最近,网络开发已经分裂。 现在我们还不是全栈程序员,而是前端和后端。 和其他地方一样,与此有关的最困难的事情是交互和集成的问题。
前端与后端通过API进行交互。 整个开发结果取决于它是什么API,后端和前端之间相互认可的好坏。 如果我们所有人都开始一起讨论如何进行升级,并花费一整天的时间对其进行重新修改,那么我们可能就无法完成业务任务。
为了不让变量名泛滥,您需要一个良好的规范。 让我们谈谈使每个人的生活更轻松应该是什么样子。 同时,我们将成为自行车棚的专家。

让我们从远处开始-解决我们要解决的问题。
很久以前,在1959年,
西里尔·帕金森 (
Cyril Parkinson )提出了一些有趣的法则(不要与这种疾病相混淆,他是作家和经济人物)。 例如,费用随收入增长而增长,等等。 其中之一称为平凡定律:
讨论该项目所花费的时间与所考虑的数量成反比。
帕金森是一位经济学家,所以他用经济术语解释了他的定律。 如果您来董事会并说您需要一千万美元来建造一座核电站,那么讨论此问题的可能性极有可能远低于为员工的自行车棚分配100磅的成本。 因为每个人都知道如何建造自行车棚,每个人都有自己的见解,每个人都感到重要并希望参与,而核电站又是一个抽象而遥远的事物,从未见过的一千万座核电站-问题更少。
1999年,帕金森的平凡定律出现在程序设计中,然后得到了积极发展。 在编程中,该法则主要出现在英语文学中,听起来像是一个隐喻。 它被称为
“自行车棚效应” (
Bikeshed effect) (自行车棚的效果),但本质是相同的-我们已经准备好自行车棚,并且希望讨论的时间比电厂的建设更长。
这个术语是由参与开发FreeBSD的丹麦开发人员Poul-Henning Kamp创造的。 在设计过程中,团队花费了很长时间讨论睡眠功能应如何工作。 这是Poul-Henning Kamp的
一封信的引言(随后通过电子邮件通讯进行了开发):
这是一个建议入睡的建议(1)DTRT如果给出一个非整数的参数来设置这种特殊的草火,那么我将不多说,因为它是一个比一个小得多的项目。期望从线程的长度开始,它已经比我们在这里遇到的一些问题更加受到关注。
他在这封信中说,还有很多更重要的未解决的问题:“我们不要处理自行车棚,我们将为此做些事情然后继续前进!”
因此,Poul-Henning Kamp于1999年将术语“自行车棚效应”引入英语文学中,其表述如下:
代码更改所产生的噪声量与更改的复杂程度成反比。
我们进行的添加或更改越简单,就需要听到更多的意见。 我想很多人都遇到了这个。 如果我们解决了一个简单的问题(例如,如何命名变量),那么对于计算机而言就无关紧要-这个问题将引起大量的抱怨。 但是没有讨论严重的,对业务问题非常重要的问题,这些问题在后台进行了讨论。
您认为更重要的是:我们如何在后端和前端之间进行通信,或者在业务任务中进行沟通? 每个人的想法都不同,但是任何客户(希望您为他带来钱的人)都会说:“已经把我的业务任务做好了!” 他绝对不在乎如何在后端和前端之间传输数据。 也许他甚至不知道后端和前端是什么。
总而言之,我想说:
API是一个自行车棚。简报 连结关于发言人: Alexey Avdeev(
Avdeev )在Neuron.Digital公司工作,该公司处理神经元并为神经元做一个很好的前端。 Alex还关注OpenSource,并为所有人提供建议。 他从事开发工作已经很长时间了-自2002年以来,他发现了古老的Internet,当时计算机规模很大,Internet规模很小,而且缺少JS并没有困扰任何人,每个人都在桌子上构成站点。
如何处理自行车棚?
在备受推崇的西里尔·帕金森(Cyril Parkinson)推论平凡律之后,他受到了广泛讨论。 事实证明,这里的自行车棚效果很容易避免:
- 不要听意见。 我认为这个想法很一般-如果您不听提示,那么您可以做这样的事情,尤其是在编程方面,尤其是如果您是新手开发人员。
- 做你想做的。 “我是一名艺术家,我明白了!” -没有效果,您所需的一切都已完成,但输出中会出现非常奇怪的事情。 这通常是在自由职业者中发现的。 当然,您遇到了必须为其他开发人员完成的任务,而这些任务的实施使您感到困惑。
- 问自己重要吗? 如果没有,您根本无法讨论,但这是个人意识的问题。
- 使用客观标准。 我将在报告中谈到这一点。 为了避免自行车棚的影响,您可以使用客观地说出哪个更好的标准。 它们存在。
- 不要谈论您不想听的建议。 在我们公司中,刚开始的后端开发人员是性格内向的人,因此碰巧他们做了一些自己没有告诉别人的事情。 结果,我们遇到了惊喜。 此方法有效,但在编程中不是最佳选择。
- 如果您不关心这个问题,则可以放任不管,也可以选择 holivarov过程中出现的任何建议选项 。
防脱落工具
我想谈谈解决自行车棚问题的
客观工具 。 为了说明什么是防自行车撞工具,我将向您介绍一个小故事。
想象一下,我们有一个新手后端开发人员。 他最近来了公司,并被指示设计一个小型服务,例如博客,您需要为此服务编写REST协议。
 Roy Fielding,REST的作者
Roy Fielding,REST的作者在照片中,罗伊·菲尔丁(Roy Fielding)在2000年为他的论文“网络风格和网络软件体系结构的设计”辩护,因此引入了REST一词。 而且,他发明了HTTP,实际上是Internet的创始人之一。
REST是一组体系结构原理,这些原理说明了如何设计REST协议,REST API,RESTful服务。 这些是非常抽象和复杂的架构原则。 我敢肯定,您从未见过完全按照所有RESTful原理制作的API。
REST架构要求
我将对
REST协议提出一些要求,然后再参考并依靠它们。 其中有很多,您可以在Wikipedia上了解更多信息。
1.
客户端-服务器模型。REST的最重要原理,即我们与后端的交互。 根据REST的说法,后端是服务器,前端是客户端,我们以客户端-服务器格式进行通信。 移动设备也是客户端。 手表,冰箱和其他服务的开发人员也开发了客户端部分。 RESTful API是客户端访问的服务器。
2.
缺乏条件。服务器上必须没有状态,也就是说,答案所需的所有内容都在请求中。 当会话存储在服务器上时,根据此会话,会有不同的答案,这违反了REST原理。
3.
接口的统一性。这是构建REST API的关键基础原则之一。 它包括以下内容:
- 资源标识是我们应该如何构建URL。 在REST上,我们转向服务器获取某种资源。
- 通过演示来操纵资源。 服务器返回给我们的视图与数据库中的视图不同。 将信息存储在MySQL还是PostgreSQL中都没有关系-我们有一个视图。
- 自描述消息(即,消息包含id,可在其中再次获得此消息的链接)-再次使用此资源所需的全部。
- 超媒体是使用资源的以下操作的链接。 在我看来,并不是只有一个REST API可以做到这一点,但是Roy Fielding对此进行了描述。
我没有再引用3条原则,因为它们对我的故事并不重要。
RESTful博客
回到最初的后端开发人员,他被要求在RESTful上为博客提供服务。 以下是原型的示例。
这个网站上有文章,您可以对其发表评论,文章和评论都有作者-标准故事。 我们的新手后端开发人员将为此博客做一个RESTful API。
我们基于
CRUD处理所有博客数据。
应该可以创建,读取,更新和删除任何资源。 让我们尝试请后端开发人员根据CRUD原理构建RESTful AP。 也就是说,编写用于创建文章,获取文章列表或单个文章,进行更新和删除的方法。
让我们看看他怎么做。
 关于REST的所有原理,这里一切都是错误的
关于REST的所有原理,这里一切都是错误的 。 最有趣的是它可以工作。 我实际上得到了看起来像这样的API。 对于客户而言,这是一个自行车棚,对于开发商而言,这是一个让他们冷静和争论的时机,对于新手开发商而言,这只是一个巨大而勇敢的新世界,他每次跌倒,摔倒,砸头都将跌倒。 他必须一遍又一遍地重做。

这是一个REST选项。 基于识别资源的原则,我们使用资源-使用文章,并使用Roy Fielding提出的HTTP方法。 他不禁在下一个工作中使用以前的工作。
要更新文章,许多人使用PUT方法;它的语义略有不同。 PATCH方法更新传递的字段,而PUT只是将一篇文章替换为另一篇文章。 从语义上讲,PATCH是合并的,而PUT是替换的。
我们的新手后端开发人员崩溃了,他们把它捡起来说:“一切都井井有条,那样做。”然后,他诚实地重做了。 但随后他将发现荆棘丛生的巨大路途。
为什么这么对?- 因为罗伊·菲尔丁(Roy Fielding)这么说;
- 因为它是REST;
- 因为这些是我们专业现在所基于的建筑原则。
但是,这是一个“自行车棚”,以前的方法将起作用。 计算机在REST之前进行了通信,并且一切正常。 但是现在行业中已经出现了标准。
删除文章
考虑删除文章的示例。 假设有一个普通的资源方法DELETE / article,它通过id删除了该文章。 HTTP包含标头。 Accept标头接受客户端希望作为响应接收的数据类型。 我们的初级员工编写了一个服务器,该服务器返回200 OK,内容类型:application / json,并传递一个空主体:
01. DELETE /articles/ 1 /1.1
02. Accept: application/json01. HTTP/1.1 200 OK
02. Content-Type: application/json
03. null
这里犯了一个非常
普遍的错误-空着的身体 。 一切似乎合乎逻辑-文章已被删除,200 OK,存在application / json标头,但客户端很可能会掉下来。 由于空的主体无效,因此将引发错误。 如果您曾经尝试解析一个空字符串,那么您将面临这样一个事实,即任何json解析器都会遇到这种情况并崩溃。
如何解决这种情况? 最好的选择可能是传递json。 如果我们说:“接受,给我们json”,服务器会说:“内容类型,我给您json”,给json。 一个空的对象,一个空的数组-在其中放置一些东西-这将是解决方案,并且它将起作用。
仍然有解决方案。 除了200 OK,还有一个响应代码204-无内容。 有了它,您就无法传播身体。 并非所有人都知道这一点。
因此,我介绍了媒体类型。
哑剧类型
媒体类型就像文件扩展名,仅在网络上。 当我们传输数据时,我们必须告知或请求我们希望接收哪种类型作为响应。
- 默认情况下,这是文本/纯文本-仅文本。
- 如果未指定任何内容,则浏览器很可能表示应用程序/八位位组流-只是位流。
您可以仅指定特定类型:
- 申请书/ pdf;
- 图片/ png;
- 应用程序/ json;
- 应用程序/ xml;
- 应用程序/ vnd.ms-excel。
Content-Type和Accept标头非常重要。
API和客户端必须传递Content-Type和Accept标头。
如果您的API是基于JSON构建的,请始终传递Accept:application / json和Content-Type application / json。
示例文件类型。

媒体类型仅在Internet上类似于这些文件类型。
答案码
下一个开发人员冒险的下一个示例是响应代码。

最有趣的响应速度是200 OK。 每个人都爱他-这意味着一切都顺利。 我什至有一个案例-我收到
错误200 OK 。 服务器上实际上掉了一些东西,作为对响应的响应,出现了一个HTML页面,在该页面上已编译HTML错误。 我要求使用代码200 OK的应用程序json,并认为如何使用它? 您通过回应去寻找“错误”一词,您认为这是一个错误。
此方法有效,但是,在HTTP中,您可以使用许多其他代码,并且REST建议您在REST上使用它们。 例如,可以回答一个实体(文章)的创建:
- 201 Created是成功的代码。 文章已创建,作为回应,您需要返回创建的文章。
- 202 Accepted表示请求已被接受,但结果将稍后。 这些是长期运行的操作。 接受后,将无法返回任何正文。 也就是说,如果您未在响应中提供Content-Type,则正文也可能不会。 还是Content-Type文字/平面-仅此而已,没问题。 空字符串是有效的文本/平面。
- 204无内容 -身体可能完全不存在。
- 403 Forbidden-不允许您创建此文章。
- 找不到404-您爬错了地方,例如,没有这种方法。
- 409冲突是很少有人使用的极端情况。 如果您是在客户端(而不是后端)上生成ID,并且有时有人已经设法创建本文,则有时需要使用该ID。 在这种情况下,冲突是正确的答案。
实体创作
下面的示例:我们创建一个实体,例如Content-Type:application / json,并传递此application / json。 这使客户-我们的前端。 让我们来创建这篇文章:
01. POST /articles /1.1
02. Content-Type: application/json
03. { "id": 1, "title": " JSON API"}该代码可能会作为响应:
- 422无法处理的实体-未处理的实体。 一切似乎都很棒-语义,有代码;
- 403禁止
- 500内部服务器错误。
但这是完全无法理解的,到底发生了什么:没有处理哪种实体,为什么我不应该去那里,服务器到底发生了什么?
返回错误
确保(并且初级人员对此一无所知)作为响应,返回错误。 这是语义上正确的。 顺便说一句,菲尔丁(Fielding)并未对此进行撰写,也就是说,它是后来发明的,并建立在REST之上。
后端可能会返回一个带有错误的数组,可能有多个。
01. HTTP/1.1 422 Unprocessable Entity
02. Content-Type: application/json
03.
04. { "errors": [{
05. "status": "422",
06. "title": "Title already exist",
07. }]}每个错误可以有其自己的状态和标题。 这很棒,但是已经在REST之上的约定级别上进行了。 这可能是我们的反自行车淘汰工具,可以停止争论并立即制作出正确的API。
添加分页
下面的例子:设计师来到我们最初的后端开发人员那里说:“我们有很多文章,我们需要分页。 我们画了这个。”

让我们更详细地考虑它。 首先,共有336页。 当我看到这个时,我想到了如何获得这个数字。 在哪里获得336,因为当我请求文章列表时,我会获得文章列表。 例如,有1万个,也就是说,我需要下载所有文章,除以页面数,然后找出这个数字。 很长一段时间我将加载这些文章,我需要一种快速获取条目数的方法。 但是,如果我们的API返回一个列表,那么通常会将此数量的记录放在何处,因为会响应一系列文章。 事实证明,由于记录数没有放在任何地方,因此必须将其添加到每篇文章中,以便每篇文章都说:“而且我们所有人都有很多!”
但是,在REST API之上有一个约定可以解决此问题。
清单要求
为了使该API具有可扩展性,您可以立即使用GET参数进行分页:当前页面的大小及其编号,以便将我们请求的页面恰好返回给我们。 这很方便。 作为响应,您不能立即提供一个数组,而是添加其他嵌套。 例如,数据键将包含一个数组,我们请求的数据,以及之前不存在的元键将包含总数。
01. GET /articles? page[size]=30&page[number]=2
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
这样,API可以返回其他信息。 除了计数之外,可能还有其他一些信息-它是可扩展的。 现在,如果初级用户没有立即执行此操作,而是仅在要求他
进行 pakinization之后,他才
进行向后不兼容的更改 ,破坏了API,所有客户都必须重做它-通常会很痛苦。
Pajinization不同。 我提供了一些您可以使用的生活技巧。
[偏移] ... [限制]
01. GET /articles? page[offset]=30&page[limit]=30
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
使用数据库的人可能已经具有[offset] ... [limit]子皮层。 使用它代替页面[size] ...页面[number]将更容易。 这是一个稍微不同的方法。
光标定位
01. GET /articles? page[published_at]=1538332156
02. Content-Type: application/json01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }光标位置使用指向开始加载记录的实体的指针。 例如,当您使用分页或加载频繁更改的列表时,这非常方便。 假设新文章不断在我们的博客上撰写。 现在,第三页与将要在一分钟内的第三页不同,但是如果转到第四页,则会从第三页上获得一些记录,因为整个列表都会移动。
通过游标分页解决了此问题。 我们说:“加载当时发表的文章之后的文章”-纯粹从技术上讲不再有任何变化,这很酷。
问题N +1
我们的初级开发人员肯定会遇到的下一个问题是N + 1问题(支持者将理解)。 假设您要列出10条文章的列表。 我们上传文章列表,每篇文章都有一位作者,您需要为每篇文章下载一位作者。 我们运送:
总计:11个查询,显示一个小的列表。
添加链接
在后端,此问题已在所有ORM中解决-您只需要记住要添加此连接即可。 这些连接也可以在前端使用。 这样做如下:
01. GET /articles? include =author
02. Content-Type: application/json
您可以使用特殊的GET参数,将其称为include(在后端),说明我们需要随文章一起加载的链接。 假设我们上载了文章,并且我们想立即让作者和文章一起。 答案看起来像这样:
01. /1.1 200
02. { "data": [{
03. { attributes: { "id": 1, "title": "JSON API" },
04. { relationships: {
05. "author": { "id": 1, "name": "Avdeev" } }
06. }, ...
07. }]}自己的商品属性已传输到数据并添加了关键关系。 我们将所有连接都放在此密钥中。 因此,通过一个请求,我们收到了之前收到11个请求的所有数据。 这是一个很酷的生活技巧,很好地解决了前端N + 1的问题。
数据重复问题
假设您要显示10条表明作者的文章,所有文章都有一位作者,但是该作者的对象很大(例如,姓氏很长,需要一个兆字节)。 答案中一位作者被包含10次,答案中同一位作者的10个包含将占用10 MB。
由于所有对象都是相同的,因此借助于数据库中使用的规范化解决了一位作者被包含10次(10 MB)的问题。 在前端,您还可以在使用API时使用规范化-这非常酷。
01. /1.1 200
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": "JSON API" },
05. "relationships": { ... }
06. "author": { "id": 1, "type": "people" } }
07. }, ... ]
08. }我们用某种类型标记所有实体(这是一种表示类型,一种资源类型)。 罗伊·菲尔丁(Roy Fielding)引入了资源的概念,即他们要求提供文章-收到了“文章”。 在关系中,我们将链接指向人的类型,也就是说,我们仍然在其他地方拥有人的资源。 资源本身包含在一个单独的密钥中,该密钥与数据处于同一级别。
01. /1.1 200
02. {
03. "data": [ ... ],
04. "included": [{
05. "id": 1, "type": "people",
06. "attributes": { "name": "Avdeev" }
07. }]
08. }因此,单个实例中的所有相关实体都属于所包含的特殊键。 我们仅存储链接,而实体本身存储在include中。
请求大小减少。 这是一个生活黑客,起始后端并不了解。 他将在以后需要中断API时找到答案。
并非所有资源字段都是必需的
当不需要所有资源字段时,可以应用以下生活技巧。 这是使用特殊的GET参数完成的,该参数列出了要返回的属性,以逗号分隔。 例如,文章很大,并且content字段中可以有兆字节,我们只需要列出标头-我们不需要响应中的内容。
GET /articles ?fields[article]=title /1.101. /1.1 200 OK
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": " JSON API" },
05. }, ... ]
06. }例如,如果您还需要发布日期,则可以用逗号分隔的“发布日期”。 作为响应,属性中将包含两个字段。 这是一个约定,可以用作反骑自行车的工具。
按文章搜索
通常,我们需要搜索和过滤器。 为此有约定-特殊过滤器GET参数:
●
GET /articles ?filters[search]=api HTTP/1.1搜索;
●
GET /articles ?fiIters[from_date]=1538332156 HTTP/1.1从特定日期下载文章;
●
GET /articles ?filters[is_published]=true HTTP/1.1下载刚刚发布的文章;
●
GET /articles ?fiIters[author]=1 HTTP/1.1由第一作者下载文章。
分类文章
●
GET /articles ?sort=title /1.1按标题;
●
GET /articles ?sort=published_at HTTP/1.1发布日期
GET /articles ?sort=published_at HTTP/1.1 -按发布日期
GET /articles ?sort=published_at HTTP/1.1 ;
●
GET /articles ?sort=-published_at HTTP/1.1按相反的发布日期
GET /articles ?sort=-published_at HTTP/1.1 ;
●
GET /articles ?sort=author,-publisbed_at HTTP/1.1如果作者来自同一作者,则首先按作者排列,然后按相反的发布日期排列。
需要更改URL
解决方案:我已经提到过,超媒体可以按以下方式完成。 如果我们希望对象(资源)是自描述的,则客户可以通过超媒体了解可以用它做什么,并且服务器可以独立于客户进行开发,那么我们可以使用特殊的链接键将链接添加到文章列表,或者添加到文章本身。 :
01. GET /articles /1.1
02. {
03. "data": [{
04. ...
05. "links": { "self": "http://localhost/articles/1" },
06. "relationships": { ... }
07. }],
08. "links": { "self": " http://localhost/articles " }
09. }
或相关,如果我们想告诉客户如何上传关于本文的评论:
01. ...
02. "relationships": {
03. "comments": {
04. "links": {
05. "self": "http://localhost/articles/l/relationships/comments ",
06. "related": " http://localhost/articles/l/comments "
07. }
08. }
09. }客户看到有一个链接,跟随它,加载评论。 如果没有链接,则没有评论。 这很方便,但是很少这样做。 Fielding提出了REST的原理,但并非所有原理都进入了我们的行业。 我们主要使用两个或三个。
在2013年,我告诉过您的所有生活黑客,Steve Klabnik都纳入了JSON API规范,并在JSON
之上注册为
新的媒体类型 。 因此,我们的初级后端开发人员逐渐发展为JSON API。
JSON API
所有内容均在
http://jsonapi.org/implementations/上进行了详细描述:甚至还提供了针对32种编程语言的170种不同规范实现的列表-这些仅添加到目录中。 库,解析器,序列化器等已被编写。
由于此规范是开源的,因此每个人都在对其进行投资。 除其他外,我自己写了一些东西。 我肯定有很多这样的人。 您可以自己加入此项目。
JSON API优点
JSON API规范解决了许多问题-
每个人的
共同协议 。 由于已达成普遍协议,因此我们
不会在团队内部争论 -记录自行车棚的情况。 我们在制造自行车棚的材料以及如何上漆方面达成协议。
现在,当开发人员做错事时,我看到了,我不开始讨论,而是说:“不是JSON API!” 并在规范中显示。 他们在公司讨厌我,但逐渐习惯了,每个人都开始喜欢JSON API。 我们根据此规范提供新的默认服务。 我们有一个日期键,我们准备添加元数据,包括键。 有一个用于过滤器的保留GET参数过滤器。 我们不争辩什么叫过滤器-我们使用此规范。 它描述了如何制作一个URL。
由于我们不是在争论而是在做业务任务,因此
开发生产率更高 。 我们已经描述了规范,开发人员阅读了后端,制作了API,然后将其拧紧了-客户很满意。
流行的问题已经解决 ,例如分页。 规范中有很多提示。
由于这是JSON(感谢Douglas Crockford使用这种格式),因此它比XML更简洁,因此非常
容易阅读和理解 。
这是
开放源代码这一事实可以是加号也可以是减号,但是我喜欢开放源代码。
缺点JSON API
对象增长了(日期,属性,包含等)-
前端需要解析答案:能够遍历数组,在对象周围走动并知道reduce如何工作。 并非所有新手开发人员都知道这些复杂的东西。 有序列化器/反序列化器的库,您可以使用它们。 通常,这只是处理数据,但是对象很大。
后端很痛苦:
- 嵌套控制-包含可以爬得很远;
- 数据库查询的复杂性-它们有时是自动构建的,结果非常困难;
- 安全性-您可以爬入丛林,尤其是在连接某种图书馆的情况下;
- 该规范很难阅读。 她是英文的,这使一些人感到恐惧,但后来所有人都习惯了。
- 并非所有的库都很好地实现了规范-这是一个开源问题。
陷阱JSON API
有点硬派。
问题中的关系数量不受限制。 如果我们确实包含,要求文章,向其中添加评论,那么作为回应,我们将收到本文的所有评论。 有10,000条评论-获得所有10,000条评论:
GET /articles/1?include=comments /1.101. ...
02. "relationships": {
03. "comments": {
04. "data": [0 ... ∞]
05. }
06. }因此,实际上有5 MB响应我们的请求:“它写在规范中-必须正确地重新格式化请求:
GET /comments? filters[article]=1& page[size]=30 HTTP/1.101. {
02. "data": [0 ... 29]
03. }我们要求按文章过滤的评论,说:“请30件”,并获得30条评论。 这是模棱两可的。
可以模棱两可 :
●
GET /articles/1 ?include=comments HTTP/1.1请求带注释的文章;
●
GET /articles/1/comments HTTP/1.1请求对文章进行注释;
●
GET /comments ?filters[article]=1 HTTP/1.1请求按文章过滤的注释。
这是一个相同的-相同的数据,以不同的方式获得,存在一些歧义。 这个陷阱不是立即可见的。
一对多多态关系非常迅速地渗透到REST中。
01. GET /comments?include=commentable /1.1
02.
03. ...
04. "relationships": {
05. "commentable" : {
06. "data": { "type": "article", "id": "1″ }
07. }
08. }后端有一个可注释的多态连接-它爬出到REST中。 因此它应该发生,但可以掩饰。 您无法在JSON API中伪装它-它会出来。
具有高级选项的复杂的多对多关系 。 而且,所有连接表都出来了:
01. GET /users?include =users_comments /1.1
02.
03. ...
04. "relationships": {
05. "users_comments": {
06. "data": [{ "type": "users_comments", "id": "1″ }, ...]
07. },
08. }招摇
Swagger是一个在线文档编写工具。
假设我们的后端开发人员被要求为其API编写文档,然后他编写了该文档。 如果API很简单,这很容易。 如果这是JSON API,那么Swagger编写起来就不会那么容易。
示例: Swagger宠物商店。 可以打开每种方法,请参阅响应和示例。
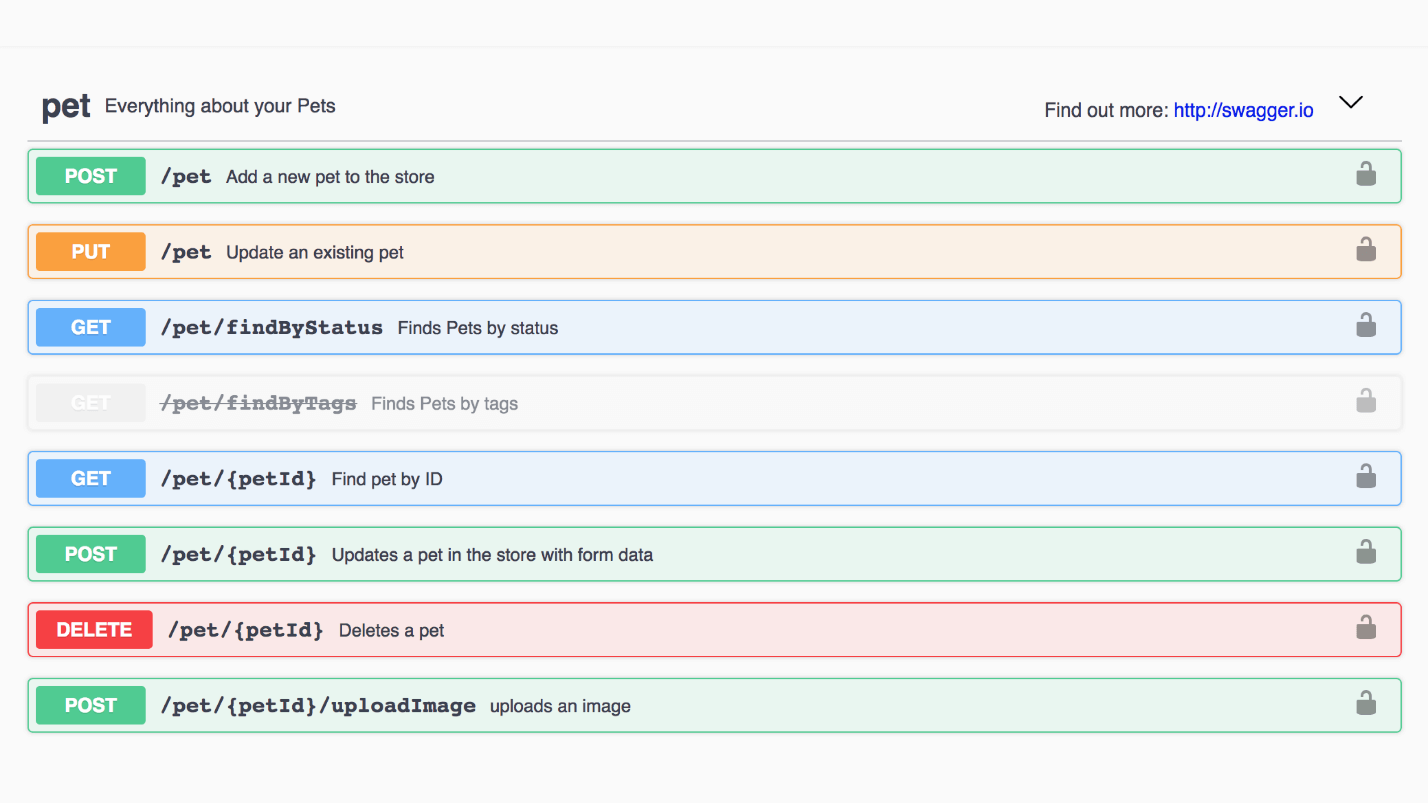
这是一个宠物模型的例子。 这是一个很酷的界面,所有内容都很容易阅读。
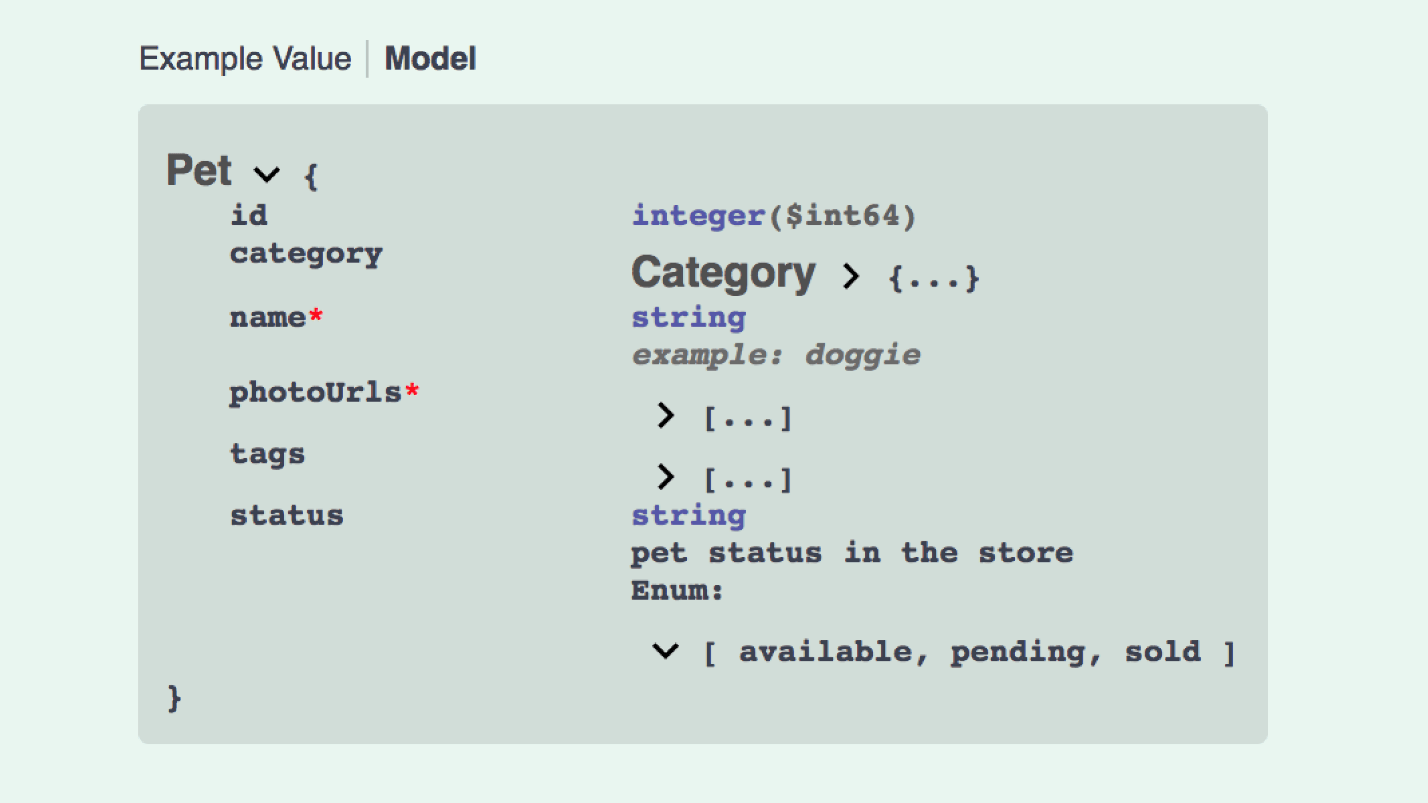
这就是创建JSON API模型的样子:

这不是很好。 我们需要数据,在包含关系的数据中,包含5种类型的模型,等等。 您可以编写Swagger,Open API是功能强大的东西,但是很复杂。
另类
有一个OData规范,该规范于2015年发布。 官方网站保证,这是“ REST的最佳方法”。 看起来像这样:
01. GET http://services.odata.org/v4/TripRW/People HTTP/1.1 -GET请求;
02. OData-Version: 4.0具有版本的特殊头;
03. OData-MaxVersion: 4.0第二个特殊版本标题
答案看起来像这样:
01. HTTP/1.1 200 OK
02. Content-Type: application/json; odata.metadata=minimal
03. OData-Version: 4.0
04. {
05. '@odata.context': 'http://services.odata.org/V4/
06. '@odata.nextLink' : 'http://services.odata.org/V4/
07. 'value': [{
08. '@odata.etag': 1W/108D1D5BD423E51581′,
09. 'UserName': 'russellwhyte',
10. ...
这是扩展的应用程序/ json和对象。
首先,我们没有使用OData,因为它与JSON API相同,但是并不简洁。 有很多物体,在我看来,所有东西都读得差得多。 OData也出现在Open Source中,但它更加复杂。
GraphQL呢?
自然,当我们在寻找一种新的API格式时,我们就遇到了这种炒作。
●
高进入阈值。从前端的角度来看,一切看起来都很酷,但是您无法让新开发人员编写GraphQL,因为您需要先对其进行研究。 这就像SQL一样-您不能立即编写SQL,必须至少阅读它的内容,并通读教程,即入门门槛增加。
●
大爆炸的效果。如果项目中没有API,而我们开始使用GraphQL,一个月后我们意识到它不适合我们,那就太迟了。 必须写拐杖。 您可以使用JSON API或OData进行开发-最简单的RESTful(逐步改进)将变成JSON API。
●
后端的地狱。GraphQL在后端调用地狱-就像完全实现的JSON API一样,因为GraphQL可以完全控制查询,而这是一个库,您将需要解决很多问题:
而不是结论
我建议不要再争论自行车棚,而应将防自行车棚工具作为规范,并制定一个具有良好规范的API。
要找到解决自行车棚问题的标准,可以查看以下链接:
●
http://jsonapi.org●
http://www.odata.org●
https://graphgl.org●
http://xmlrpc.scripting.com●
https://www.jsonrpc.org: alexey-avdeev.com github .
, Frontend Conf , 27 28 ++ . , .
? ? ? , ? !
, , , , .