让我们创建一个原型强化学习代理(RL),它将掌握交易技巧。
鉴于原型实现使用R语言工作,我鼓励R用户和程序员接近本文中提出的想法。
这是我英语文章的翻译:
强化学习可以交易吗? 在R中执行。我想警告代码猎人,在本说明中,只有适用于R的神经网络代码。如果我的俄语水平不佳,请指出错误(文本是在自动翻译的帮助下编写的)。
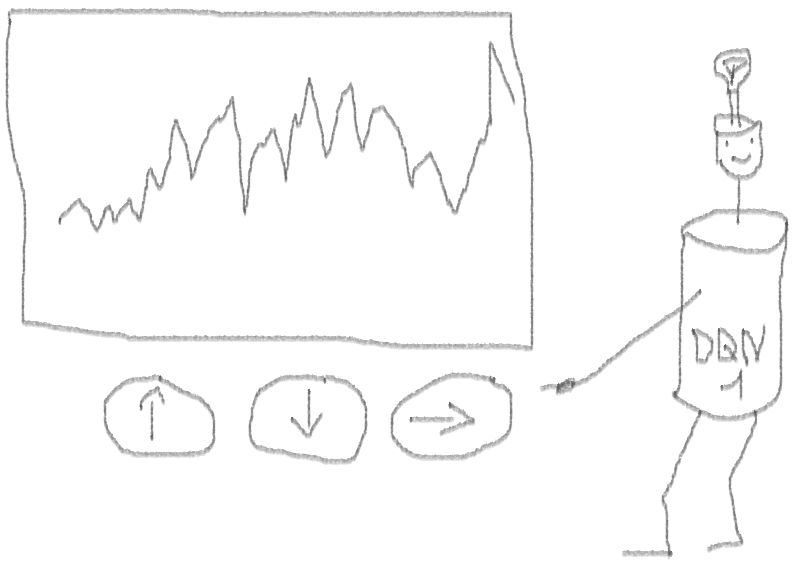
问题介绍
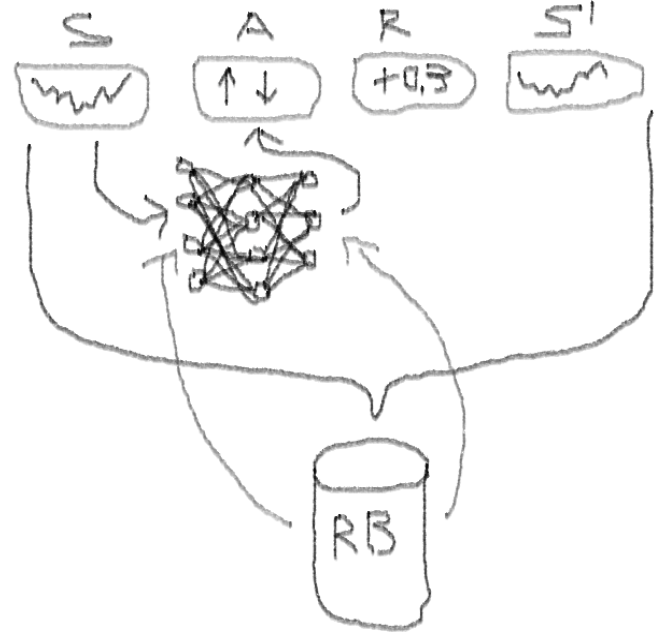
我建议您通过本文开始深入探讨该主题:
DeepMind她将向您介绍使用深度Q网络(DQN)近似值对马尔可夫决策过程至关重要的价值函数的想法。
我还建议您使用Richard S. Sutton和Andrew J. Barto的本书预印本深入研究数学:
强化学习下面,我将介绍原始DQN的扩展版本,其中包括更多有助于算法快速有效收敛的想法,即:
从体验播放缓冲区中选择优先级的“
深双决斗”噪声神经网络 。
是什么让这种方法比传统的DQN更好?
- 双重:有两个网络,其中一个受过训练,另一个评估以下Q值
- 决斗:有些神经元具有明显的价值和益处
- 嘈杂:中间层的权重上应用了噪声矩阵,其中均值和标准差是经过训练的权重
- 采样优先级:回放缓冲区中的观察批包含示例,由于这些示例先前的功能训练会导致大量残留,可以将其存储在辅助阵列中。
那么,DQN代理商进行的交易又如何呢? 因此,这是一个有趣的话题。
有一些有趣的原因:
- 选择状态,动作,奖项和NN架构表示的绝对自由。 您可以使用从新闻到其他股票和指数的所有值得尝试的内容来丰富进入空间。
- 交易逻辑与强化学习逻辑的对应关系是:代理执行离散的(或连续的)动作,很少得到奖励(在交易结束或期限到期后),环境可以部分观察到并且可能包含有关后续步骤的信息,交易是一种情景游戏。
- 您可以将DQN结果与几个基准进行比较,例如指数和技术交易系统。
- 代理可以不断学习新信息,从而适应不断变化的游戏规则。
为了不扩展内容,请看一下我想分享的NN代码,因为这是整个项目中神秘的部分之一。
使用Keras构建我们的RL代理的价值神经网络的R代码
我使用此源代码将Python代码改编为网络的噪声部分:
github repo这个神经网络看起来像这样:
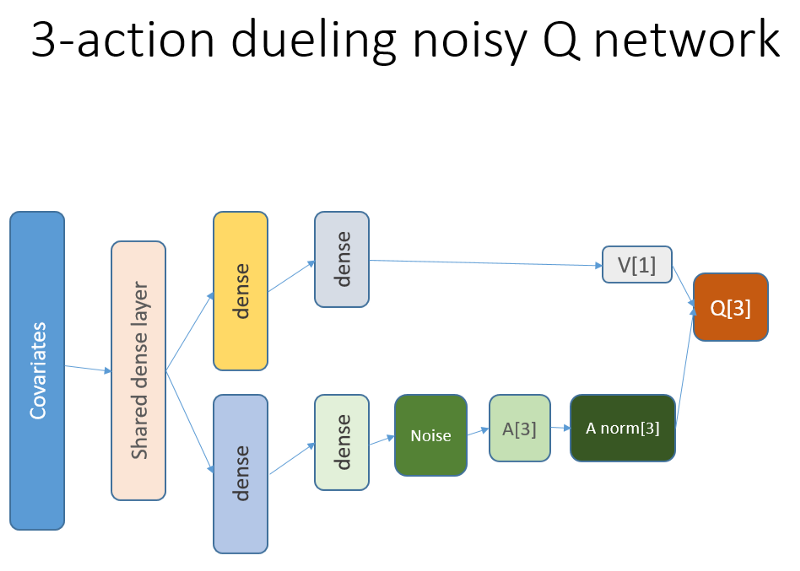
回想一下在决斗架构中,我们使用等式(等式1):
Q = A'+ V,其中
A'= A-平均(A);
Q =国家行动的价值;
V =状态值;
A =优势。
代码中的其他变量说明了一切。 此外,此体系结构仅适合于特定任务,因此不要认为它是理所当然的。
其余代码很可能具有足够的通用性以供发布,并且程序员自己编写它会很有趣。
现在-实验。 对代理商工作的测试是在沙盒中进行的,与实际经纪人进行交易的真实市场相去甚远。
第一阶段
我们针对合成数据集运行代理。 我们的交易成本为0.5:
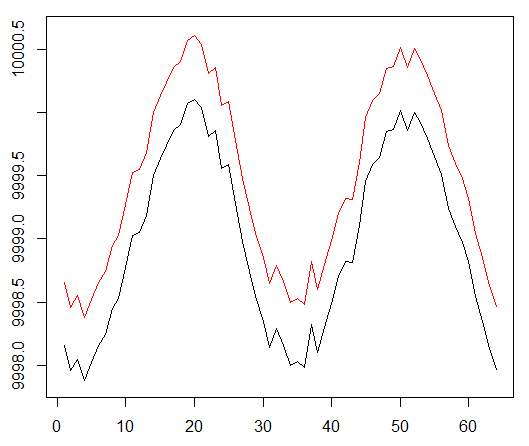
结果是极好的。 此实验中的最大平均情节奖励
应该是1.5。
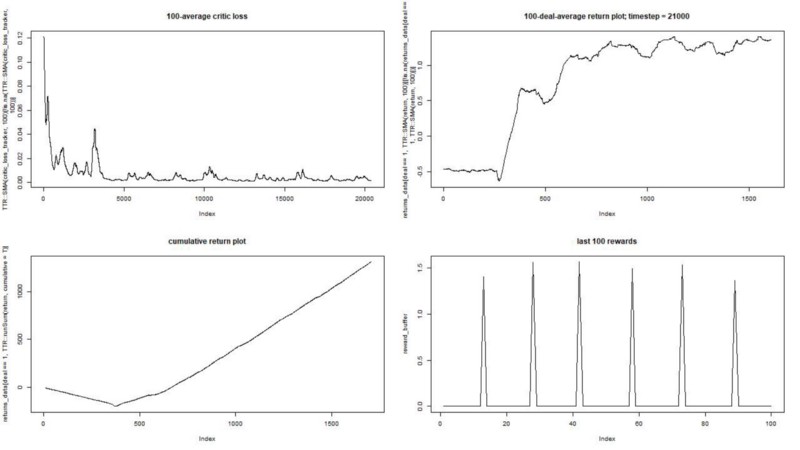
我们看到:批评的丧失(演员批评方法中的所谓价值网络),一集的平均奖励,累积的奖励,最近的奖励样本。
第二阶段
我们教给我们的经纪人一个任意选择的股票符号,该符号表现出有趣的行为:平稳的开始,中间的快速增长和沉闷的结尾。 在我们的培训工具包中,大约需要4300天。 交易成本设置为0.1美元(故意降低); 奖励是在完成买卖1.0股交易后的美元盈亏。
资料来源:
finance.yahoo.com/quote/algn?ltr=1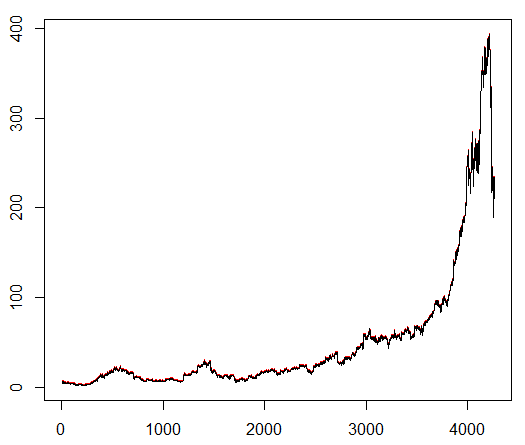 纳斯达克:ALGN
纳斯达克:ALGN设置一些参数后(使NN体系结构保持不变),我们得出以下结果:

事实证明还不错,因为最终代理商通过按控制台上的三个按钮来获利。
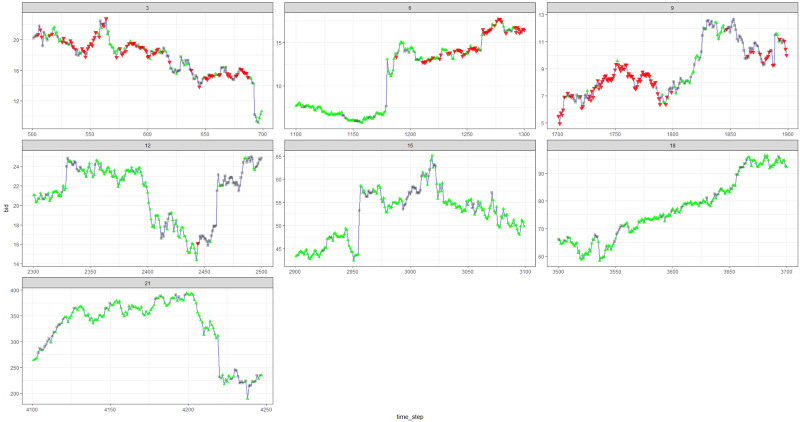 红色标记=卖出,绿色标记=买入,灰色标记=不执行任何操作。
红色标记=卖出,绿色标记=买入,灰色标记=不执行任何操作。请注意,在最高峰时,每集的平均奖励超过了在真实交易中可能遇到的实际交易价值。
可惜的是,由于坏消息,股市疯狂下跌。
结论性意见
用RL交易不仅困难,而且很有用。 当您的机器人比您做得更好时,就该花费您的个人时间来接受教育和健康。
我希望这对您来说是一次有趣的旅程。 如果您喜欢这个故事,请挥手。 如果有很多兴趣,我可以继续向您展示使用R语言和Keras API的策略渐变方法如何工作。
我还要感谢对神经网络感兴趣的朋友的建议。
如果您还有问题,我会一直在这里。