在本文中,您将学习有关巴比伦库的所有知识,最重要的是-如何重新创建它,甚至是任何库。
让我们从
路易斯·博尔赫斯 (
Luis Borges)的
巴比伦图书馆引文开始。
报价单“宇宙-有人称它为图书馆-由庞大的,可能是无限数量的六角形画廊组成,宽大的通风室被低矮的轨道包围。 从每个六边形都可以看到两个上层和两个下层-达到无穷大。”
“图书馆是一个球,它的确切中心在一个六边形中,并且无法访问表面。 在每个六角形的每个壁上有五个书架,每个书架上有三十二本格式相同的书,每本书有四百一十页,每页有四十行,每行包含约八十个黑字母。 这本书的书脊上有一些字母,但是它们并没有定义或预示页面会说些什么。 我知道,这种差异曾经看起来很神秘。”
如果您输入随机的六边形,则爬到任意一堵墙,看着任何书架,拿最喜欢的书,那么您很可能会感到沮丧。 毕竟,您希望能找到那里生活的意义,但是您看到了一些奇怪的人物角色。 但是不要这么快就生气! 大多数书都是毫无意义的,因为它们是对25个字符的所有可能变体的组合搜索(
博尔赫斯在他的图书馆中使用的是这个字母,但随后读者会发现图书馆中可以有任意数量的字符 )。 图书馆的主要法律是其中没有两本完全相同的书,因此它们的数量是有限的,图书馆也有一天会结束。 博尔赫斯认为图书馆是定期的:
报价单“也许恐惧和晚年正在欺骗我,但我认为人类(唯一的人类)已濒临灭绝,图书馆将生存下来:光明,无人居住,无限,绝对静止,充满珍贵的书卷,无用,廉洁,神秘。 我只是写不完。 我不是出于对修辞学的热爱而设置这个词的。 我认为假设世界是无限的是合乎逻辑的。 那些认为有限的人承认,在远处的走廊,楼梯和六边形的某个地方可以出于某种未知的原因而结束-这样的假设是荒谬的。 那些无国界想象它的人会忘记,可能的书本数量是有限的。 我敢于为这个古老的问题提出这样的解决方案:该库是无限且定期的。 如果永恒的流浪者踏上了任何方向的旅程,那么他将能够在几个世纪后验证同一本书在同一混乱中重复出现(当重复出现时,将变成顺序-顺序)。 这种优雅的希望使我更加孤独。”
与胡说八道相比,很少有人能至少以某种方式理解其内容的书籍,但这并不能改变图书馆包含了一个人曾经并且将会发明的所有文本这一事实。 此外,从孩提时代起,您就习惯于认为某些符号序列有意义,而另一些则没有意义。 实际上,在库的上下文中,它们之间没有区别。 但是,有意义的百分比要低得多,我们称之为语言。 这是人与人之间的交流手段。 任何一种语言都只包含成千上万个单词,其中我们知道它的70%的优势,因此事实证明,我们无法解释大部分书籍的组合搜索。 有人患有
失语症 ,甚至在随机字符集中也看到了隐藏的含义。 但这对于
隐写术是个好主意! 好吧,我将继续在评论中讨论这个主题。
在继续执行此库之前,我将使您感到惊讶,这是一个有趣的事实:如果您要重新创建路易斯·博尔赫斯的巴比伦库,您将不会成功,因为它的体积超过了可见的10 ^ 611338(!)倍。 关于甚至更大的库中将发生的事情,我什至不敢思考。
图书馆实施
模块说明
我们的小介绍结束了。 但这并非毫无意义:现在您了解了巴比伦图书馆的面貌,继续阅读只会更加有趣。 但是我将摆脱最初的想法,我想创建一个“通用”库,稍后将对其进行讨论。 我将在Node.js下用JavaScript编写该库应该做什么?
- 快速找到所需的文本并在库中显示其位置
- 定义书名
- 快速找到标题正确的书
另外,它应该是通用的,即 如果需要,可以更改任何库参数。 好吧,我想我将首先展示该模块的全部代码,我们将对其进行详细分析,看看其工作方式,然后说几句话。
Github仓库主文件是index.js,在那里描述了库的整个逻辑,我将解释该文件的内容。
let sha512 = require(`js-sha512`);
我们连接实现
sha512哈希
算法的模块。 这对您来说似乎很奇怪,但对我们仍然有用。
我们模块的输出是什么? 它返回一个函数,对该函数的调用将返回具有所有必要方法的库对象。 我们可以立即将其返回,但是当我们将参数传递给函数并获得“所需”库时,管理库就不那么方便了。 这将使我们能够创建一个“通用”库。 由于我尝试以ES6风格编写,所以我的arrow函数接受一个对象作为参数,该对象随后将被分解为必要的变量:
module.exports = ({ lengthOfPage = 4819, lengthOfTitle = 31, digs = '0123456789abcdefghijklmnopqrstuvwxyz', alphabet = ', .', wall = 5, shelf = 7, volume = 31, page = 421, } = {}) => {
现在让我们来看一下参数。 作为标准的数字参数,我决定选择质数,因为在我看来,这会更有趣。
- lengthOfPage-数字,一页上的字符数。 默认值为4819。如果将这个数字考虑在内,我们将得到61和79。61行包含79个字符,反之亦然,但是我更喜欢第一种选择。
- lengthOfTitle-数字,书名标题中的字符数。
- digs-字符串,基数等于此字符串长度的数字的可能数字。 这个号码是做什么用的? 它将包含我们要移动到的六边形的数字(标识符)。 默认情况下,它是小写拉丁字母和数字0-9。 大部分文本都在此处进行编码,因此将是一个很大的数目-几千位(取决于页面上的字符数),但是将逐个字符地对其进行处理。
- 字母 -字符串,我们要在库中看到的字符。 它将充满他们。 为了使一切正常工作,字母中的字符数必须等于字符串中的字符数,并且可能的数字数字标识六角形。
- wall-数字,最大墙壁数,默认为5
- 架子 -编号,最大架子号,默认为7
- 卷 -数量,最大书本号,默认为31
- 页 - 页数 ,最大页数,默认421
如您所见,这有点像真正的巴比伦图书馆路易斯·博尔赫斯。 但是我已经不止一次地说过,我们将创建“通用”库,这些库将成为我们希望看到它们的方式(因此,十六进制数可以用不同的方式解释,例如,仅存储所需位置的某个地方的标识符信息)。 巴比伦图书馆只是其中之一。 但是它们都有很多共同点-一种算法负责其性能,现在将对其进行讨论。
页面搜索和显示算法
当我们转到某个地址时,我们会看到页面的内容。 如果再次访问相同的地址,则内容应该完全相同。 库的此属性提供了一种生成伪随机数的算法-
线性一致法 。 当我们需要选择一个字符来生成地址时,或者相反,该页面的内容将对我们有帮助,并且页面,架子等的数量将用作谷物。 我的PRNG的配置为:m = 2 ^ 32(4294967296),a = 22695477,c =1。我还想补充一点,在我们的实现中,线性一致方法仅保留了数字生成的原理,其余的都被更改了。 我们将进一步列出该程序:
代号 module.exports = ({ lengthOfPage = 4819, lengthOfTitle = 31, digs = '0123456789abcdefghijklmnopqrstuvwxyz', alphabet = ', .', wall = 5, shelf = 7, volume = 31, page = 421, } = {}) => { let seed = 13;
如您所见,PRNG谷物在每次收到数字后都会发生变化,结果直接取决于所谓的参考点-谷物,之后数字将使我们感兴趣。 (我们生成地址或获取页面内容)
getHash函数将帮助我们生成参考点。 我们只是从一些数据中得到一个哈希值,取7个字符,转换为十进制数字系统,就可以了!
mod函数的行为与%运算符相同。 但是,如果被除数是<0(可能出现这种情况),则由于特殊的结构,
mod函数将返回正数,因此,当在地址处接收页面内容时,我们需要此函数以正确地从
字母字符串中选择字符。
最后的甜点代码是返回的库对象:
代号 return { wall, shelf, volume, page, lengthOfPage, lengthOfTitle, search(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), page = pad(`${(Math.random()* this.page + 1 ^ 0)}`, 3), locHash = getHash(`${wall}${shelf}${volume}${page}`), hex = ``, depth = Math.random() * (this.lengthOfPage - searchStr.length) ^ 0; for (let i = 0; i < depth; i++){ searchStr = alphabet[Math.random() * alphabet.length ^ 0] + searchStr; } seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]] || -1, rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}-${+page}`; }, searchExactly(text) { const pos = Math.random() * (this.lengthOfPage - text.length) ^ 0; return this.search(`${` `.repeat(pos)}${text}${` `.repeat(this.lengthOfPage - (pos + text.length))}`); }, searchTitle(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), locHash = getHash(`${wall}${shelf}${volume}`), hex = ``; searchStr = searchStr.substr(0, this.lengthOfTitle); searchStr = searchStr.length == this.lengthOfTitle ? searchStr : `${searchStr}${` `.repeat(this.lengthOfTitle - searchStr.length)}`; seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]], rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}`; }, getPage(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}${pad(addressArray[4], 3)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfPage) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfPage); }, getTitle(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfTitle) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfTitle); } };
在开始时,我们将上面描述的库属性写入其中。 即使调用了main函数,您也可以更改它们(原则上可以称为构造函数,但是我的代码与库的类实现几乎没有相似之处,因此我将自己局限于“ main”一词)。 也许这种行为不是完全足够的,而是灵活的。 现在遍历每种方法。
搜索方式
search(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random() * this.volume + 1 ^ 0)}`, 2), page = pad(`${(Math.random() * this.page + 1 ^ 0)}`, 3), locHash = getHash(`${wall}${shelf}${volume}${page}`), hex = ``, depth = Math.random() * (this.lengthOfPage - searchStr.length) ^ 0; for (let i = 0; i < depth; i++){ searchStr = alphabet[Math.random() * alphabet.length ^ 0] + searchStr; } seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]] || -1, rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}-${+page}`; }
返回库中
searchStr字符串的地址。 为此,请随机选择
墙壁,架子,体积,页面 。
卷和
页面也用零填充到所需的长度。 接下来,将它们连接成一个字符串以传递给
getHash函数。 产生的
locHash是起点,即 谷物。
为了提高不可预测性,我们
用字母的伪随机字符补充
searchStr 深度 ,并将种子
种子设置为
locHash 。 在此阶段,我们对该行进行补充并不重要,因此您可以使用内置的JavaScript PRNG,这并不重要。 您可以完全放弃它,以便我们感兴趣的结果始终位于页面顶部。
剩下的唯一事情就是生成六角形标识符。 对于
searchStr字符串的每个字符,
我们执行以下算法:
- 从AlphabetIndexes对象获取字母表中索引字符的编号。 如果不是,则返回-1,但是如果发生这种情况,则您肯定做错了什么。
- 使用我们的PRNG生成一个伪随机数rand ,范围是0到字母长度。
- 计算新索引,该新索引的计算方式为符号索引的数量与伪随机数rand的和 ,以取挖取的长度为模。
- 因此,我们得到了六边形标识符的数字-newChar (从digs获取 )。
- 将newChar添加到十六进制标识符hex
十六进制生成完成后,我们返回包含所需行的地方的完整地址。 地址部分由连字符分隔。
SearchExactly方法
searchExactly(text) { const pos = Math.random() * (this.lengthOfPage - text.length) ^ 0; return this.search(`${` `.repeat(pos)}${text}${` `.repeat(this.lengthOfPage - (pos + text.length))}`); }
此方法与
搜索方法相同,但是会填充所有可用空间(使
搜索字符串
searchStr具有
lengthOfPage个字符的长度)。 查看此类页面时,除了您的文字外,似乎没有任何内容。
SearchTitle方法
searchTitle(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), locHash = getHash(`${wall}${shelf}${volume}`), hex = ``; searchStr = searchStr.substr(0, this.lengthOfTitle); searchStr = searchStr.length == this.lengthOfTitle ? searchStr : `${searchStr}${` `.repeat(this.lengthOfTitle - searchStr.length)}`; seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]], rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}`; }
searchTitle方法返回名为
searchStr的书的地址。 在内部,它与
search非常相似。 区别在于,在计算
locHash时,我们不使用页面将其名称绑定到书。 它不应该取决于页面。
searchStr被截断为
lengthOfTitle,并在必要时用空格填充。 类似地,生成六边形标识符,并返回接收到的地址。 请注意,其中没有页面,就像在搜索任意文本的确切地址时一样。 因此,如果您要查找书中用您创造的名字写的东西,请决定要转到的页面。
GetPage方法
getPage(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}${pad(addressArray[4], 3)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfPage) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfPage); }
与
搜索方法相反。 它的任务是将页面的内容返回到指定的地址。 为此,我们使用分隔符“-”将地址转换为数组。 现在我们有了一系列地址组件:六角形标识符,墙,架子,书本,页面。 我们以与
搜索方法相同的方式计算
locHash 。 我们得到的数字与生成地址时的数字相同。 这意味着PRNG将产生相同的数字,正是这种行为确保了我们对源文本进行转换的可逆性。 为了计算它,我们对六边形标识符的每个字符(实际上,这是一个数字)执行算法:
- 我们在字符串dig中计算索引 。 从digsIndexes中获取 。
- 使用PRNG,我们生成一个伪随机数rand ,范围是0到大数的数字系统的底数,该整数等于包含该美丽数字的数字的字符串的长度。 一切都是显而易见的。
- 我们将源文本newIndex的符号位置计算为index和rand之间的差,以字母的长度为模除。 在这种情况下,如果差为负,则通常的除法模将给出负指数,这不适合我们,因此我们使用模除的修改版本。 (您可以尝试从上述公式中选择取绝对值,这也解决了负数的问题,但实际上尚未进行过测试)
- 页面文本的字符是newChar ,我们从字母表中获取索引。
- 在结果中添加文本字符。
在此阶段获得的结果并不总是会填满整个页面,因此我们将根据当前结果计算出新的颗粒,并用字母中的字符填充可用空间。 PRNG帮助我们选择符号。
这样就完成了页面内容的计算,我们将其返回,而不会忘记裁剪到最大长度。 输入地址中的六角形标识符可能过大。
GetTitle方法
getTitle(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfTitle) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfTitle); }
好吧,故事是一样的。 想象一下,阅读前一种方法的描述时,仅在计算PRNG粒度时不考虑页码,而是将结果添加并裁切为书籍title-
lengthOfTitle的最大长度。
测试用于创建库的模块
在我们研究了类似巴比伦的任何图书馆的运作原理之后,现在该在实践中尝试一下。 我将使用与Louis Borges创建的配置尽可能接近的配置。 我们将搜索一个简单的短语“ habr.com”:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
运行,结果:

目前,它没有给我们任何东西。 但是,让我们找出此地址背后隐藏的内容吧! 代码将如下所示:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
结果:
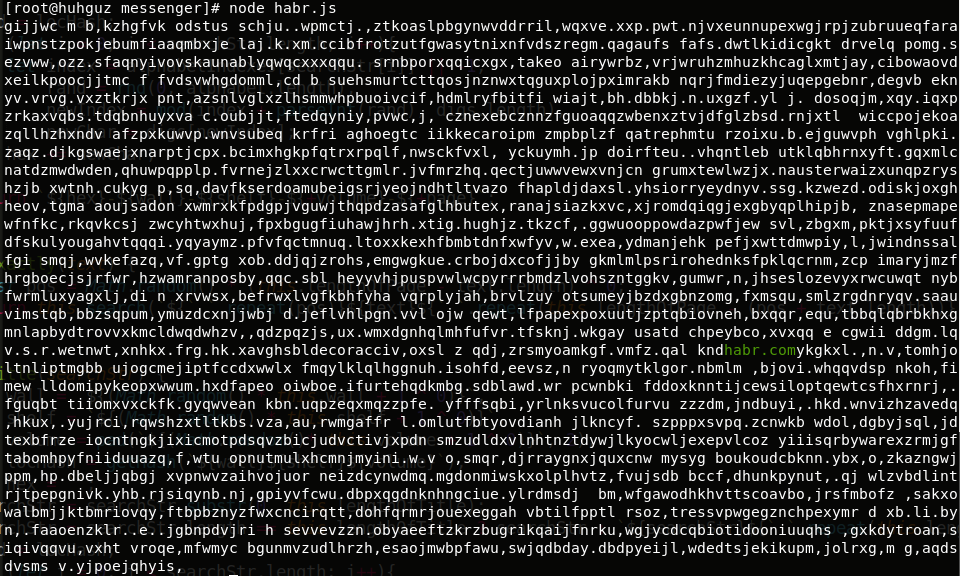
我们在无数无意义的页面中找到了所需的内容!
但这远不是该短语所在的唯一位置。 下次程序启动时,将生成另一个地址。 如果需要,可以保存一个并使用它。 最主要的是页面的内容永远不会改变。 让我们看看我们的短语所在的书的标题。 代码如下:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
这本书的标题是这样的:
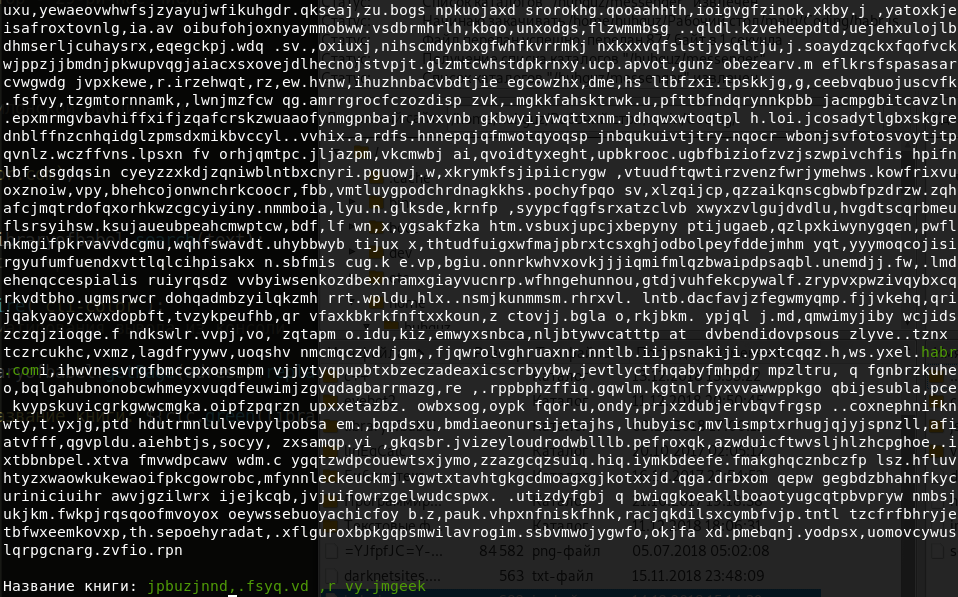
老实说,它看起来并不吸引人。 然后,找到一本标题为我们的短语的书:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
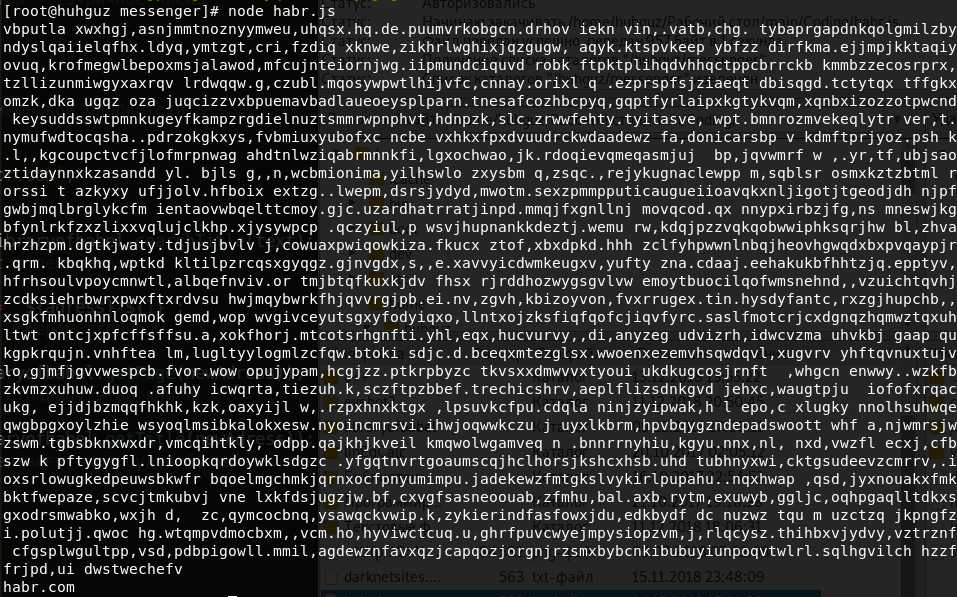
现在您了解了如何使用该库。 让我演示创建一个完全不同的库的可能性。 现在将用1和0填充,每个页面将包含100个字符,地址将是一个十六进制数字。 不要忘记遵守使字母的长度与我们的大数字串相等的条件。 我们将搜索例如“ 10101100101010111001000000”。 我们看:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 100, alphabet: `1010101010101010`,

让我们看一下寻找完全匹配的地方。 为此,
让我们回到旧示例,然后在代码
中将 libraryofbabel.search替换为
libraryofbabel.searchExactly :
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`,
结论
阅读了库操作算法的描述之后,您可能已经猜到这是一种欺骗。
当您在库中寻找有意义的东西时,它只是以不同的形式编码并以不同的形式显示。但是它的服务如此精美,以至于您开始相信这些无休止的六边形行。实际上,这不过是数学上的抽象而已。但是事实是,在这个库中您可以找到任何东西。事实是,如果您生成随机的字符序列,则迟早可以获得绝对任何文本。为了更好地理解该主题,您可以研究无尽的猴子定理。您可以提出用于实现库的其他选项:使用任何加密算法,其中密文是您综合库中的地址。解密-获取页面内容。或者也许尝试base64,米?该库的一种可能用途是将密码存储在其某些位置。创建所需的配置,找出密码在库中的位置(是的,密码已经存在。您以为是您发明了密码?),保存地址。现在,当您需要查找某种密码时,只需在库中找到它即可。但是这种方法很危险,因为攻击者可以找出库配置并仅使用您的地址。但是,如果他不知道所发现的含义,那么您的数据就不太可能到达他的手中。真的是这样一种主流的密码存储方法吗?不,所以它有一个地方。这个想法可以用来创建各种“库”。您不仅可以遍历字符,还可以遍历整个单词甚至声音!想象一下一个地方,您可以在这里收听到任何可以感知的声音,也可以找到某种歌曲。将来,我一定会尝试实现这一点。俄语的Web版本在这里可用,它已部署在我的虚拟服务器上。我不知道在巴比伦图书馆或您想要创造的东西中,对生命意义的所有令人愉快的搜索。再见! :)