择数字(例如,“ twix extra 2 4.5”->“ 2”,“ 4.5”)
令牌过滤器
- 小写过滤器
- 填塞过滤器-为每个令牌执行填塞算法。 词干是确定单词的初始形式(例如,“米”->“米”)
- 语音分析。 为了最大程度地减少拼写错误和以相同方式写相同单词对搜索结果的影响,这是必要的。 下表显示了用于语音分析的各种可用算法以及在有问题的情况下其工作的结果。 在第一种情况(洗发水/香槟/香菇/香菇)中,成功的产生取决于不同编码的产生,其余情况相同。

相似模型
需要相关性模型以确定一个令牌的重合在多大程度上影响数据库中对象相对于请求的相关性。 假设请求中的令牌与数据库中的产品相匹配-这当然不错,但是它几乎没有说明产品与请求的一致性。 因此,不同令牌的重合携带不同的值。 为了考虑到这一点,需要相关模型。 Elastic提供了许多不同的模型。 如果您真的了解它们,则可以针对特定情况选择非常具体且合适的模型。 选择可以基于经常使用的单词的数量(例如相同的标记),对长标记的重要性的评估(越长意味着更好?更糟糕?没关系吗?),我们希望最后看到什么结果等。 Elastic中提出的模型的示例可以是TF-IDF(最简单和最容易理解的模型), Okapi BM25 (增强的TF-IDF,默认模型),随机性发散,独立性发散等。 每个模型还具有可自定义的选项。 在对该模型进行多次实验后,Okapi BM25默认模型显示出最佳结果,但参数与预定义的参数不同。
使用类别
在进行搜索的过程中,可以获得有关该产品的非常重要的附加信息-其类别-。 您可以在本文中了解有关我们如何实现分类的更多信息, 据我了解,我吃了很多糖果,或者通过在应用程序中检查来对商品进行分类 。 在此之前,我们仅基于产品名称的比较进行搜索,现在已经可以在数据库中比较请求和产品的类别。
使用此信息的可能选项是在类别字段中进行强制匹配(格式为结果过滤器),具有匹配类别的商品以点的形式(如数字)的附加优势以及按类别对结果进行排序(首先进行匹配,然后进行所有其他匹配)。 对于我们的情况,最后一个选项效果最好。 这是因为我们的分类算法太好了,无法使用第二种方法,而又不足以使用第一种方法。 我们对算法有足够的信心,并希望类别匹配是一大优势。 如果在速度上添加其他点(第二种方法),则具有相同类别的商品将排在列表的上方,但仍会输给某些名称更匹配的商品。 但是,第一种方法也不适合我们,因为分类仍然有可能出错。 有时,该请求可能包含的信息不足,无法正确确定类别,或者在用户的直接半径内,该类别中的产品太少。 在这种情况下,我们仍要显示具有不同类别的结果,但仍按产品名称显示。
第二种方法也很好,因为它不会因搜索而“破坏”产品的速度,并且使您可以继续使用计算出的最小速度而没有障碍。
在最终查询中可以看到排序的具体实现。
最终模型
最终搜索模型的选择包括各种搜索引擎的生成,评估和比较。 通常,比较是基于其中一个参数进行的。 假设在一种特定情况下,我们需要为edgeNgram令牌生成器计算最佳大小(即,选择N的最有效范围)。 为此,我们生成了相同的搜索引擎,但此范围的大小只有一个差异。 之后,可以确定该参数的最佳值。
使用nDCG(归一化折现累积收益)度量标准评估模型,该度量标准用于评估排名质量。 将预定义的查询发送到每个搜索模型,然后根据接收到的搜索结果计算nDCG指标。
进入最终模型的分析器:



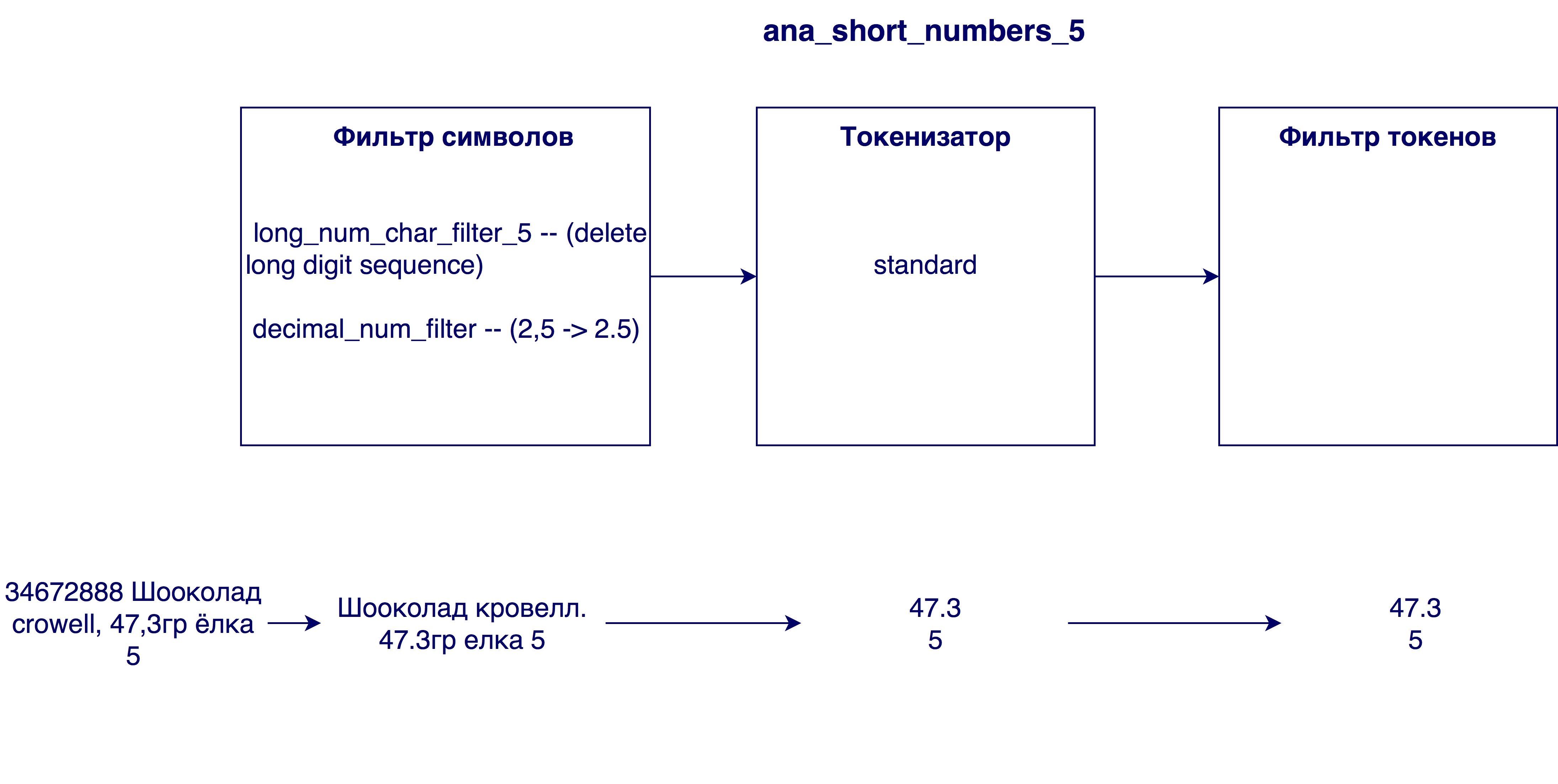
相关参数选择参数b = 0.5的默认模型(Okapi-BM25)。 默认值为0.75。 此参数显示产品名称的长度在多大程度上标准化了tf(术语频率)变量。 在我们的情况下,较小的数字效果更好,因为长名称通常不会影响单个单词的含义。 也就是说,名称“巧克力”和“碎榛子巧克力装25包”的名称不会因其名称足够长而失去其价值。
最终查询如下所示:
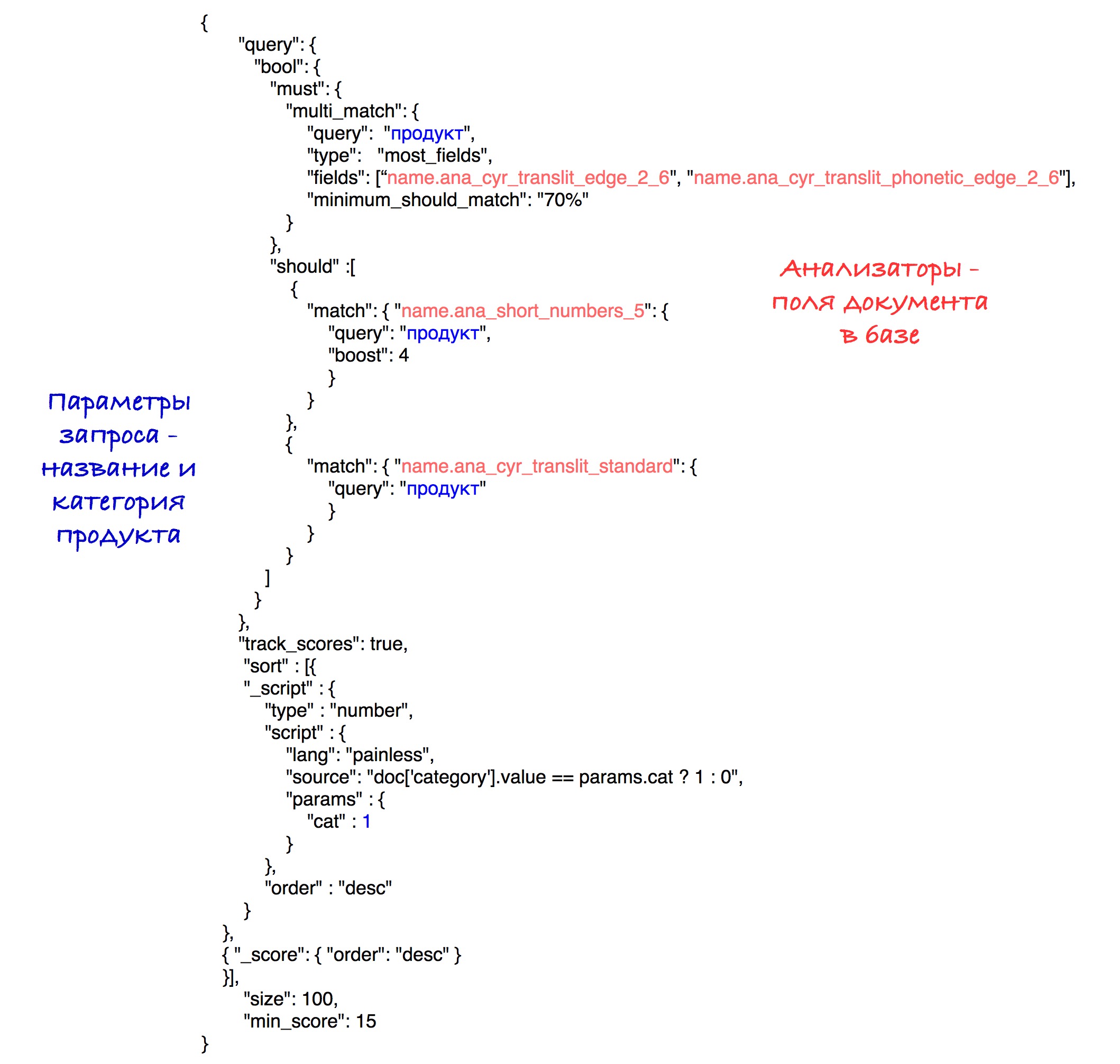
通过实验,揭示了分析仪和砝码的最佳组合。
排序的结果是,具有相同类别的产品转到结果的开头,然后转到所有其他内容。 按点数(速度)排序存储在每个子集中。
为简单起见,在此请求中将速度阈值设置为15,尽管在我们的系统中我们使用了前面所述的计算参数。
将来
有一些想法可以解决我们算法中最令人尴尬的问题之一,那就是存在一百万种和一种缩短5个字母的单词的不同方法来改善搜索效果。 可以通过名称的初始处理来解决它,以显示缩写。 解决此问题的一种方法是尝试将数据库中的缩写名称与数据库中具有“正确”全名的名称之一进行比较。 这一决定遇到了明确的障碍,但似乎是一个有希望的改变。