在项目管理和任务跟踪系统中制作票证,我们每个人都非常高兴看到上诉决定的大致条款。
收到入场票流时,人员/团队需要将他们排在优先级和时间上,以解决每个申诉。
所有这些使您可以更有效地为双方安排时间。
在剪辑中,我将讨论如何分析和训练机器学习模型,这些模型可以预测解决向我们团队发出的票证所需的时间。
我本人在一个名为LAB的团队中担任SRE职位。 我们正接到开发人员和质量检查人员的电话,内容涉及新测试环境的部署,其对最新发行版的更新,针对出现的各种问题的解决方案等等。 这些任务是非常不同的,并且在逻辑上需要花费不同的时间来完成。 我们的团队已有数年之久,在此期间积累了良好的请求基础。 我决定分析此基础,并在机器学习的帮助下,基于此基础,构建一个模型,该模型将处理对上诉可能的结束时间(票)的预测。
在我们的工作中,我们使用JIRA,但是,本文中介绍的模型没有指向特定产品的链接-从任何数据库中获取必要的信息都不是问题。
因此,让我们从言传身行。
初步数据分析
我们加载所需的一切,并显示所用软件包的版本。
源代码import warnings warnings.simplefilter('ignore') %matplotlib inline import matplotlib.pyplot as plt import pandas as pd import numpy as np import datetime from nltk.corpus import stopwords from sklearn.model_selection import train_test_split from sklearn.metrics import mean_absolute_error, mean_squared_error from sklearn.neighbors import KNeighborsRegressor from sklearn.linear_model import LinearRegression from datetime import time, date for package in [pd, np, matplotlib, sklearn, nltk]: print(package.__name__, 'version:', package.__version__)
pandas version: 0.23.4 numpy version: 1.15.0 matplotlib version: 2.2.2 sklearn version: 0.19.2 nltk version: 3.3
从csv文件下载数据。 它包含有关过去1.5年内关闭的门票的信息。 在将数据写入文件之前,需要对它们进行一些预处理。 例如,逗号和句点已从带有说明的文本字段中删除。 但是,这只是初步处理,将来会进一步清除文本。
让我们看看数据集中的内容。 总共有10783张门票。
栏位说明| 已建立 | 工单创建日期和时间 |
| 已解决 | 门票截止日期和时间 |
| 解析时间 | 创建和关闭故障单之间经过的分钟数。 它被认为是日历时间,因为 该公司在不同的国家设有办事处,在不同的时区工作,整个部门没有固定的时间。 |
| 工程师_N | 工程师的“编码”名称(为了将来不会无意间泄露任何个人或机密信息,文章中将有很多“编码”数据,这些数据实际上只是重命名了)。 这些字段包含在显示的日期集中接收到每个票证时处于“进行中”模式的票证数量。 我将在本文结尾处分别介绍这些领域,因为 他们值得特别注意。 |
| 受让人 | 解决问题的员工。 |
| 问题类型 | 票证类型。 |
| 环境环境 | 为其制作票证的测试工作环境的名称(可能表示特定环境或整个位置,例如,数据中心)。 |
| 优先权 | 票务优先权。 |
| 工作类型 | 此票证预期的工作类型(添加或删除服务器,更新环境,使用监视等) |
| 内容描述 | 内容描述 |
| 总结 | 票证标题。 |
| 观察者 | “观看”门票的人数,即 他们会收到故障单中每个活动的电子邮件通知。 |
| 投票数 | “投票”购票的人数,从而表明其重要性和对其的兴趣。 |
| 记者 | 出票的人。 |
| Engineer_N_vacation | 发行票时工程师是否在休假。 |
df.info()
<class 'pandas.core.frame.DataFrame'> Index: 10783 entries, ENV-36273 to ENV-49164 Data columns (total 37 columns): Created 10783 non-null object Resolved 10783 non-null object Resolution_time 10783 non-null int64 engineer_1 10783 non-null int64 engineer_2 10783 non-null int64 engineer_3 10783 non-null int64 engineer_4 10783 non-null int64 engineer_5 10783 non-null int64 engineer_6 10783 non-null int64 engineer_7 10783 non-null int64 engineer_8 10783 non-null int64 engineer_9 10783 non-null int64 engineer_10 10783 non-null int64 engineer_11 10783 non-null int64 engineer_12 10783 non-null int64 Assignee 10783 non-null object Issue_type 10783 non-null object Environment 10771 non-null object Priority 10783 non-null object Worktype 7273 non-null object Description 10263 non-null object Summary 10783 non-null object Watchers 10783 non-null int64 Votes 10783 non-null int64 Reporter 10783 non-null object engineer_1_vacation 10783 non-null int64 engineer_2_vacation 10783 non-null int64 engineer_3_vacation 10783 non-null int64 engineer_4_vacation 10783 non-null int64 engineer_5_vacation 10783 non-null int64 engineer_6_vacation 10783 non-null int64 engineer_7_vacation 10783 non-null int64 engineer_8_vacation 10783 non-null int64 engineer_9_vacation 10783 non-null int64 engineer_10_vacation 10783 non-null int64 engineer_11_vacation 10783 non-null int64 engineer_12_vacation 10783 non-null int64 dtypes: float64(12), int64(15), object(10) memory usage: 3.1+ MB
总共,我们有10个“对象”字段(即包含文本值)和27个数字字段。
首先,立即在我们的数据中查找排放。 如您所见,有些故障单的决策时间估计为数百万分钟。 这显然不是相关信息,此类数据只会干扰模型的构建。 之所以到达这里,是因为JIRA的数据收集是通过对“已解决”字段的查询执行的,而不是“创建”的。 因此,在过去1.5年中关闭的那些票到达了这里,但可以早些打开。 现在是摆脱它们的时候了。 我们将丢弃那些在2017年6月1日之前创建的票证。 我们将剩下9493张门票。
出于原因-我认为在每个项目中,您都可以轻松地找到由于各种情况而徘徊了很长时间的请求,而且通常不是通过解决问题本身而是通过“限制时效”来关闭请求。
源代码 df[['Created', 'Resolved', 'Resolution_time']].sort_values('Resolution_time', ascending=False).head()

源代码 df = df[df['Created'] >= '2017-06-01 00:00:00'] print(df.shape)
(9493, 33)
因此,让我们开始看看我们可以从数据中找到什么有趣的东西。 首先,让我们找出最简单的-票证中最流行的环境,最活跃的“记者”等。
源代码 df.describe(include=['object'])

源代码 df['Environment'].value_counts().head(10)
Environment_104 442 ALL 368 Location02 367 Environment_99 342 Location03 342 Environment_31 322 Environment_14 254 Environment_1 232 Environment_87 227 Location01 202 Name: Environment, dtype: int64
源代码 df['Reporter'].value_counts().head()
Reporter_16 388 Reporter_97 199 Reporter_04 147 Reporter_110 145 Reporter_133 138 Name: Reporter, dtype: int64
源代码 df['Worktype'].value_counts()
Support 2482 Infrastructure 1655 Update environment 1138 Monitoring 388 QA 300 Numbers 110 Create environment 95 Tools 62 Delete environment 24 Name: Worktype, dtype: int64
源代码 df['Priority'].value_counts().plot(kind='bar', figsize=(12,7), rot=0, fontsize=14, title=' ');
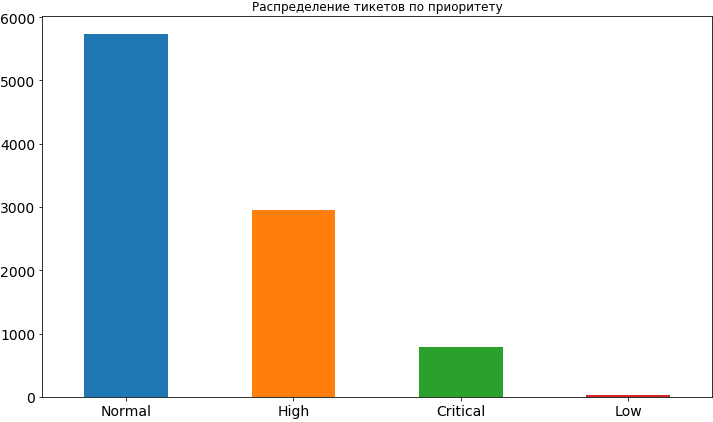
好吧,我们已经学到了一些东西。 多数情况下,票证的优先级是正常的,比高优先级低2倍,甚至不那么严格。 很少有低优先级,显然人们害怕暴露它,认为在这种情况下它将在队列中挂起相当长的时间,并且可能会延迟其决定时间。 稍后,当我们已经建立模型并分析其结果时,我们将看到这种担心可能并非没有根据,因为低优先级确实会影响任务的时间范围,并且当然不会影响加速的方向。
从最流行的环境和最活跃的报告程序的列中,我们看到Reporter_16的使用率大大提高,而Environment_104在该环境中排名第一。 即使您还没有猜到,我也会告诉您一个小秘密-这位记者是在这个特定环境下工作的团队的。
让我们看看最关键的票证来自哪种环境。
源代码 df[df['Priority'] == 'Critical']['Environment'].value_counts().index[0]
'Environment_91'
现在,我们将打印出有关来自同一“关键”环境的具有不同优先级的故障单的信息。
源代码 df[df['Environment'] == df[df['Priority'] == 'Critical']['Environment'].value_counts().index[0]]['Priority'].value_counts()
High 62 Critical 57 Normal 46 Name: Priority, dtype: int64
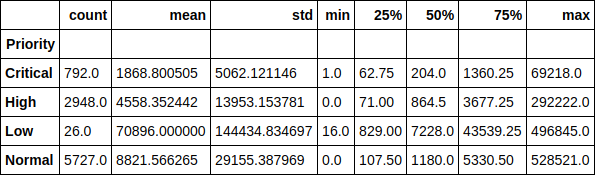
让我们在优先级的上下文中查看票证的执行时间。 例如,有趣的是,低优先级票证的平均运行时间超过7万分钟(约1.5个月)。 凭单执行时间对其优先级的依赖性也很容易追踪。
源代码 df.groupby(['Priority'])['Resolution_time'].describe()
或此处为图形,中间值。 如您所见,情况没有太大变化,因此,排放不会对分布产生很大影响。
源代码 df.groupby(['Priority'])['Resolution_time'].median().sort_values().plot(kind='bar', figsize=(12,7), rot=0, fontsize=14);

现在,让我们看看每个工程师的平均故障单解决时间,具体取决于当时工程师拥有多少故障单。 实际上,令我惊讶的是,这些图没有显示任何图片。 对于某些人来说,执行时间随着工作中当前票证的增加而增加,而对于某些人而言,这种关系却相反。 对于某些人来说,成瘾根本无法追溯。
但是,再次展望,我会说此功能在数据集中的存在使模型的准确性提高了2倍以上,并且肯定会对执行时间产生影响。 我们只是没有看到他。 模型看到了。
源代码 engineers = [i.replace('_vacation', '') for i in df.columns if 'vacation' in i] cols = 2 rows = int(len(engineers) / cols) fig, axes = plt.subplots(nrows=rows, ncols=cols, figsize=(16,24)) for i in range(rows): for j in range(cols): df.groupby(engineers[i * cols + j])['Resolution_time'].mean().plot(kind='bar', rot=0, ax=axes[i, j]).set_xlabel('Engineer_' + str(i * cols + j + 1)) del cols, rows, fig, axes
让我们对具有以下特征的成对交互进行小的矩阵处理:票务解决时间,票数和观察者数量。 有了对角线奖金,我们就可以分配每个属性。
从有趣的一件事中,可以看到减少票务解决时间对越来越多的观察员的依赖性。 还可以看到人们在使用投票方面不是很活跃。
源代码 pd.scatter_matrix(df[['Resolution_time', 'Watchers', 'Votes']], figsize=(15, 15), diagonal='hist');
因此,我们对数据进行了较小的初步分析,看到了目标属性(即解决票证所需的时间)与诸如票证的票数,其背后的“观察员”数量及其优先级之类的标志之间存在的依存关系。 我们继续前进。
建立模型。 建筑标志
现在该继续构建模型本身了。 但是首先,我们需要将我们的功能引入模型可以理解的形式。 即 将分类符号分解为稀疏向量,并消除多余的向量。 例如,我们不需要模型中创建票证和关闭票证的时间字段以及“受让人”字段,因为 我们最终将使用该模型来预测尚未分配给任何人(“暗杀”)的故障单的执行时间。
正如我刚才提到的,目标标志是时候为我们解决问题了,因此我们将其作为一个单独的向量并将其从常规数据集中删除。 此外,由于报告者在发放票证时并不总是填写描述字段,因此某些字段为空。 在这种情况下,pandas将其值设置为NaN,我们只是将它们替换为空字符串。
源代码 y = df['Resolution_time'] df.drop(['Created', 'Resolved', 'Resolution_time', 'Assignee'], axis=1, inplace=True) df['Description'].fillna('', inplace=True) df['Summary'].fillna('', inplace=True)
我们将分类符号分解为稀疏向量( 单热编码 )。 直到我们触摸票证的描述和目录字段。 我们将以不同的方式使用它们。 一些报告者名称包含[X]。 因此,JIRA标记了不再在公司工作的不活跃员工。 我决定将它们留在标志中,尽管有可能清除它们中的数据,因为将来在使用模型时,我们将看不到这些员工的罚单。
源代码 def create_df(dic, feature_list): out = pd.DataFrame(dic) out = pd.concat([out, pd.get_dummies(out[feature_list])], axis = 1) out.drop(feature_list, axis = 1, inplace = True) return out X = create_df(df, df.columns[df.dtypes == 'object'].drop(['Description', 'Summary'])) X.columns = X.columns.str.replace(' \[X\]', '')
现在,我们将处理故障单中的描述字段。 我们将以一种可能最简单的方式来使用它-我们将收集票证中使用的所有单词,计算其中最流行的单词,舍弃“多余的”单词-那些显然不会影响结果的单词,例如单词最受欢迎的“请”(请-JIRA中的所有交流都严格以英语进行)。 是的,这些是我们的有礼貌的人。
根据nltk库,我们还删除了“ 停用词 ”,并更彻底地清除了不必要字符的文本。 让我提醒您,这是可以用文本完成的最简单的事情。 我们不“ 盖章 ”单词,您也可以数出最流行的N-gram单词,但是我们将限于此。
源代码 all_words = np.concatenate(df['Description'].apply(lambda s: s.split()).values) stop_words = stopwords.words('english') stop_words.extend(['please', 'hi', '-', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '(', ')', '=', '{', '}']) stop_words.extend(['h3', '+', '-', '@', '!', '#', '$', '%', '^', '&', '*', '(for', 'output)']) stop_symbols = ['=>', '|', '[', ']', '#', '*', '\\', '/', '->', '>', '<', '&'] words_series = pd.Series(list(all_words)) del all_words words_series = words_series[~words_series.isin(stop_words)] for symbol in stop_symbols: words_series = words_series[~words_series.str.contains(symbol, regex=False, na=False)]
完成所有这些之后,我们得到了pandas.Series对象,其中包含所有使用的单词。 让我们看一下其中最受欢迎的一个,并从列表中选择前50个作为标志。 对于每张票证,我们将查看说明中是否使用了该词,如果是,则在相应的列中输入1,否则输入0。
源代码 usefull_words = list(words_series.value_counts().head(50).index) print(usefull_words[0:10])
['error', 'account', 'info', 'call', '{code}', 'behavior', 'array', 'update', 'env', 'actual']
现在,在我们的常规数据集中,我们将为所选单词创建单独的列。 在此,您可以摆脱描述字段本身。
源代码 for word in usefull_words: X['Description_' + word] = X['Description'].str.contains(word).astype('int64') X.drop('Description', axis=1, inplace=True)
我们将对票证标题字段执行相同的操作。
源代码 all_words = np.concatenate(df['Summary'].apply(lambda s: s.split()).values) words_series = pd.Series(list(all_words)) del all_words words_series = words_series[~words_series.isin(stop_words)] for symbol in stop_symbols: words_series = words_series[~words_series.str.contains(symbol, regex=False, na=False)] usefull_words = list(words_series.value_counts().head(50).index) for word in usefull_words: X['Summary_' + word] = X['Summary'].str.contains(word).astype('int64') X.drop('Summary', axis=1, inplace=True)
让我们看看在特征矩阵X和响应向量y中得到的结果。
((9493, 1114), (9493,))
现在,我们将这些数据分为百分比为75/25的训练(训练)样本和测试样本。 共有7119个示例可供我们训练,而2374个示例可以供我们评估模型。 由于分类符号的布局,我们的属性矩阵的维数增加到1114。
源代码 X_train, X_holdout, y_train, y_holdout = train_test_split(X, y, test_size=0.25, random_state=17) print(X_train.shape, X_holdout.shape)
((7119, 1114), (2374, 1114))
我们训练模型。
线性回归
让我们从最轻和(预期)最不准确的模型开始-线性回归。 我们将通过训练数据的准确性以及延迟的(保持)样本(模型未看到的数据)来评估。
在线性回归的情况下,模型在训练数据上或多或少都可以接受,但是延迟样本的准确性非常低。 甚至比预测所有门票的通常平均水平差得多。
在这里,您需要休息一下,并告诉模型如何使用评分方法评估质量。
通过确定系数进行评估:
哪里 模型A预测的结果是 -整个样本的平均值。
我们现在不会过多地讨论系数。 我们只注意到它不能完全反映我们感兴趣的模型的准确性。 因此,同时,我们将使用平均绝对误差(MAE)进行评估并依靠它。
源代码 lr = LinearRegression() lr.fit(X_train, y_train) print('R^2 train:', lr.score(X_train, y_train)) print('R^2 test:', lr.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(lr.predict(X_train), y_train)) print('MAE test', mean_absolute_error(lr.predict(X_holdout), y_holdout))
R^2 train: 0.3884389470220214 R^2 test: -6.652435243123196e+17 MAE train: 8503.67256637168 MAE test: 1710257520060.8154
梯度提升
好吧,如果没有它,没有梯度增强? 让我们尝试训练模型,看看会发生什么。 我们将为此使用臭名昭著的XGBoost。 让我们从标准超参数设置开始。
源代码 import xgboost xgb = xgboost.XGBRegressor() xgb.fit(X_train, y_train) print('R^2 train:', xgb.score(X_train, y_train)) print('R^2 test:', xgb.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(xgb.predict(X_train), y_train)) print('MAE test', mean_absolute_error(xgb.predict(X_holdout), y_holdout))
R^2 train: 0.5138516547636054 R^2 test: 0.12965507684512545 MAE train: 7108.165167471887 MAE test: 8343.433260957032
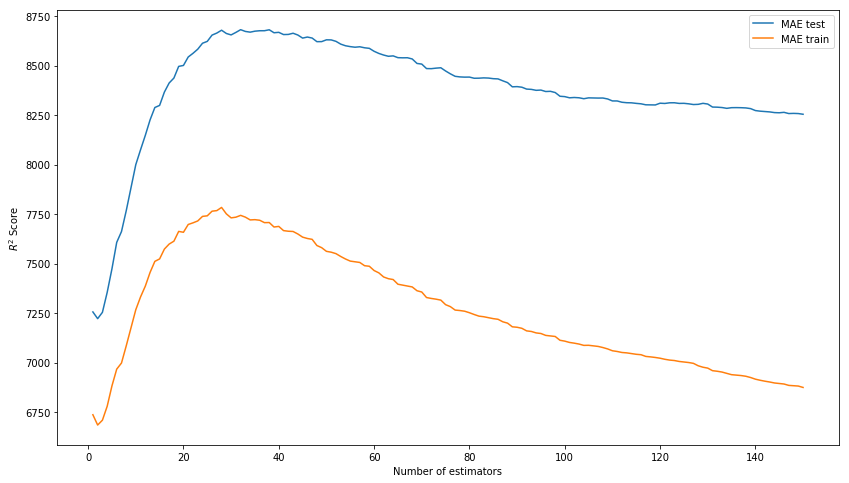
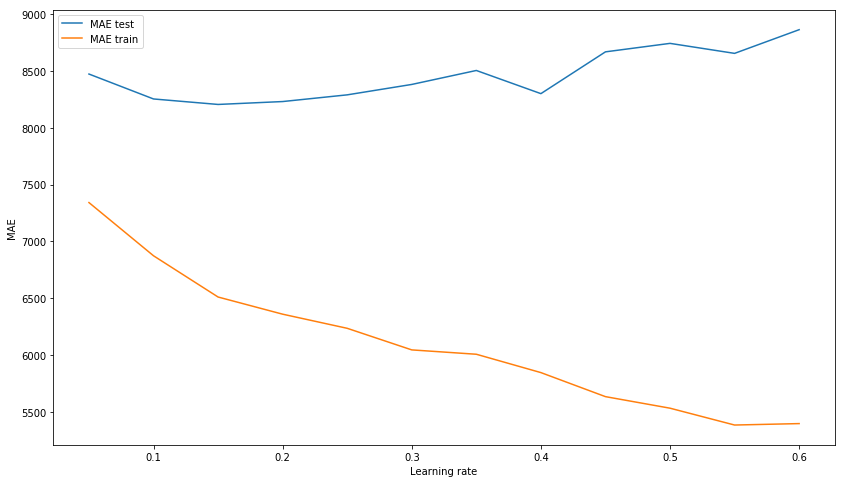
包装盒的结果不再是问题。 让我们尝试通过选择超参数对模型进行建模:n_estimators,learning_rate和max_depth。 结果,我们分别停留在150、0.1和3的值上,因为在没有对训练数据进行模型过度训练的情况下,在测试样本上显示了最佳结果。
我们选择n_estimators* 图片中的得分应为MAE,而不是R ^ 2。
xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(1,151) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Number of estimators') plt.ylabel('$R^2 Score$') plt.legend(loc='best') plt.show();
我们选择learning_rate xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(0.05, 0.65, 0.05) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Learning rate') plt.ylabel('MAE') plt.legend(loc='best') plt.show();
我们选择max_depth xgb_model_abs_testing = list() xgb_model_abs_training = list() rng = np.arange(1, 11) for i in rng: xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=0.1, max_depth=i) xgb.fit(X_train, y_train) xgb.score(X_holdout, y_holdout) xgb_model_abs_testing.append(mean_absolute_error(xgb.predict(X_holdout), y_holdout)) xgb_model_abs_training.append(mean_absolute_error(xgb.predict(X_train), y_train)) plt.figure(figsize=(14, 8)) plt.plot(rng, xgb_model_abs_testing, label='MAE test'); plt.plot(rng, xgb_model_abs_training, label='MAE train'); plt.xlabel('Maximum depth') plt.ylabel('MAE') plt.legend(loc='best') plt.show();

现在,我们将使用选定的超参数训练模型。
源代码 xgb = xgboost.XGBRegressor(n_estimators=150, random_state=17, learning_rate=0.1, max_depth=3) xgb.fit(X_train, y_train) print('R^2 train:', xgb.score(X_train, y_train)) print('R^2 test:', xgb.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(xgb.predict(X_train), y_train)) print('MAE test', mean_absolute_error(xgb.predict(X_holdout), y_holdout))
R^2 train: 0.6745967150462303 R^2 test: 0.15415143189670344 MAE train: 6328.384400466232 MAE test: 8217.07897417256
具有选定参数和可视化效果的最终结果具有重要性-根据模型显示标志的重要性。 首先是票务观察员的数量,但随后有4位工程师马上就去了。 因此,工程师的雇用会极大地影响票的雇用时间。 逻辑上,其中一些的空闲时间更为重要。 至少因为团队既有高级工程师又有中级人才(我们没有初级人员)。 顺便说一句,还是秘密的,排在第一位的工程师(橙色栏)确实是整个团队中经验最丰富的工程师之一。 而且,所有这4位工程师在其职位中都具有高级前缀。 事实证明,该模型再次证实了这一点。
源代码 features_df = pd.DataFrame(data=xgb.feature_importances_.reshape(1, -1), columns=X.columns).sort_values(axis=1, by=[0], ascending=False) features_df.loc[0][0:10].plot(kind='bar', figsize=(16, 8), rot=75, fontsize=14);
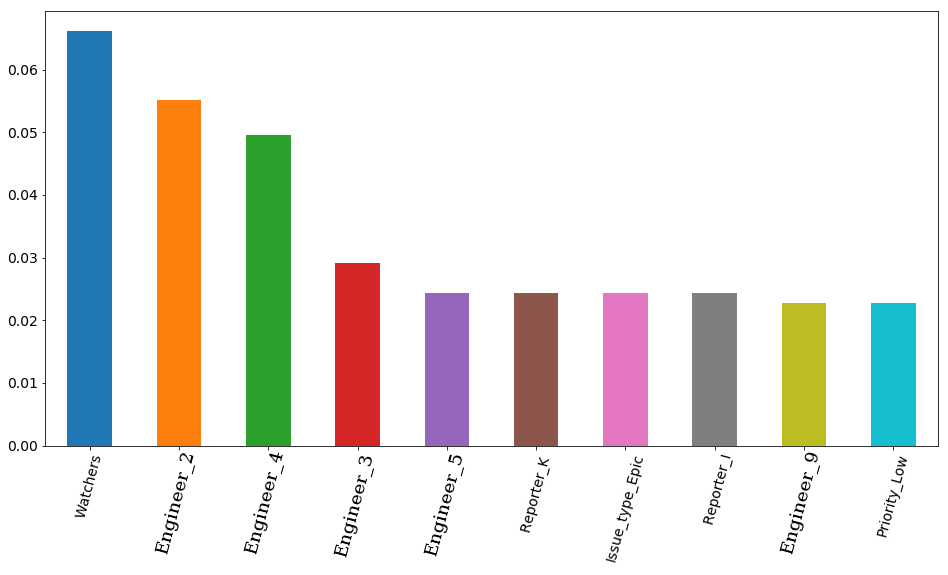
神经网络
但是,我们不会止步于梯度提升,而是尝试训练神经网络,或者更确切地说是多层感知器,即完全连接的直接分布神经网络。 这次我们将不从超参数的标准设置开始,因为 在我们将使用的sklearn库中,默认情况下,只有一个隐藏的层包含100个神经元,并且在训练过程中,该模型会警告有关标准200次迭代的不一致。 我们立即使用分别具有300、200和100个神经元的3个隐藏层。
结果,我们看到模型没有在训练样本上过度训练,但是,这并不能阻止模型在测试样本上显示出令人满意的结果。 这个结果比梯度提升的结果差很多。
源代码 from sklearn.neural_network import MLPRegressor nn = MLPRegressor(random_state=17, hidden_layer_sizes=(300, 200 ,100), alpha=0.03, learning_rate='adaptive', learning_rate_init=0.0005, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) print('R^2 train:', nn.score(X_train, y_train)) print('R^2 test:', nn.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(nn.predict(X_train), y_train)) print('MAE test', mean_absolute_error(nn.predict(X_holdout), y_holdout))
R^2 train: 0.9771443840549647 R^2 test: -0.15166596239118246 MAE train: 1627.3212161350423 MAE test: 8816.204561947616
让我们看看通过尝试选择网络的最佳体系结构可以实现的目标。 , , 200 , , . .
plt.figure(figsize=(14, 8)) for i in [(500,), (750,), (1000,), (500,500)]: nn = MLPRegressor(random_state=17, hidden_layer_sizes=i, alpha=0.03, learning_rate='adaptive', learning_rate_init=0.0005, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) plt.plot(nn.loss_curve_, label=str(i)); plt.xlabel('Iterations') plt.ylabel('MSE') plt.legend(loc='best') plt.show()

. 3 10 .
plt.figure(figsize=(14, 8)) for i in [(500,300,100), (80, 60, 60, 60, 40, 40, 40, 40, 20, 10), (80, 60, 60, 40, 40, 40, 20, 10), (150, 100, 80, 60, 40, 40, 20, 10), (200, 100, 100, 100, 80, 80, 80, 40, 20), (80, 40, 20, 20, 10, 5), (300, 250, 200, 100, 80, 80, 80, 40, 20)]: nn = MLPRegressor(random_state=17, hidden_layer_sizes=i, alpha=0.03, learning_rate='adaptive', learning_rate_init=0.001, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) plt.plot(nn.loss_curve_, label=str(i)); plt.xlabel('Iterations') plt.ylabel('MSE') plt.legend(loc='best') plt.show()
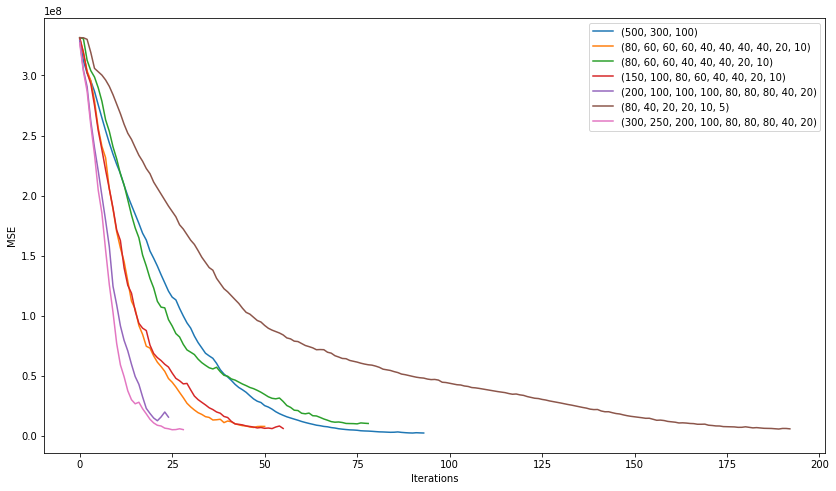
"" (200, 100, 100, 100, 80, 80, 80, 40, 20) :
2506
7351
, , . learning rate .
nn = MLPRegressor(random_state=17, hidden_layer_sizes=(200, 100, 100, 100, 80, 80, 80, 40, 20), alpha=0.1, learning_rate='adaptive', learning_rate_init=0.007, max_iter=200, momentum=0.9, nesterovs_momentum=True) nn.fit(X_train, y_train) print('R^2 train:', nn.score(X_train, y_train)) print('R^2 test:', nn.score(X_holdout, y_holdout)) print('MAE train', mean_absolute_error(nn.predict(X_train), y_train)) print('MAE test', mean_absolute_error(nn.predict(X_holdout), y_holdout))
R^2 train: 0.836204705204337 R^2 test: 0.15858607391959356 MAE train: 4075.8553476632796 MAE test: 7530.502826043687
, . , . , , .
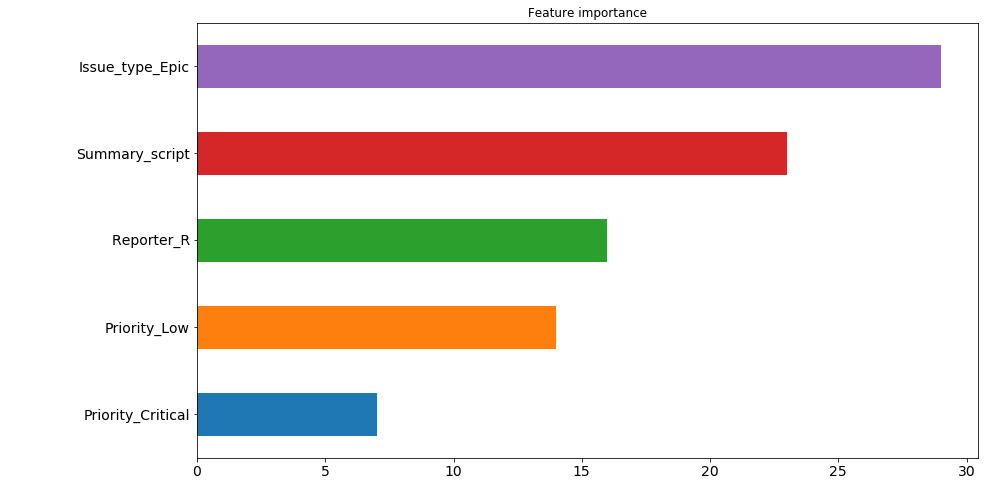
. : ( , 200 ). , "" . , 30 200 , issue type: Epic . , .. , , , , . 4 5 . , . , .
— 9 , . , , , .
pd.Series([X_train.columns[abs(nn.coefs_[0][:,i]).argmax()] for i in range(nn.hidden_layer_sizes[0])]).value_counts().head(5).sort_values().plot(kind='barh', title='Feature importance', fontsize=14, figsize=(14,8));
. 怎么了 7530 8217. (7530 + 8217) / 2 = 7873, , , ? 不,不是那样。 , . , 7526.
, kaggle . , , .
nn_predict = nn.predict(X_holdout) xgb_predict = xgb.predict(X_holdout) print('NN MSE:', mean_squared_error(nn_predict, y_holdout)) print('XGB MSE:', mean_squared_error(xgb_predict, y_holdout)) print('Ensemble:', mean_squared_error((nn_predict + xgb_predict) / 2, y_holdout)) print('NN MAE:', mean_absolute_error(nn_predict, y_holdout)) print('XGB MSE:', mean_absolute_error(xgb_predict, y_holdout)) print('Ensemble:', mean_absolute_error((nn_predict + xgb_predict) / 2, y_holdout))
NN MSE: 628107316.262393 XGB MSE: 631417733.4224195 Ensemble: 593516226.8298339 NN MAE: 7530.502826043687 XGB MSE: 8217.07897417256 Ensemble: 7526.763569558157
? 7500 . 即 5 . . . , .
( ):
((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values(ascending=False).head(10).values
[469132.30504392, 454064.03521379, 252946.87342439, 251786.22682697, 224012.59016987, 15671.21520735, 13201.12440327, 203548.46460229, 172427.32150665, 171088.75543224]
. , .
df.loc[((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values(ascending=False).head(10).index][['Issue_type', 'Priority', 'Worktype', 'Summary', 'Watchers']]
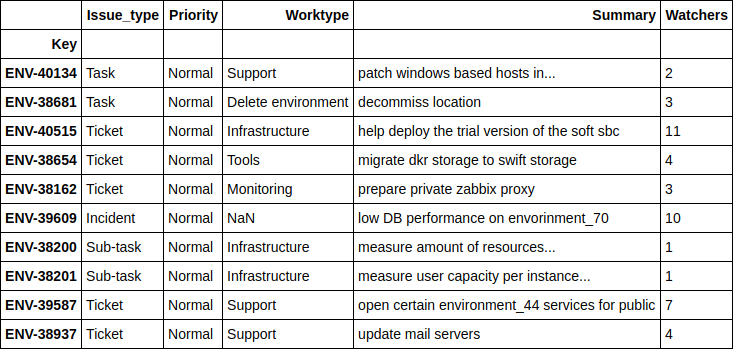
, - , . 4 .
, .
print(((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values().head(10).values) df.loc[((nn_predict + xgb_predict) / 2 - y_holdout).apply(np.abs).sort_values().head(10).index][['Issue_type', 'Priority', 'Worktype', 'Summary', 'Watchers']]
[ 1.24606014, 2.6723969, 4.51969139, 10.04159236, 11.14335444, 14.4951508, 16.51012874, 17.78445744, 21.56106258, 24.78219295]
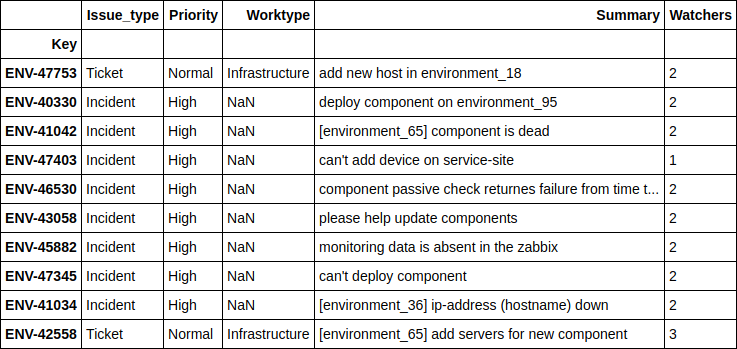
, , - , - . , , , .
Engineer
, 'Engineer', , , ? .
, 2 . , , , , . , , , "" , ( ) , , , . , " ", .
, . , , 12 , ( JQL JIRA):
assignee was engineer_N during (ticket_creation_date) and status was "In Progress"
10783 * 12 = 129396 , … . , , , .. 5 .
, , , , 2 . .
. SLO , .
, , ( : - , - , - ) , .