你好!
在12月,我们将开始为下一个
数据科学家小组提供培训,因此会有越来越多的公开课和其他活动。 例如,就在前几天,以“经典工程”中的“泰坦尼克号数据集”为特色的“特征工程”举行了网络研讨会。 它由
亚历山大·西佐夫 (
Alexander Sizov )进行,
亚历山大·西佐夫 (
Alexander Sizov )是一位经验丰富的开发博士,是机器/深度学习专家,并且是与人工智能和数据分析有关的各种国际商业项目的参与者。
公开课耗时约一个半小时。 在网络研讨会期间,老师讨论了选择功能,转换源数据(编码,缩放),设置参数,训练模型等等。 在课程中,向参与者展示了Jupyter笔记本。 在工作中,我们使用了来自
Kaggle平台(有关泰坦尼克号的经典数据集,许多人开始熟悉Data Science)的开放数据。 下面提供了过去活动的视频和成绩单,在
这里您可以在Jupiter笔记本电脑中获取演示文稿和代码。
功能选择
选择的主题虽然很经典,但仍然有些阴郁。 特别是,有必要解决二进制分类问题,并从可用数据中预测乘客是否会幸存。 数据本身分为两个样本Training和Test。 关键变量是生存(生存/未生存; 0 =否,1 =是)。
输入训练数据:
- 机票舱位
- 乘客的年龄和性别;
- 婚姻状况(船上是否有亲戚);
- 票价;
- 机舱号
- 登船口岸。
如您所见,变量的类型不同:数字,文本。 通过这种万花筒,有必要为即将进行的模型训练形成数据集。
我们总结:
- train.csv-训练集-训练数据集。 答案是已知的-生存-二进制符号0(未生存)/ 1(生存);
- test.csv-测试集-测试数据集。 答案是未知的。 这是一个样本,将发送给kaggle平台以计算模型质量指标;
- sex_submission.csv是要发送到kaggle的数据格式的示例。
工作算法
- 工作分阶段进行:
- 分析来自train.csv的数据。
- 处理缺失值。
- 缩放比例。
- 分类特征的编码。
- 建立模型并选择参数,然后从train.csv中为转换后的数据选择最佳模型。
- 转换方法的固定和模型。
- 使用管道将相同的转换应用于test.csv。
- 该模型在test.csv上的应用。
- 以与gender_submission.csv中相同的格式保存应用程序结果文件。
- 将结果发送到kaggle平台。
网络研讨会的实践部分首先需要做的是读取数据集并在屏幕上显示我们的数据:
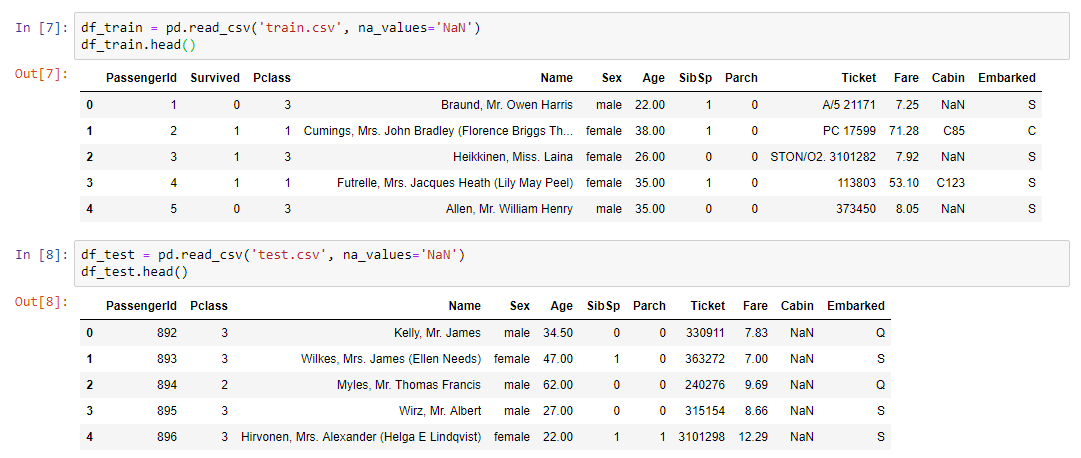
为了进行数据分析,使用了一个鲜为人知但非常有用的性能分析库:
pandas_profiling.ProfileReport(df_train)有关配置的更多信息该库会执行所有可以事前完成的操作,而无需了解有关数据的详细信息。 例如,显示有关数据的统计信息(多少变量和它们是什么类型,多少行,缺少的值,等等)。 此外,每个变量的单独统计信息带有最小值和最大值,分布图和其他参数。
如您所知,要建立一个好的模型,您需要深入研究我们试图模拟的过程,并了解关键属性是什么。 而且,远非总是在我们的数据中需要所有的东西,更确切地说,在他们中几乎从来没有任何需要的东西,它们完全确定并确定了我们的流程。 通常,我们总是需要结合一些东西,也许添加数据集中未显示的其他功能(例如天气预报)。 这是为了了解我们需要数据分析的过程,可以使用配置文件库完成此过程。
缺失值下一步是解决缺少值的问题,因为在大多数情况下,数据不会完全填充。
以下解决方案可用于此问题:
- 删除缺少值的行(请记住,您可能会丢失一些重要值);
- 删除标志(如果数据太少则相关);
- 用其他内容(中位数,平均值...)替换缺失值。
使用fillna方法的简单转换示例,该方法将中值变量的值仅分配给那些未填充的单元格:

此外,老师还展示了使用Imputer和管道的示例。
功能缩放模型的操作和最终决定取决于功能的规模。 事实是,具有较大比例尺的要素比具有较小比例尺的要素更重要。 这就是为什么模型需要提交比例缩放的特征,即特征具有相同的权重。
缩放技术有不同,但是,公开课的格式只允许我们更详细地考虑其中的两个:
 功能组合
功能组合使用算术运算(求和,乘法,除法)组合现有特征可以使您获得使模型更有效的任何特征。 这并不总是成功的,并且我们不知道哪种组合会达到预期的效果,但是实践表明尝试这种方法是有意义的。 使用管道应用特征转换非常方便。
编码方式因此,我们拥有不同类型的数据:数字和文本。 当前,市场上的大多数模型都无法使用文本数据。 结果,必须将所有分类符号(文本)转换为数字表示形式,并为此使用编码。
标签编码 。 这是在许多可以调用和应用的库的框架中实现的机制:

标签编码为每个唯一值分配一个唯一标识符。 减号-我们将排序引入到未排序的某个变量中,这不好。
OneHotEncoder。 文本变量的唯一值以添加到源数据中的列的形式扩展,其中每一列都是0和1形式的二进制变量。这种方法没有Label编码缺陷,但有其缺点:如果有很多唯一值,我们会添加太多列在某些情况下,该方法根本不适用(数据集增长过多)。
模型训练执行上述步骤后,将使用一组所有必要的操作来编译最终管道。 现在,足以获取源数据集,并使用fit_transform操作将结果管道应用于此数据:
x_train = vec.fit_transform(df_train)结果,我们获得了x_train数据集,可以在模型中使用它。 唯一要做的是分离目标变量的值,以便我们进行培训。
接下来,选择模型。 作为网络研讨会的一部分,老师提出了一个简单的逻辑回归。 使用拟合操作对模型进行了训练,从而产生了具有某些参数的逻辑回归形式的模型:
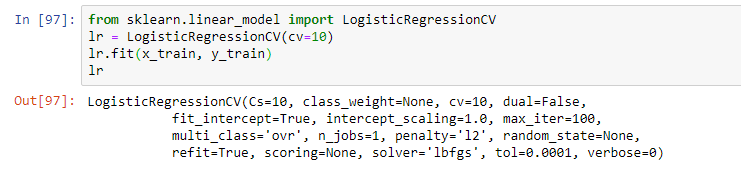
但是,实际上,通常使用几种似乎最有效的模型。 最终的解决方案通常是使用堆叠技术和其他方法集成模型(使用同一混合模型中的多个模型)的这些模型的组合。
训练后,该模型可以应用于测试数据,并在某些指标框架内评估其质量。 在我们的案例中,precision_score内的质量为0.8:

这意味着在80%的情况下,可以根据获得的数据正确预测变量。 收到训练结果后,我们可以改进模型(如果准确性不令人满意),也可以直接进行预测。
这是本课程的主要主题,但是老师更详细地讨论了模型在不同任务中的功能,并回答了听众的问题。 因此,如果您不想错过任何内容,请对本主题感兴趣,观看完整的网络研讨会。
与往常一样,我们正在等待您的评论和问题,您可以在这里离开,也可以在
开放日去
亚历山大询问他们
。