这篇文章继续讨论性能改进的问题,如果不是针对不同的情况,则可能会实现。 关于StringBuilder的上一部分在这里 。
在这里,我们来看一些由于对语言规范的精妙之处,不明显的极端情况和其他原因缺乏理解而被拒绝的“改进”。 走吧
当没有预兆的时候
我认为我们每个人都使用了Collections.emptySet() / Collections.emptyList() 。 这些非常有用的方法使您无需创建新对象即可返回空的不可变集合。 在EmptyList类中EmptyList我们将看到以下内容:
private static class EmptyList<E> { public Iterator<E> iterator() { return emptyIterator(); } public Object[] toArray() { return new Object[0]; } }
看到强大的改进潜力吗? EmptyList.iterator()方法从存在时返回一个空的迭代器,为什么不对toArray()方法返回的数组进行相同的EmptyList.iterator()呢?
换句话说,该方法应始终返回一个新数组。
您会说:“他是一成不变的!怎么可能出问题了??”
只有经验丰富的专家才能回答以下问题:
-谁负责?
-负责专家Paul Sandoz和Tagir Valeev
这句话可能会使您感到困惑:
例如 有人可能会对toArray调用返回的数组对象进行同步,因此此更改可能会导致不必要的锁共享。
您会说:“谁将在他们的正确思维中同步数组(!)从集合中返回(!!!)!!”
听起来不太可信,但是这种语言提供了这样的机会,这意味着某个用户有可能这样做(甚至已经做到了)。 然后,建议的更改最多将更改代码的行为,而最坏的情况将导致同步崩溃(以后再捕获)。 风险是如此不合理,预期收益是如此微不足道,以至于最好还是保留一切。
通常,对任何对象kmk进行同步的能力是语言开发人员的错误。 首先,每个对象的标头都包含负责同步的结构,其次,我们发现自己处于上述情况,因为看似不可变的对象可以在其上同步,因此无法多次返回。
这个寓言的寓意是:规范和向后兼容性是Java的神圣代表。 甚至不要试图侵犯他们:警卫在没有警告的情况下开枪射击。
尝试,尝试...
JDK中一次有几个基于数组的类,它们全部实现List.indexOf()和List.lastIndexOf() :
- java.util.ArrayList
- java.util.Arrays $ ArrayList
- java.util.Vector
- java.util.concurrent.CopyOnWriteArrayList
这些类中这些方法的代码几乎一对一重复。 许多应用程序和框架还提供针对相同问题的解决方案:
结果,我们需要编译一些杂散的代码(有时有时需要几次),这些代码发生在ReserverCodeCache中,需要对其进行测试,并且在各个类之间徘徊几乎没有任何变化。
反过来,开发人员非常喜欢编写类似
int i = Arrays.asList(array).indexOf(obj);
我想在JDK中引入通用实用程序方法,并根据建议在各处使用它们。 补丁仅需两个便士:
1) List.indexOf()和List.lastIndexOf()移至java.util.Arrays
2)相反,分别调用Arrays.indexOf()和Arrays.lastIndexOf()
看来可能出什么问题了? 这种方法的好处显而易见。 但是本文是关于失败的,所以请考虑可能出了什么问题。
-谁负责?
-负责专家Martin Buchholz和Paul Sandoz
恕我直言,有点绷紧,但是马丁·布赫霍尔兹(Martin Buchholz):
Sergey,我正在维护所有这些收集类,有时我还想在Array.java中使用indexOf方法。 但是:
通常不建议使用数组。 数组上的任何新静态方法(或者,在我实际需要它们的地方,数组对象本身!需要更改Java语言!)都会遇到阻力。
我们很遗憾在集合中支持空值,因此较新的集合类(如ArrayDeque)不支持它们。
用户可能想要的另一个变体是要使用哪种相等比较。
我们感到遗憾的是,ArrayList具有从零开始的索引。从第一天开始,最好具有ArrayDeque的循环数组行为。
搜索数组切片的代码非常小,因此您不会节省太多。 容易出错,这很容易,但是对于Arrays API也是如此。
保罗·桑多兹(Paul Sandoz):
我不会说不鼓励使用数组,我会积极地将其旋转为“谨慎使用”,因为它们比较刺眼,例如总是可变的。它们肯定会得到改进。我很高兴看到数组实现了一个通用数组在“ ish”界面上,价值类型沉淀后,我们也许可以取得一些进展。
但是,至少对我来说,对Arrays的任何新添加都会遇到一定的阻力:-)它永远不会只添加一种或两种方法,许多其他方法也需要使用(所有原语和范围变体)。 因此,任何新功能都必须具有足够的优势,在这种情况下,我认为优势不足(例如可能减少代码缓存压力)。
保罗
对应: http : //mail.openjdk.java.net/pipermail/core-libs-dev/2018-March/051968.html
这个寓言的寓意是这样的:仅仅因为他们看不到任何特殊的价值,就可以宰杀您的巧妙补丁以进行审查。 好吧,是的,有重复的代码,但是它不会打扰任何人,所以让它活下去。
ArrayList的改进? 我有他们
助力车 该补丁不是我的,我将其发布,供您思考。 提案本身已在这里表达出来,并且看起来非常有吸引力。 自己看看:
用肉眼看,这个提议是非常非常合乎逻辑的。 您可以使用简单的基准来衡量性能:
@State(Scope.Benchmark) public class ArrayListBenchmark { @State(Scope.Benchmark) public static class Data { @Param({"10", "100", "1000", "10000"}) public int size; ArrayList<Integer> arrayRandom = new ArrayList<Integer>(size); @Setup(Level.Invocation) public void initArrayList() { Random rand = new Random(); rand.setSeed(System.currentTimeMillis());
总结:
Benchmark (size) Mode Cnt Score Error Units construct_new_array_list 10 thrpt 25 388.212 ± 23.110 ops/s construct_new_array_list 100 thrpt 25 90.208 ± 7.995 ops/s construct_new_array_list 1000 thrpt 25 23.289 ± 1.687 ops/s construct_new_array_list 10000 thrpt 25 7.659 ± 0.560 ops/s construct_new_array_list 10 thrpt 25 562.678 ± 37.370 ops/s construct_new_array_list 100 thrpt 25 119.791 ± 13.232 ops/s construct_new_array_list 1000 thrpt 25 33.811 ± 3.812 ops/s construct_new_array_list 10000 thrpt 25 10.889 ± 0.564 ops/s
如此简单的更改一点也不差。 最主要的是,似乎没有收获。 诚实地创建一个数组,诚实地复制数据,不要忘记大小。 现在,他们一定要接受补丁!
没有什么可以禁止我从ArrayList取消关联并将数据存储在链接列表中的。 然后, c instanceof ArrayList将返回真相,我们将到达复制区域并安全下落。
这个寓言的寓意是:行为的可能改变可能是失败的原因。 换句话说,如果语言手段允许的话,即使是最荒谬的变化,也必须牢记。 是的,如果ArrayList从一开始就声明为final ,则可以解决问题。
再次规格
在调试我的应用程序时,我不小心陷入了Spring的胆量,发现以下代码 :
幸运的是,通过进入java.lang.reflect.Constructor.getParameterTypes()我将代码向下滚动一点,找到了一个漂亮的代码:
@Override public Class<?>[] getParameterTypes() { return parameterTypes.clone(); } public int getParameterCount() { return parameterTypes.length; }
你看,是吗? 如果我们需要找出构造函数/方法参数的数量,则只需调用java.lang.reflect.Method.getParameterCount() ,而无需复制数组。 在最简单的情况下(该方法没有参数),检查游戏是否值得尝试:
@State(Scope.Thread) @BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) public class MethodToStringBenchmark { private Method method; @Setup public void setup() throws Exception { method = getClass().getMethod("toString"); } @Benchmark public int getParameterCount() { return method.getParameterCount(); } @Benchmark public int getParameterTypes() { return method.getParameterTypes().length; } }
在我的机器上以及JDK 11上,结果如下:
Benchmark Mode Cnt Score Error Units getParameterCount avgt 25 2,528 ± 0,085 ns/op getParameterCount:·gc.alloc.rate avgt 25 ≈ 10⁻⁴ MB/sec getParameterCount:·gc.alloc.rate.norm avgt 25 ≈ 10⁻⁷ B/op getParameterCount:·gc.count avgt 25 ≈ 0 counts getParameterTypes avgt 25 7,299 ± 0,410 ns/op getParameterTypes:·gc.alloc.rate avgt 25 1999,454 ± 89,929 MB/sec getParameterTypes:·gc.alloc.rate.norm avgt 25 16,000 ± 0,001 B/op getParameterTypes:·gc.churn.G1_Eden_Space avgt 25 2003,360 ± 91,537 MB/sec getParameterTypes:·gc.churn.G1_Eden_Space.norm avgt 25 16,030 ± 0,045 B/op getParameterTypes:·gc.churn.G1_Old_Gen avgt 25 0,004 ± 0,001 MB/sec getParameterTypes:·gc.churn.G1_Old_Gen.norm avgt 25 ≈ 10⁻⁵ B/op getParameterTypes:·gc.count avgt 25 2380,000 counts getParameterTypes:·gc.time avgt 25 1325,000 ms
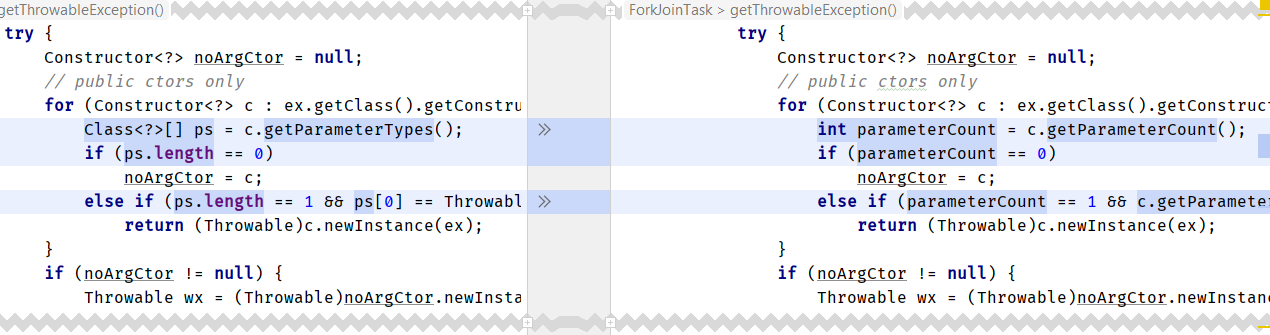
我们该怎么办? 我们可以在JDK中搜索反模式Method.getParameterTypes().length (至少在java.base ),并在有意义的地方将其替换:
java.lang.invoke.MethodHandleProxies
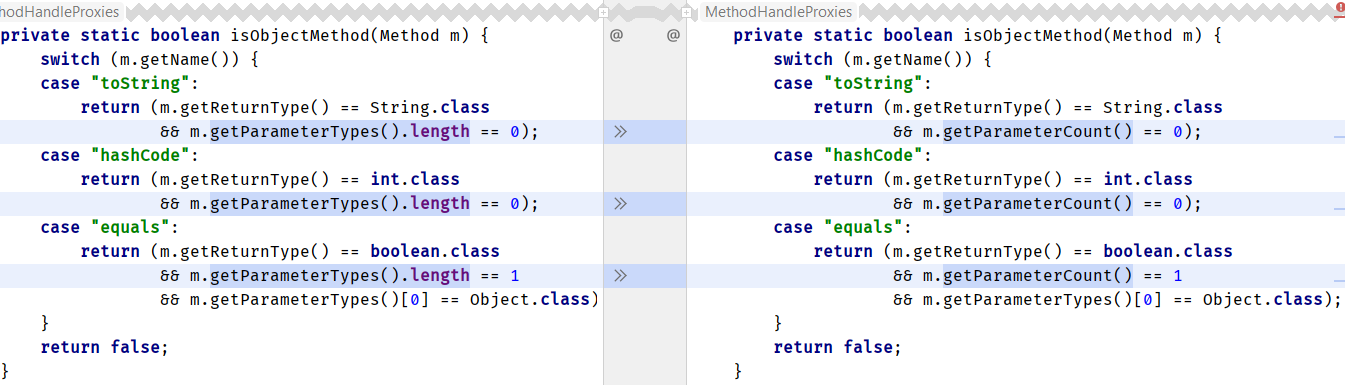
java.util.concurrent.ForkJoinTask
java.lang.reflect.Executable

sun.reflect.annotation.AnnotationType

补丁和求职信一起发送。
突然之间,事实证明,几年来一直存在类似的任务,甚至为此也作了准备。 评论指出,通过这种简单的更改,性能有了相当不错的提高。 但是,到目前为止,它们和我的贴片都已被清洁并且静止不动。 怎么了 可能是因为开发人员忙于处理更多必要的事情,而他们却愚蠢地没有去做。
这个寓言的寓意是这样的:仅仅由于缺乏工人,您的巧妙改变就会冻结。
但这还没有结束! 在讨论其他项目中所述替换的合理性时,更有经验的同志提出了一个反建议:也许您不应该Method.getParameterTypes().length -> Method.getParameterCount()替换Method.getParameterTypes().length -> Method.getParameterCount() ,而是将其委托给编译器? 这可能吗,并且会“合法”吗?
让我们尝试使用测试进行检查:
@Test void arrayClone() { final Object[] objects = new Object[3]; objects[0] = "azaza"; objects[1] = 365; objects[2] = 9876L; final Object[] clone = objects.clone(); assertEquals(objects.length, clone.length); assertSame(objects[0], clone[0]); assertSame(objects[1], clone[1]); assertSame(objects[2], clone[2]); }
这将通过,并且表明如果克隆的数组没有离开范围,则可以删除它,因为可以从原始单元中访问其单元格或length字段中的任何元素。
JDK可以这样做吗? 我们检查:
@State(Scope.Thread) @BenchmarkMode(Mode.AverageTime) @OutputTimeUnit(TimeUnit.NANOSECONDS) public class ArrayAllocationEliminationBenchmark { private int length = 10; @Benchmark public int baseline() { return new int[length].length; } @Benchmark public int baselineClone() { return new int[length].clone().length; } }
JDK 13的输出:
Benchmark Mode Cnt Score Error Units baseline avgt 50 6,135 ± 0,140 ns/op baseline:·gc.alloc.rate.norm avgt 50 56,000 ± 0,001 B/op clone avgt 50 18,359 ± 0,619 ns/op clone:·gc.alloc.rate.norm avgt 50 112,000 ± 0,001 B/op
事实证明,与Grail不同,openjdk不知道如何抛出new int[length] ,呵呵:
Benchmark Mode Cnt Score Error Units baseline avgt 25 2,470 ± 0,156 ns/op baseline:·gc.alloc.rate.norm avgt 25 0,005 ± 0,008 B/op lone avgt 25 13,086 ± 1,059 ns/op lone:·gc.alloc.rate.norm avgt 25 112,113 ± 0,115 B/op
事实证明,您可以对openjdk优化编译器进行一些调整,使其可以完成Grail可以执行的操作。 由于不仅每个人都可以在VM代码中打入正面广告并提交有意义的内容,所以我将自己限于一封陈述我的观点的信中。
事实证明,其中有一些微妙之处。 弗拉基米尔·伊万诺夫表示 :
考虑到没有办法增加/缩小Java数组,
“ cloned_array.length => original_array.length”转换正确
不管克隆的变种是否逃脱。
而且,转换已经存在:
http://hg.openjdk.java.net/jdk/jdk/file/tip/src/hotspot/share/opto/memnode.cpp#l2388
我没有研究您提到的基准,但是看起来
cloned_array.length访问不是克隆数组仍然存在的原因
在那里。
关于您的其他想法,请将访问从克隆实例重定向到
由于编译器必须证明原始数据是有问题的(通常情况下)
两个版本都没有变化,索引访问甚至使
更难。 安全点也会引起问题(用于重新实现)。
但是我同意覆盖(至少)一些简单的案例会很好
防御性复制。
也就是说,敲打一个克隆似乎是可能的,而且并不是特别困难。 但是随着转换
int len = new int[arrayLength].length;
->
int len = arrayLength;
出现困难 :
我们不会消除长度未知的数组分配
因为它们可能会导致NegativeArraySize异常。 在这种情况下,我们
应该能够证明长度为正。
无论如何-我的补丁即将完成,可以替换未使用的阵列
在适当的保护下进行分配。
换句话说,您不能只是取消并丢弃数组的创建,因为根据规范,执行必须抛出NegativeArraySizeException而我们对此无能为力:
@Test void arrayWithNwgativeSize() { int length = 0; try { int newLen = -3; length = new Object[newLen].length;
为什么圣杯能干? 我认为原因是上述基准中的length字段的值恒定且始终等于10,这使探查器得出结论认为不需要检查负值,这意味着可以在创建数组本身的同时将其删除。 如果我输入有误,请在评论中更正。
今天就这些了:)我们将理解在注释中添加您的示例。